Introduction
Caching is an important step in increasing the performance of many applications. It can be difficult to determine which caching solution is the best for your use case. Two likely contenders that will often make an appearance in your search for the answer are Redis vs Memcached.
In the green corner is Memcached (est. 2003), the classic, high performance caching solution. In the red corner is Redis, a slightly newer (est. 2009) but very mature and feature-rich caching in-memory database. Below, we’ll take a look at the differences between the two to help you make the decision which to choose.

Table of Contents
- What Is Redis?
- What Is Memcached?
- Redis Vs Memcached
- Data Types
- Persistence
- Data Length
- Data Eviction Policies
- Replication
- Clustering
- Multithreading
- Memcached vs Redis – Features Compared
- When to Use Memcached
- When to Use Redis
- Conclusion
What Is Redis?
Redis’ official website lists Redis as ‘an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message broker.’ To expand on this a little, Redis is a way to store key-value pairs, in a selection of different data types such as Lists, Sets, and Hashes. Redis keeps this data in memory, meaning that it is extremely fast to return the data when requested. This speed makes it perfect as a cache for your application where you need to request and return data and speed is an important factor.
You can read more about what Redis is and what you might use it for here.
What Is Memcached?
Memcached’s website describes Memcached as a ‘Free and open source, high-performance, distributed memory object caching system’. Like Redis, Memcached is an open source way to store key value pairs in memory, meaning that data is very quickly retrieved. This makes Memcached another way to return data where speed is a factor. Memcached is also multithreaded, meaning that there may be some performance improvements where your application can utilize multiple cores.
Redis Vs Memcached
What Is the Same About Redis and Memcached?
At face value, Redis and Memcached look like they do the same thing.
Both Redis and Memcached:
- Store data in memory for fast retrieval, making them perfect targets for caching.
- Are a NoSQL data store, keeping data as key value pairs.
- Are both open source, with plenty of documentation to help get set up.
However, as we look deeper into them both below, it can be seen that the full feature sets are different between the two, and that careful consideration is required before deciding which to choose.
What Is Different About Redis and Memcached?
There are a number of key differences between Redis and Memcached which need to be mentioned. These differences are very specific around how Redis and Memcached handle the data they are caching, and how they are able to deal with it at scale.
Data Types:
When storing data, Redis stores data as specific data types, whereas Memcached only stores data as strings. Because of this, Redis can change data in place without having to re-upload the entire data value. This reduces network overhead. Below I cover the different types of data that Redis can handle.
String
Strings are a basic value to store data. Redis strings are binary safe, which means that strings can store something like a small image. String values can be up to 512MB in length.
List
Redis Lists are a way to store unordered data, which can then be accessed by index. Redis implements what is known as a Linked List which is a slightly different way of implementing lists than an Array. What this means is that Redis is extremely fast and consistent when adding or removing a value from the start or end of a list.
Hash
Hashes, or dictionaries as they are known in some languages, allow for the storage of tightly related data in a series of fields with their own key value relationships. Although it is very similar to common data structures in programming languages it is important to note there isn’t always a 1:1 mapping as Redis’ version is fairly “flat” (e.g. a Python dictionary can be nested and hold different types of objects and cannot be stored into a Redis Hash easily if it has these properties).
Set
Sets are unordered collections of unique items. Sets can add, remove, and test for the existence of members. The benefit of a set over a list is that a set does not allow duplicates, meaning that for data where you are just storing a unique key, if it does not exist, you can just add the key and know that it will be unique within the set.
Sorted Set
Sorted sets are an expansion of the Redis set, where they are a collection of unique strings. However each member of the Redis sorted set is given a score to help order the set. Sorted sets also allow for accessing ranges based on the score given by Redis.
Persistence:
Redis allows for persistence to disk, meaning that the data in Redis’ database can be stored and recovered in the event of the Redis server crashing or being rebooted. Whilst memory is fantastic for speed, it does have the caveat that if the server goes down, the data on the memory is lost. Redis’ persistence is not 100% data safe, depending on the type of persistence used there may be between a few seconds and several minutes of changed data, but the persistence is better than none at all. Memcached does not have the ability to persist to disk natively. Instaclustr enables persistence as default, ensuring that even a new cluster can recover from an outage, with nodes restarting with a “warm cache”. There are two different ways to persist data in Redis:
AOF Log
AOF stands for Append Only File, and for Redis, works by appending all write operations received by the server. The AOF Log stores all of these commands in the same format Redis receives them, which means they can be replayed back to the instance at boot to reconstruct the current state.
AOF Log can be configured to write to the disk in a few different ways, all with their own advantages and disadvantages. The AOF can be configured to flush (that is, write the buffer to disk) every received Redis operation, every one second, or as often as is configured in the host operating system—which is usually around 30 seconds for Linux. Redis recommends writing once per second, as this is a good balance between disk writes (which are slow) and data security (the amount of data that can be lost in the event of a failure).
RDB Snapshot
RDB stands for Redis Database Backup file, which is a way to take a full snapshot of the current Redis state. The RDB is a compact way to store the current Redis state in a file which can be transferred elsewhere (that is, offsite for disaster recovery). RDB works by creating a child process of the Redis instance, and letting the child process complete the backup. This means that the parent redis process isn’t occupied creating the RDB file and writing to disk, leaving it free to do the normal Redis work. RDB also works well for large datasets over the AOF Log, as it doesn’t have to replay the Redis instance line by line.
RDB has the downside that it may take a period of time to create the file. As the child process forks from the parent process (essentially a duplicate at that time), the RDB file will be as the Redis data is at that point. So, for example, if the AOF process runs every 10 minutes, the RDB file is created which takes 5 minutes, and then before the RDB process starts again the Instance fails, you will have lost up to 10 minutes of Redis data. For this reason RDB is better as a backup only.
Both methods have their uses, and Redis documentation recommends using a combination of both, so that you can recover in the event of a full server outage.
Data Length:
Redis data keys and strings can be up to 512 MB (megabytes) in length although strings of this size are generally not recommended for performance reasons. As they are binary safe, you can also store any kind of data, even a JPEG image. Memcached supports a key of only 250 bytes and values are capped at 1MB by default (but this can be increased by changing settings). If you have larger data objects, Redis can be a better choice than trying to work around these limits.
Data Eviction Policies:
As memory is finite on servers, stale data in a cache must be automatically ‘evicted’ from the memory to make way for new data. This is handled through a process called data eviction. Both Redis and Memcached have ways of handling this, however they aren’t always the same. A common way to evict data is called Least Recently Used—evicting the data that hasn’t been hit recently. If the data is hit, it is noted, meaning it won’t be a candidate for eviction. This is the only way that Memcached works. However, Redis offers a number of other ways to deal with data eviction, such as No Eviction where Redis just lets the memory fill up and then not take any more keys, and Volatile TTL (Time to Live), where Redis will attempt to remove keys with a set TTL first, in an attempt to preserve data not annotated with a TTL that was meant to persist for longer.
Replication:
Replication is a way in which to copy data from one instance to another creating a Replica. The intention is to ensure a duplicate copy of data is kept within another instance, in the event the master instance experiences an outage. Redis supports replication natively and is able to replicate in a master to follower fashion. Redis instances can also have more than one replica for added redundancy. Memcached does not support replication without third party software.
Clustering:
Clustering is a way of ensuring high availability of a service by creating a number of instances and connecting them together to form a cluster. Creating clusters can sometimes be difficult to set up and manage when the software is not designed for it. As a solution for scalable caching, Redis offers Redis Cluster, which enables clustering features for Redis.
There are many benefits to using Redis in a cluster rather than just as a standalone instance:
Performance
Redis will experience improved performance as load from clients are spread across multiple clusters. Cluster aware drivers understand which node the data is on and connect directly do that node.
Availability
Using a combination of replication along with clustering allows for high availability for applications. Redis Cluster can be set up with a selection of master instances, and connected replicas. If a single master goes offline in the cluster, it can failover, and the replica will be automatically promoted to master in the cluster. When the failed instance comes online again, it will automatically sync as the replica for the new master. Replicas can be kept in separate racks for redundancy.
Pricing and Scalability
As Redis is memory intensive, clustering allows for horizontal scalability, where load is spread over multiple instances with smaller memory footprints, rather than a single instance with a lot of memory. In a traditional server application instance, to get better performance from the application, you could increase the system resources via vertical scaling. At some point though the system will be limited by either availability of technology to increase the size of the server or, the more likely scenario, it is no longer cost effective to increase the machine resources. The main alternative to this is called horizontal scaling, where servers with smaller resources are grouped together in a cluster. The cluster will have the same or better performance as vertical scaling at a smaller cost. Horizontal scaling can be particularly important for Redis, as memory is very expensive as the size increases.
Multithreading:
Memcached formerly had the advantage over Redis in multithreading speed. This meant that in certain situations, Memcached could outperform Redis. However, as of Redis 6, multithreading is supported in Redis and because of this should see an improvement in multithreaded workloads.
Memcached vs Redis – Features Compared:
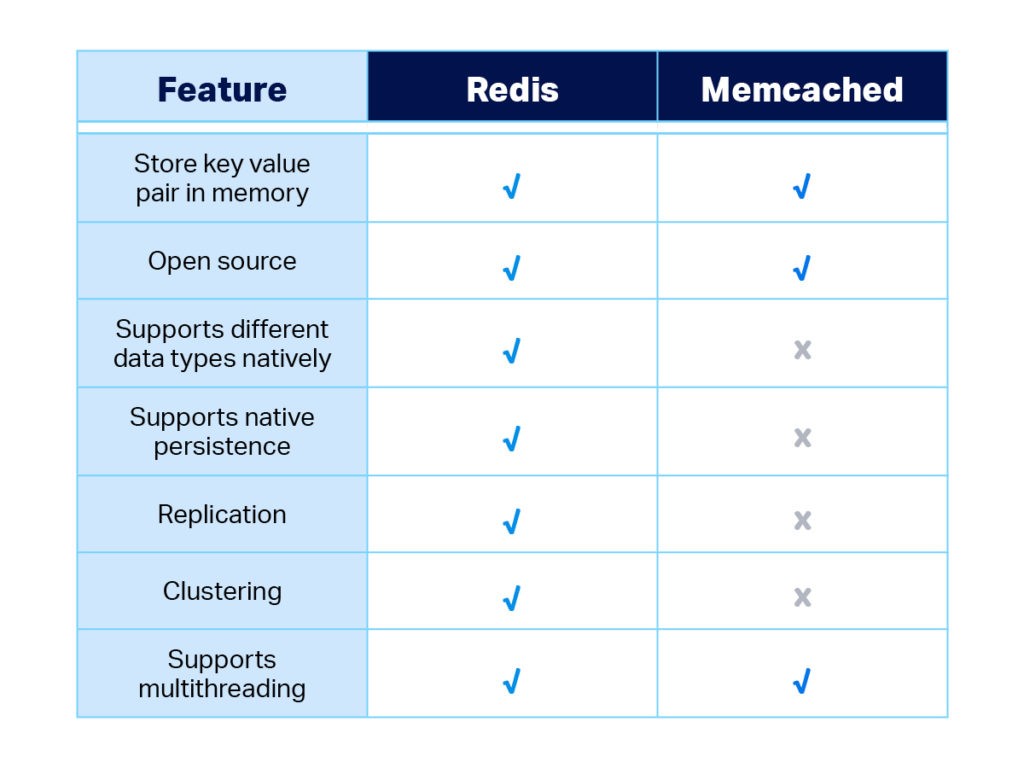
When to Use Memcached:
Memcached is, by design, very simple to set up and use. If you had an extremely simple application on only a few servers, and only required simple string interpretation for your application, then Memcached may be the correct choice for you. However, even with small workloads, it may be worth the little extra effort to set up Redis, as it has the option for expandability later on.
When to Use Redis:
Redis is a very well rounded, mature product, with active ongoing development. It has a bunch of features and really gives the option for expandability into the future. You should be using Redis when:
- You need access to a wider set of data structures and stream processing capability.
- The ability to modify and change keys and values in place is required.
- Custom data eviction policies are required (for example, needing to keep keys with a longer Time to Live, even if the system is out of memory).
- You need to persist your data to disk for backups and warm restarts.
- You need to have high availability or scalability of your application, through the use of replicas and clustering.
Conclusion:
Memcached was one of the first popular open source memory caching solutions and works well for basic key value workloads. However, if you are working in the enterprise, or are just looking for a more modern, feature rich and actively developed product, Redis is the best solution. You can try Redis today with a free trial of our managed Redis clusters, and see what Redis can do for your web applications or see Instaclustr Pricing Here.
If you have questions about Instaclustr’s managed Redis clusters get in touch today to discuss options.