Throughout this series, we’ll be walking through the design, implementation, and use of a compute cluster, comprised (as completely as can be) of open source hardware and software. But what is a compute cluster? And what do I mean by open source hardware and software?
In Part 1, we’ll give a high-level overview of the project, what it can do, and where we’ll be taking this series and the project in the future.
Let’s start with some definitions that will make explaining the project a bit easier.
What Is a Compute Cluster?
A compute cluster is defined as 2 or more computers programmed to act as one computer. Our compute cluster will host several APIs, but users will not know what each node does, or even see the nodes; any request made to the cluster will return a single API response. The compute cluster does not need all computers of the same type; it can be heterogeneous (like the cluster we’ll describe in this post).
Open Source Hardware
From the Open Source Hardware Association (OSHWA) website:
“Open source hardware is hardware whose design is made publicly available so that anyone can study, modify, distribute, make, and sell the design or hardware based on that design. The hardware’s source, the design from which it is made, is available in the preferred format for making modifications to it.
“Ideally, open source hardware uses readily available components and materials, standard processes, open infrastructure, unrestricted content, and open source design tools to maximize the ability of individuals to make and use hardware.
“Open source hardware gives people the freedom to control their technology while sharing knowledge and encouraging commerce through the open exchange of designs.”
In short, open source hardware has its complete design publicly available and allows anyone to modify or re-distribute it.
Now let’s take a closer look at a subset of hardware: single-board computers.
Single-Board Computers
These computers are usually credit-card sized and contain everything you need to run operating systems like Debian, Android, and more.
You may have heard of the very notable Raspberry Pi; this is one of the more well-known examples. There are also other boards that meet this definition, such as the BeagleBone series of computers, and Orange Pi series.

Raspberry Pi (Source: Wikipedia)
Now that we’ve covered the vocabulary, let’s look at what the project is in detail.
What Is the Project About?
The elevator pitch is this: a compute cluster made from open source hardware and software that hosts an Apache Cassandra® database and an Apache Kafka® messaging system. The objective was to see if a physical cluster could be created that even remotely represented what it’s like to manage clusters in the cloud.
Not an easy task; perhaps doing it would add at least a couple of layers of complexity to the project. But rather than see that as a negative, continue reading to find out how it got turned into a positive.
A Way to Learn About New Technologies
One of the many things someone working in Developer Relations (DevRel) should know (in my non-expert opinion) is how they learn best and how to pick up new technologies quickly.
I pick things up best by playing with them and building things. In many ways, this project offered me a lot of hands-on experience with many of the technologies needed in my day-to-day work including but not limited to:
- Apache Cassandra
- Apache Kafka
- KRaft
- Ansible
- Docker
- Docker Compose
- Docker Swarm
- Linux utilities and command line tools
- Networking
New technologies are being added to this list; it’s been a wonderful deep dive into deploying Cassandra clusters and Kafka swarms.
At the beginning it was unclear exactly how many technologies would be added to my repertoire of “skills I know just enough to be dangerous with”, and that’s because of the nature of the project.
An Experiment in IoT
This project should definitely be filed under “experimental”: Version 1.0 was all about not knowing for sure if it would even work.
But what makes these kinds of projects exciting is the fear of failure. Luckily, it did work (sort of–more on that in a bit) and building onto it made it work well. I will be using a lot of IoT technologies in building and monitoring the cluster, including I2C drivers, a lot of cli command parsing, and some embedded programming.
A Fun Demo!
Sometimes a cool demo is all it takes to bring people into a booth or a presentation.
Creating 4 racks of computers that fit on a desk and network together to host a distributed database and messaging system was challenging, interesting and most definitely a good time to build!
What This Project Does
This project hosts an Apache Cassandra database and an Apache Kafka message broker. The Cassandra database is accessible through a Stargate API (more on that below) and the Kafka system can be accessed directly. This means this project could be used as a locally deployed database and messaging setup, with possibilities for physically distributed hardware.
Apache Cassandra
The database is currently designed to hold health data sent from the nodes and overall cluster itself. Visualizations and alerts using this data will be built at a later stage—watch out for the future blog post on this.
Stargate API
The Stargate project allows us to have a GraphQL API of our Cassandra database data without any extra programming steps. You can learn more on the project’s website.
Apache Kafka
Kafka is the messaging system currently used to send data from users and cluster APIs to the Cassandra database. There are producers and consumers running on the cluster itself, creating and consuming topics and messages.
Version 1.0: the Prototype
The prototype was made from mostly my own boards that were lying around (which is a lot of boards… more details below). Wi-Fi was used for internet communication.
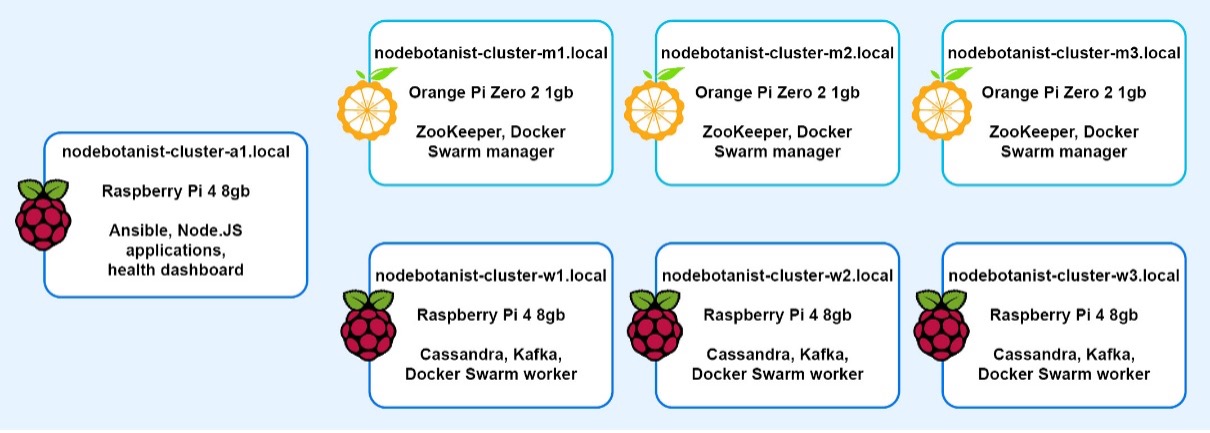
Hardware
Here is a list of the hardware:
- 3 Orange Pi Zero 2 computers
- 3 Raspberry Pi 4 computers with 8GB memory
The Raspberry Pi computers were used as the “workers” (running the Cassandra and Kafka systems), and the Orange Pi computers as the “managers” (running swarm management software, see Docker swarm below for more).
Each node was hand-configured with either Armbian (on the Orange Pi computers) or Raspberry Pi OS (on the Raspberry Pi computers).
A fourth Raspberry Pi 4 was added to serve as an admin machine for the cluster. The initial setup looked something like the following:
Here’s a picture:

