What is Apache Kafka?
Apache Kafka is a distributed event streaming platform for high-throughput, fault-tolerant, and scalable data streaming. It enables real-time data processing by allowing applications to publish, subscribe to, store, and process streams of records in a distributed manner.
Kafka consists of key components:
- Producers send data (events) to Kafka topics.
- Brokers store and manage data streams.
- Consumers read and process data from topics.
- Apache ZooKeeper™ manages cluster coordination and leader election; however, ZooKeeper will soon be replaced with KRaft-based clusters.
Kafka is commonly deployed via containers. Docker is a popular containerization platform that makes it possible to package Kafka in a container, which includes all the dependencies it needs to run, making it easy to deploy in diverse environments.
This is part of a series of articles about Apache Kafka
What is Docker?
Docker is an open source platform that automates application deployment using containerization. It packages applications and their dependencies into lightweight, portable containers that run consistently across different environments.
Key components of Docker include:
- Docker Engine: The runtime that builds and runs containers.
- Docker Images: Pre-configured templates containing the application and dependencies.
- Docker Containers: Running instances of Docker images.
- Docker Compose: A tool for defining and managing multi-container applications.
Docker ensures applications run the same way in development, testing, and production environments. It is widely used for microservices, DevOps workflows, and cloud-native development.
Getting started with Apache Kafka on Docker
Install Docker
To install Docker on Ubuntu, follow these steps:
- Update the package index
1sudo apt-get update
![Apache Kafka Docker tutorial screenshot]()
- Install required dependencies
1sudo apt-get install ca-certificates curl gnupg
![Apache Kafka Docker tutorial screenshot]()
- Add Docker’s official GPG key
1234sudo install -m 0755 -d /etc/apt/keyringscurl -fsSL https://download.docker.com/linux/ubuntu/gpg |sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.ascsudo chmod a+r /etc/apt/keyrings/docker.asc
![Apache Kafka Docker tutorial screenshot]()
- Set up the repository
1234echo \"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \$(. /etc/os-release && echo "${UBUNTU_CODENAME:-$VERSION_CODENAME}") stable" | \sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
![Apache Kafka Docker tutorial screenshot]()
- Update the package index again
1sudo apt-get update
![Apache Kafka Docker tutorial screenshot]()
- Install Docker Engine, CLI, and containerd
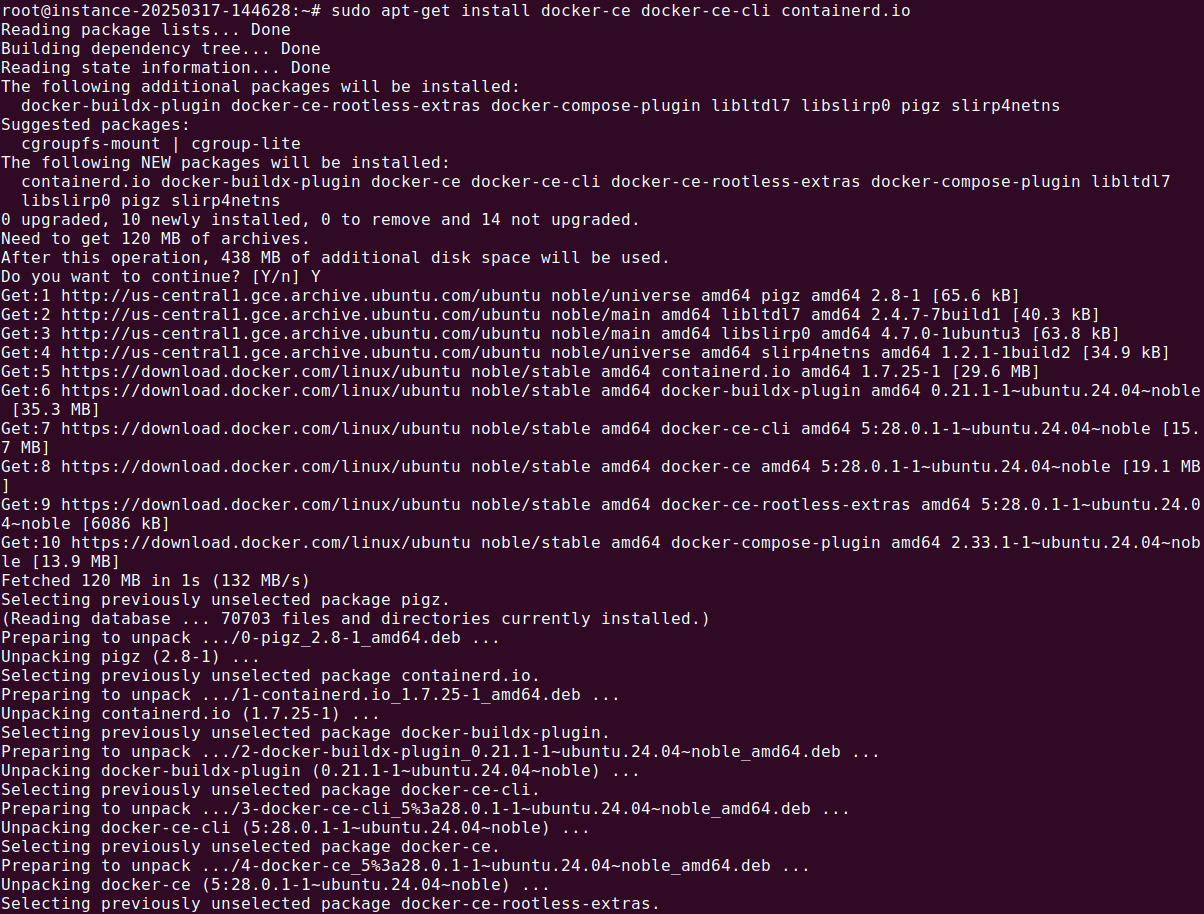
1sudo apt-get install docker-ce docker-ce-cli containerd.io
![Apache Kafka Docker tutorial screenshot]()
- Verify the installation: Run the following command to check if Docker is installed correctly:
1docker --version
It should return an output like:
1docker version X.Y.Z, build ABCD123![Apache Kafka Docker tutorial screenshot]()






By default, Docker is installed at /usr/bin/docker, and the service should start automatically. If needed, you can start it manually using:
|
1 |
sudo systemctl start docker |
To enable it to start on boot:
|
1 |
sudo systemctl enable docker |

Installing Docker Compose
To install Docker Compose, you need to set up the appropriate repository and install the package based on your operating system.
- Install on Ubuntu and Debian
- First, update the package index:
1sudo apt-get update
- Then, install the Docker Compose plugin:
1sudo apt-get install docker-compose-plugin && apt-get install docker-compose
![Apache Kafka Docker tutorial screenshot]()
- First, update the package index:
- Install on RPM-based distributions (CentOS, Fedor, RHEL, SLES)
- Update the system packages
1sudo yum update
- Then, install Docker Compose:
1sudo yum install docker-compose-plugin
- Update the system packages
- Verify installation
- After installation, check that Docker Compose is installed correctly by running:
1docker-compose version - This command should return an output similar to:
1docker-compose version vN.N.N![Apache Kafka Docker tutorial screenshot]()
Replace
vN.N.Nwith the installed version number.
- After installation, check that Docker Compose is installed correctly by running:


Run Kafka with Docker
To set up Kafka using Docker, you need a docker-compose.yml file that defines the necessary services, including ZooKeeper and a Kafka broker. Instead of writing the configuration manually, you can use a pre-configured setup:
- Clone the Kafka Docker project from GitHub:
1git clone https://github.com/conduktor/kafka-stack-docker-compose.git
![Apache Kafka Docker tutorial screenshot]()
- Navigate into the cloned directory and list the available files:
12cd kafka-stack-docker-composels -l
![Apache Kafka Docker tutorial screenshot]()
You’ll find multiple configuration files, includingzk-single-kafka-single.yml, which sets up a single ZooKeeper instance and one Kafka broker. - Start the Kafka cluster using Docker Compose:
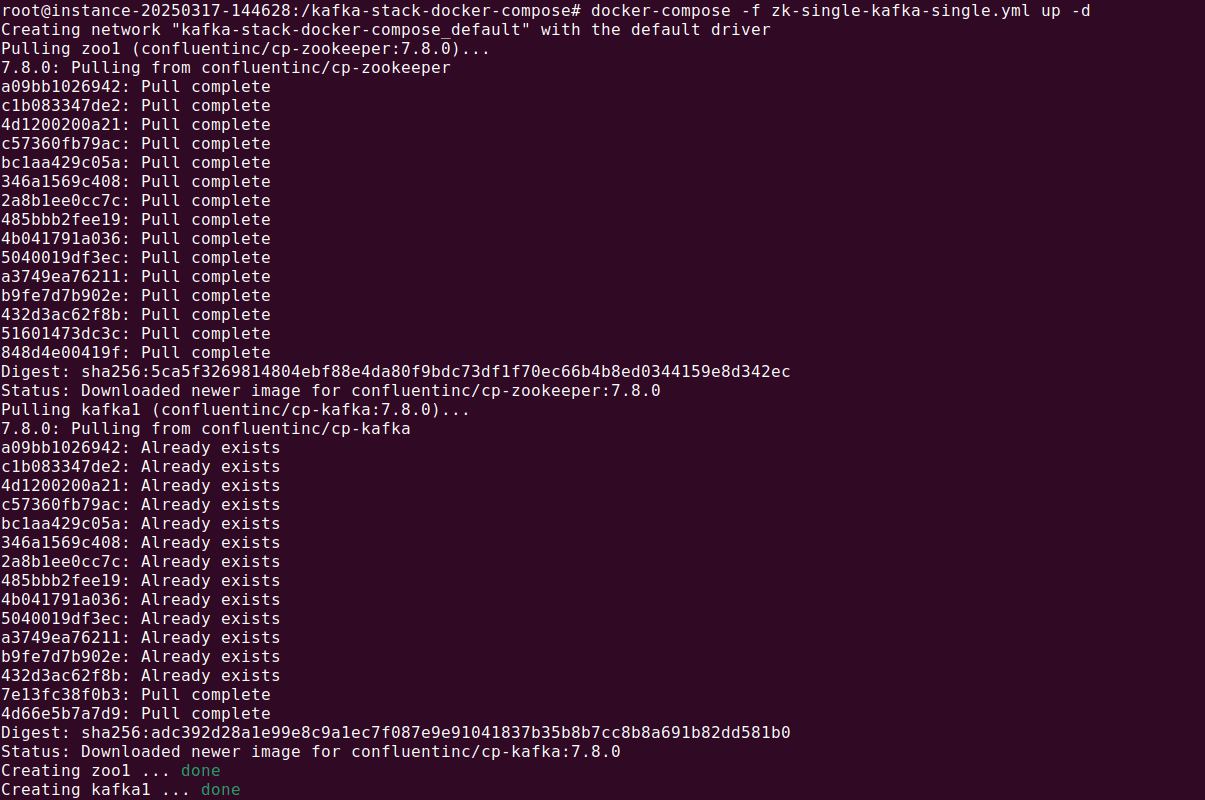
1docker-compose -f zk-single-kafka-single.yml up -d
![Apache Kafka Docker tutorial screenshot]()
The-dflag runs the containers in the background. - Verify that the services are running:
1docker-compose -f zk-single-kafka-single.yml ps
![Apache Kafka Docker tutorial screenshot]()
You should see both Kafka and ZooKeeper in a running state. Kafka will be accessible atlocalhost:9092.



Running commands
Once Kafka is running, you can interact with it using Kafka commands. There are two ways to execute commands:
From inside the Kafka container:
|
1 |
docker exec -it kafka1 /bin/bash |
Inside the container, you can run Kafka commands directly:
|
1 |
kafka-topics --version |

From the host machine
To run Kafka commands outside the container, install Java and Kafka binaries on your system:
Once installed, you can use Kafka commands such as:
|
1 |
kafka-topics.sh |
Stopping Kafka on Docker
To stop the running Kafka services, use:
|
1 |
docker-compose -f zk-single-kafka-single.yml stop |

To completely remove all containers and resources, use:
|
1 |
docker-compose -f zk-single-kafka-single.yml down |

Related content: Read our guide to Apache Kafka tutorial
5 Best practices for running Kafka with Docker
Here are some useful practices to run Kafka efficiently and reliably in a Docker environment.
1. Utilize official Docker images
Always use the official Docker images for Kafka and ZooKeeper provided by Apache. These images are well-maintained, regularly updated, and tested for compatibility with the latest Kafka versions. Using third-party images may introduce security risks, compatibility issues, or lack of proper support.
For Apache’s official image:
|
1 |
docker pull apache/kafka |
Using verified images ensures stability and simplifies maintenance.
2. Configure listeners and advertised listeners
Kafka clients need to know how to connect to the broker, both from within Docker and externally. Improper listener configuration can cause connection issues, especially when running Kafka in a containerized environment.
Define KAFKA_LISTENERS and KAFKA_ADVERTISED_LISTENERS properly in your docker-compose.yml file:
|
1 2 3 |
environment: KAFKA_LISTENERS: PLAINTEXT://:9092 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092 |
For multi-container deployments, use proper DNS resolution to ensure the advertised listeners reflect the correct hostnames accessible by clients.
3. Implement data persistence
By default, Kafka stores data in /var/lib/kafka/data inside the container. If containers are restarted without persistent storage, all messages will be lost. To ensure data durability, mount a volume:
|
1 2 |
volumes: - kafka_data:/var/lib/kafka/data |
Define this volume in docker-compose.yml:
|
1 2 |
volumes: kafka_data: |
This setup prevents data loss in case of container restarts or upgrades.
4. Secure network configurations
Kafka should not expose open ports unnecessarily. Use Docker’s network configuration to restrict access:
Place Kafka and ZooKeeper in a dedicated Docker network:
|
1 |
docker network create kafka-net |
Define the network in docker-compose.yml:
|
1 2 3 |
networks: default: name: kafka-net |
Use authentication and encryption (SASL, SSL) for securing Kafka traffic in production.
5. Monitor resource allocation
Kafka can be resource-intensive. Running it in Docker requires monitoring CPU, memory, and disk usage to prevent performance degradation. Use Docker’s built-in monitoring tools:
Check container resource usage:
|
1 |
docker stats kafka1 |
Use Prometheus and Grafana for advanced monitoring:
|
1 2 3 4 5 |
services: prometheus: image: prom/prometheus ports: - "9090:9090" |
Adjust JVM heap size (KAFKA_HEAP_OPTS) in docker-compose.yml to optimize performance:
|
1 2 |
environment: KAFKA_HEAP_OPTS: "-Xmx1G -Xms1G" |
Learn more in our detailed guide to Apache Kafka use cases
Maximize Kafka’s power with Instaclustr
Apache Kafka is a phenomenal tool for building real-time data pipelines and streaming applications, but effectively managing and scaling Kafka can be a daunting challenge. That’s where Instaclustr for Apache Kafka steps in, making your Kafka experience seamless, efficient, and worry-free.
Instaclustr offers a fully-managed Kafka service, handling everything from deployment to ongoing performance optimization. By taking care of Kafka’s complexity, it lets businesses focus on what truly matters—extracting value from their data. This includes automated monitoring, patches, and updates, saving your team time and reducing operational burdens. The result? A robust streaming platform you can depend on without the headaches of managing it in-house.
Built for reliability and scalability
With Instaclustr for Apache Kafka, you get an environment built for reliability and high availability. Their managed service runs on fault-tolerant infrastructure with built-in replication, ensuring that your data streams are always available, even during unexpected disruptions. And when your business grows, scaling your Kafka cluster becomes effortless, with Instaclustr’s expert team offering guidance to optimize performance.
Open source freedom with enterprise-grade security
Instaclustr is committed to open-source technology, giving you vendor-neutral flexibility and avoiding lock-in. At the same time, security is never compromised. Instaclustr for Kafka is equipped with enterprise-grade security features, including encryption, role-based access controls, and compliance with industry standards.
Switching to Instaclustr for Apache Kafka means more than just outsourcing management; it’s about empowering your team with a reliable, scalable, and efficient streaming solution. Simplify your Kafka operations, and take your data-driven initiatives to the next level with a trusted partner by your side.
For more information: