
What Is Apache Kafka?
Apache Kafka is a distributed event streaming platform used for building real-time data pipelines and streaming applications. It operates as a highly scalable, fault-tolerant, and durable commit log where events are published to topics, partitioned for speed, and stored across a cluster of brokers.
Apache Kafka offers four key APIs: the Producer API, Consumer API, Streams API, and Connector API. Combined with redundant storage of massive data volumes and a message bus capable of throughput reaching millions of messages each second, these capabilities make Kafka tailor-made for processing streaming data from real-time applications.
Core architecture components:
- Producers: applications or services that publish messages and events to Kafka topics.
- Consumers: applications or services that subscribe to topics and process streams of data, usually as part of a consumer group.
- Brokers: individual servers in a Kafka cluster that store data and serve client requests, balancing load and providing fault tolerance.
- Topics and partitions: topics are categorized streams of data, and each topic is divided into append-only partitions distributed across brokers.
- Offsets: sequential, monotonically increasing IDs assigned to events in a partition that guarantee message ordering and position.
How data flows and scales:
- Zero-copy principle: Kafka writes sequentially to disk and uses the operating system zero-copy feature to stream data straight to the network for maximum throughput.
- Consumer groups: Kafka assigns each partition to exactly one consumer within a group, enabling massive parallel processing.
Free download: Apache Kafka insights e-Book [Access now]
This is part of a series of articles about Apache Kafka
What is Apache Kafka used for?
Apache Kafka is primarily used for building real-time data pipelines and streaming applications. It enables high-throughput, low-latency message processing, making it suitable for a wide range of use cases.
- Message queuing: Kafka can act as a traditional message broker, where producers send messages and consumers process them. Its ability to handle high volumes of messages with low latency makes it a superior choice compared to traditional messaging systems.
- Real-time data streaming: Kafka is often used to stream data in real time, enabling applications to react to data as it is generated. Common examples include monitoring data, sensor feeds, and clickstream analytics for user behavior tracking.
- Log aggregation: Kafka consolidates logs from multiple services into a centralized location. This is useful for analysis, monitoring, and alerting on event data across distributed systems.
- Event sourcing: Kafka can store a full history of changes to system states, enabling event-driven architectures. This allows applications to rebuild states or reprocess events by replaying logs.
- Data integration and ETL: Kafka Connect simplifies integrating Kafka with other systems such as databases or Hadoop. It serves as a backbone for ETL (Extract, Transform, Load) processes by moving data between various sources and destinations in real-time.
- Microservices communication: Kafka is widely adopted in microservices architectures, allowing loosely coupled services to communicate asynchronously. This reduces dependencies and enhances system resilience.
Learn more about data architecture principles
Summary of key Kafka architecture concepts
Apache Kafka’s architecture is built around the concept of distributed messaging with high scalability, fault tolerance, and low latency. The system’s key components interact to allow Kafka to handle massive streams of real-time data.
| Component | Description |
| Producer | An application that publishes data (messages) to Kafka topics. It optimizes, serializes, and balances messages across partitions. |
| Consumer | An application that subscribes to Kafka topics and reads messages from partitions, typically within a consumer group. |
| Broker | A Kafka server that manages message storage and handles read/write requests. Brokers work together to form a Kafka cluster. |
| Topic | A logical channel that organizes messages. Producers write to topics, and consumers subscribe to them. |
| Partition | A sub-division of a topic that enables parallel processing. Each partition is replicated across brokers for fault tolerance. |
| Offset | A sequential, monotonically increasing ID assigned to each event as it arrives in a partition. Offsets guarantee the ordering and position of messages and let consumers track their read position. |
| KRaft | Kafka’s built-in consensus mechanism that replaces ZooKeeper, managing metadata, controller quorum, and leader elections internally. |
| Replication | Ensures copies of partitions are maintained across different brokers to enhance fault tolerance and availability. |
| Tiered storage | A storage model that offloads older log segments to remote storage, enabling cheaper long-term retention and reduced load on broker disks. |
| Consumer Group | A group of consumers sharing the workload of processing messages from partitions of a topic, ensuring parallelism. |
| Leader | The broker responsible for handling all reads and writes for a partition. Each partition has one leader at any time. |
| Follower | Brokers that replicate data from the leader broker for redundancy and failover purposes. |
The following diagram offers a simplified look at the interrelations between these components. They will be discussed in more detail in the sections below.
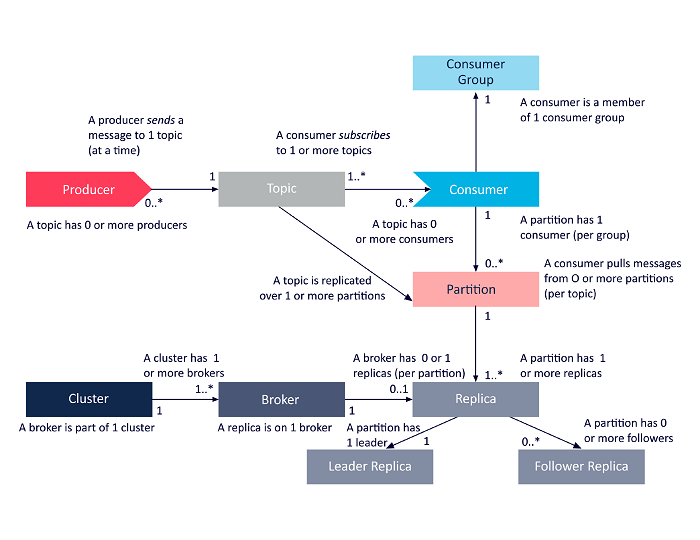
Learn more about Kafka architecture
Apache Kafka basics: Topics, partitions, and commit lo
The following concepts are the foundation to understanding Kafka architecture:
Kafka topics
A Kafka topic defines a channel through which data is streamed. Producers publish messages to topics, and consumers read messages from the topic they subscribe to.
Topics organize and structure messages, with particular types of messages published to particular topics. Topics are identified by unique names within a Kafka cluster, and there is no limit on the number of topics that can be created.
Kafka partitions
Within the Kafka cluster, topics are divided into partitions, and the partitions are replicated across brokers. From each partition, multiple consumers can read from a topic in parallel. It’s also possible to have producers add a key to a message—all messages with the same key will go to the same partition.
While messages are added and stored within partitions in sequence, messages without keys are written to partitions in a round robin fashion. By leveraging keys, you can guarantee the order of processing for messages in Kafka that share the same key. This is a particularly useful feature for applications that require total control over records. There is no limit on the number of Kafka partitions that can be created (subject to the processing capacity of a cluster).
Apache Kafka’s commit log
The Kafka commit log provides a persistent ordered data structure. Records cannot be directly deleted or modified, only appended onto the log. The order of items in Kafka logs is guaranteed. The Kafka cluster creates and updates a partitioned commit log for each topic that exists. All messages sent to the same partition are stored in the order that they arrive. Because of this, the sequence of the records within this commit log structure is ordered and immutable. Kafka also assigns each record a unique sequential ID known as an “offset,” which is used to retrieve data.
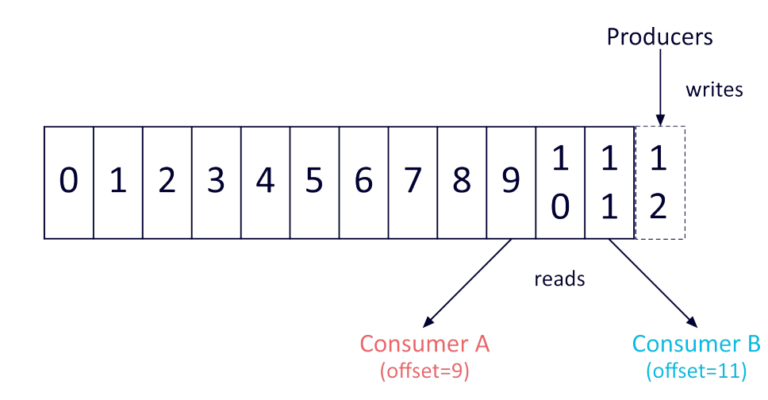
Kafka addresses common issues with distributed systems by providing set ordering and deterministic processing. Because Kafka stores message data on-disk and in an ordered manner, it benefits from sequential disk reads. Considering the high resource cost of disk seeks, the fact that firstly Kafka processes reads and writes at a consistent pace, and secondly reads and writes happen simultaneously without getting in each other’s way, combine to deliver tremendous performance advantages.
With Kafka, horizontal scaling is easy. This means that Kafka can achieve the same high performance when dealing with any sort of task you throw at it, from the small to the massive.
Kafka API architecture
Apache Kafka offers four key APIst: the Producer API, Consumer API, Streams API, and Connector API. Let’s take a brief look at how each of them can be used to enhance the capabilities of applications:
Producer API
The Kafka Producer API enables an application to publish a stream of records to one or more Kafka topics.
Consumer API
The Kafka Consumer API enables an application to subscribe to one or more Kafka topics. It also makes it possible for the application to process streams of records that are produced to those topics.
Streams API
The Kafka Streams API allows an application to process data in Kafka using a streams processing paradigm. With this API, an application can consume input streams from one or more topics, process them with streams operations, and produce output streams and send them to one or more topics. In this way, the Streams API makes it possible to transform input streams into output streams.
Kafka cluster architecture
Now let’s take a closer look at some of Kafka’s main architectural components:
Kafka brokers
A Kafka broker is a server running in a Kafka cluster (or, put another way: a Kafka cluster is made up of a number of brokers).
Typically, multiple brokers work in concert to form the Kafka cluster and achieve load balancing and reliable redundancy and failover. Brokers utilize Apache ZooKeeper® for management and coordination of the cluster. Each broker instance is capable of handling read and write quantities reaching to the hundreds of thousands each second (and terabytes of messages) without any impact on performance. Each broker has a unique ID, and can be responsible for partitions of one or more topic logs.
Kafka brokers also leverage ZooKeeper for leader elections, in which a broker is elected to lead the dealing with client requests for an individual partition of a topic. Connecting to any broker will bootstrap a client to the full Kafka cluster. To achieve reliable failover, a minimum of 3 brokers should be utilized—with greater numbers of brokers comes increased reliability.
KRaft (Kafka Raft)
KRaft is Kafka’s built-in metadata management mode that replaces the need for a separate ZooKeeper ensemble. Instead of relying on ZooKeeper for storing cluster metadata and performing leader elections, a Kafka cluster running in KRaft mode uses an internal Raft-based consensus protocol to maintain and replicate metadata across a set of controller nodes. A quorum of these controllers manages all cluster metadata—topics, partitions, configurations, and leader state—ensuring fault tolerance and consistency. This design simplifies deployment and operations by removing an external dependency, reduces latency in metadata updates, and improves scalability.
Kafka clusters in KRaft mode designate specific servers as controllers (or combined broker/controllers) that participate in the Raft quorum. A majority of controllers must be operational to maintain metadata availability, and if the active controller fails, a new one is elected from the quorum. KRaft has become the default metadata mechanism in recent Kafka releases, with ZooKeeper support deprecated and planned for removal.
Kafka producers
A Kafka producer serves as a data source that optimizes, writes, and publishes messages to one or more Kafka topics. Kafka producers also serialize, compress, and load balance data among brokers through partitioning.
Kafka consumers
Consumers read data by reading messages from the topics to which they subscribe. Consumers will belong to a consumer group. Each consumer within a particular consumer group will have responsibility for reading a subset of the partitions of each topic that it is subscribed to.
Learn more in our blog on Kafka Partitions
Topic replication factor
Topic replication is essential to designing resilient and highly available Kafka deployments.
When a broker goes down, topic replicas on other brokers will remain available to ensure that data remains available and that the Kafka deployment avoids failures and downtime. The replication factor that is set defines how many copies of a topic are maintained across the Kafka cluster. It is defined at the topic level, and takes place at the partition level.
For example, a replication factor of 2 will maintain 2 copies of a topic for every partition. As mentioned above, a certain broker serves as the elected leader for each partition, and other brokers keep a replica to be utilized if necessary. Logically, the replication factor cannot be greater than the total number of brokers available in the cluster. A replica that is up to date with the leader of a partition is said to be an In-Sync Replica (ISR).
Tiered storage (KIP-405)
Tiered storage, introduced as part of KIP-405, enables Kafka to extend its storage capacity beyond local broker disks by offloading older log segments to a remote storage tier such as object stores (e.g., Amazon S3, Google Cloud Storage, Azure Blob Storage). In this architecture, Kafka maintains a local tier for recent data to support low-latency tail reads, and a remote tier for older, infrequently accessed data, which can be retained for much longer periods and at lower cost. When log segments on local storage roll over, they are asynchronously copied to the configured remote store.
Consumers reading older data can fetch it from the remote tier without requiring the broker to host the segment locally. This separation of hot and cold data allows Kafka clusters to scale storage independently from compute, reduce recovery and rebalancing overhead, and support longer retention without continually increasing broker disk capacity. Tiered storage is transparent to clients and configurable per topic, with distinct retention settings for local and remote tiers.
Consumer group
A Kafka consumer group includes related consumers with a common task.
Kafka sends messages from partitions of a topic to consumers in the consumer group. At the time it is read, each partition is read by only a single consumer within the group. A consumer group has a unique group-id, and can run multiple processes or instances at once. Multiple consumer groups can each have one consumer read from a single partition. If the quantity of consumers within a group is greater than the number of partitions, some consumers will be inactive.
Examples of relationships between Kafka components
Let’s look at the relationships among the key components within Kafka architecture. Note the following when it comes to brokers, replicas, and partitions:
- Kafka clusters may include one or more brokers.
- Kafka brokers are able to host multiple partitions.
- Topics are able to include 1 or more partitions.
- Brokers are able to host either 1 or zero replicas for each partition.
- Each partition includes 1 leader replica, and zero or greater follower replicas.
- Each of a partition’s replicas has to be on a different broker.
- Each partition replica has to fit completely on a broker, and cannot be split onto more than one broker.
- Each broker can be the leader for zero or more topic/partition pairs.
Now let’s look at a few examples of how producers, topics, and consumers relate to one another:
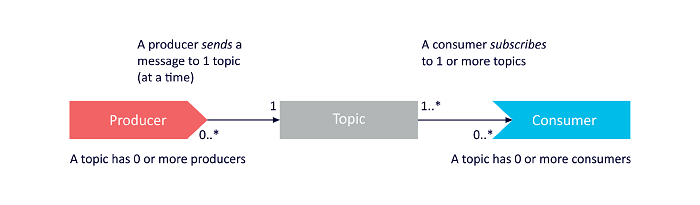
Here we see a simple example of a producer sending a message to a topic, and a consumer that is subscribed to that topic reading the message.
The following diagram demonstrates how producers can send messages to singular topics:
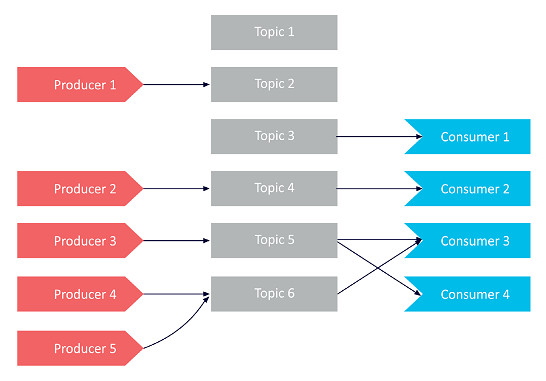
Consumers can subscribe to multiple topics at once and receive messages from them in a single poll (Consumer 3 in the diagram shows an example of this). The messages that consumers receive can be checked and filtered by topic when needed (using the technique of adding keys to messages, described above).
Now let’s look at a producer that is sending messages to multiple topics at once, in an asynchronistic manner:
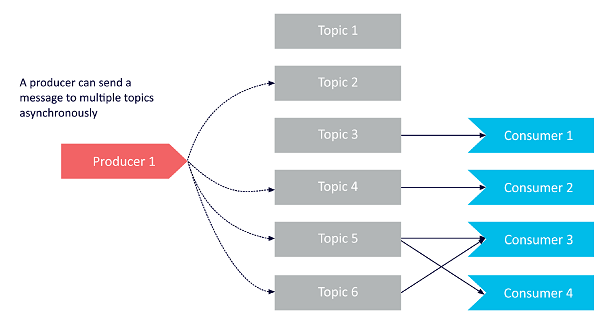
Technically, a producer may only be able send messages to a single topic at once. However, by sending messages asynchronously, producers can functionally deliver multiple messages to multiple topics as needed.
Learn more in our detailed guide to apache kafka cluster
Advantages of Apache Kafka architecture
There are many beneficial reasons to utilize Kafka, each of which traces back to the solution’s architecture. Some of these key advantages include:
Scalability and performance
Kafka offers high-performance sequential writes, and shards topics into partitions for highly scalable reads and writes. As a result, Kafka allows multiple producers and consumers to read and write simultaneously (and at extreme speeds). Additionally, topics divided across multiple partitions can leverage storage across multiple servers, which in turn can enable applications to utilize the combined power of multiple disks.
With multiple producers writing to the same topic via separate replicated partitions, and multiple consumers from multiple consumer groups reading from separate partitions as well, it’s possible to reach just about any level of desired scalability and performance through this efficient architecture.
Much of this speed comes from how Kafka handles I/O. Kafka writes directly to disk in a sequential, append-only fashion, and it uses the operating system zero-copy feature to stream data from disk straight to the network without copying it through application buffers. This minimizes CPU and memory overhead and lets Kafka sustain very high throughput even under heavy load.
Reliability
Kafka architecture naturally achieves failover through its inherent use of replication. Topic partitions are replicated on multiple Kafka brokers, or nodes, with topics utilizing a set replication factor. The failure of any Kafka broker causes an ISR to take over the leadership role for its data, and continue serving it seamlessly and without interruption.
Disaster recovery
Beyond Kafka’s use of replication to provide failover, the Kafka utility MirrorMaker delivers a full-featured disaster recovery solution. MirrorMaker is designed to replicate your entire Kafka cluster, such as into another region of your cloud provider’s network or within another data center.
In this way, Kafka MirrorMaker architecture enables your Kafka deployment to maintain seamless operations throughout even macro-scale disasters. This functionality is referred to as mirroring, as opposed to the standard failover replication performed within a Kafka cluster. For an example of how to utilize Kafka and MirrorMaker, an organization might place its full Kafka cluster in a single cloud provider region in order to take advantage of localized efficiencies, and then mirror that cluster to another region with MirrorMaker to maintain a robust disaster recovery option.
Optimizing Kafka consumers
Relation of partitions to consumers
Within Kafka architecture, each topic is associated with 1 or more partitions, and those are spread over 1 or more brokers.
Each partition is replicated on those brokers based on the set replication factor. While the replication factor controls the number of replicas (and therefore reliability and availability), the number of partitions controls the parallelism of consumers (and therefore read scalability). This is because each partition can only be associated with 11 consumer instance out of each consumer group, and the total number of consumer instances for each group is less than or equal to the number of partitions. Adding more partitions enables more consumer instances, thereby enabling reads at increased scale.
As a result of these aspects of Kafka architecture, events within a partition occur in a certain order. Inside a particular consumer group, each event is processed by a single consumer, as expected. When multiple consumer groups subscribe to the same topic, and each has a consumer ready to process the event, then all of those consumers receive every message broadcast by the topic. In practice, this broadcast capability is quite valuable.
Techniques for scaling a single topic across multiple partitions and consumers
Consider an example where the Kafka deployment architecture uses an equal number of partitions and consumers within a consumer group:
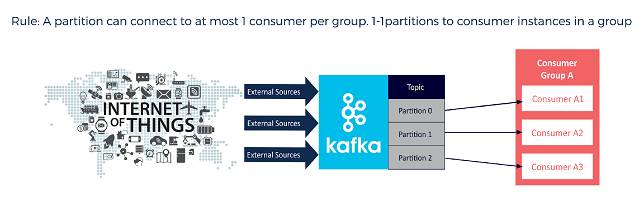
As we’ve established, Kafka’s dynamic protocols assign a single consumer within a group to each partition. This is usually the best configuration, but it can be bypassed by directly linking a consumer to a specific topic/partition pair. Doing so is essentially removing the consumer from participation in the consumer group system. While it is unusual to do so, it may be useful in certain specialized situations.
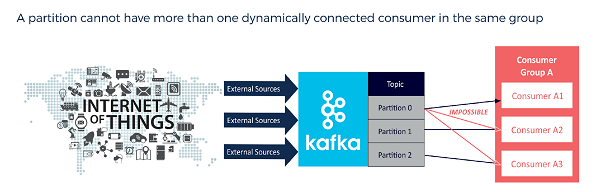
Now let’s look at a case where we use more consumers in a group than we have partitions. This causes some consumers to stand idle. Kafka can make good use of these idle consumers by failing over to them in the event that an active consumer dies, or assigning them work if a new partition comes into existence.
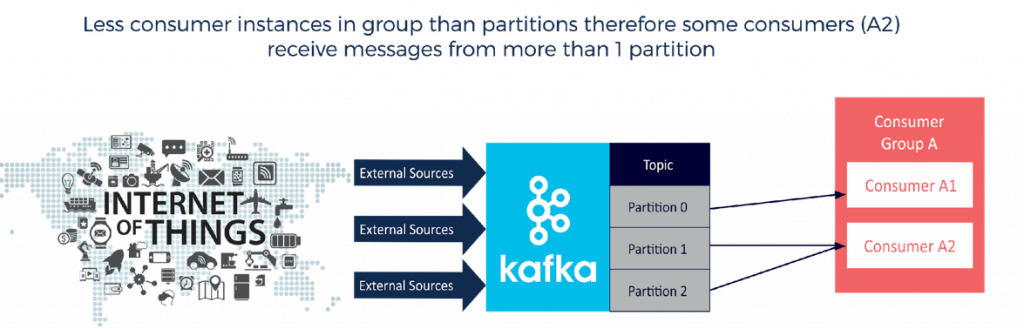
Next, let’s look at an example of a group which includes fewer consumers than partitions. The result in this example is that Consumer A2 is stuck with the responsibility of processing more messages that its counterpart, Consumer A1:
In our last example, multiple consumer groups receive every event from every Kafka partition, resulting in messages being fully broadcast to all groups:
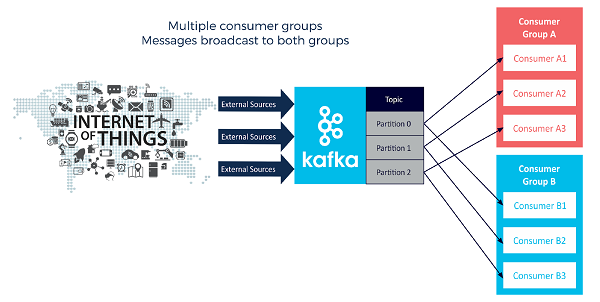
Kafka’s dynamic protocol handles all the maintenance work required to ensure a consumer remains a member of its consumer group. When new consumer instances join a consumer group, they are also automatically and dynamically assigned partitions, taking them over from existing consumers in the consumer group as necessary. If and when a consumer instance dies, its partition will be reassigned to a remaining instance in the same manner.
Consumer resource independence
It’s crucial to recognize that consumers and producers do not run on Kafka brokers, and instead require their own CPU and IO resources. This resource independence is a boon when it comes to running consumers in whatever method and quantity is ideal for the task at hand, providing full flexibility with no need to consider internal resource relationships while deploying consumers across brokers.
That said, this flexibility comes with responsibility: it’s up to you to figure out the optimal deployment and resourcing methods for your consumers and producers. This is no small challenge, and must be considered with care. Leveraging highly scalable and elastic microservices to fulfill this need is one suggested strategy.
Harnessing the power of Apache Kafka with the NetApp Instaclustr Managed Platform
NetApp Instaclustr, a leading provider of managed open-source data platforms, delivers a comprehensive solution for organizations leveraging Apache Kafka. With its managed platform, Instaclustr simplifies the deployment, management, and optimization of this popular streaming tool, offering businesses the ability to build scalable, real-time data pipelines with ease.
Instaclustr handles infrastructure setup, configuration, and ongoing maintenance, allowing organizations to quickly adopt Apache Kafka without dealing with complex infrastructure management. This reduces time-to-market and lets businesses focus on developing their data pipelines and applications.
With Instaclustr for Apache Kafka, you can experience:
- Seamless scaling of Apache Kafka clusters to handle growing data volumes and traffic spikes.
- Automated scaling for a reliable, high-performance streaming platform.
- Built-in redundancy and fault tolerance to minimize risks of data loss or service interruptions.
- Expert engineering support for optimizing Kafka clusters’ performance and reliability.
- Proactive monitoring, troubleshooting, and performance tuning to maximize Kafka capabilities.
- Robust security measures including encryption, authentication, authorization, and network isolation.
- Compliance with industry best practices and privacy regulations to protect sensitive data.
For more information: