Apache Kafka Coming Soon to Instaclustr’s Service Offering!
 (Source: Wikipedia)
(Source: Wikipedia)
If you haven’t read Kafka’s “The Castle” (I haven’t) a few online observations are sufficient for a concise summary (and will save you the trouble of reading it):
- Time seems to have stopped in the village
- The story has no ending (Kafka died before completing it)
- The events recounted seemingly form part of an infinite series of occurrences
- The protagonist (only known as K.) was erroneously summoned to the village
- K. witnesses a servant destroying paperwork when he cannot determine who the recipients should be
- And who is this anonymous K. person anyway?
Nobody wants to end up in a Kafkaesque situation such as the village in Kafka’s “The Castle”, so let’s take a closer look at how Apache Kafka supports less Kafkaesque messaging for real-life applications. In this part, we’ll explore aspects of the Kafka architecture (UML, and consumers), and time and delivery semantics. In the next part, we’ll look at reprocessing (which does sound somewhat Kafkaesque), and how to speed up time.
1. Kafka Architecture
1.1 Kafka UML
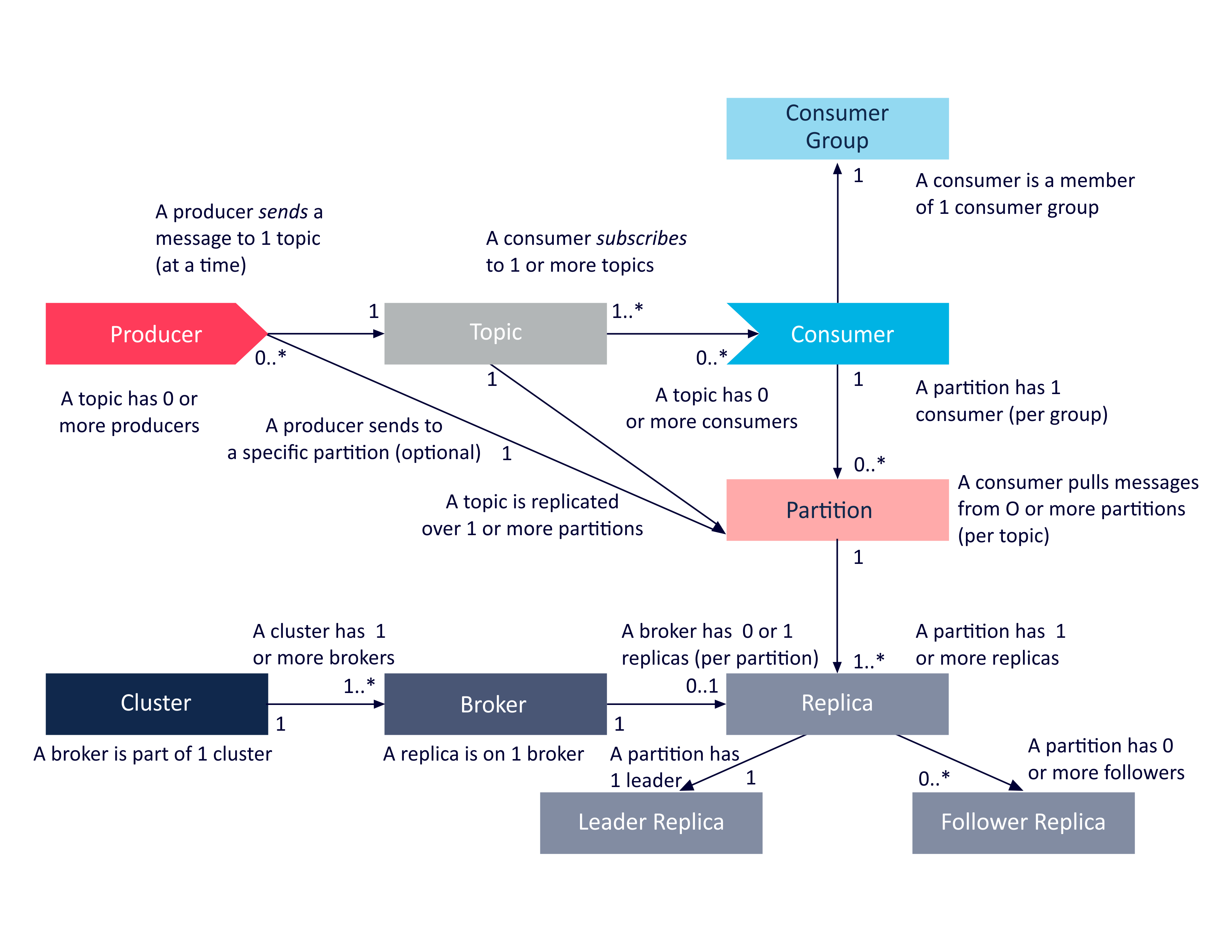
The main Kafka components are Producers, Topics, Consumers, Consumer Groups, Clusters, Brokers, Partitions, Replicas, Leaders and Followers. I couldn’t find an existing UML class diagram anywhere so I produced this simplified UML diagram from the documentation in order to help understand the relationship between these components:
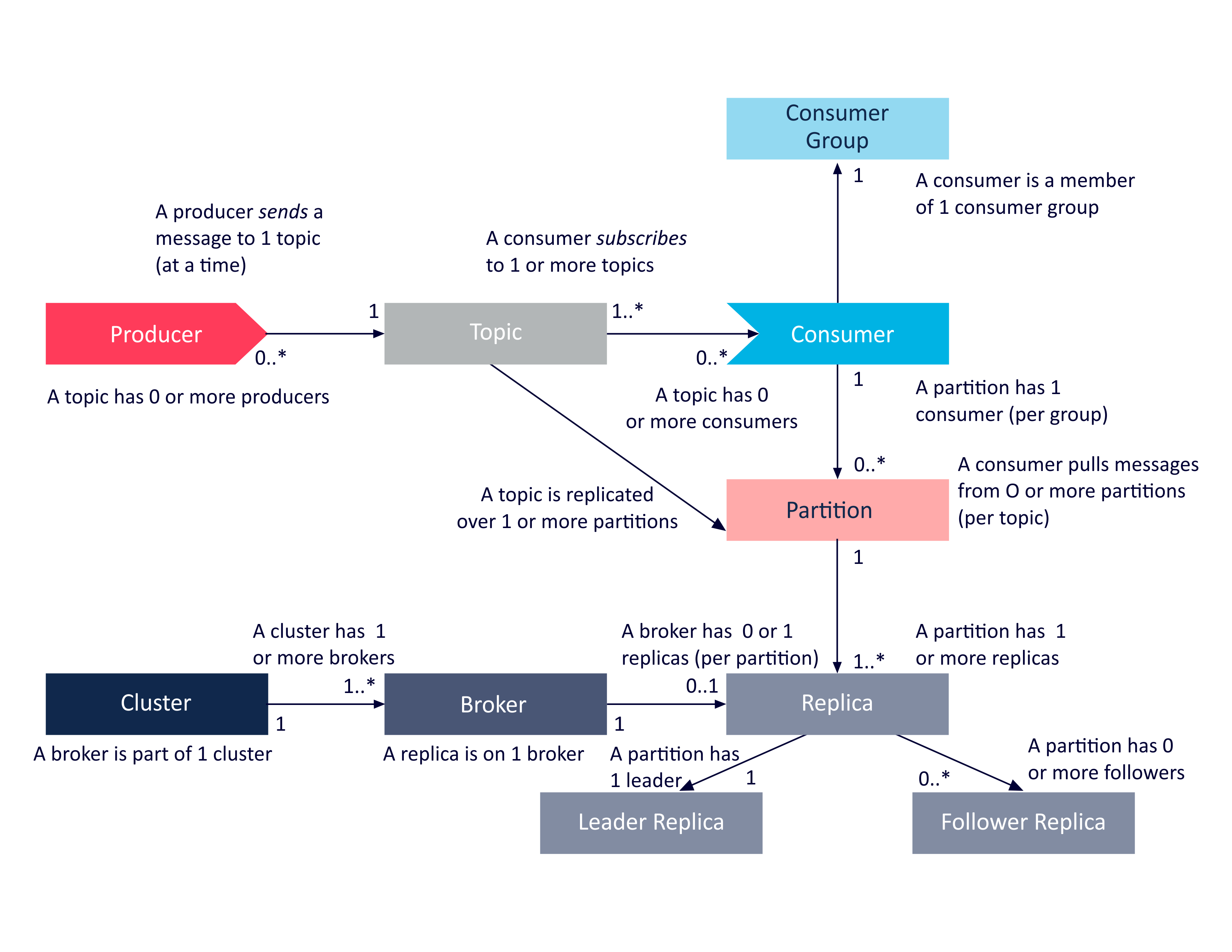
Some obvious relationships that can be derived from this diagram include (focussing on brokers, replicas and partitions):
- A Kafka cluster can have 1 or more brokers.
- A broker can host multiple replicas.
- A topic has 1 or more partitions.
- A broker can host 0 or 1 replica for a given partition.
- Each partition has exactly 1 leader replica, and 0 or more follower replicas.
- Each replica for a partition must be on a different broker.
- Each partition replica must fit on a broker (a partition cannot be spread over multiple brokers).
- Each broker can have 1 or more leaders (for different partitions and topics).
Focussing on the producer, topic, consumer relationships:
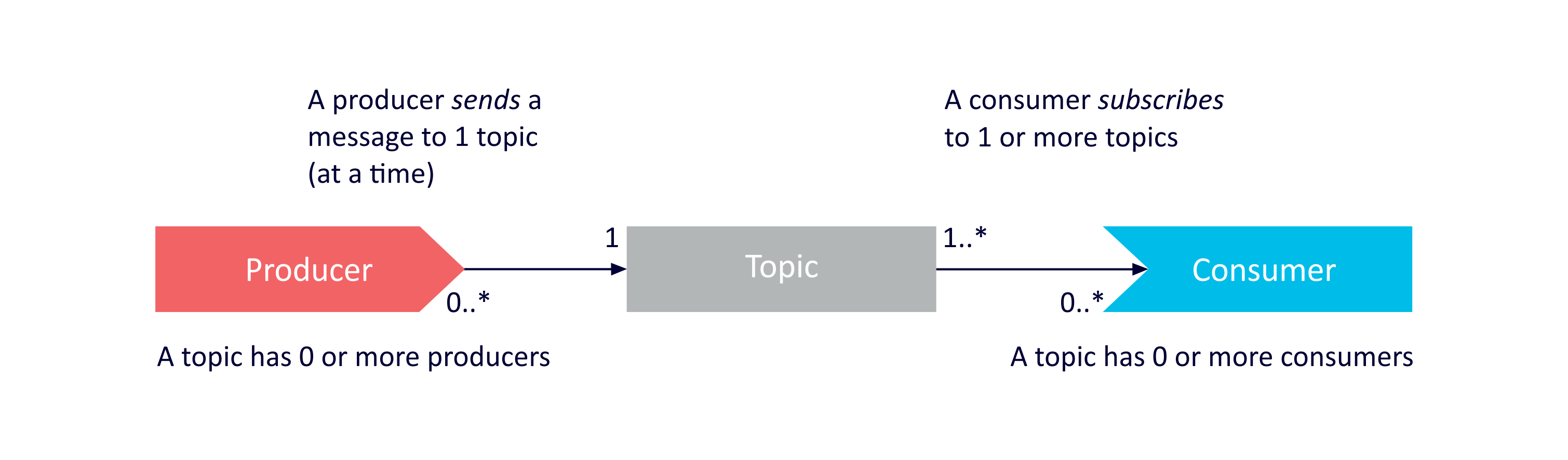
Some possible examples derived from the UML are as follows.
Producers sending to single topics:
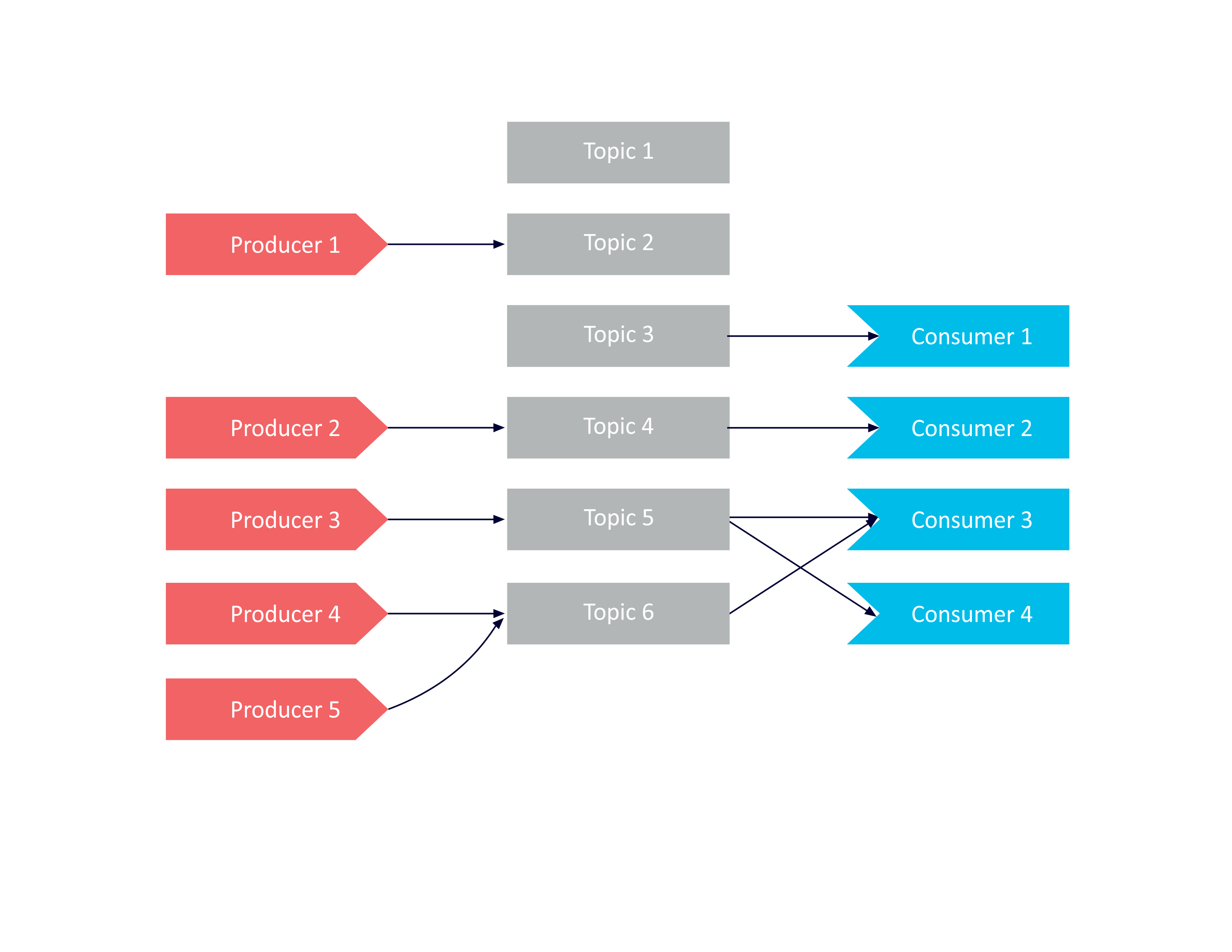
Consumers (e.g. Consumer 3) can be subscribed to multiple topics at a time and will receive messages from all topics in a single poll. You need to check/filter the received messages by topic if this matters.
Producers sending to multiple topics:
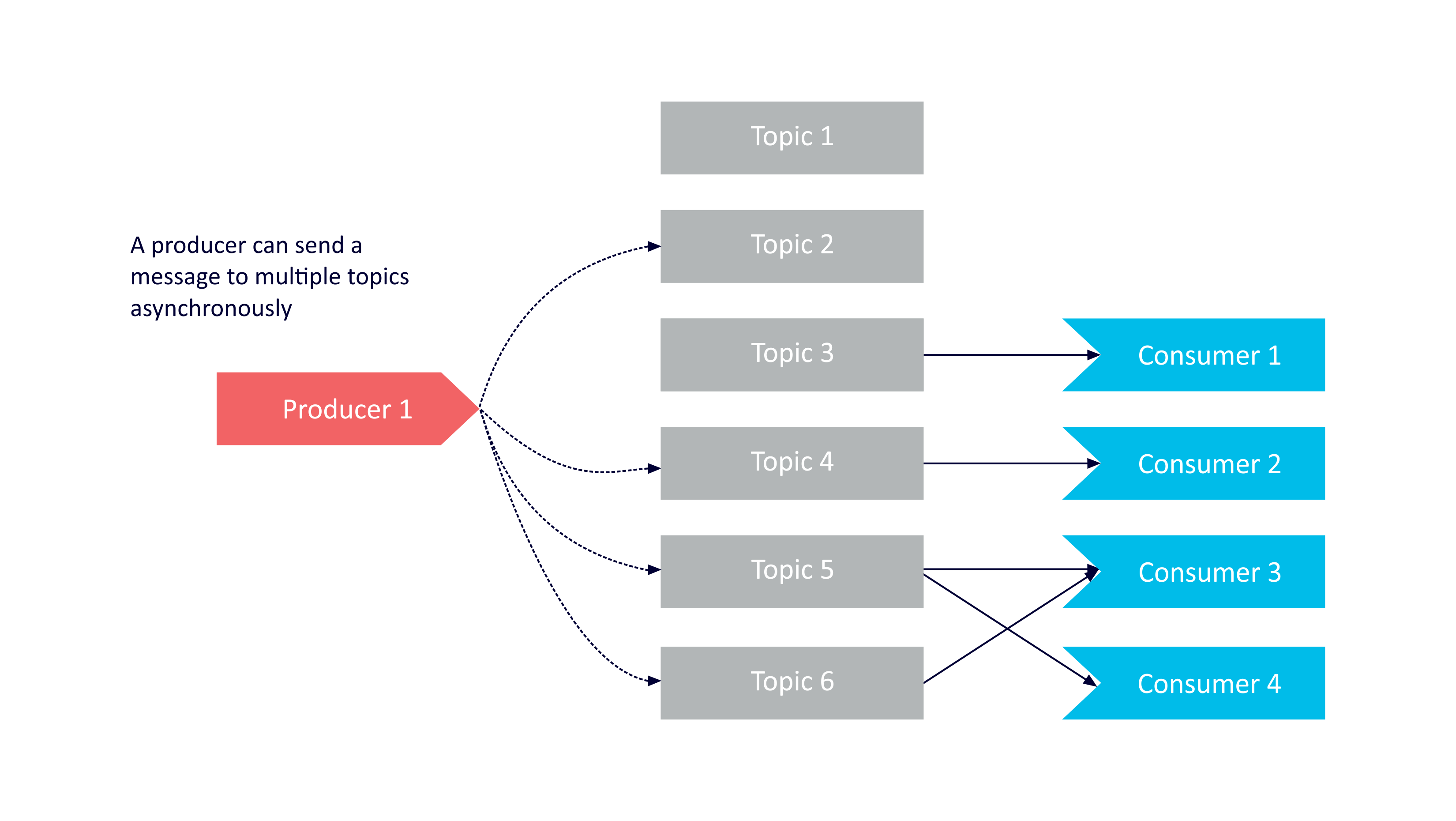
Producers can only send a message to a single topic at a time, but can do so asynchronously, so in practice a producer can have multiple sends to multiple topics in progress concurrently.
It’s also possible for Producers to send messages to specific partitions (using a Custom Partitioner or the Default Partitioner with manual or hashing options), which is reflected in the final version of the UML diagram:
1.2 Consumer Rules
At a high level, this is the way Kafka works: for each topic, there are one or more partitions spread over one or more brokers. Each partition is replicated to one or more brokers as determined the replication factor. The replication factor determines the reliability, and the number of partitions determines the parallelism for the consumers. Each partition is allocated to one consumer instance (per consumer group) only. The number of consumer instances (per group) is less than or equal to the number of partitions, so to support more consumer instances the number of partitions must be increased.
This also guarantees ordering of events within a partition (only). For a Consumer group, each event is only ever processed by one consumer. However, if multiple consumer groups subscribe to a topic, with a consumer in each, then each consumer receives every message (broadcast).
The following diagrams show some of the possible permutations for a single topic, multiple partitions and consumers/consumer groups.
Number of Partitions equal to a number of consumers (in the same group):
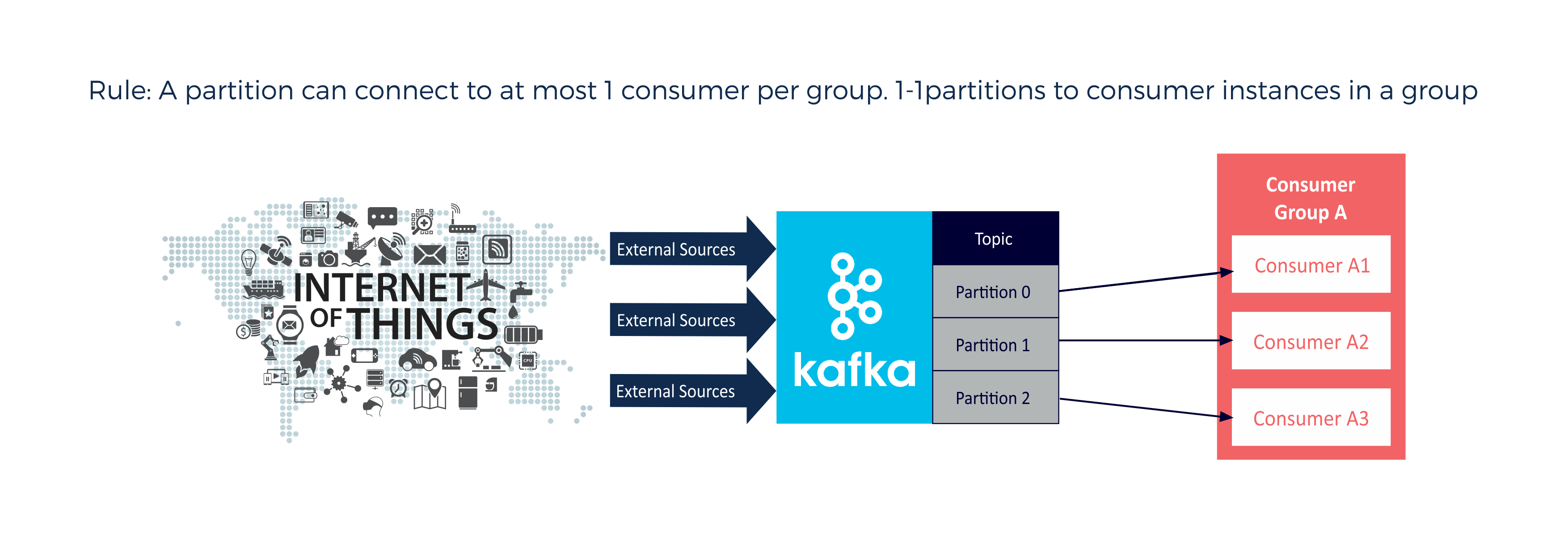
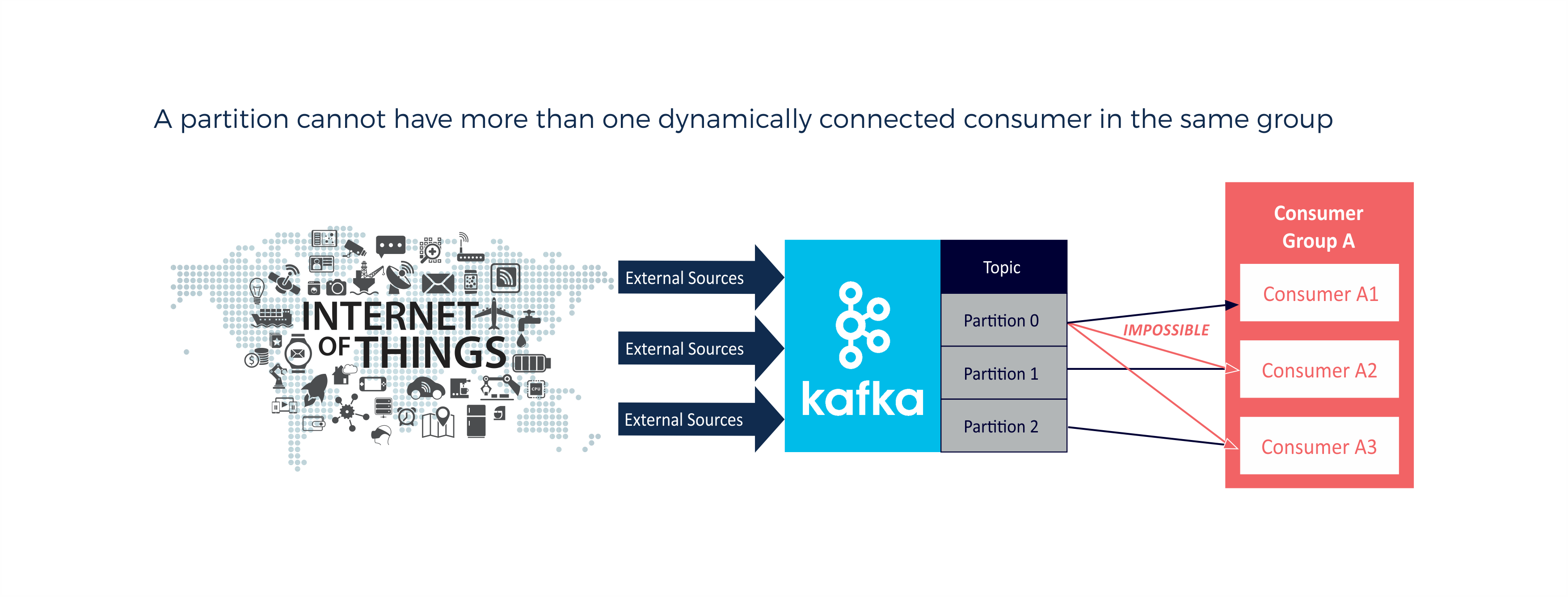
A partition (Partition 0) cannot have more than one consumer in the same group (e.g. A1, A2, A3). Except if a consumer manually connects to a specific partition in a topic, as this overrules the dynamic protocol for that consumer. Manually connected consumers should not be in the same groups, and consumers connected or connecting dynamically are unaffected:
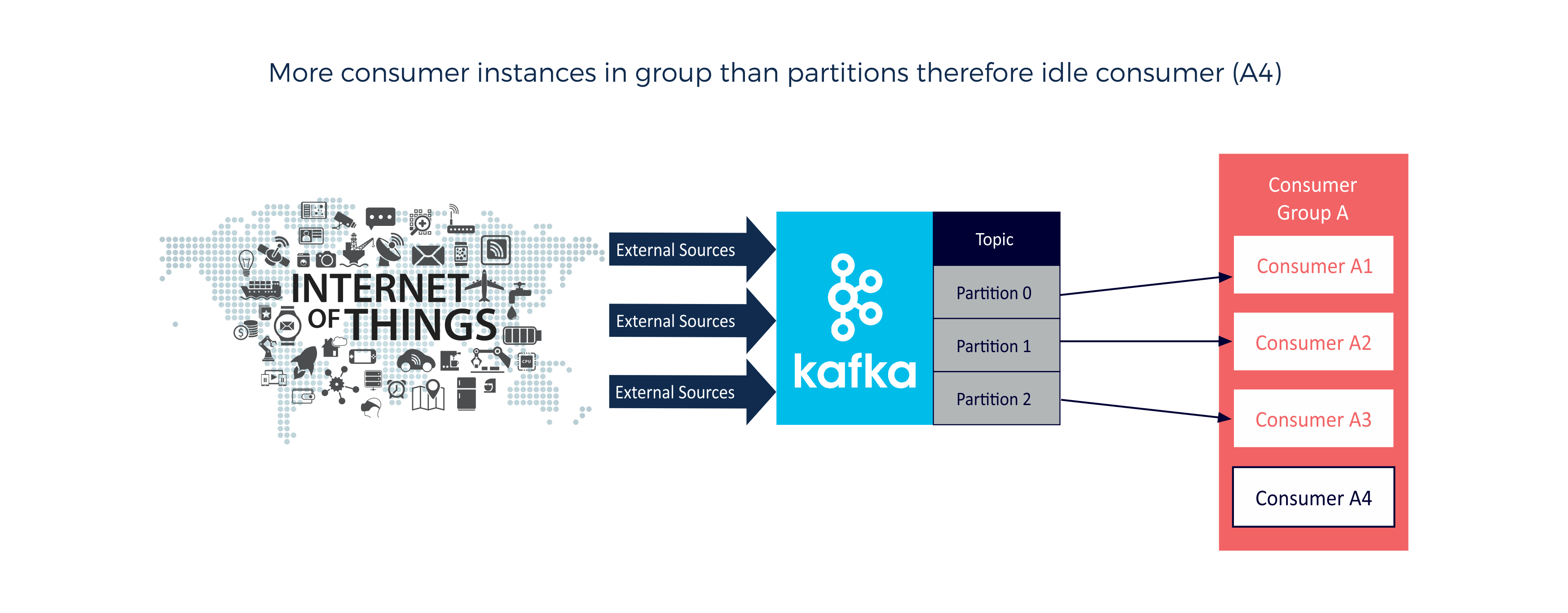
Number of consumers (in a group) greater than the number of partitions (consumer A4 idle). Kafka can use the idle consumers for failover (active consumer dies) or if the number of partitions increases:
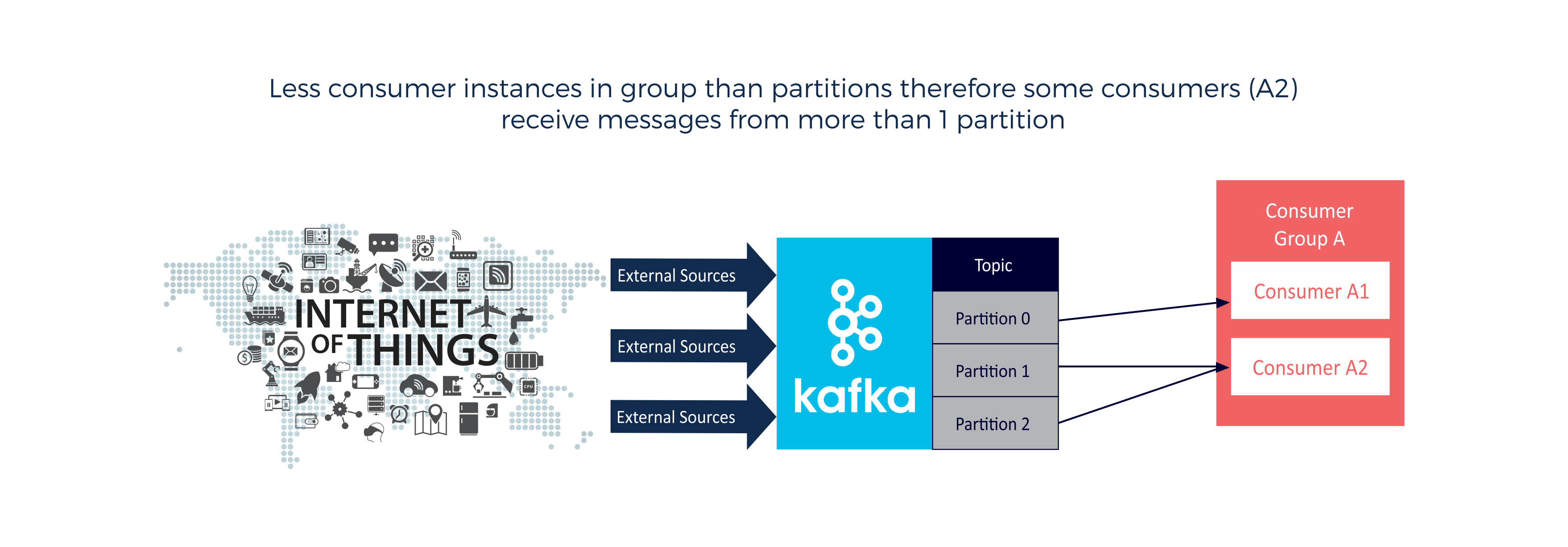
Less consumers (in a group) than the number of partitions (consumer A2 processes more messages than consumer A1):
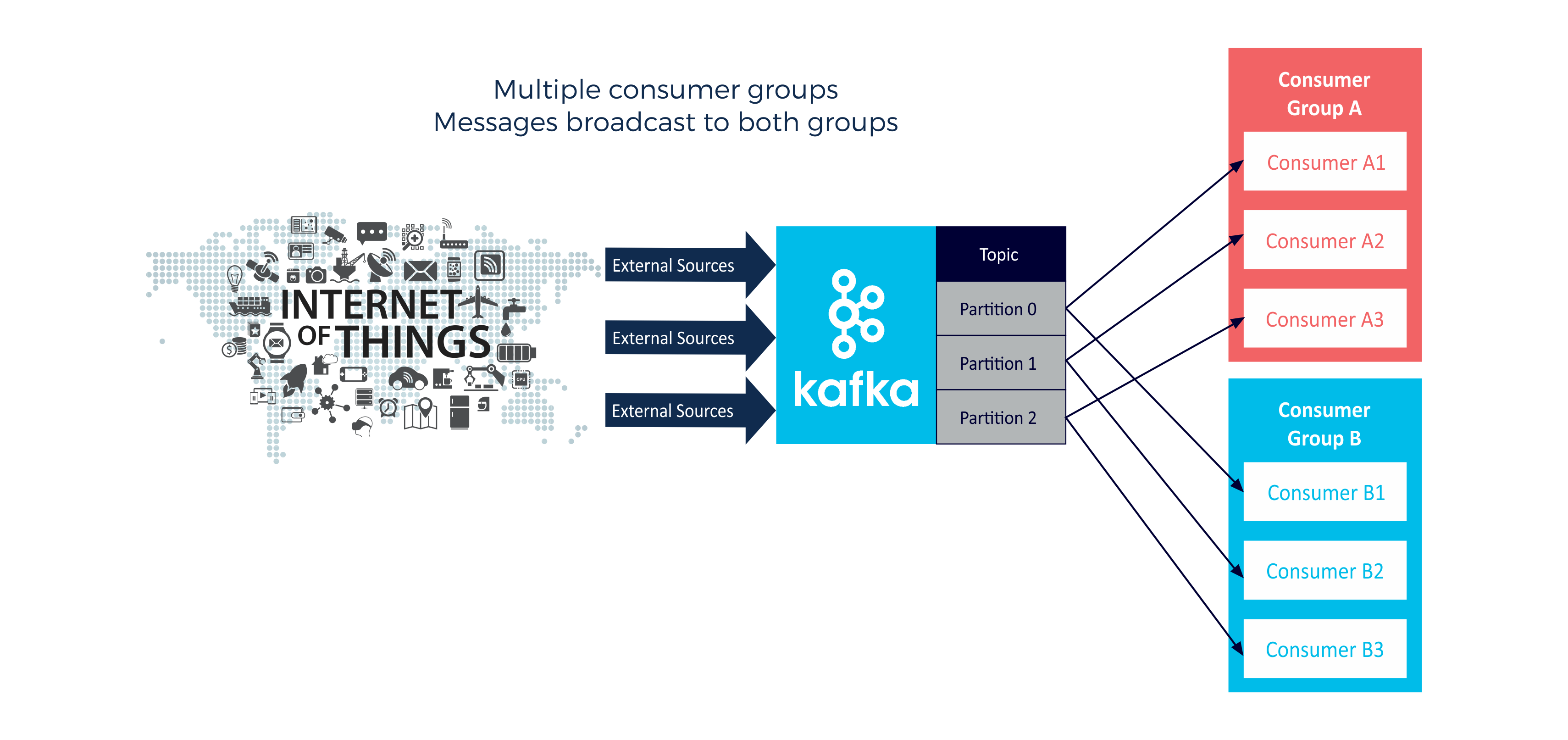
Multiple consumer groups. Each event from each partition is broadcast to each group:
The process of maintaining membership in the consumer group is handled by the Kafka protocol dynamically. If new instances join the group they will take over some partitions from other members of the group, and if an instance dies, its partitions will be distributed to the remaining instances.
Where do Kafka consumers (and producers) run? Anywhere they want to, just not on Kafka brokers
An important resourcing and architectural aspect of Kafka consumers (and producers, including streams) is that they don’t execute in the Kafka brokers, as they need their own resources (CPU, IO). This is good and bad. Good because you don’t need to worry about deploying them to the Kafka brokers and sharing resources with the brokers, and you have more flexibility about how many, where and how consumers are run. Bad because you have to think about this at all. How can/should Kafka consumers and producers be scalably/reliably deployed and resourced? Some of sort of scalable/elastic microservices approach would be ideal.
Can consumers be deployed on Brokers? Maybe, as this is just how partition replication works. Followers consume messages from the leaders just as normal Consumers would, and apply them to their own log.
Kafka consumer language or library can impact throughput
Different Kafka client side languages or libraries can substantially impact message throughput. This was observed by Rackspace, who reported these Apache Kafka Client Benchmarks results in 2016 (from a low of 250 msgs/s to a high of 50,000 msg/s, 200 times difference):
| Client Type | Throughput (msgs/s) |
| Java | 40,000 – 50,0000 |
| Go | 28,000 – 30,0000 |
| Node | 6,000 – 8,0000 |
| Kafka-pixy | 700 – 800 |
| Logstash | 250 |
2. Semantics
2.1 Time Semantics
Time in stream systems can get a bit confusing as events are in motion, and naturally move through the system over a period of time (not instantaneously), making the interpretation of time important. Kafka has three important time semantics:
- event time
- ingestion time, and
- processing time.
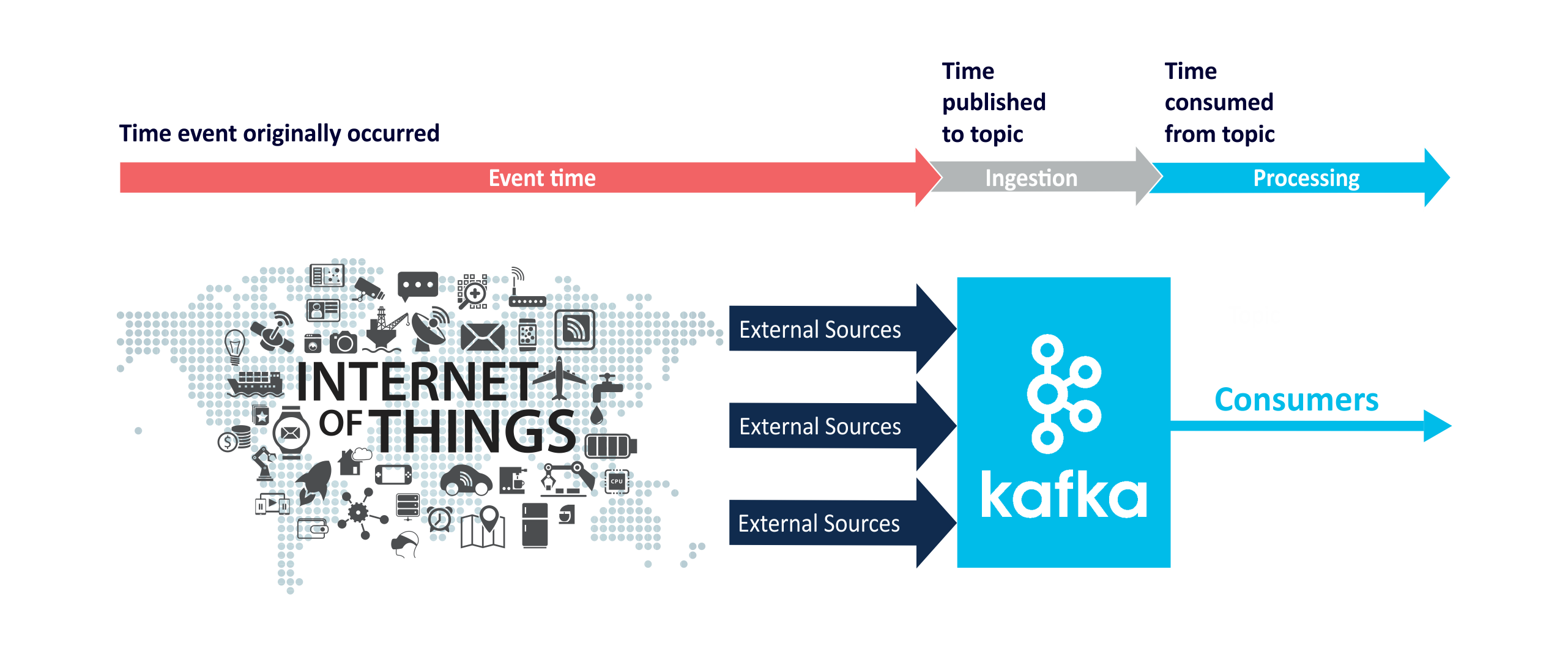
Event time is the time that an event occurred, and is typically recorded by sensors external to Kafka before events arrive in Kafka. Ingestion time is when an event arrives in a topic. Processing time is when an event is consumed from a topic:
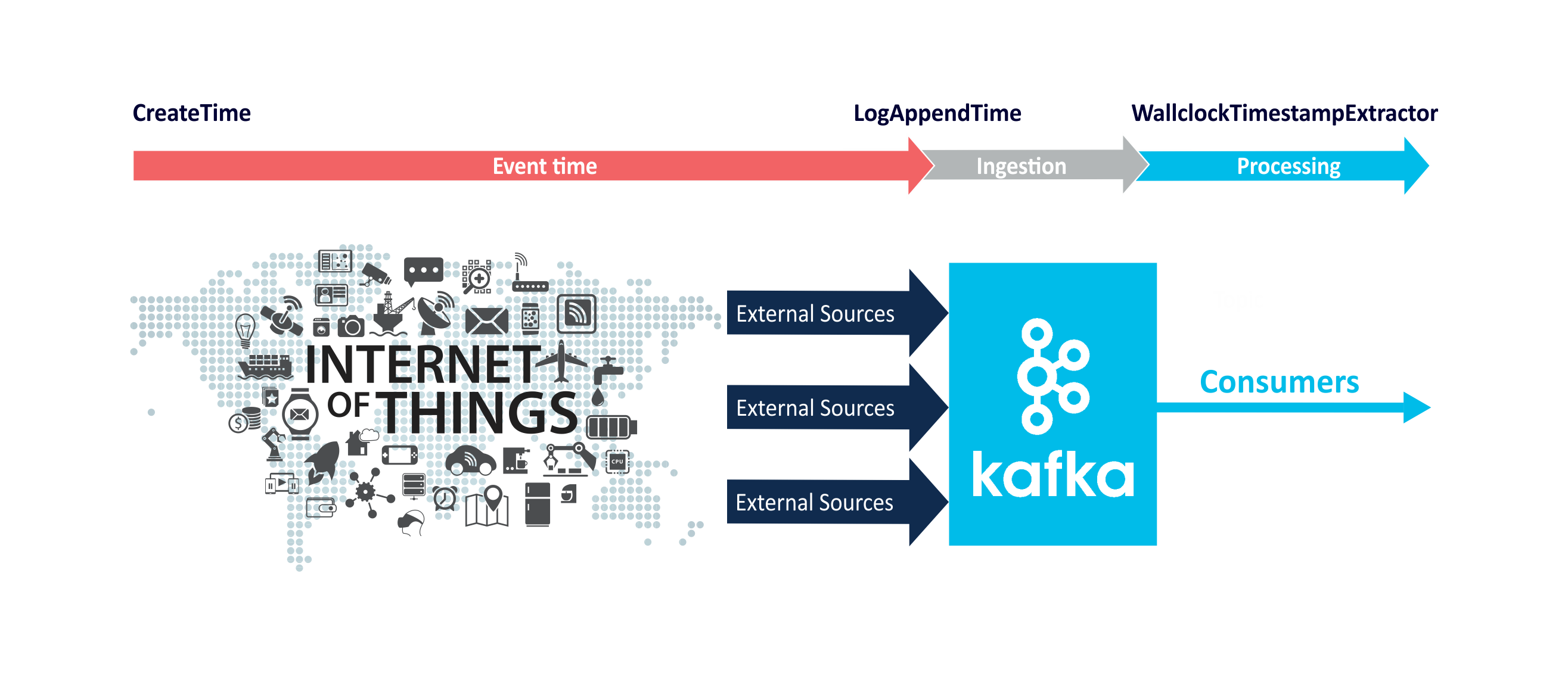
So in theory: event time <= ingestion time <= processing time! (if all clocks are perfectly synchronized). Since 0.10 Kafka automatically embeds timestamps into messages. Depending on Kafka’s configuration (broker or per topic) these timestamps represent event or ingestion time. The timestamps can be retrieved with a timestamp extractor (ouch!):
- If CreateTime is used then the extractor provides event-time semantics.
- If LogAppendTime is used then the extractor provides ingestion-time semantics.
- Otherwise, the WallclockTimestampExtractor provides processing-time semantics
Custom timestamp extractors are possible, so it may be possible to have embed and process futures times. There is also support for a time-based index for use by consumers to retrieve records with timestamps that are equal to or larger than the given timestamp.
More resources on Kafka time:
- https://kafka.apache.org/0110/documentation/streams/core-concepts#streams_time
- https://docs.confluent.io/3.0.0/streams/developer-guide.html
- https://stackoverflow.com/questions/39514167/retrieve-timestamp-based-data-from-kafka
2.2 Delivery semantics: I’m only going to say this {zero, once, multiple} times!
 (Source: Shutterstock – edited)
(Source: Shutterstock – edited)
If you send a message, how many times should it be received? And by how many consumers? Zero? Exactly once? Multiple times? For many critical applications receiving a message multiple times is unacceptable (e.g. financial transactions). But missing a critical message altogether can also be problematic (“Fire! Fire!”). “Exactly once” delivery of messages in distributed systems is actually pretty hard to achieve, and many systems only support “one or more” delivery semantics.
Kafka was designed as a highly scalable and reliable distributed message system, with persistence of messages in immutable logs across replicated topic partitions (to allow for data sizes greater than can fit on a single server, redundancy and parallelism). Consumers keep track of which messages they have processed in each topic (using offsets, 0 is the offset of the oldest message). Multiple consumers can therefore be scalably supported per topic.
This diagram (from the documentation) shows a topic (with a single partition) with multiple consumers reading from different offsets:
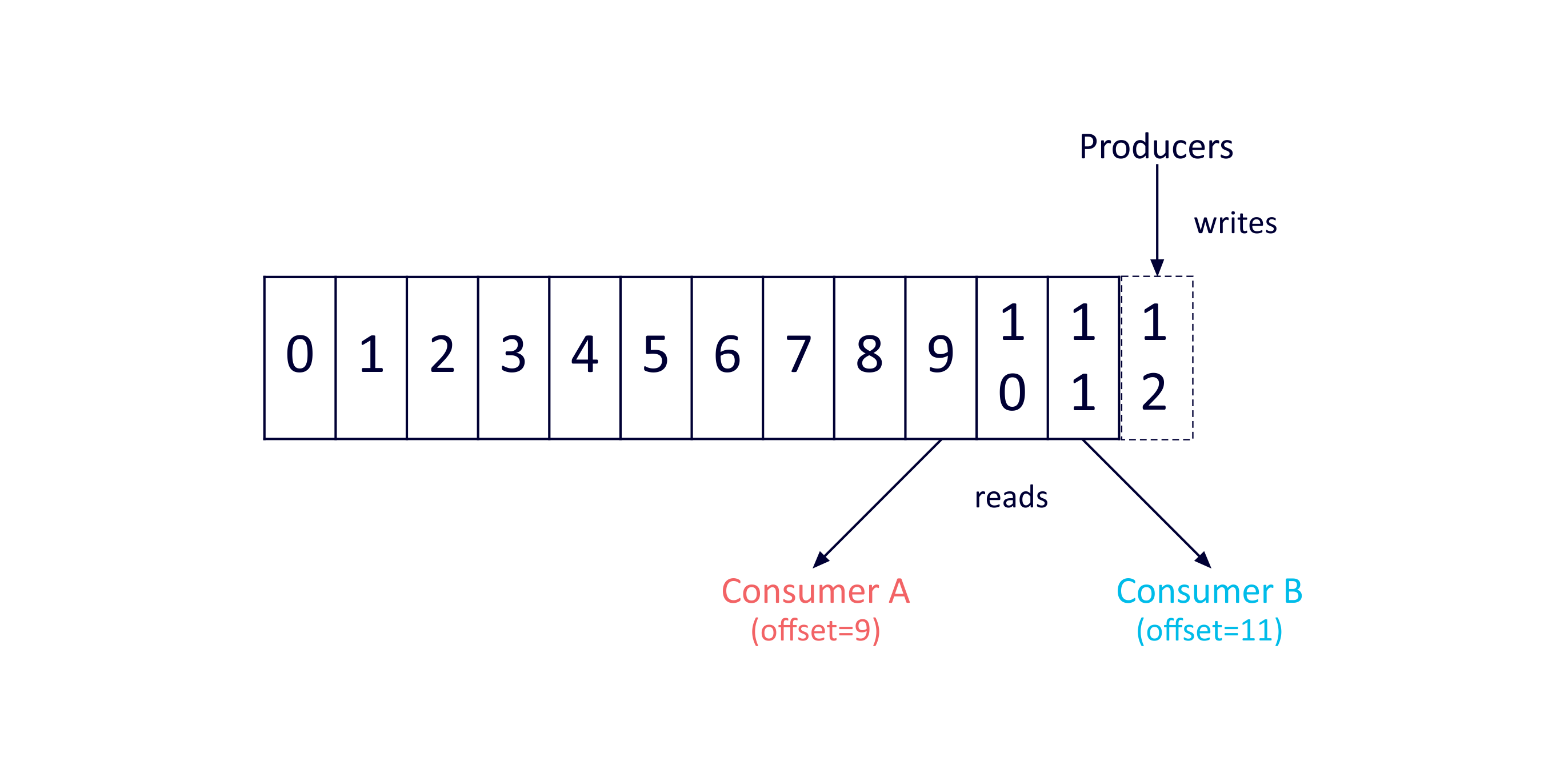
Prior to Kafka version 0.11 the delivery semantics were “at least once”. That is, messages are never lost but may be re-delivered resulting in duplication. There are two cases where duplication could occur:
- Duplicate messages could be sent by Producers
In the case that a commit acknowledgment is received the producer sends another copy of the message to the broker.
- Duplicate messages could be received by Consumers
If consumers fail there is the possibility that the current message was processed but the offset was not updated correctly in which case the same message will be processed again by a different consumer.
Kafka now supports tunable delivery semantics which includes exactly-once delivery:
- Kafka streams supports exactly-once delivery
- How do they do it? Apparently a combination of unique message ids (to allow deduplication of messages), and using Kafka topics as an internal state store.
- The transactional producer/consumer can be used for exactly-once delivery between topics.
- Kafka provides some support to 3rd party sources/sinks for exactly-once delivery using Kafka Connect.
However, it’s not just to handle failures that “at least once” delivery is relevant. It’s actually useful for normal operation. Because multiple consumers are supported, and each consumer manages their own offset, then multiple consumers can process the same message. Consumers can also choose the order of messages, if and which messages to process, and how many times to process messages. For example, they can reset the offset to the oldest message, ignore all past events if they are only interested in future messages, process messages in reverse order, skip back to any older past offset, and process some or all of the messages multiple times, which leads to the powerful idea of event reprocessing (next blog).