What is DataStax Astra DB?
DataStax Astra DB is a fully managed database-as-a-service built on Apache Cassandra, supporting modern, data-intensive applications. It simplifies development by offering a cloud-native platform that reduces operational overhead through automation and intuitive APIs. Astra DB is intended for generative AI use cases, with vector search and integration with AI development tools.
Astra DB supports scalable, secure, and high-performance data operations, making it suitable for mission-critical applications that handle petabytes of data. Developers can focus on building applications without worrying about infrastructure complexity, relying on features like multi-region deployment and automated backups.
This is part of a series of articles about DataStax
IBM acquires DataStax
In May, 2025, IBM acquired DataStax to strengthen its position in the NoSQL market. For existing DataStax customers, the acquisition introduces uncertainty, with potential changes in product direction, pricing models, and support structure.
While the deal could bring benefits such as tighter integration with IBM’s cloud offerings and enhanced R&D resources, it may also lead to shifts in roadmap priorities that favor IBM’s platform. This could be a concern for customers seeking a cloud-agnostic approach or those wary of vendor lock-in.
During this transition, customers should closely monitor updates from IBM and DataStax regarding platform compatibility, SLAs, and future development plans. While the long-term impact remains to be seen, organizations dependent on Astra DB or other DataStax offerings should evaluate their strategic fit in light of IBM’s cloud-first orientation.
Related content: Read our guide to DataStax Cassandra
Key features of DataStax Astra DB
Here are the key features that make DataStax Astra DB a strong choice for building scalable, AI-driven applications:
- Data API: Provides a simplified interface for developers, allowing access to the full capabilities of Astra DB without complex data modeling. It supports multiple languages including Python, TypeScript, and Java.
- Built-in vector search: Enables AI applications to store and query vector embeddings natively, making it easier to build real-time AI agents and generative AI features.
- Scalability and performance: Capable of scaling to petabytes of data while maintaining high performance, making it suitable for demanding workloads.
- Operational automation: Features like automated backup, restore, and cloning reduce the need for manual operations and lower the risk of human error.
- Multi-region deployment: Supports deployment across multiple regions, increasing fault tolerance and availability for production environments.
- Developer tool integration: Works with popular tools such as GitHub, Vertex AI, and Vercel to streamline development and deployment workflows.
- Langflow integration: Allows developers to experiment with different LLMs, embedding modes, and retrievers in a secure, hosted environment with no setup required.
- Zero-downtime migration: Includes migration tools that support phased rollouts and rollback, ensuring safer transitions from other systems.
Understanding DataStax Astra DB pricing
DataStax Astra DB offers flexible pricing across three main tiers: Free, Pay As You Go, and Enterprise. Each tier matches different usage needs, from experimentation to large-scale production workloads.
Free tier
The Free plan gives developers a risk-free way to explore Astra DB. It includes up to 80 GB of storage and 20 million read/write operations per month, covered by a $25 monthly credit. It supports GraphQL, REST, and JSON APIs, as well as a zero-ops Cassandra-compatible backend. Support is limited to chat and community channels.
Pay as you go
This model is usage-based and scales with application demand. Users pay per operation and per GB of storage or transfer, with no upfront commitment. The service supports multi-region deployments, private networking, and includes the option to upgrade to 24×7 Enterprise Support with a prepaid commitment. Pricing varies by cloud provider (AWS, Google Cloud, or Azure) and region (Americas, EMEA, or APAC). For example, on AWS in the Americas region:
- Write request units: $0.62 per 1M
- Read request units: $0.37 per 1M
- Storage: $0.25 per GB/month
- Internet data transfer: $0.11 per GB
Costs differ slightly across clouds and regions. For example, Google Cloud write units in EMEA are $0.64 per 1M, while Microsoft Azure write units in the same region are $0.69 per 1M.
Enterprise plan
For high-scale and mission-critical deployments, the Enterprise plan offers custom pricing with volume discounts based on annual usage commitments. It includes 24×7 support, advanced health checks, and the option to add Premium Support for faster response times. The Enterprise model also supports a provisioned capacity consumption approach, enabling predictable cost planning for large organizations.
Related content: Read our guide to DataStax competitors
Tutorial: Getting started with Astra DB
This tutorial walks through the basic steps to create a vector-enabled database in Astra DB, insert data with automatic embedding, and perform a vector search. It uses Python and the Astra Data API.
1. Create a vector-enabled database
Sign in to the Astra Portal and click Databases > Create Database. Use the following settings:
- Deployment type: Serverless (Vector)
- Cloud provider: Amazon Web Services
- Region:
us-east-2
Click Create Database and wait for it to reach Active status.
Once active, go to Database Details and:
- Copy the API endpoint
- Click Generate Token and copy the token
Store both values as environment variables:
|
1 2 |
export ASTRA_DB_API_ENDPOINT=your_api_endpoint export ASTRA_DB_APPLICATION_TOKEN=your_application_token |

2. Install the client and connect
Ensure Python 3.9+ and pip 23.0+ are installed. Then install the Astra DB Python client:
|
1 |
pip install astrapy==1.5.2 |
2. Create a file quickstart_connect.py to define a connection function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import os from astrapy import DataAPIClient def connect_to_database(): endpoint = os.environ.get("ASTRA_DB_API_ENDPOINT") token = os.environ.get("ASTRA_DB_APPLICATION_TOKEN") if not token or not endpoint: raise RuntimeError("Missing required environment variables") client = DataAPIClient(token) database = client.get_database(endpoint) print(f"Connected to database {database.info().name}") return database |
3. Insert sample data and generate embeddings
Download the sample file quickstart_dataset.json, which contains a list of book records.
Next, create a script quickstart_upload.py to create a vector-enabled collection and upload the data:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
from quickstart_connect import connect_to_database from astrapy.constants import VectorMetric from astrapy.info import CollectionVectorServiceOptions import json def create_collection(database, name): return database.create_collection( name, metric=VectorMetric.COSINE, service=CollectionVectorServiceOptions( provider="nvidia", model_name="NV-Embed-QA" ) ) def upload_json_data(collection, data_path): with open(data_path, "r", encoding="utf8") as file: json_data = json.load(file) documents = [ { **doc, "$vectorize": f"summary: {doc['summary']} | genres: {', '.join(doc['genres'])}" } for doc in json_data ] result = collection.insert_many(documents) print(f"Inserted {len(result.inserted_ids)} items.") def main(): db = connect_to_database() collection = create_collection(db, "quickstart_collection") upload_json_data(collection, "PATH_TO_DATA_FILE") if __name__ == "__main__": main() |
Replace "PATH_TO_DATA_FILE" with the path to the downloaded JSON file. You can upload data to Astra DB using the following command:
|
1 |
python quickstart_upload.py |

4. Perform a vector search
After inserting the data, you can run searches using traditional filters and vector search. Create a script quickstart_find.py:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from quickstart_connect import connect_to_database def main(): db = connect_to_database() collection = db.get_collection("quickstart_collection") print("\nBooks with rating > 4.5:") for doc in collection.find({"rating": {"$gt": 4.5}}): print(f"{doc['title']} - Rating: {doc['rating']}") print("\nClosest match to 'A scary novel':") result = collection.find_one({}, sort={"$vectorize": "A romantic novel"}) print(f"{result['title']} is a romantic novel") print("\nTop 3 books set in the arctic with >300 pages:") for doc in collection.find( {"numberOfPages": {"$gt": 300}}, sort={"$vectorize": "A book set in Renaissance Europe"}, limit=3, projection={"title": True, "author": True} ): print(doc) if __name__ == "__main__": main() |
You can run vector search using the following command:
|
1 |
python quickstart_find.py |
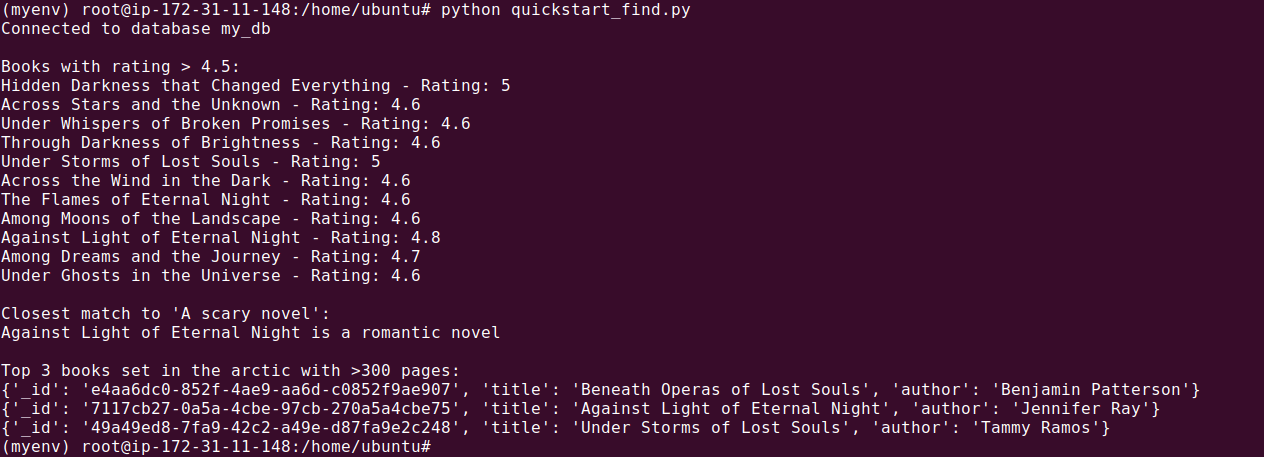
Make sure the collection name matches the one used in the upload script.
Datastax Astra DB limitations
Despite its capabilities, Astra DB has some limitations users should be aware of. These limitations were reported by users on the G2 platform:
- Steep learning curve: While user-friendly on the surface, mastering Astra DB’s features and optimizing performance can take time, especially for users new to Cassandra or distributed systems.
- Limited analytics support: Data ingestion and retrieval for analytics use cases need improvement. The current setup can be inefficient for large-scale analytical workloads.
- Operational overhead: Even though Astra is managed, running distributed Cassandra clusters may still require significant operational expertise, especially for scaling and tuning performance.
- Query model constraints: Due to Cassandra’s design, queries are tightly coupled with the data model. Developers must define primary keys and query paths in advance, limiting flexibility and requiring careful schema planning.
- Lack of transactional guarantees: Astra DB, like Cassandra, doesn’t support full ACID transactions or joins. Its eventual consistency model may not be suitable for use cases requiring strict consistency.
- Monitoring and observability gaps: The platform currently lacks advanced, customizable monitoring and observability features that enterprise teams often rely on.
- Refined security controls: Astra DB does not yet support fine-grained role-based access control (RBAC) or advanced network security configurations.
- Tutorial limitations: Official tutorials may not match all development workflows. Users often need to rework their data ingestion pipelines to align with query patterns demonstrated in documentation.
- Fewer no-code integrations: Compared to platforms like Make.com or n8n, Astra DB has fewer no-code tool integrations.
- Slow startup time: Initial setup and cold-start latency can be slow, particularly for vector-enabled features.
- High cost at scale: Running Astra DB for large workloads can become expensive, especially in multi-region setups or when relying on enterprise-tier support and storage.
Related content: Read our guide to Datastax competitors (coming soon)
Comparing options for managing Apache Cassandra
Instaclustr is a fully managed open source solution that offers a unified approach to optimizing every facet of data infrastructure, streamlining the process and enhancing the data ecosystem. Here is a brief comparison of Instaclustr and IBM DataStax for managing Apache Cassandra:
Fully open source for freedom and flexibility
- Instaclustr is 100% committed to open source technology. Unlike proprietary software options, Instaclustr ensures freedom from vendor lock-in, providing full control and flexibility over data infrastructure.
- IBM DataStax combines proprietary systems with open source technologies, which may limit customization and scale.
Expert support and management
- Instaclustr’s focus is on delivering fully managed, open source solutions like Apache Cassandra, Kafka, PostgreSQL, Valkey, OpenSearch and ClickHouse.
- IBM DataStax support is limited to Apache Cassandra.
Simplified pricing model
- Instaclustr offers transparent, predictable pricing without hidden fees or complicated licensing agreements.
- IBM DataStax, licensing and integration costs can add layers of complexity that may hurt the bottom line.
Seamless scaling
- Instaclustr’s scalable, fully managed solutions are built to grow with your business seamlessly.
- A fully open source model means scalability without the added restrictions or costs that often come with proprietary offerings like IBM DataStax.
Commitment to innovation
- Instaclustr is deeply aligned with ongoing advancements in the open source community, ensuring that customers benefit from the latest innovations.
- IBM DataStax balances proprietary development with open source, which can sometimes mean slower adoption of cutting-edge trends in open source technologies.
Instaclustr specializes in making open source operate seamlessly for businesses. Instaclustr frees organizations from the complexities of proprietary systems, maximizes open source investments, providing exceptional, stress-free support at every step.
For more information: