Introduction
In a previous post, we showed one method for migrating an existing REST-based data ingestion endpoint to Kafka®, by leveraging Karapace Rest Proxy to allow upstream clients to continue using familiar APIs to interface with the service, and by using Kafka® Connect to allow downstream services to receive data from Kafka without requiring complex changes in the downstream services themselves.
This goes a long way toward enabling incremental adoption of Kafka within a software system, but there are some obvious questions to ask. Among them is the one we’ll be addressing in this post, namely: What if your downstream services were using some other message format?
Initial setup
To justify this question, let’s take a look at an example setup:
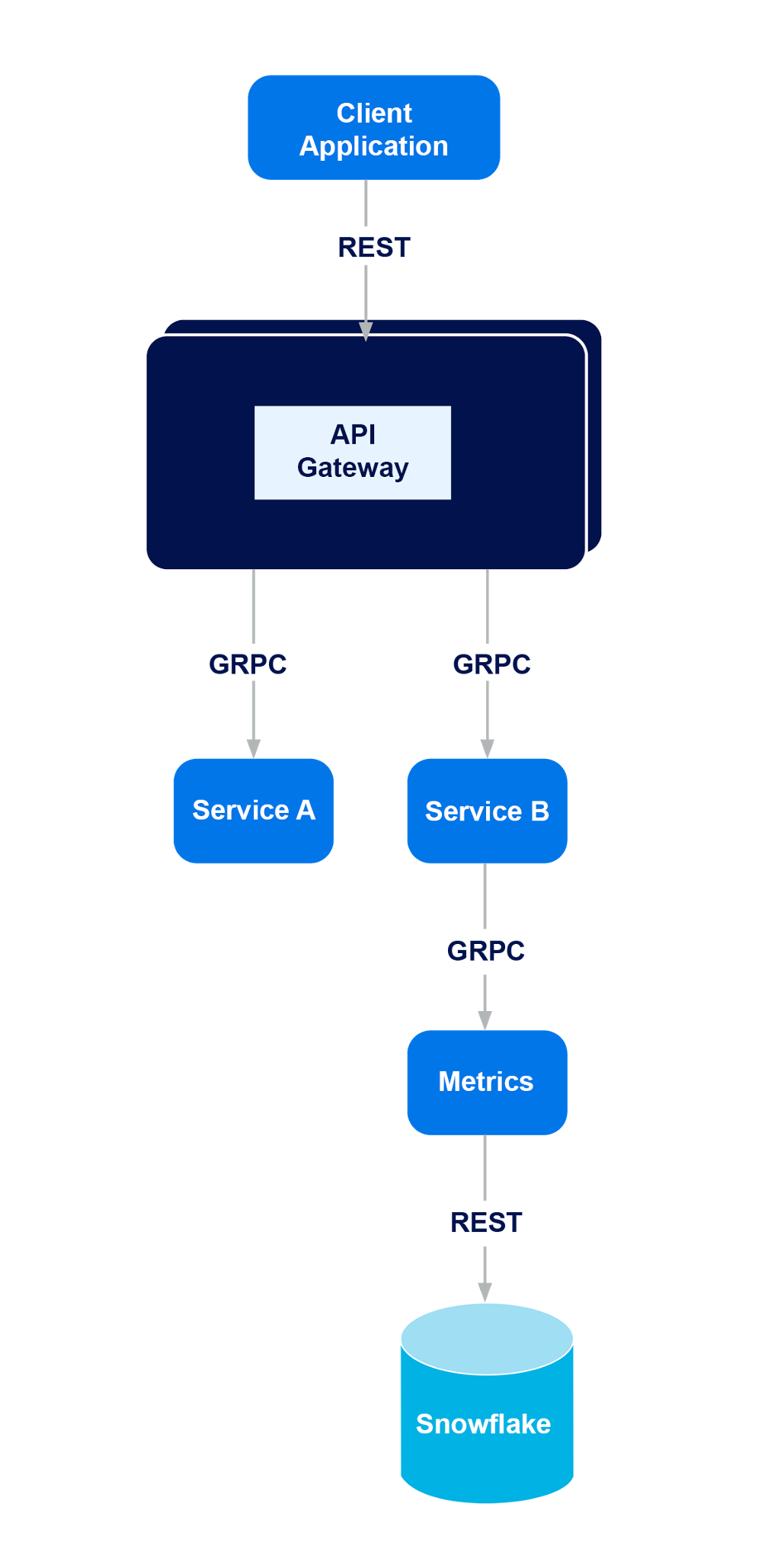
In this example, our API gateway consumes requests from upstream client applications in a format that is familiar and easy for them to use: REST.
