How Is OpenSearch used for vector search?
OpenSearch is an open source big data solution, typically used in scenarios including log monitoring, infrastructure observability, and enterprise search. It is often chosen as an open source alternative to Elasticsearch.
OpenSearch provides robust capabilities for vector search, enabling the storage, indexing, and search of high-dimensional vector embeddings. This functionality is crucial for modern AI and machine learning applications that rely on similarity-based retrieval, such as semantic search, recommendation systems, and Retrieval-Augmented Generation (RAG).
Key aspects of OpenSearch vector search include:
- Vector Engine: OpenSearch incorporates a dedicated Vector Engine designed for efficient handling of vector data. This engine supports various vector search algorithms and index configurations to optimize performance for different use cases.
- k-Nearest Neighbors (k-NN): A core feature of OpenSearch’s vector search is its k-NN plugin, which allows for finding the ‘k’ most similar vectors to a given query vector. This is fundamental for similarity search operations.
- Radial search: OpenSearch also supports vector radial search, which enables searches based on distance or score thresholds, offering greater flexibility in defining search criteria.
- Integration with ML models: The Vector Engine is designed to integrate with machine learning models, allowing for the storage and retrieval of model embeddings generated from various data types (text, images, audio).
- Scalability and performance: OpenSearch is built for scalability, capable of handling billions of vectors and supporting real-time search operations. It offers options like UltraWarm and Cold tiers for cost-effective storage of less frequently accessed vector data.
- GPU acceleration (preview): OpenSearch is actively developing GPU acceleration for its Vector Engine, leveraging technologies like NVIDIA cuVS to significantly reduce index building time and improve performance for large-scale vector workloads
This is part of a series of articles about OpenSearch
How vector search works in OpenSearch
OpenSearch supports vector search through Vector Engine, a component that handles unstructured and high-dimensional data using numerical embeddings. These embeddings are representations of data such as text, images, or audio that allow machine learning models to compare items based on semantic similarity rather than exact matches.
The engine enables similarity searches using algorithms like k-nearest neighbors (k-NN), making it suitable for use cases such as recommendation systems, anomaly detection, and natural language applications. By comparing embeddings, OpenSearch can retrieve results that are contextually relevant, not just syntactically similar.
Embeddings can be indexed and stored alongside traditional data, allowing for hybrid search strategies that combine vector-based and keyword-based retrieval. The system supports multiple AI-focused search paradigms including semantic, multimodal, sparse vector, and hybrid search with score normalization.
OpenSearch Vector Engine is also optimized for scalability. It supports real-time ingestion and indexing of data from multiple sources and integrates with large language models (LLMs), enabling its use in generative AI workflows such as retrieval-augmented generation (RAG). With built-in support for ingest pipelines and a flexible query DSL, developers can efficiently process, transform, and search data at scale.
Learn more in our detailed guide to OpenSearch architecture
Tips from the expert
Kassian Wren
Open Source Technology Evangelist
Kassian Wren is an Open Source Technology Evangelist specializing in OpenSearch. They are known for their expertise in developing and promoting open-source technologies, and have contributed significantly to the OpenSearch community through talks, events, and educational content
In my experience, here are tips that can help you better productionize OpenSearch vector search:
- Shard and route for vector locality: Don’t rely on round-robin routing. Learn coarse clusters (e.g., k-means on embeddings) and use the cluster ID, tenant, or region as a routing key so nearest neighbors co-locate on fewer shards—cutting fan-out and tail latency.
- Align metric and preprocessing up front: If you score with cosine, store unit-normalized embeddings and enforce normalization at ingest to avoid per-query math. For dot-product/inner-product, keep magnitude; for L2, ensure consistent scaling. Mismatches here silently wreck recall.
- Use two-stage retrieval with deterministic rerank: First get a generous candidate set via ANN (k ≫ final N). Then rerank those IDs with an exact distance + business features (freshness, permissions) in a second pass. This preserves recall while letting you express domain relevance cleanly.
- Push filters before vectors, not after: Structure queries so hard filters (tenant, language, time range, ACL) execute before ANN. Keep the candidate pool small and relevant; tune k/candidate count per filter selectivity rather than using a one-size-fits-all value.
- Control segment/merge behavior for k-NN stability: Frequent merges mean frequent graph rebuilds and volatile latency. For read-mostly indices, raise
refresh_interval, throttle merges, and force-merge immutable indices to a low segment count so vectors live on stable, few segments.
Tutorial: Getting started with vector search in OpenSearch
To experiment with vector search, you first need an OpenSearch cluster running. Once installed, you can create an index, add sample data, and run a similarity query. The example below demonstrates the workflow using two-dimensional vectors for hotel locations, but the same steps apply to higher-dimensional vectors used in semantic or multimodal search.
These instructions are adapted from the OpenSearch documentation.
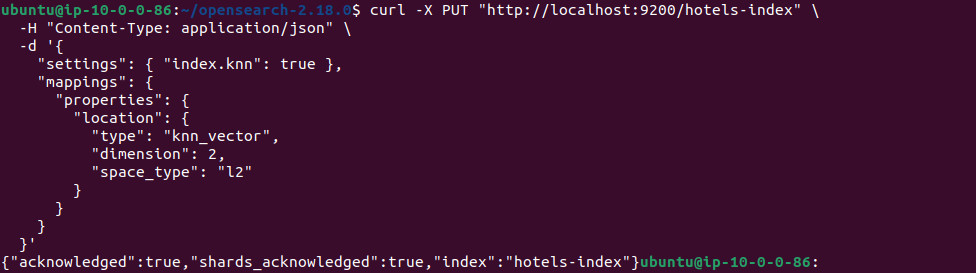
Step 1: Create a vector index
Define a new index and enable vector search by setting index.knn to true. Add a knn_vector field to store embeddings, specifying its dimension and similarity metric. In this example, the field is named location, with two dimensions and Euclidean (l2) distance:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
PUT /hotels-index { "settings": { "index.knn": true }, "mappings": { "properties": { "location": { "type": "knn_vector", "dimension": 2, "space_type": "l2" } } } } |
For workloads dominated by vector queries, consider tuning the request cache. In OpenSearch 2.19 and later, increasing dynamic.indices.requests.cache.maximum_cacheable_size to values such as 256 allows larger vector queries to benefit from caching.
Step 2: Add data
Next, insert documents into the index. Each document represents a hotel with its location expressed as a two-dimensional vector:
|
1 2 3 4 5 6 7 8 9 10 11 |
POST /_bulk { "index": { "_index": "hotels-index", "_id": "1" } } { "location": [5.2, 4.4] } { "index": { "_index": "hotels-index", "_id": "2" } } { "location": [5.2, 3.9] } { "index": { "_index": "hotels-index", "_id": "3" } } { "location": [4.9, 3.4] } { "index": { "_index": "hotels-index", "_id": "4" } } { "location": [4.2, 4.6] } { "index": { "_index": "hotels-index", "_id": "5" } } { "location": [3.3, 4.5] } |

Step 3: Run a vector search
To retrieve the three hotels closest to the coordinate [5, 4], run a k-NN query with k set to 3:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
POST /hotels-index/_search { "size": 3, "query": { "knn": { "location": { "vector": [5, 4], "k": 3 } } } } |

The query returns the nearest neighbors ranked by similarity score. In this dataset, the response includes documents 2, 1, and 3, ordered by proximity to the specified point.
Generating vector embeddings automatically
If your source data is not already in vector form, OpenSearch can generate embeddings during ingestion. Text, images, or other unstructured inputs can be converted into numerical vectors, making them searchable with the same k-NN workflow.
Related content: Read our OpenSearch tutorial
Best practices for vector search in OpenSearch
Here are some useful practices to consider when using OpenSearch for vector search.
1. Enable knn_vector fields properly
When defining vector fields in your mappings, ensure that the knn_vector type is explicitly set with correct parameters, including the dimension and space_type. A mismatch between the dimension of stored vectors and query vectors will result in errors at query time. Additionally, choosing the appropriate space_type (e.g., l2, cosinesimil, or innerproduct) based on your similarity metric is critical for accurate results.
Be mindful that each knn_vector field incurs memory overhead, as vector indices are stored off-heap. If your index contains multiple vector fields or large dimensions, monitor memory usage closely. Use index templates to enforce consistent vector field configuration across indices, especially in multi-tenant or automated deployment environments.
2. Choose the right backend engine and tuning
OpenSearch k-NN supports multiple backend engines for ANN search, primarily FAISS and NMSLIB, each with unique performance characteristics. FAISS tends to be more suitable for GPU-accelerated workloads and dense datasets, whereas NMSLIB can be more flexible and CPU-friendly for various data types. Assess the size and access patterns of your data before committing to a backend, as the engine choice influences memory usage, search speed, and maintenance overhead.
Beyond engine selection, optimal ANN performance requires additional algorithm-specific tuning. Adjust method parameters such as the HNSW (hierarchical navigable small world) graph’s efConstruction and efSearch, depending on whether you prioritize recall accuracy or search latency. Benchmark your queries with representative workloads before deploying at scale, and revisit these settings as your data volume or search traffic evolves.
3. Consider hybrid search for relevance
Using hybrid search in OpenSearch combines the strengths of both keyword-based and vector-based retrieval. This approach fuses classic BM25 scoring with vector similarity, which is particularly effective for queries that mix precise intent with ambiguous or semantic content.
To implement hybrid search, construct multi-modal queries that include a standard text clause and a k-NN vector clause within the same request. OpenSearch computes relevancy scores from both sources and merges the results, often with user-configurable weighting. This flexibility allows organizations to incrementally adopt vector search without losing the advantages of mature keyword ranking models.
4. Use neural sparse search when resource-conscious
Neural sparse search is an alternative to dense vector search that leverages sparse representations, like token weights, rather than full dense embeddings. This method, available in OpenSearch, can be more resource-efficient, as it requires less memory and can reuse existing inverted index structures. Especially for workloads constrained by hardware, neural sparse search reduces the impact on heap and storage.
Neural sparse methods work best for search tasks where semantic richness is needed but latency and resource budgets are tight. By configuring OpenSearch to use neural sparse models or integrating with plugins designed for this purpose, teams can achieve near-semantic results while maintaining operational efficiency. Test performance and quality during evaluation to decide if this approach suits your scale and requirements.
5. Optimize vector queries and caching
Optimizing your vector search queries is vital for maintaining responsive search performance as your dataset grows. Start by minimizing the dimension of your vectors to the smallest size that preserves accuracy; larger vectors increase memory use and computational cost.
Batch queries where possible, and set appropriate limits for the number of nearest neighbors (k) to prevent unnecessarily large result sets. Review your query patterns to identify redundant or expensive operations that can be consolidated.
Caching is another key practice. OpenSearch supports query result and index caching, which can dramatically decrease the latency for repeated queries or popular vectors. Fine-tune cache settings in your node configurations and monitor hit ratios. Regularly evaluate cached query patterns to ensure your cache retains only high-value results.
Enhancing vector search with Instaclustr for OpenSearch
Instaclustr for OpenSearch supercharges vector search capabilities, providing a robust and fully managed platform designed for the demands of modern AI and machine learning applications. As businesses increasingly rely on sophisticated search functionalities like image recognition, natural language processing, and recommendation engines, the need for an efficient way to manage vector embeddings has become critical.
Vector search works by representing complex data as numerical vectors and finding the “nearest neighbors” to a query, enabling more nuanced and context-aware results than traditional keyword matching. The Instaclustr Managed Platform simplifies this complex process, allowing organizations to focus on innovation while Instaclustr handles the operational heavy lifting.
Instaclustr provides a highly scalable and reliable OpenSearch environment, perfectly suited for vector search workloads. Instaclustr ensures clusters are optimized for performance, automatically handling scaling to accommodate growing datasets and query volumes without compromising speed or availability. This means applications can seamlessly manage millions or even billions of vectors, delivering consistently fast and accurate search results. The reliability of Instaclustr fully managed services, backed by an expert support team, provides the stable foundation necessary for mission-critical AI systems, preventing downtime and ensuring vector search functionality is always on.
The primary benefit of using Instaclustr for OpenSearch is the combination of powerful, open source technology with enterprise-grade management and support. Instaclustr empowers your development teams to leverage the full potential of OpenSearch’s k-NN (k-Nearest Neighbor) plugin for vector search without getting bogged down in database administration. This streamlined approach accelerates development cycles, reduces operational overhead, and allows organizations to build and deploy advanced AI-driven features faster. Choosing Instaclustr means partnering with a trusted guide committed to helping unlock new possibilities with scalable, efficient, and powerful vector search.
For more information: