Achieving sub-millisecond Redis latency with Java clients and client-side caching
In my previous Redis blog, we discovered what Redis really is! It’s an open-source in-memory data structures server. And we discovered how fast it is! For a 6 node Instaclustr Managed Redis cluster latencies are under 20ms and throughput is in the millions of “gets” and “sets” a second. However, in order to actually use Redis as a low-latency server in a real application, you need to use one of the many programming language-specific Redis clients. And did you know that Redis also works as a cache (server or client side), so it is possible to get even better latency results? In this blog, we try out two different Redis Java clients (Jedis and Radisson) and explore Redisson client-side caching in more detail.
1. Redis Java Clients: Jedis and Redisson
Redis clients communicate with Redis using a standard protocol. No, just kidding! Well, yes and no. Redis uses a Redis specific protocol (RESP—Redis Serialization Protocol) over TCP (which has been used for just about everything imaginable since it came out in 1981, predating the IP part of the TCP/IP stack by 8 years). Unfortunately, this means that to use Redis from a specific programming language you need a programming-language specific client that talks RESP with Redis. One of the important things that the protocol supports is pipelining. Another important thing clients need to do is understand Redis clustering.
As far as I can tell, there are no official Redis clients, but fortunately, there are a large number of community supported clients for just about any programming language you can think of (and I was pleasantly surprised to find Prolog in the list, which is my all-time favourite language). However, these days I’m pretty much a monolingual sort of person so let’s focus our attention on Java clients. There are in excess of 10 possible Java clients, with 3 recommended: Jedis, Lettuce and Redisson. Lettuce looks sophisticated and supports Redis clusters, but this time around I ended up trying Jedis and Redisson as they both support Redis clusters, and Redisson supports client-side caching which I also wanted to try out. Client-side caching is supported by “client tracking” in Redis 6 and upwards.

Source: Rattana – Adobe Stock
Instaclustr Managed Redis is version 6 and is also clustered so it made sense to use clients that supported Redis clusters (both) and client-caching (Redisson only).
Rather than using a simple Redis client, you can also use a higher level framework, for example, I noticed support for Hibernate and Spring frameworks.
2. Jedis vs. Redisson
Both Jedis and Redisson are easy to use and configure to connect to an Instaclustr Redis cluster. With Jedis you need to configure JedisCluster and with Redisson you use useClusterServers as follows.
For Jedis:
String ip = “ip address”; int port = 6379; int connectionTimeout = 10000; int soTimeout = 10000; int maxAttempts = 20; String clientPassword = “password”; Set<HostAndPort> nodes = new HashSet<HostAndPort>(); nodes.add(new HostAndPort(ip, port)); GenericObjectPoolConfig pc = new JedisPoolConfig(); JedisCluster jc = new JedisCluster(nodes, connectionTimeout, soTimeout, maxAttempts, clientPassword, pc); // and to set a key jc.set(“key”, “value”);
And for Redisson:
Config config = new Config();
config.useClusterServers()
.addNodeAddress("redis://" + ip3 + ":" + port)
.setPassword(pass)
.setCheckSlotsCoverage(false)
.setRetryAttempts(20)
.setRetryInterval(10000)
.setTimeout(20000)
.setConnectTimeout(10000);
RedissonClient redisson = Redisson.create(config);
RMap<String, String> map = redisson.getMap(“aMap”);
// and to set a key use fastPut if you don’t need the previous value
map.fastPut(“key”, “value”);
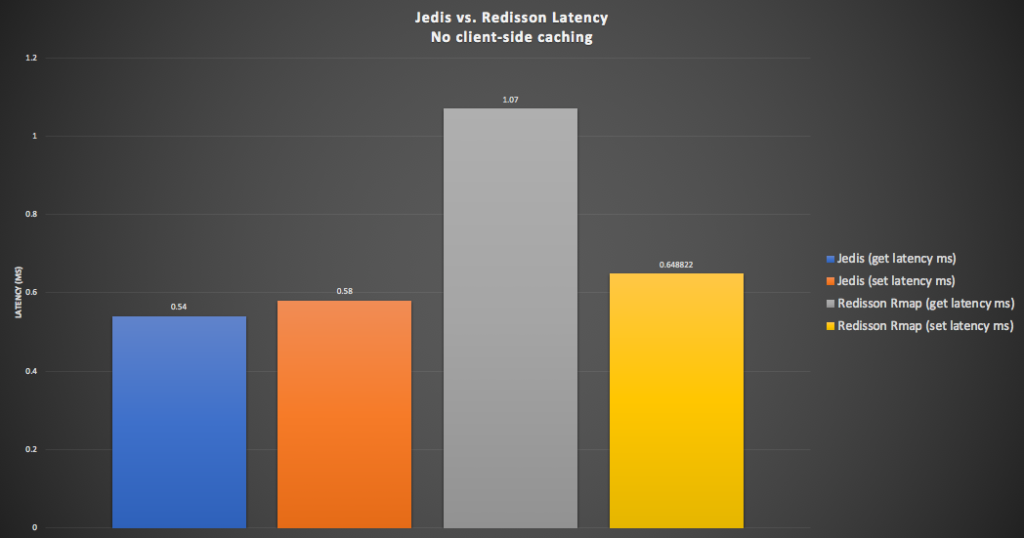
I ran some (single threaded) tests to measure latency for simple string key/value sets/gets with both clients, using set for Jedis and RMap and fastPut (if you don’t need the previous value) for Redisson. This graph shows that get and set latencies for Jedis (blue and orange) are comparable, and slightly faster than Redisson’s get and set latencies (grey and yellow). Redisson’s get latency is around 1ms, and set is faster, but comparable with Jedis, at 0.6ms (which is odd but appears to be true over multiple re-runs).
3. Redisson Client-Side Caching: Introduction
My initial reaction when I heard about Redis a few months ago was that it was probably some sort of distributed Java object caching technology. But then I found out what it really is (see Blog). However, when exploring Redis Java clients I discovered that it actually can work as a client-side cache so it turns out that my first guess wasn’t too far off the mark! Why did I immediately jump to the conclusion that it was a Java cache technology? Partially because of my background in distributed Java, which has been around for a while.
In 2001 I published some research on Enterprise Java Bean (EJB) caching (Entity Bean A, B, C’s: Enterprise Java Beans Commit Options and Caching, Middleware 2001). The EJB specification (part of Enterprise Java or J2EE) had sophisticated standards-based support for distributed Java components (beans), including container managed persistence (CMP), which automatically synchronized the object state with the database. The standard had support for multiple different types of caching (A, B and C!), and I ran some extensive experiments with a realistic stockbroker application and compared the performance of various vendor’s application servers. In general, caching did result in lower latencies and reduced the load on the database, enabling better scalability. Technologies such as Hibernate (for Object-Relational Mapping), and distributed Java Caches (e.g. Apache JCS) also grew out of this era, and this 2004 article explains what you need to keep all the distributed cache data in sync (basically using messages to invalidate the cached keys when they are modified elsewhere, which is what Redis does).
If you do a google search for “distributed java cache” now, Java-Distributed Caching in Redis comes up as the top result (for me anyway, maybe Google has been watching what I’ve been searching for the last few weeks!).
Now, Redis is advertised as having “sub-ms” latencies. But in the previous blog we found that using a Redis Cluster it’s actually difficult to achieve this goal, given that round trip network latency is the major component of the time. With client-side caching it may be possible to reduce the average latency by removing the network hop. We’ll use Redisson client-side caching which is implemented with RLocalCachedMap. Instead of RMap in the above example code just create RLocalCachedMap as follows:
RLocalCachedMap<String, String> map = redisson.getLocalCachedMap(" cacheTest", LocalCachedMapOptions.defaults());
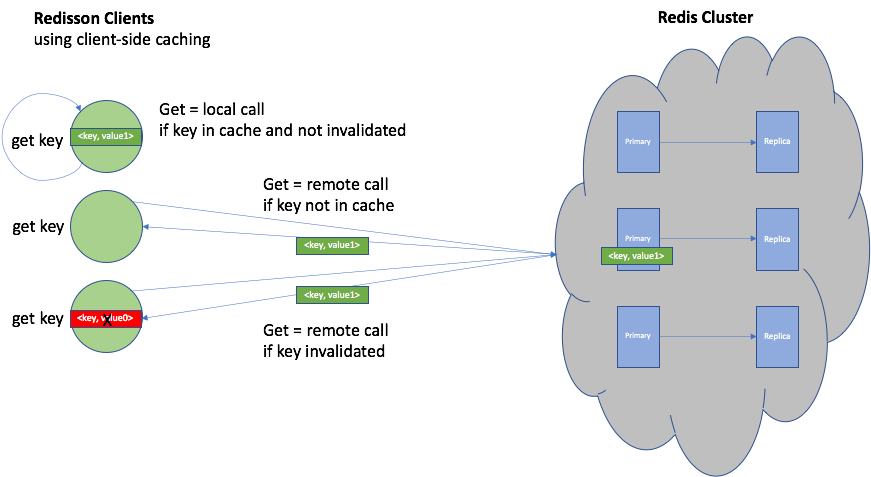
This diagram shows how RLocalCachedMap works for “gets”. If the requested key is in the local cache then the get is just a local call, otherwise if the key is not present or if it’s been invalidated then the get is a remote call to the Redis cluster to refresh the value.
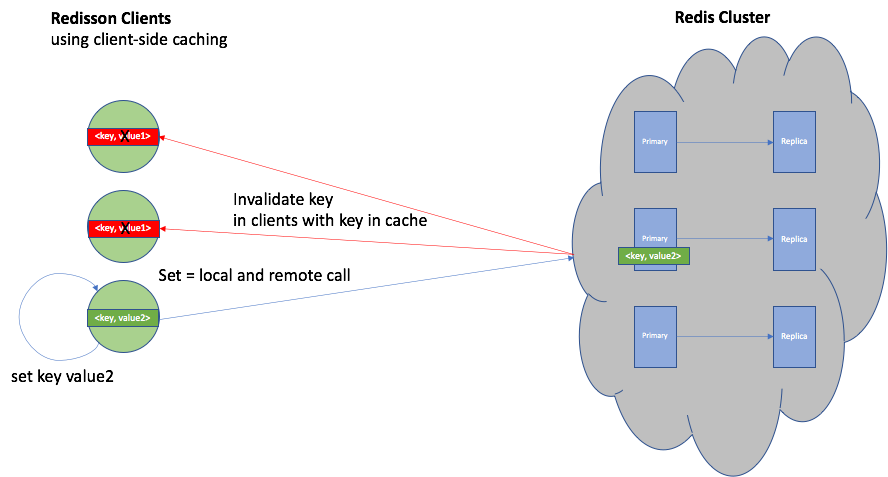
This diagram shows how the Redis tracking invalidation works. For a “set” operation, the value is changed in the local client-side cache and also remotely changed in the Redis cluster, which results in invalidation messages being sent to all the other clients that are currently caching that key (all of them in this example):
4. Redisson Client-Side Caching: Performance
There are multiple factors that impact the cache hit rate for testing. To ensure a high cache hit rate (100%):
- Preload the cache (there’s a method, preloadCache, for this, which attempts to preload as many keys as possible. Note that this can take a long time for large caches!)
- Warm up the cache (if the test is run for long enough the cache will eventually fill).
- Increase the cache size.
- Decrease the number of keys in use, which increases the chance that a key has been read, or reuse a small subset of keys.
- Decrease the write rate. Writes invalidate the key in other clients, forcing them to refresh from Redis, so less writes increases the hit rate.
On the other hand, to obtain (for testing) a low cache hit rate (0%):
- Increase the number of keys in use, so the chance of the key being in the cache is very small, or ensure that each key read is new.
- Decrease the cache size.
- Increase the write rate. Writes invalidate the key in other clients, forcing them to refresh from Redis, so more writes decreases the hit rate.
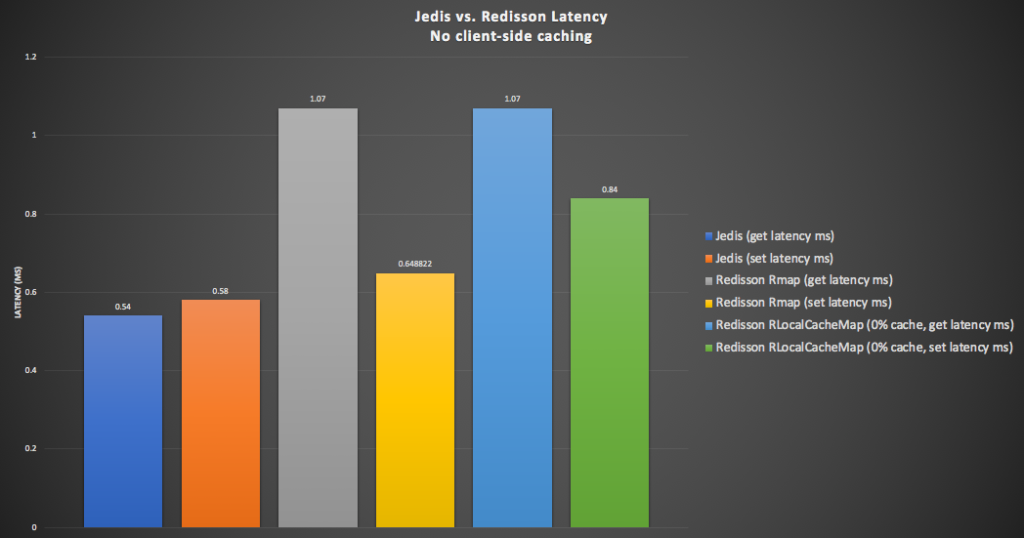
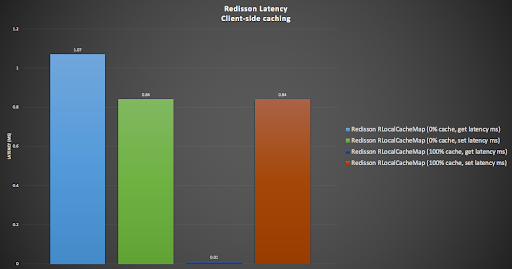
In the following graph we show the Redisson RLocalCachedMap latency results (with 0% cache hit rate), with the above baseline results for comparison. The RLocalCachedMap “get” latency (light blue) is identical to the RMap “get” latency (grey, 1.07ms), but the “set” latency (green) is slower (0.84ms), and the slowest “set” time overall.
In the following graph (showing Redisson caching results only) we show the impact of a 100% client-side cache hit rate (2 right hand bars). As expected the get latency drops to almost zero (0.01ms) , and the set latency remains unchanged (as expected as all sets have to go to Redis).
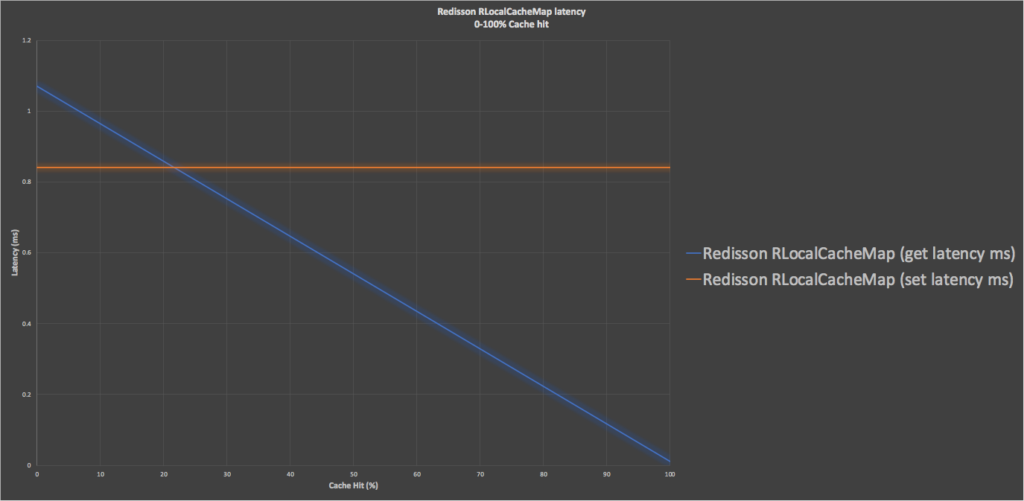
This graph shows just the Redisson RLocalCachedMap “get/set” latencies with increasing cache hit from 0-100%, resulting in a linear decrease in “get” latency from the maximum of 1.07ms to the minimum of 0.01 ms.
