In Part 3 of this Elasticsearch blog series we pick up where we left off in Part 2, looking under the hood at how clustering works. We’ll take Elasticsearch for a spin around the race track with Mussa Shirazi, one of Instaclustr’s resident Elasticsearch professionals! We’ll explore indexing in more detail, and see how indexing solves some real Elasticsearch use cases and how Elasticsearch works in practice.
 (Source: Shutterstock)
(Source: Shutterstock)
Then may I set the world on wheels,
when she can spin for her living. (Two Gentlemen of Verona, III, 1)
The weary sun hath made a golden set,
And by the bright track of his fiery car,
Gives signal, of a goodly day to-morrow. (Richard III, V, 3)
Thy burning car never had scorch’d the earth! (Henry VI, Part III, II, 6)
(Surprisingly Shakespeare mentions wheels, spinning, and cars frequently)
Paul:
Hi again Mussa! The word “index” occurred a lot in the first Q&A (60 times!) so I guess it must be important. I understand that Elasticsearch uses an “Inverted” Index, could you explain how this works with an example?
Mussa:
In order to understand how Elasticsearch keeps track of word order in a document, let’s take a more detailed approach to how Elasticsearch works under the hood. So, when you work with Elasticsearch you have a cluster which consists of nodes and within an Elasticsearch cluster you have Elasticsearch indexes which can span over multiple nodes through shards— a shard is a Lucene index as mentioned previously, and Lucene is the full-text library.
A Lucene index further divides into segments which are sort of like mini indices and within these segments you have data structures such as inverted indexes, stored fields and document values etc. This diagram shows the structure of a node with an Elasticsearch index, multiple shards and Lucene indices, and multiple segments.
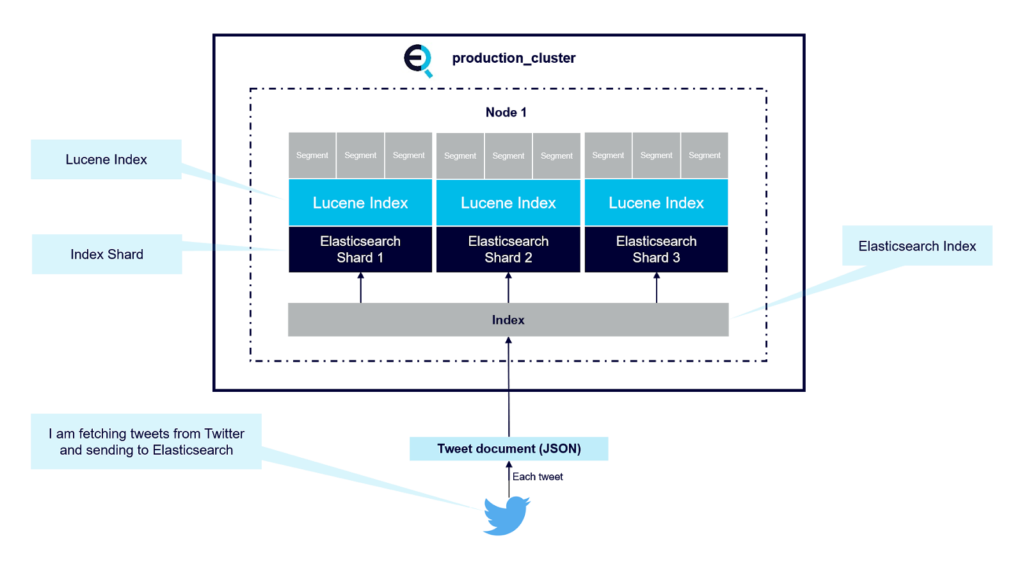
So, an inverted index is the key data structure to understand when you work with search. It consists of two parts, the sorted dictionary which contains the index terms, and for every term you have a posting list which is the document containing the term; so when you do a search you first operate on the sorted dictionary and then process the postings. Let’s take an example of a document set with three simple documents:
- Elasticsearch is best
- Node is the part of Elasticsearch cluster
- The Instaclustr offered Elasticsearch managed cluster
Once we index these documents in Elasticsearch, after some simple text processing (lowercasing, removing punctuation, and splitting or tokenizing on the whitespace in the words), Elasticsearch can construct the “inverted index” shown in the table below.
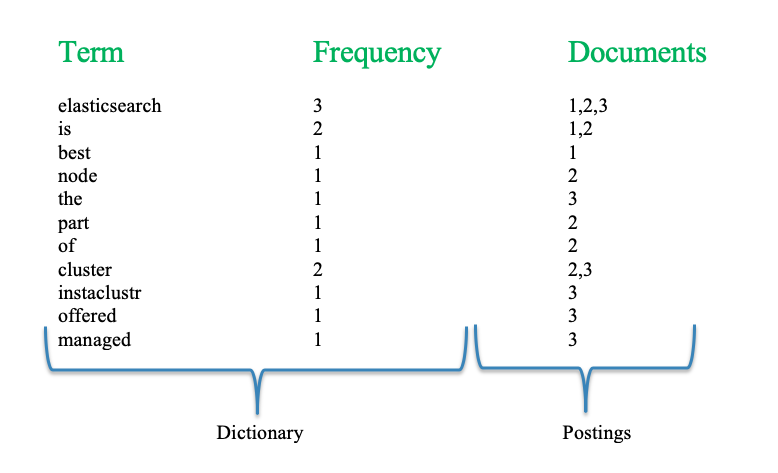
So, when you want to search, for example, for the words “Elasticsearch cluster”, Elasticsearch first finds the terms in the dictionary and then intersects or unions the postings (list) depending on what type of search you want. For example, an intersection search (logical AND) for these two words returns documents 2 and 3. This is a simple example, but the principle is the same for all kinds of searches. First Elasticsearch operates on the dictionary to find the searched terms and then operates on the postings of the documents.
Paul:
I noticed that Elasticsearch supports regular expression search. What’s the difference between using regular expression search and normal search? What are some use cases for regular expressions? Is there different performance?
Mussa:
Following on from the previous question (where we talked about the inverted indexes), consequently, an index term is the unit of search. The terms we generate dictate what types of searches we can (and cannot) efficiently perform. For example, when you do a simple search, Elasticsearch looks for the terms in the dictionary and gives us the documents containing the terms in these documents. However, there are situations where users may not know the single exact term. Let’s take an example, my first name is “mussa” and let’s suppose someone is looking to search my name and they only know the first 3 letters “mus” of my name. We cannot efficiently perform a search on everything that contains “mus”. To do so, we would have to traverse all the terms, to find that “mussa” also contains the substring.
Regardless of the situation, regular expressions, also known as “regexps”, and wildcard queries can be used on Elasticsearch fields of type keyword and text to allow for partial matching.
There are three important things to know about regular expressions in Elasticsearch.
- Matching is done at the token level, not the string level.
- The operators and syntax are different from most other languages.
- Wildcard matchers dramatically affect performance.
Another alternative to regex is to use n-grams (which we will talk about in the next question – Paul).
Below are some example of simple and wildcard/regex queries:
Simple match query:
The query below will look for the documents where the name field contain the string “mussa”:
GET persons/_search
{
"query": {
"match" : {
"name" : "mussa"
}
}
}
Wildcard queries:
Wildcard queries allow you to specify a pattern to match instead an exact term.
To create a wildcard query for Elasticsearch, you need to specify the wildcard option in your query, followed by a string pattern and asterisks (*), all contained within double quotes.
The query below will return documents containing names like “mussa”, “musa”, “mussaa”, etc:
GET persons/_search
{
"query": {
"wildcard" : {
"name" : "mus*"
}
}
}
Regexp Queries:
Another method for broadening your searches to include partial matches is to use a “regexp” query, which functions in a similar manner to “wildcard”. For example (where “.” matches any single character):
GET person/_search
{
"query": {
"regexp":{
"name": "mus.a"
}
}
}
Paul:
You promised to explain n-grams (and I started to explore them in part 1 of the blog)—how do they work? When would you use them? How applicable are they to non-English languages?
Mussa:
What is an n-gram? Well, in this context an n-gram is just a sequence of characters constructed by taking a substring of a given string. As I explained before (Question 4) “You can find only terms that exist in the inverted index.” Although the prefix, wildcard, and regexp queries demonstrated that is not strictly true, it is true that doing a single-term lookup is much faster than iterating through the terms list to find matching terms on the fly.
Preparing your data for partial matching ahead of time will increase your search performance.
An n-gram can be best thought of as a moving window on a word. The n stands for a length. If we were to n-gram the string (album), the results would depend on the length we have chosen:
Length 1 (unigram): [ a, l, b, u, m ]
Length 2 (bigram): [ al, lb, bu, um ]
Length 3 (trigram): [ alb, lbu, bum ]
Length 4 (four-gram): [ albu, lbum ]
Length 5 (five-gram): [ album ]
In Elasticsearch n-grams are normally used for autocomplete and search as you type features. For example, e-commerce platforms are heavily used by users and making sure that products are super easy to be found is crucial for companies, here’s an example:

For search-as-you-type, Elasticsearch uses a specialized form of n-grams called edge n-grams. Edge n-grams are anchored to the beginning of the word. Edge n-gramming the word ‘album’ would result in these suggestions:
- a
- al
- alb
- lbum
- album
Yes you are right, n-grams can be used to search languages with compound words.
Paul:
That’s cool, I guess n-grams would work well with say German, which is known for longish words, e.g. “Bezirksschornsteinfegermeister” means “head district chimney sweep”! The Elasticsearch course I completed recently mentioned search relevance but didn’t go into any detail, so could you tell me how Elasticsearch computes relevance? Can it be customized?
Mussa:
Elasticsearch uses the concept of relevance to sort the resultant document set. In the world of Elasticsearch, this concept is referred to as scoring. Each document will have a score associated with it represented by a positive floating-point number. The higher the score of a document the more relevant the document is. Score is directly proportional to the query match. Each clause in the query will contribute to the score of the document.
And yes, you can use a script to provide a custom score for returned documents, the details are here.
Paul:
In the course I did, every time they made a change to an index (e.g. to change mappings) they deleted the index and started from scratch. This seemed inefficient, and what if you don’t have the original documents? Is there a trick to create a new index from an old index?
Mussa:
Yes, you can use the reindex operation. With the reindex operation, you can copy all or a subset of documents that you select through a query to another index. Reindex is a POST operation. In its most basic form, you specify a source index and a destination index.
Paul:
I guess another approach would be to create a new index rather than start from scratch or reindex? Can/should you have more than one index for the same documents?
Mussa:
Yes, it is possible, and I have seen companies using the same document indexed with multiple indices. Let’s take an example of network log messages. Operational teams may be interested in certain types of information in the log message, whereas security teams may be interested in more granular level detail in the message. So, we can use a tool like Logstash which can enrich the document in different ways and index to multiple indices.
Paul:
Say I have lots of unstructured text data. How can I import all of it into Elasticsearch and have it automatically indexed?
Mussa:
There are different ways you can index your data. If you are a developer and can convert your text into JSON format then you can use Elasticsearch bulk api to index your text data into Elasticsearch. Otherwise you can also use tools like Logstash, Filebeat, and Fluntd to index your data into Elasticsearch. You don’t have to be a developer to index the data using these tools and can easily index data with few simple steps.
Paul:
Elasticsearch SQL looks elegant, but I haven’t tried it out in detail. Does Elasticsearch SQL have any limitations? Are there any performance implications?
Mussa:
Both Elastic and Open Distro for Elasticsearch have developed their own SQL plugin to write queries in SQL rather than the Elasticsearch query domain-specific language (DSL). If you’re already familiar with SQL and don’t want to learn the query DSL, this feature is a great option. However, the SQL plugins do have limitations! You can do aggregations in SQL, but with limited functionality. Also, there are performance implications when you run very large queries using SQL plugins. For more information visit Open Distro for Elasticsearch and Elastic SQL documentation. One important thing to note is that SQL for Open Distro for Elasticsearch is totally free, however, if you are using the Elastic.co distribution then you will have to have the x-pack license.
Paul:
Now you’d think that Elasticsearch is all about letters rather than numbers. However, you have mentioned some “magic” numbers already (e.g. 2,147,483,519!) and I’m curious to find out more about what the limits of Elasticsearch are, and how to get the best performance out of an Elasticsearch cluster.
For example, what exactly is a “document”, and how big can/should it be?
Mussa:
A document is a basic unit of information that can be indexed. Documents are serialized into JSON and stored in Elasticsearch.
Some examples of documents are:
- an entry in a log file
- a tweet
- some system metric values
- a blog post
- a comment made by a customer on your website
- a row of a csv file
- the weather details from a weather station at a specific moment.
In Elasticsearch the default size of the document is set up to be 100mb (http.max_content_length). Elasticsearch will refuse to index any document that is larger than that, but you can increase this limit to a higher value, however you cannot index more than 2GB size, as this is the hard limit of the Lucene Index. Even without considering hard limits, large documents are usually not practical, and large documents put more stress on the network, memory usage, and disk.
Paul:
How big can an index be? How big can a shard be?
Mussa:
There is no theoretical limit to the size of an Elasticsearch Index. Same for a shard, however, you cannot go over 2 billion documents per shard—which is also the Lucene index limit. The number of shards you can hold on a node will be proportional to the amount of heap you have available, but there is no fixed limit enforced by Elasticsearch. A good rule-of-thumb is to ensure you keep the number of shards per node below 20 per GB of heap it has configured. A node with a 30GB heap should therefore have a maximum of 600 shards, but the further below this limit you can keep it the better. This will generally help the cluster stay in good health.
Paul:
Ok, you’ve convinced me that it’s not sensible to try and index all of Wikipedia as a single document (> 16GB compressed)! I believe that primary shards determine the write capacity of an Elasticsearch cluster, but you can’t add primary shards without re-indexing. How should you do capacity planning and scaling for increased write loads?
Mussa:
This is a typical question I am asked during meetups, and my answer is “it depends”. The reason being that every data set has its own properties, and we cannot use a standard method for capacity planning and shards allocation. One important thing to note is to never over-shard your index as it can lead to lots of issues. The number of shards a node can hold is proportional to the available heap space. As a general rule, the number of shards per GB of heap space should be less than 20.
Aim to keep the average shard size between a few GB and a few tens of GB. For use cases with time-based data, it is common to see shards in the 20GB to 40GB range.
Paul:
That’s the end for this three part (Part 1 and Part 2) blog series where I took Elasticsearch for a spin and discussed the core concepts and architecture of Elasticsearch with a resident expert at Instaclustr.
This week we’ve also just released a hosted and managed Kibana which is a great visualisation and analytics engine that pairs up with Elasticsearch. Don’t hesitate to reach out to us if you want a demo or to have a chat about your needs.