What is vector similarity search?
Vector similarity search is an information retrieval technique that matches data based on semantic meaning and concept rather than exact keyword matches. By converting text, images, or audio into high-dimensional numerical arrays called embeddings, it allows computers to understand the relationship between different ideas, such as recognizing that a “dog” and a “canine” are closely related, and to retrieve the items most similar to a query vector.
Its efficiency in handling large, high-dimensional datasets and its ability to produce accurate, context-aware results make vector similarity search an important component of modern, data-driven AI applications.
How vector similarity search works:
- Vector embeddings: Machine learning models such as embedding models transform unstructured data like text, images, or audio into long sequences of numbers, or vectors.
- Vector space: These numbers act as coordinates in a massive, multi-dimensional space, where data points with similar meanings are plotted close together.
- Distance metrics: The system measures the distance or angle between the query vector and stored vectors to find the most conceptually similar results, using metrics such as cosine similarity and Euclidean distance.
Common use cases:
- Retrieval-augmented generation (RAG): Grounds large language models in an organization’s private documents so AI assistants can reference specific, accurate information.
- Semantic search: Powers intelligent, natural language search across enterprise platforms and ecommerce catalogs.
- Recommendation systems: Suggests content and products by identifying items that share similar attributes or appeal to users with similar tastes.
This is part of a series of articles about AI technology.
This is part of a series of articles about vector databases.
Why are vector similarity searches important?
Vector similarity searches enable efficient querying of large datasets with high-dimensional data. They provide a way to measure and retrieve items that share similar properties, critical for applications like image recognition, text analysis, and recommendation systems. By focusing on vector properties, these searches can handle complex queries with high precision.
Vector similarity searches also contribute to advancements in artificial intelligence and machine learning. They support the handling and processing of large volumes of data, allowing for more insightful analytics and better decision-making.
Related content: Read our guide to vector search vs semantic search
Traditional keyword search vs. vector similarity search
Traditional keyword search looks for exact words or character matches, which makes it rigid: a search for “apple” only returns results that contain the word “apple.” Vector similarity search instead looks at the underlying context and intent of a query. A search for “apple” can surface related concepts such as “fruit,” “orchard,” or “healthy snacks,” even when the word “apple” never appears, because results are matched on meaning rather than exact text.
Common use cases for vector similarity search
Vector similarity search underpins a growing range of AI and data-driven applications. Some of the most common use cases include:
- Retrieval-augmented generation (RAG): Grounds large language models in an organization’s private documents, enabling AI assistants and chatbots to reference specific, accurate, and up-to-date information.
- Semantic search: Powers intelligent, natural language search across enterprise platforms, knowledge bases, and ecommerce catalogs by matching on meaning rather than keywords.
- Recommendation systems: Drives content and product suggestions by identifying items that share similar attributes or appeal to users with similar tastes.
How vector similarity search works
Vector similarity search operates primarily through vector embeddings, similarity score computation, and nearest neighbor algorithms. These components work in tandem to identify and retrieve vectors that closely match the query vector based on predefined metrics.
Vector embedding
Vector embedding is the process of transforming data into numerical vector representations. For example, words or images are converted into vectors of numbers, capturing intrinsic properties and relationships. The quality of vector embeddings impacts the accuracy of the similarity search.
Techniques like Word2Vec, GloVe, and BERT generate high-quality embeddings for textual data. Methods like Convolutional Neural Networks (CNNs) create embeddings for images. These transformations enable computers to handle and process complex data types efficiently.
Vector space
Once data has been transformed into embeddings, those numbers act as coordinates in a massive, multi-dimensional space. Data points with similar meanings are plotted close together, so proximity within this vector space directly reflects semantic similarity. Finding similar items then becomes a matter of locating the points nearest to the query vector.
Similarity score computation
Similarity score computation is crucial for determining how close two vectors are. This calculation often involves metrics like Euclidean distance, cosine similarity, or other mathematical functions. The resulting score indicates the level of similarity, with lower scores or higher similarities denoting closer matches.
This step is computationally intensive, especially for large datasets. Efficient algorithms and optimized libraries are essential to handle these computations.
Nearest neighbor algorithms
Nearest neighbor algorithms identify the closest vectors to a given query vector. Techniques like k-Nearest Neighbors (k-NN) and its variants are commonly used. These algorithms compare the query vector against a dataset to find the top k closest vectors. Methods like Approximate Nearest Neighbor (ANN) can speed up the process by trading off some accuracy for speed, useful in real-time applications.
Scalability and efficiency are critical for these algorithms to perform well on large datasets. Advanced techniques such as Hierarchical Navigable Small World graphs (HNSW) or locality-sensitive hashing help in making these searches more efficient. Optimizations and heuristics ensure that the nearest neighbors are retrieved quickly, even from large, high-dimensional datasets.
Tips from the expert

Sharath Punreddy
Solution Architect
Sharath Punreddy is a Solutions Engineer with extensive experience in cloud engineering and a proven track record in optimizing infrastructure for enterprise clients
In my experience, here are tips that can help you better leverage vector similarity search:
- Consider hybrid indexing techniques: Combine multiple indexing structures, such as using a hierarchical navigable small world (HNSW) graph for coarse search and local sensitive hashing (LSH) for fine-tuning, to balance speed and accuracy.
- Optimize distance metric selection: Conduct thorough testing with various distance metrics beyond the common ones like Euclidean and cosine. Metrics like Manhattan distance or Chebyshev distance might perform better for specific data distributions.
- Integrate multi-stage filtering: Implement a multi-stage filtering approach where an initial broad search is followed by a more refined search on a smaller candidate set, enhancing both efficiency and precision.
- Implement distributed computing frameworks: Utilize frameworks like Apache Spark or Ray to distribute the similarity search workload across multiple nodes, ensuring scalability and handling large datasets efficiently.
- Focus on anomaly detection in vectors: Incorporate anomaly detection algorithms to identify and handle outliers in vector space, ensuring that atypical data points do not skew the search results.
Key distance metrics used in a vector similarity search
Distance metrics define how closeness between vectors is measured. Common metrics include Euclidean distance, cosine similarity, and Jaccard similarity.
Euclidean distance
Euclidean distance is the straight-line distance between two points in a multidimensional space. Given vectors (A) and (B), the Euclidean distance (d) is computed as:
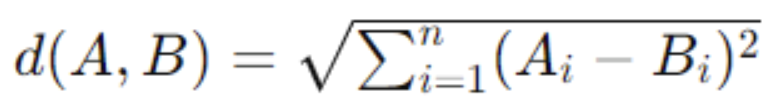
This metric is widely used due to its straightforward mathematical properties. However, it can lead to high computational costs for large datasets. Euclidean distance is useful for low-dimensional data and provides clear geometric interpretation, but it can lead to less accurate results in high-dimensional spaces.
Cosine similarity
Cosine similarity measures the cosine of the angle between two vectors. It assesses the orientation rather than magnitude, making it suitable for text or document similarity where vector lengths vary:
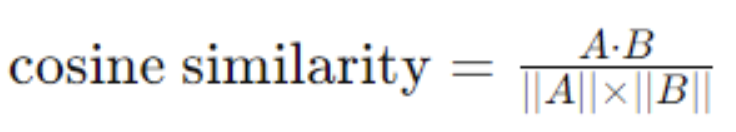
This metric is useful in high-dimensional spaces like text analysis, providing results independent of vector magnitude variations. It aids in determining document or text similarity, where directional alignment between vectors is crucial. Cosine similarity is popular in text mining and natural language processing due to its performance in high-dimensional spaces. However, it can struggle with dense data or when vector magnitudes significantly affect the query’s outcome.
Jaccard similarity
Jaccard similarity evaluates the similarity between two sets by comparing the intersection over the union of the sets. For vectors, it measures shared attributes, often used in binary data applications:
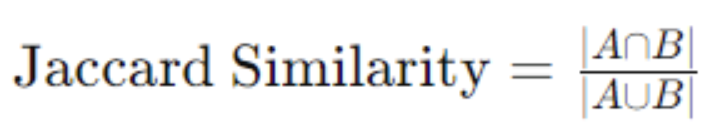
This metric is particularly effective in applications involving set comparison, such as collaborative filtering and genotype analysis. Jaccard similarity is useful for set comparisons and is simple to compute for binary or categorical data. It is less effective with continuous data or when the vectors’ shared attributes are less meaningful.
Related content: Read our guide to vector databases vs relational databases
Pros and cons of vector search
Using vector similarity search offers the following advantages:
- Efficient searching: By leveraging data structures like HNSW graphs and optimized algorithms, it enables rapid retrieval of similar items. This efficiency is critical for applications such as real-time recommendation systems, multimedia searches, and dynamic content delivery.
- High accuracy: By focusing on vector properties and relationships, it can identify patterns that traditional keyword-based searches might miss. This precision is particularly useful for applications like personalized content, where user satisfaction hinges on accurate recommendations.
- Range query support: It enables users to find vectors within a specific range or threshold. This feature is useful for applications requiring intermediate values, such as financial data analysis, where users need to identify data points within particular bounds.
It should also be noted that this method has some limitations:
- High-dimensional data: As dimensionality increases, the volume of data grows exponentially, making traditional algorithms inefficient. Specialized algorithms and data structures are required to maintain performance and accuracy in high-dimensional spaces. Techniques like Principal Component Analysis (PCA) or t-Distributed Stochastic Neighbor Embedding (t-SNE) help reduce dimensionality, but they also introduce complexities in implementation and interpretation.
- Scalability: Traditional algorithms like k-NN face difficulties in maintaining performance as the dataset size increases. Optimizations and distributed computing approaches are necessary to ensure scalable solutions.
- Choice of distance metric: Different metrics are suitable in different contexts, and an incorrect choice can lead to inaccurate results. Understanding the data characteristics and query requirements is essential for optimal metric selection.
- Indexing and storage requirements: The size and complexity of high-dimensional data require advanced indexing techniques. Traditional indexing methods may not be suitable, leading to the development of specialized structures like HNSW or Annoy. Additionally, high-dimensional vectors require substantial storage space.
5 tips for successful vector similarity search implementation
Here are some of the ways that organizations can ensure the most effective use of vector similarity search techniques.
1. Cleaning and Normalizing Data
Cleaning involves removing noise, errors, and irrelevant data, ensuring that only meaningful information is processed. Normalization adjusts data to a common scale without distorting value ranges.
Standardization and rescaling help in achieving consistent results and prevent biases. Techniques like z-score normalization or min-max scaling are commonly used. Proper data preprocessing significantly enhances the performance and accuracy of similarity searches.
2. Configuring and Optimizing Algorithms
Algorithms like k-NN or HNSW must be implemented with considerations for data type and size. Algorithm configuration involves parameter tuning to balance performance and accuracy.
Continual monitoring and testing of algorithm effectiveness are necessary. Machine learning models can adapt over time, so reconfigurations and updates ensure they remain optimized.
3. Sharding and Partitioning Data
Sharding and partitioning strategies improve scalability and efficiency. By dividing large datasets into smaller segments, parallel processing is enabled, leading to faster query responses. Sharding involves distributing data across multiple storage instances or servers.
Effective partitioning ensures data subsets are evenly distributed, reducing computational load. This approach improves system performance and supports scaling as data volumes grow, making it critical for large-scale applications dealing with high-dimensional vectors.
4. Implementing Hardware Acceleration
Using hardware accelerations, like GPUs and TPUs, can significantly boost processing speeds. These accelerators handle parallel computations more efficiently than traditional CPUs, making them suitable for the computationally intensive tasks of similarity searches.
Optimizing software to support these hardware capabilities can increase throughput and reduce latency. This practice is especially important in real-time applications and large-scale data environments, where performance is a key differentiator.
5. Handling High-Dimensional Data
Effective methods for handling high-dimensional data include dimensionality reduction techniques like PCA or LDA. These methods simplify data structure while retaining essential information. Proper handling ensures that searches remain efficient and accurate.
Combining dimensionality reduction with advanced algorithms helps manage complexity and maintain performance. Continuous evaluation of these strategies ensures they remain effective as data and query types evolve.
Common tools and databases for vector similarity search
To implement vector similarity search, developers rely on specialized vector databases or existing databases with built-in vector capabilities. The ecosystem generally falls into three categories:
- Dedicated vector databases: Purpose-built engines such as Pinecone, Milvus, and Qdrant, designed specifically for storing and querying embeddings at scale.
- Databases with vector extensions: Established databases that have added vector capabilities, including Elasticsearch, OpenSearch, MongoDB Atlas Vector Search, and PostgreSQL with the pgvector extension.
- Cloud solutions: Managed services such as Google Cloud Vector Search and Azure AI Search that build vector search into broader cloud platforms.
Enhancing data exploration and insights with Instaclustr's vector search capabilities
Instaclustr, a leading provider of managed open source data platforms, recognizes the growing importance of advanced search capabilities in today’s data-driven landscape. To meet the evolving needs of organizations, Instaclustr incorporates vector search into its offerings, enabling businesses to efficiently search and analyze large volumes of complex data.
Vector search, also known as similarity search or approximate nearest neighbor search, is a technique that allows for efficient searching of high-dimensional data based on their similarity or proximity in a vector space. It is particularly useful for scenarios where traditional keyword-based search falls short, such as image and video analysis, natural language processing, recommendation systems, and anomaly detection.
Instaclustr leverages vector search to enhance the search capabilities of its managed data platforms. By integrating vector search libraries and frameworks, such as Apache Cassandra, and OpenSearch Instaclustr enables organizations to perform fast and accurate similarity searches on their data.
One of the key benefits of vector search in Instaclustr’s platforms is its ability to handle high-dimensional data efficiently. Traditional search methods struggle with high-dimensional data due to the “curse of dimensionality,” where the effectiveness of distance metrics diminishes as the number of dimensions increases. Vector search techniques, on the other hand, employ algorithms and indexing structures specifically designed to mitigate this issue and provide efficient search performance even in high-dimensional spaces.
Another advantage of Instaclustr’s vector search capabilities is its support for advanced similarity models. Organizations can leverage state-of-the-art machine learning models, such as deep learning-based embeddings, to represent data as vectors in a meaningful and semantically rich manner. This allows for more accurate and context-aware similarity searches, enabling businesses to uncover hidden patterns, discover relevant connections, and extract valuable insights from their data.
Instaclustr’s integration of vector search also aligns with its commitment to scalability and performance. The managed data platforms offered by Instaclustr are designed to handle large-scale data workloads, and vector search is no exception. By leveraging distributed computing and parallel processing techniques, Instaclustr’s platforms can efficiently perform similarity searches on massive datasets, enabling organizations to process and analyze their data at scale.
For more information:
- Vector Search in Apache Cassandra® 5.0
- Use Your Data in LLMs With the Vector Database You Already Have: The New Stack
- Instaclustr for PostgreSQL® Releases Support for pgvector
See Additional Guides on Key AI Technology Topics
Open Source AI
Authored by Instaclustr
- Top 10 open source databases: Detailed feature comparison
- Open source AI tools: Pros and cons, types, and top 10 projects
- Top 10 open source LLMs for 2025
AI Cyber Security
Authored by Exabeam
- AI Cyber Security: Securing AI Systems Against Cyber Threats
- AI Regulations and LLM Regulations: Past, Present, and Future
- LLM Security: Top 10 Risks and 7 Security Best Practices
Model Training
Authored by Kolena