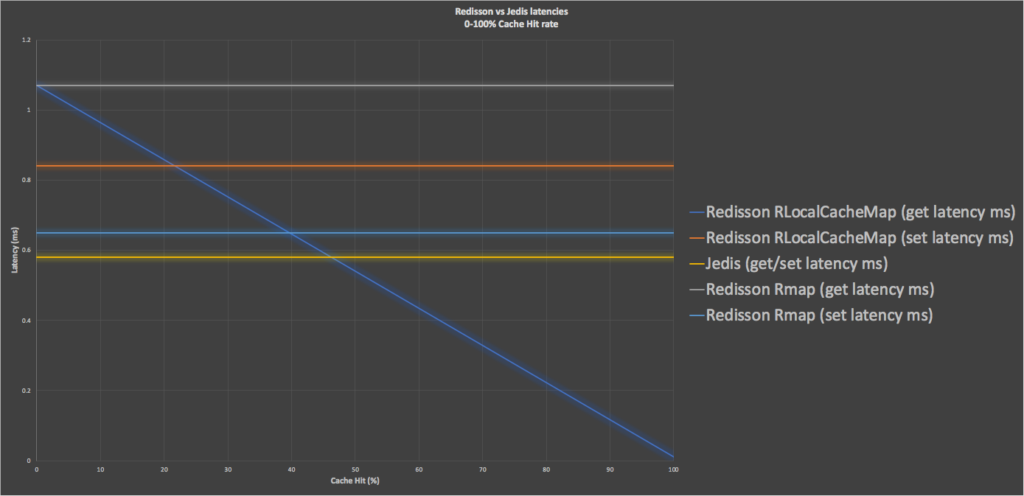
This graph adds the non client-side caching results back (Redis and Redisson RMap) for comparison to show the tradeoffs between using client-side caching, different cache hit rates, and no caching. Jedis “get/set” latencies (yellow) are faster than Redisson RMap (no cache, grey and light blue). Redisson RLocalCachedMap get latency (dark blue) is faster than Redisson RMap “get” latency (grey) and gets faster with increasing cache hit rate. Most significantly, above 45% cache hit rate it starts beating the fastest alternative, Jedis (yellow). However, the penalty is that the RLocalCachedMap set latency is the slowest of all the options (orange).
5. Redisson Client-Side Caching: A Simple Model
To better understand tradeoffs in Redis/Redisson client-side caching between the number of clients, set and get ratios and rates, keyspace cardinality, bytes per key/value, cache size, cache hit rates, and latency, I built a simple (spreadsheet) performance model. The model is parameterized with the measurements from the above exercise. For simplicity I assumed a fixed “get” rate per client (rather than a variable rate which changes based on latencies), and a load-independent model (i.e. latencies don’t increase with load, so the model is only valid for low loads unless reparameterized).
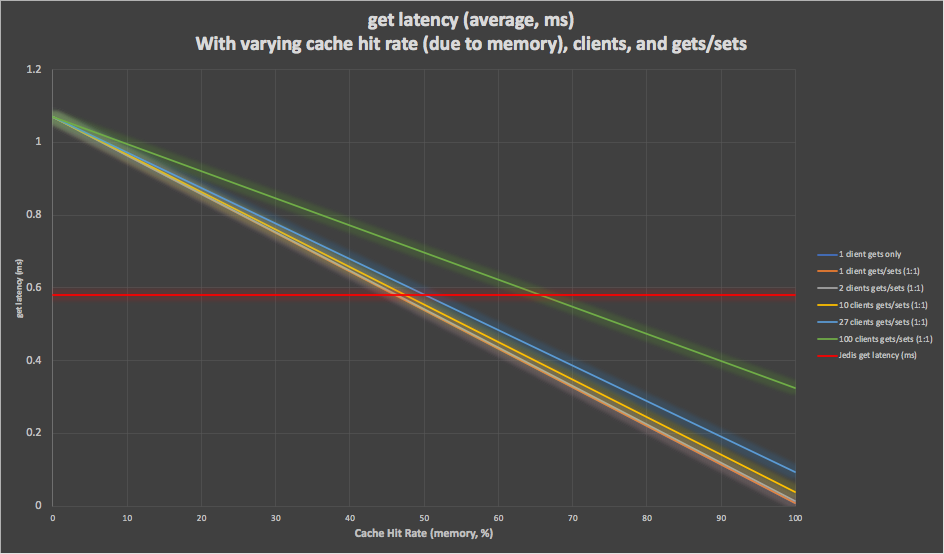
Here are some results for a particular combination of parameters. Assuming 1 million keys, and sufficient memory for 0, 50, and 100% cache hit rates (due to the available memory, the model computes the actual cache hit rate due to number of keys, clients and “set” rate), from 1 to 100 clients, and a 1:1 ratio of “gets” and “sets”, then the following graph shows the predicted average “get” latency with increasing cache hit rates (due to memory). To summarize, the latency increases with more clients, and it takes a higher cache hit rate (due to memory) to achieve reduced latencies. With 27 clients you need more than 50% cache hit rate (due to memory) to have a faster latency than the equivalent non-cached Jedis client (anything below the red horizontal line is better). And by100 clients you need more than 65% cache hit (due to memory) to do better than Jedis.
Caching typically performs better when there is a high read to write ratio, so 1:1 is not an ideal candidate ratio. A large keyspace (e.g. 1 billion) or a more realistic read to write ratio (e.g. 10:1) improves the predicted latency for higher numbers of clients (even 100) back to the best-case baseline single client result, i.e. faster than Jedis with at least 45% cache hit rate (due to memory).
However, there are some other metrics that the model can predict that we haven’t considered yet: cache warm up time, latency under increased load, and throughput.
Cache warm up time is the time taken to preload the cache to the desired cache hit rate (due to memory). For 1 million keys it takes a significant 5.5 minutes to warm the cache to an initial 100%. For 1 billion keys it naturally takes significantly longer (and in practice you probably wouldn’t preload all of it, and you could just let it warm up naturally due to gets). You should also ensure that the Redis cluster has sufficient capacity to cope with the initial higher loads due to cache preloading.
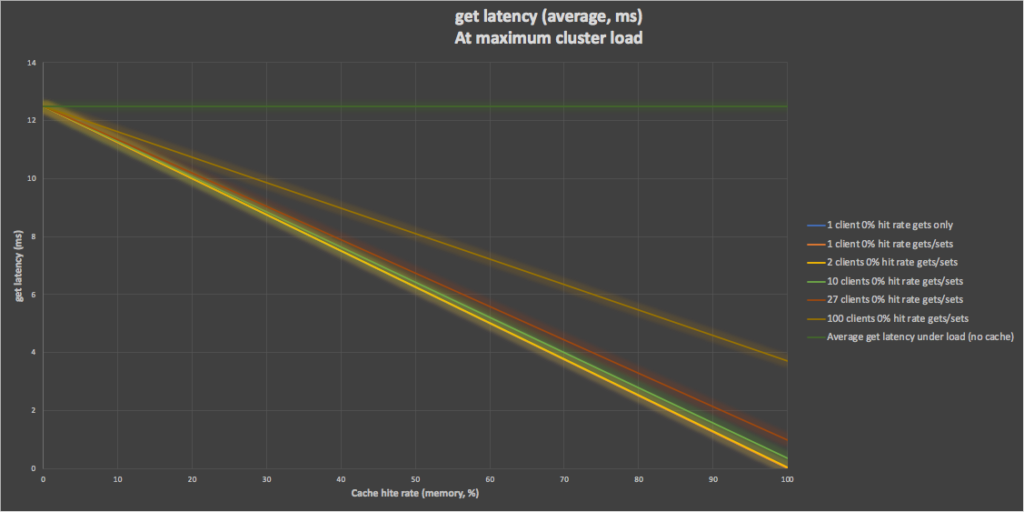
So far we’ve assumed best case latency under load. From the previous blog, however, we know that the latency increases under load and the maximum usable capacity of a 6 node cluster is around 5 million ops/s with a “get” latency of 12.5ms. It’s easy to recalibrate the model to produce “get” latency predictions with this higher latency for 0% cache hit rate and shows that even with 100 clients the latency can be improved from the worst case of 12.5ms to 8ms at 50% cache hit rate and 3.7ms at 100%. Of course, the improvement is even better with fewer clients, but in practice, the higher number of clients is likely correlated with a higher load on the cluster resulting in the higher baseline “get” latency.
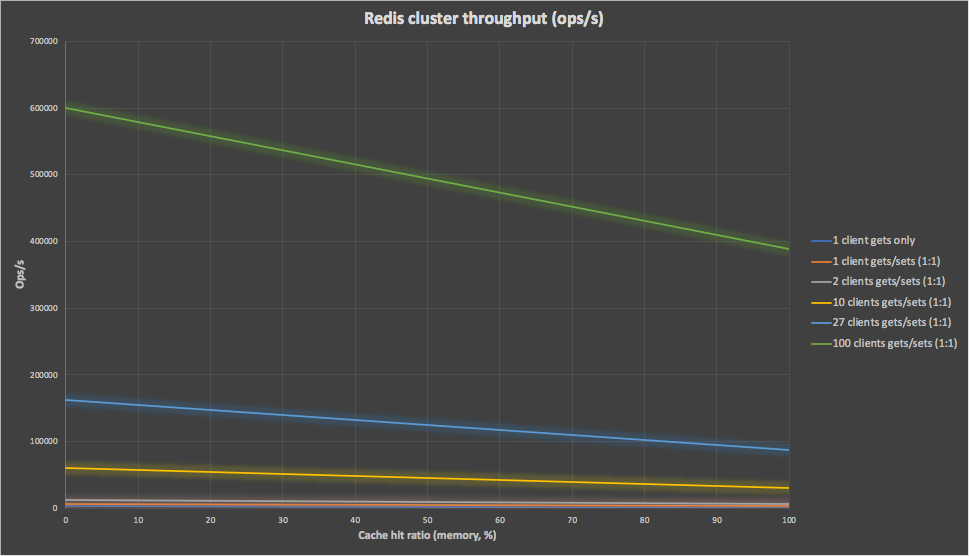
Client-side caching can also reduce the load on the Redis cluster, as for each cache hit no server side get request is issued. The model computes the load on the Redis cluster with increased cache hit ratios, and this graph shows the significant reduction in load, particularly for higher cache hit ratios and number of clients. The side-effect of this is that the Redis cluster has increased capacity so the client side throughput can be increased without further cluster resources being added. For example, for 100 clients, at 50% cache the throughput is reduced by 18%, and at 100% cache, by 35%.
Finally, given that the latency reduces with increasing cache hit rate, the client-side throughput would naturally increase significantly (approximately x100). However, the current model assumed a fixed (but parameterized) workload. A model with a client-side workload that changes with the latency could be implemented, but this isn’t trivial as the model needs to be enhanced to be load-dependent (to take into account dependencies between load and latency).
6. Conclusions
Jedis and Redisson are both good open source Redis Java clients with support for Redis clusters. Redisson also offers extra functionality for some caching and cluster operations in a paid version. Jedis is faster for both “get” and “set” operations without the use of client-side caching. However, using Redisson client-side caching, faster “get” latencies can be achieved, potentially even achieving the advertised Redis goal of “sub-ms” latencies!
But how fast depends on a number of factors including client-side cache memory, ratio of “gets” to “sets”, and the number of clients. Using the client-side cache can also reduce the load on the Redis cluster, and enable higher client-side throughputs. A good rule of thumb would be that latency is improved most with cache hit rates > 50% and less “sets”, clients and load, but more substantial throughput savings are achieved with more clients—it just depends what your particular performance/throughput tradeoff goals are in practice. And with all benchmarking and modeling activities, it pays to repeat a similar exercise with your own clusters, applications, clients, and workloads, as the results may differ.
Further resources
Redis Caching
https://dzone.com/articles/how-to-boost-redis-with-local-caching-in-java
https://dzone.com/articles/java-distributed-caching-in-redis
https://redisson.org/glossary/redis-caching.html
https://redis.io/topics/client-side-caching
Redisson Cluster
https://github.com/redisson/redisson/wiki/2.-Configuration#24-cluster-mode
Redisson RLocalCachedMap
https://www.javadoc.io/doc/org.redisson/redisson/latest/org/redisson/api/RLocalCachedMap.html
Jedis Cluster
https://github.com/xetorthio/jedis#jedis-cluster
https://javadoc.io/doc/redis.clients/jedis/latest/redis/clients/jedis/JedisCluster.html
INTERESTED IN MANAGED REDIS?