Instaclustr is pleased to announce the availability, as part of Apache Kafka® Connect Managed Service, of the open source Instaclustr Kafka Connect S3 connector. This connector is designed to enable Kafka users to easily store data to, and source data from, Amazon S3. The Kafka Connect S3 connector builds on the recent general availability release of Kafka Connect on the Instaclustr Managed Platform.
Kafka Connect Connectors
By creating connectors, developers are able to simplify the integration of data sources or data sinks with Kafka. The connectors leverage the Kafka Connect API and the reliability and scalability benefits offered by Kafka Connect.
S3 Connector
The primary use case of the S3 Connector is to allow backup and recovery. When implemented as both a sink and source to a single Kafka topic, the connector allows for the backup and recovery of Kafka message streams. The S3 Connector may also be used as a sink to write data to S3 for long term storage or analytical use.
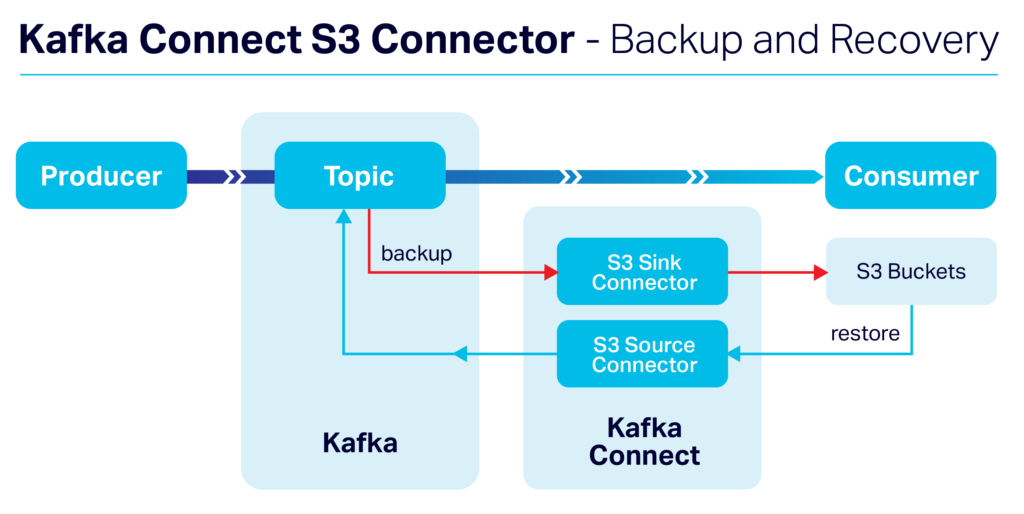
Before commencing the development of our own S3 Connector, Instaclustr undertook a study of existing available connectors but determined they were either not under a true open source license, lacking in crucial features, or not actively maintained.
We have open sourced the Instaclustr Kafka Connect S3 Connector under the Apache 2.0 license, removing any licensing concerns for our customers. As the first pre-built connector as part of our Managed Kafka Connect offering, the S3 connector will be fully supported and maintained by Instaclustr. Being a pre-built connector also means that setup of the connector is as simple as sending a configuration that you require to your Instaclustr Managed Kafka Connect cluster.
Full details of how to implement and configure the connector can be found on our S3 connector support page.
If you want to know more about Instaclustr Kafka Connect and our S3 Connector, or if you have specific requirements around additional connectors, please contact our Support team.