In our first blog, “IoT Overdrive Part 1: Compute Cluster Running Apache Cassandra® and Apache Kafka®”, we explored the project’s inception and Version 1.0. Now, let’s dive into the evolution of the project via a walkthrough of Version 1.4 and our plans with Version 2.0.
Some of our initial challenges that need to be addressed include:
- Insufficient hardware
- Unreliable WiFi
- Finding a way to power all the new and existing hardware without as many cables
- Automating the setup of the compute nodes
Upgrade: Version 1.4
Version 1.4 served as a steppingstone to Version 2.0, codenamed Ericht, which needed to be portable for shows and talks. Scaling up and out was a big necessity for this version, to make it operable at demonstrations in a timely manner.
Why the jump to 1.4? We made a few changes in between that were relatively minor, and so we rolled v1.1–1.3 into v1.4.
Let’s walk through the major changes:
Hardware
To resolve the insufficient hardware issue, we enhanced the hardware, implementing both vertical and horizontal scaling, and introduced a new method to power the Pi computers. This includes lowering the baseline model for a node at a 4GB quad-core computer (for vertical scale) and increasing the number of nodes for horizontal scaling.
These nodes are comparable to smaller AWS instances, and the cluster could be compared to a free cluster on the Instaclustr managed service.
Orange Pi 5
We upgraded the 4 Orange Pi worker nodes to Orange Pi 5s with 8gb RAM and added 256GB M.2 storage drives to each Orange Pi for storing database and Kafka data.
Raspberry Pi Workers
The 4 Raspberry Pi workers were upgraded to 8GB RAM Raspberry Pi 4bs, and the 4GB models were reassigned as Application Servers. We added 256GB USB drives to the Raspberry Pis for storing database and Kafka data.
After all that, the cluster plan looked like this:
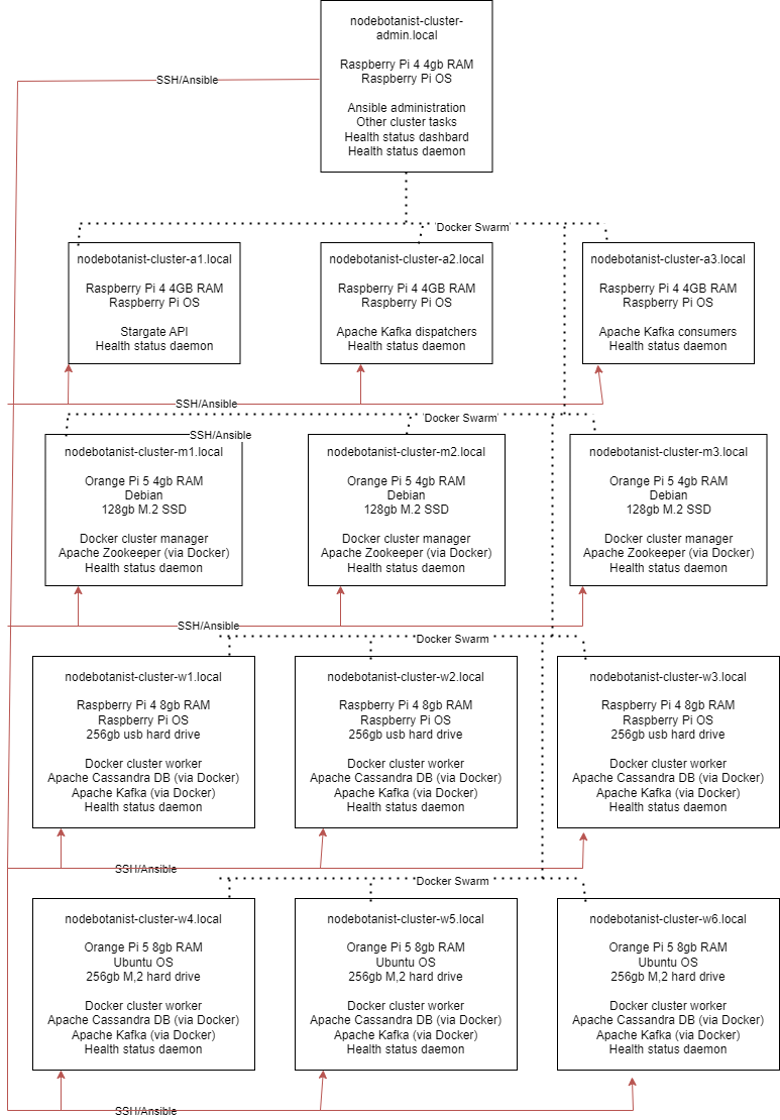
Source: Kassian Wren
We needed a way to power all of this; luckily there’s a way to kill two birds with one stone here.
Power Over Ethernet (PoE) Switch
To eliminate power cable clutter and switch to ethernet connections, I used a Netgear 16-port PoE switch. Each Pi has its own 5V/3A adapter, which splits out into power USB-C and ethernet connectors.
This setup allowed for a single power plug to be used for the entire cluster instead of one for each Pi, greatly reducing the need for power strips and slimming down the cluster considerably.
The entire cluster plus the switch consume about 20W of power, which is not small but not unreasonable to power with a large solar panel.

Source: Kassian Wren
Software
I made quite a few tweaks on the software side in v1.4. However, the major software enhancement was the integration of Ansible.
Ansible automated the setup process for both Raspberry and Orange Pi computers, from performing apt updates to installing Docker and starting the swarm.
Making it Mobile
We made the enclosure more transport-friendly with configurations for both personal travel and secure shipping. An enclosure was designed from acrylic plates with screw holes to match the new heat sink/fan cases for the Pi computers.
Using a laser cutter/engraver, we cut the plates out of acrylic and used standoff screws for motherboards to stand the racks two high; although it can be configured to be four-high, it gets tall and ungainly.
The next challenge was coming up with a way to ship it for events.
There are two configurations: one where the cluster travels with me, and the other where the cluster is shipped to my destination.
For shipping, I use one large pelican case (hard-sided suitcase) with the pluck foam layers laid out to cradle the enclosures, with the switch in the layer above.
The “travel with me” configuration is still a work in progress; fitting everything into a case small enough to travel with is interesting! I use a carry-on pelican case and squish the cluster in. You can see the yellow case in this photo:

Source: Kassian Wren
More Lessons Learned
While Version 1.4 was much better, it did bring to light the need for more services and capabilities, and showed how my implementation of the cluster was pushing the limits of Docker.
Now that we’ve covered 1.4 and all of the work we’ve done so far, it’s time to look to the future with version 2.0, codenamed “Ericht.”
Next: Version 2.0 (Ericht)
With 2.0, I needed to build out a mobile, easy-to-move version of the cluster.
Version 2.0 focuses on creating a mobile, easily manageable version of the cluster, with enhanced automation for container deployment and management. It also implements a service to monitor the health of the cluster and pass and store the data using Kafka and Cassandra.
The problems we’re solving with 2.0 are:
- Container management overhaul
- Create mobility for the cluster
- Give the cluster something to do and show
- Monitor the health and status of the cluster
Hardware for 2.0
A significant enhancement in this new version is the integration of INA226 Voltage/Current sensors into each Pi. This addition is key in providing advanced power monitoring, and detailed insights into each unit’s energy consumption.
Health Monitoring
I will be implementing an advanced health monitoring system that tracks factors such as CPU and RAM usage, Docker status, and more. These will be passed into the Cassandra database using Kafka consumers and producers.
Software Updates
Significant software updates are planned on the software side of things. As the Docker swarm requires a lot of manual maintenance, I wanted a better way to orchestrate the containers. One way we thought of was Kubernetes.
Kubernetes (K8s)
We’re transitioning to utilizing with Docker, an open source container orchestration system, to manage our containers. Though Kubernetes is often used for more transient containers than Kafka and Cassandra, we have operators available such as Strimzi for Kafka and K8ssandra for Cassandra to help make this integration more feasible and effective.
Moving Ahead
As we continue to showcase and demo this cluster more and more often, (we were at Current 2023 and Community Over Code NA!), we are learning a lot. This project’s potential for broader technological applications is becoming increasingly evident.
As I move forward, I’ll continue to document my progress and share my findings here on the blog. Our next post will go into getting Apache Cassandra and Apache Kafka running on the cluster in Docker Swarm.