Source: Kassian Wren
Software
For the software, we needed something that could manage a cluster of nodes without a ton of overhead. We decided on using Docker, Docker Compose, and Docker Swarm for the prototype. These tools were chosen because they’re open source and very well-supported.
Docker
Docker is a container technology used to run containers with Linux operating systems such as the ones on our Pi computers. Docker also has some utilities that make it exceptionally useful for this project: Docker Compose and Docker Swarm.
Docker Compose
Docker Compose allows us to write out multi-machine services, such as our Cassandra and Kafka clusters. These will then be deployed on Docker containers on the Pi computers.
Docker Swarm
Docker Swarm allows us to network together all of our containers and run them as a swarm. We then use Docker Compose with Swarm to apply services to our Docker container cluster.
A Dockerfile is used to describe the Cassandra and Kafka services as well as any others. We then used Docker Swarm with Compose to create services on the cluster using the Dockerfile mentioned previously.
Putting It All Together
Getting this working was relatively straightforward, even if it appears a bit complicated at first:
- Write an ISO file containing an operating system to the board via MicroSD cards (Ubuntu official image for Orange Pi computers, Raspberry Pi OS for Raspberry Pi computers)
- Logged into each one using ssh
- Perform basic setup and system updates
- Install Docker onto each board (except admin)
- Register a Docker Swarm and add the workers and managers using the CLI utility
- Create a Dockerfile that installed the Cassandra and Kafka services to the worker nodes
- Run Docker Compose with the Dockerfile to create services
- Test Cassandra with cqlsh
- Test Kafka by creating producer and consumer from cli
And after all that preparation–it all worked with minimal tweaking or configuration. Here’s a picture of an in–progress cluster running the software via Docker:

Source: Kassian Wren
Up and Running
Once everything was up and running, the next thought I had was how to test it. Cassandra has cqlsh, an easy way to connect to and access the database.
However, it was…a bit slow. Very slow in fact (it took several seconds to run queries)! The good news was that it looked like my prototype worked, but there were a few issues that made its operation less than ideal.
Lessons Learned
A few good lessons were learnt in the time spent planning, creating, and building version 1.0 and they are:
Need More Compute Power!
It turns out running a database and messaging system takes resources, and there just weren’t enough to go around in my prototype. It needed to scale–not just vertically–but horizontally.
Automation Is Your Friend…
Using secure shell (or ssh) to access each node and configuring it by hand was a bit of a nightmare. There needs to be a way to automate this process for the Pi computers in a repeatable, standard way.
…but Wi-Fi Isn’t
Part of the speed issue was running the cluster on Wi-Fi; the network connections between nodes had high latency and failed intermittently. We will need to switch to ethernet for future iterations.
Too Many Cables!
An issue in the prototype that would get in the way of any horizontal scaling was too many power cables. Each Pi needed one, and the router needed one, too…so unless we wanted to get several power strips, we were going to have to come up with another solution.
Summary
Time for more Pi?
It’s been an interesting experience learning all the technologies involved in building my prototype as well as getting it up and running. It hasn’t all been easy but it’s not over yet.
Version 1.0 was only the beginning—the next evolution of the experiment is in progress.
So, watch out for Part 2 in this series where I share what happened next!