To keep the latency of request handling low, the gateway only implements a small portion of the application behavior itself. For much of the more complex behavior of the system, the gateway processes incoming requests and produces requests for various downstream services.
These could be “microservices”, each implementing a small and discrete part of the system functionality, or they could be larger systems combining multiple operations on common data to limit time lost to network I/O. We’re going to make a few key assumptions about these services:
- These services are implemented in a variety of languages, making sharing source code between them directly a challenge. This could be because the teams developing them have different specializations, or it could be because for the different tasks being performed by the services, different languages are appropriate
- These services are also going to be communicating with each other
- These services need to share a common definition for the messages they’ll be exchanging with each other
For these, and other reasons, we’re going to assume that communication between these downstream services is performed using GRPC, a networking protocol popularized by its use within Google.
In this example, I hope it’s easy to see why we might choose to use GRPC and Protobuf over something like REST for inter-service communication: keeping message definitions in sync across different services and their associated codebases is challenging, and GRPC makes it easy for us to support this use-case.
The downside to using GRPC within our services is that when we need to send data to an external service like Snowflake, we need a way to convert that data into the external service’s native format. In this example, that’s the job of the Metrics service.
Why Kafka?
Given that our reference architecture has changed a bit since the last post, it’s worth re-examining Kafka and why we’d consider switching to it.
The key difference between this system and the previous one is the presence of the additional downstream services. This prompts 2 new reasons to consider Kafka over our existing REST + GRPC message transport:
- Downstream services have different scaling requirements, and using Kafka topics to distribute messages over instances may be easier than setting up a load balancer.
- Reliability—if a downstream service becomes unavailable, messages can be automatically picked up by other consumers in the same consumer group, rather than requiring the API Gateway to implement retry logic. If the whole service goes down, messages are not lost; they stay in the topic and can be consumed when the service returns to operation.
It’s also important that our existing services be compatible with an asynchronous communication model. Although GRPC supports a request/response communication pattern, Kafka does not, so for the purposes of this post we’re going to assume our GRPC services are already designed to work asynchronously. The same is true of the client application, as noted in the previous post.
Goal Setup
With our initial setup and motivation defined, we can start thinking about our goal setup.
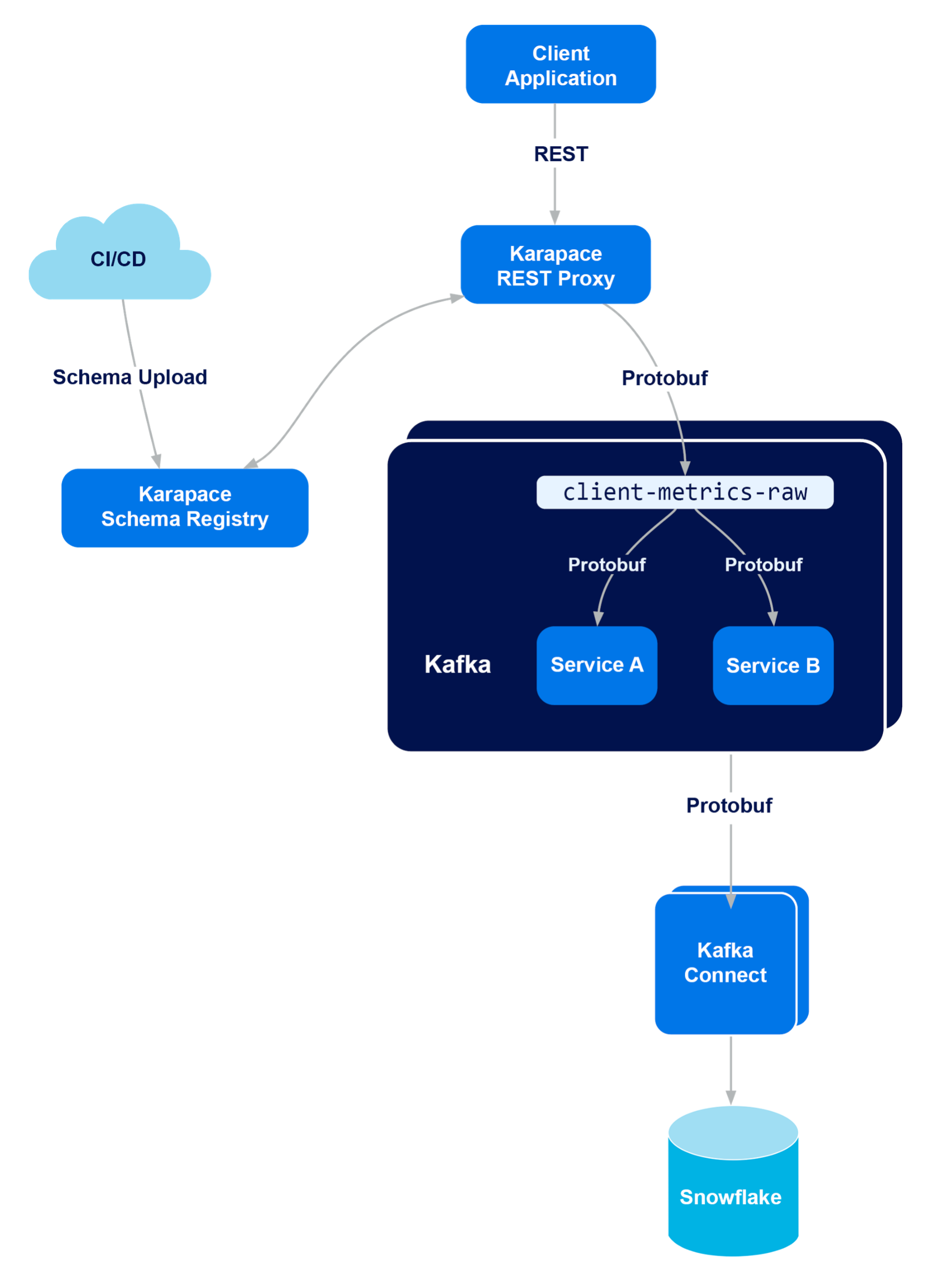
As with the previous blog, we’ll be replacing the API gateway with a combination of Kafka and Karapace REST Proxy. Downstream services will be able to receive messages by subscribing to Kafka topics, rather than by directly receiving messages via GRPC.
However, there’s a small snag here: our existing setup uses GRPC and Protocol Buffers for good reason, but the data going into Kafka is JSON! If we try to rewrite our existing GRPC services to consume this JSON instead, we’ll lose all the benefits of protocol buffers discussed above. How do we get around this problem?
Karapace Schema Registry
Actually, the solution here is pretty straightforward. In addition to providing Karapace REST proxy, Karapace provides a schema registry component, and can use schemas uploaded to that registry to translate incoming messages from JSON to one of a number of target formats, including protocol buffers.
So, we’ll work around this problem by introducing Karapace Schema Registry and uploading our Protobuf schemas to it, which will allow the REST proxy to translate incoming client messages from JSON to protocol buffers.
The running theme here is that each of the components is using tools best suited to its use case:
- The client application is using JSON and REST, technologies built-in to the client platform (a web browser or other JavaScript runtime, such as Node.js)
- Downstream services continue to use protocol buffers, avoiding the need for rewriting the codebase and leveraging the benefits of a schema-based message format
- Because the schema registry is aware of the schema, incoming JSON messages can be checked against the schema, ensuring that all messages delivered into the topic meet the schema and providing some of the benefits of using protocol buffers to client applications as well
Receiving Messages
There’s another open question here as well: in addition to providing protocol buffers as a message format, GRPC conveniently provides message transport, and can generate code for both sending and receiving messages using this transport. By adopting Kafka, we’d be stepping away from this transport layer, so we need a new way for our client applications to consume messages as well 1.
If the language used by the downstream service is a JVM language, this is an easy problem to solve. Kafka integrates seamlessly into the Java ecosystem, and those services can adopt one of a number of different libraries to consume messages from Kafka topics, such as the Kafka Consumer API or Kafka Streams.
In our case though, we’re going to make things interesting by assuming that the downstream service is implemented in a language natively supported by GRPC, but not by Kafka—Python. Fortunately, Kafka is a widely used technology and there are streaming libraries available for clients in a number of different languages. For this project, we’ll be using the Faust Streaming library to consume messages from Kafka topics.
In the end, our new system will look something like this:
First Steps
Set up a Kafka cluster with Karapace RP + SR. If you’ve already followed the previous blog, this step is almost exactly the same, except that when provisioning the cluster through the Instaclustr console, we’ll also select the options to include the Karapace Schema Registry, and to integrate the REST Proxy and Schema Registry together. This will allow the REST proxy to transform incoming REST objects into Protobuf format by using schemas provided to the schema registry.
Getting Schemas into Schema Registry
Following the instructions on the Instaclustr Console, we can take our existing .proto files and upload them to the schema registry:
|
1 2 3 4 5 6 7 8 9 10 |
curl -XPOST https://url.to.karapace.schema.registry:8085/subjects/test-key/versions \ -H "Content-Type: application/vnd.schemaregistry.v1+json" \ -H "Accept: application/vnd.kafka.v2+json, application/json" \ --data "$( echo '{ "schemaType": "PROTOBUF" }' \ | jq ".schema = $(cat proto/simple.proto | jq -R --slurp)" )" \ -u ickarapaceschema:<Password from the Instaclustr Console> |
Aside: Schema References
If your data model is complex, you might want to split out your schema definitions into multiple .proto files: some for the different message types, and others for the shared types that they all refer to. In our use case we haven’t needed to do that, so providing the whole .proto in a single invocation of curl is sufficient.
If you do need to do this though, Karapace 3.5.0 and later have support for schema references, which allow you to refer to Protobuf schemas you’ve already uploaded by passing references to them alongside the dependent schema when you upload it. The reference requires three fields:
| Field Name | Value |
| name | The name of the reference you intend to use to import it in the dependent schema (e.g. CommonTypes.proto) |
| subject | The subject under which the referenced schema was registered |
| version | The version of the referenced schema your new schema should reference |
So, if your dependent schema wants to import a file named dependency.proto, previously uploaded as version 1 of subject dependency, you will include something like:
|
1 2 3 4 5 6 7 |
{ "schemaType": "PROTOBUF", "schema": "Your protobuf schema goes here", "references": [ { "name": "dependency.proto", "subject": "dependency", "version": 1 } ] } |
Moving From GRPC to Faust-Streaming
Faust is a stream processing library for Python, which brings the ideas in Kafka Streams into the Python ecosystem.
To begin adopting Faust in our consumer services, we’ll need to change how the service starts. GRPC services are pretty self-contained, but Faust is built on top of python’s asyncio module, so we’ll need to define our consumer in terms of that library.
A minimal working example might be something like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import faust import asyncio import logging from .serde import SchemaRegistryProtobuf from .proto.edit_event_value_pb2 import EditEventValue BROKER_ENDPOINT='kafka://' # Get this from the Instaclustr Console TOPIC_NAME='wiki_updates_protobuf' async def main(): app = faust.App( 'tailer', broker=BROKER_ENDPOINT, broker_credentials=faust.SASLCredentials( username='ickafka', # Get this from the Instaclustr Console password='', # Get this from the Instaclustr Console mechanism='' # Get this from the Instaclustr Console ) ) schema = faust.Schema( key_serializer = 'raw', value_serializer = SchemaRegistryProtobuf(EditEventValue) ) topic = app.topic(TOPIC_NAME, schema=schema) @app.agent(topic) async def hello(messages): async for message in messages: print(f'Received {message}') await faust.Worker(app, loglevel=logging.INFO).start() if __name__ == '__main__': asyncio.run(main()) |
Consuming Protobuf Messages
If you’re paying close attention, you’ll notice that we’ve provided a custom value serializer to Faust. Faust supports four codecs by default: raw (used here for the message keys), json, pickle, and binary. However, it also has excellent support for custom serializers, which we’ll be using to inject the Protobuf code generated by protoc.
This leads to our first real hurdle: the messages being delivered by Kafka aren’t actually protocol buffers!
Wait, What?
So far, we’ve been working on the assumption that Karapace is going to simply read in the incoming JSON messages, fit them to the Protobuf schema we’ve provided, encode the resulting message using the Protocol Buffers wire format, and deliver it to Kafka. It turns out that this assumption is a little naive, and not actually correct.
All our thinking so far has been about reading messages into our services via the REST proxy. But the proxy works in both directions: you can create consumers with it, and if you ask it nicely it will also translate messages back from protocol buffers into JSON so that client applications can leverage their existing JSON support, just as we did on the ingestion route earlier. However, to make this possible, the proxy needs to be able to identify the schema that should be used to decode each outbound message. And to facilitate this, the REST proxy attaches a short header to the front of every message that it ingests.
So, the messages being delivered along our Kafka topics are in the Protobuf wire format— but they’ve got an additional header at the front. If we want to be able to parse these messages using our existing Protobuf schemas, we’ll need to strip this header away first.
Fortunately implementing this isn’t too difficult—the full implementation of the decoder used above fits into 30 lines of Python, and reads as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
from faust.serializers import codecs from typing import Any from logging import error from google.protobuf.internal.decoder import _VarintDecoder as MakeVarintDecoder DecodeVarint = MakeVarintDecoder(0xff, int) class SchemaRegistryProtobuf(codecs.Codec): def __init__(self, proto): self._proto = proto super(self.__class__, self).__init__() def _dumps(self, obj: Any) -> bytes: # For this example, we're only considering consuming messages, so we don't need # an implementation here. # In a production service though, you'd likely need to implement this using an # inversion of the implementation of `_loads` below. pass def _loads(self, s: bytes) -> Any: offset = 4 magic = bytes.fromhex('00 00 00 00') if s[:offset] != magic: error(f'Expected null byte magic to match {magic.hex()}, got {s[:offset].hex()}') schema_id, offset = DecodeVarint(s, offset) type_index, offset = DecodeVarint(s, offset) result = self._proto(); result.ParseFromString(s[offset:]) return result |
With the addition of this decoder, we’re now able to:
- Push Protobuf messages into Kafka via Karapace REST Proxy
- Rely on Karapace Schema Registry to translate between the 2 message formats, producing Protobuf + Schema Header messages
- Consume these messages in our existing downstream services, leaving business logic largely unchanged
Importantly, all the changes we’ve made to the downstream services are at the edge of the service. Assuming these services are using protocol buffers as their main data representation, none of the rest of their implementation has to change!
Consuming Protobuf Messages with Snowflake
Now that we’ve migrated the downstream services, let’s talk about Snowflake. As in the last post, we’re going to be using Kafka Connect to get data out of Kafka and into Snowflake. In this case the process is a bit different though, because our internal services use GRPC/Protobuf.
We could continue using our existing metrics service, whose job in the initial setup was to collect GRPC inputs from internal services, translate that data to JSON, and send it to Snowflake. However, because we’re adopting Kafka, we get to leverage the same Kafka Connect plugin that we used in the previous blog post, allowing us to drop a service from our implementation!
Snowflake provides a community version of their protobuf converter, which we’ll be using here to funnel data from Kafka into Snowflake. This process is very similar to the one we followed in the previous post, so I’m going to discuss only the changes in the process here.
The biggest change is that in addition to downloading the Kafka Connect plugin from Maven, we’re going to have to build the Protobuf converter and upload it to AWS S3 as well. We do this so that we can compile in the classes generated by protoc, and also so that we can patch the decoder class to process the schema information header we encountered above.
As with the Python example above, the Java decoder is fairly simple but could be extended to include features that make use of the header information if that fits your use case. The relevant changes are in the methods of the ProtobufConverter class.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
import com.google.protobuf.CodedInputStream; public class ProtobufConverter implements Converter { // ... @Override public byte[] fromConnectData(String topic, Schema schema, Object value) { if (protobufData == null || schema == null || value == null) { return null; } // I've hardcoded this in, but in a production application we'd // be uploading the expected schema here and using the resulting // schema id (0x02 here) and type index (0x00 here). byte[] dummyHeader = { 0x00, 0x00, 0x00, 0x00, 0x02, 0x00 }; byte[] valueBytes = protobufData.fromConnectData(value); byte[] result = new byte[dummyHeader.length + valueBytes.length]; System.arraycopy(dummyHeader, 0, result, 0, dummyHeader.length); System.arraycopy(valueBytes, 0, result, dummyHeader.length, valueBytes.length); return result; } @Override public SchemaAndValue toConnectData(String topic, byte[] value) { if (protobufData == null || value == null) { return SchemaAndValue.NULL; } // Check that the Schema Registry null-bytes are present if ((value[0] | value[1] | value[2] | value[3]) != 0) { return SchemaAndValue.NULL; } // Bytes from the start of the buffer from which we will read the next value int offset = 4; CodedInputStream istream = CodedInputStream.newInstance(value, offset, value.length - offset); try { final int schemaId = istream.readRawVarint32(); final int typeIndexCount = istream.readRawVarint32(); if (typeIndexCount != 0) { final int[] typeIndices = new int[typeIndexCount]; for (int i = 0; i < typeIndexCount; i++) { typeIndices[i] = istream.readRawVarint32(); } } offset += istream.getTotalBytesRead(); // If you wanted to e.g. pull the schema from the registry and compile // the proto classes dynamically, you could do that here. // In our case though, we're going to only handle the case in which // the received message is forward-compatible with the compiled-in schema return protobufData.toConnectData(Arrays.copyOfRange(value, offset, value.length)); } catch (IOException e) { return SchemaAndValue.NULL; } } } |
As you can see, using Google’s Protobuf libraries makes parsing the header relatively straightforward. With this patch in place, all that remains is to configure the Kafka Connect plugin to use the right value converter by specifying the value.converter and value.converter.protoClassName properties:
|
1 2 3 4 5 6 7 8 |
{ // ... "key.converter": "org.apache.kafka.connect.storage.StringConverter", "value.converter": "com.blueapron.connect.protobuf.ProtobufConverter", // This will vary depending on what package you put your Protobuf classes in "value.converter.protoClassName": "proto.EditEventValueOuterClass$EditEventValue" } |
Conclusion
In this example, we extended our previous migration of a simple metrics shipping API from an existing custom API server to Kafka. We continued to use Karapace REST Proxy and Kafka connect to assist with data ingress and egress, and extended the example to consider internal services using GRPC and Protocol Buffers for inter-service communication.
We showed how to use Karapace Schema Registry to allow these internal services to continue using their existing Protobuf message definitions, allowing them to continue using the bulk of their business logic implementation without needing to change their data model. We showed how to implement a simple service for consuming Protobuf data from Kafka using Faust Streaming, and discussed the process of adding Snowflake’s Protobuf decoder to our system to avoid running a transcoding service ourselves. Finally, we also discussed the problem of decoding schema information from Protobuf messages encoded by Karapace REST Proxy. We showed 2 examples of decoding this information, allowing us to connect our Faust Streaming services and Kafka Connect Snowflake plugin to our topics containing data written by Karapace.
There’s a lot more to discuss here, and the solution space for this kind of problem is rapidly evolving. In particular, we recently added support for Karapace 3.6.2 on our managed platform, which improves the deployment experience for Protobuf message schemas in Karapace Schema Registry by allowing uploaded schemas to refer to each other naturally via import statements, just as they would in a normal Protobuf code generation step.
Finally, it’s worth noting that while we’ve been discussing protocol buffers in this post, Karapace also has first-class support for Apache Avro and JSON schemas. If you’ve got existing services using those message formats, you should also be able to leverage Karapace Schema Registry to translate incoming JSON objects using those schemas, just as we did with protocol buffers in this example.
If you’re already using these technologies and would like to try using them within the Kafka ecosystem, Instaclustr’s Managed Platform makes it simple and easy to deploy Kafka, Karapace, and Kafka Connect and have an application up and running in minutes. If you’re interested in reading more, we have further examples on deploying and using Karapace Schema Registry in our support documentation.