Marry, that’s a bountiful answer that fits all questions
(All’s Well That Ends Well, II, 2)
In Part 1 of this multi-part Elasticsearch Blog I revealed the most interesting things I learnt after taking Elasticsearch for my first “Test Drive”, including that Elasticsearch comes well equipped with some clever-sounding computational linguistics analysis tricks including Stemming, Lemmatization, Levenshtein fuzzy queries, N-grams, and Slop!
After the online course and some exploration I felt like I’d taken Elasticsearch for a short drive and kicked the tires, but I still had more questions than answers so there was obviously still a lot to learn. It, therefore, seemed sensible to quiz one of Instaclustr’s resident Elasticsearch experts, Mussa Shirazi, to find out more about how Elasticsearch is used and how it works under the hood (or bonnet as it’s called here).

Q&A
We did the following interview in “slow motion” over email, that allowed Mussa to add some diagrams.
Paul:
Hi Mussa, thanks for offering to answer some Elasticsearch questions. How long have you been with Instaclustr? What’s your role and what does that involve?
Mussa:
Hi Paul, first of all thanks for having this Q&A session. I have been working with Instaclustr for the last 6 months as a Senior Consultant. I provide support and consultancy for Instaclustr clients on technologies like Elasticsearch, Kafka, and Cassandra. I also give public talks like meetups, workshops, virtual events, and write blogs. Before joining Instaclustr I was working with big financial organizations (exchanges, market data providers, trading companies) here in the United Kingdom and have been involved in designing and deploying big data solutions and search engines using Elasticsearch and Kafka.
Paul:
Thanks Mussa, it sounds like you are definitely the right person to answer my Elasticsearch questions. Here’s my first question: Elasticsearch is built on Lucene but the course I did recently didn’t really explain the Elasticsearch cluster architecture. Could you give me a brief explanation of how the clustering works please?
Mussa:
As you mention Elasticsearch is built on Lucene. Let’s talk a little bit about Lucene. So Lucene is an open source project from The Apache Foundation. It’s a very fast search engine library written in Java and used for full-text search, but it is tough to use directly and has very limited features to scale beyond a single machine. This is where Elasticsearch shines as it makes it very easy to deploy Elasticsearch clusters and scales very quickly. Some of the key features are mentioned in the diagram below.
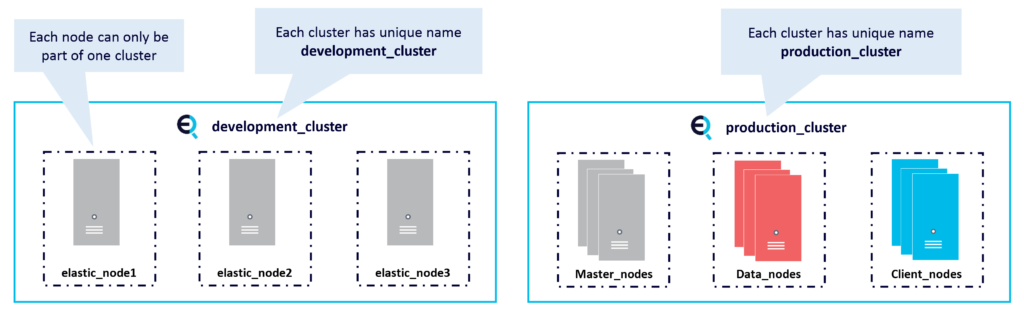
Before we examine how Elasticsearch interacts with Lucene let’s first talk about clusters and nodes. An Elasticsearch cluster is a group of one or more Elasticsearch node instances that are connected together. A cluster automatically reorganizes when nodes join or leave and Elasticsearch makes it very easy to scale the cluster. This diagram shows two Elasticsearch clusters and nodes. On the left is an example of a development cluster consisting of 3 nodes. Whereas on the right is the production cluster with multiple nodes having their own dedicated roles.
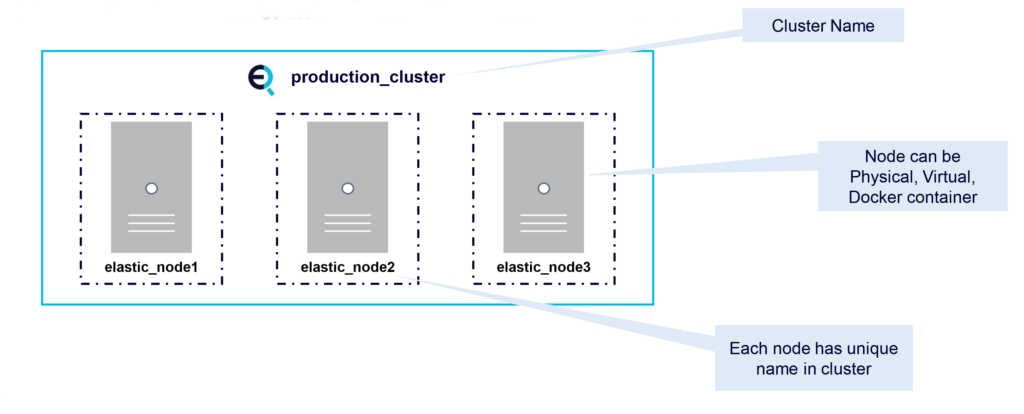
So what is a node? A node is an instance of Elasticsearch. A node can be Physical, Virtual, or a Docker container. Every node has a name and is part of a single cluster. Nodes can even have different roles in an Elasticsearch cluster.
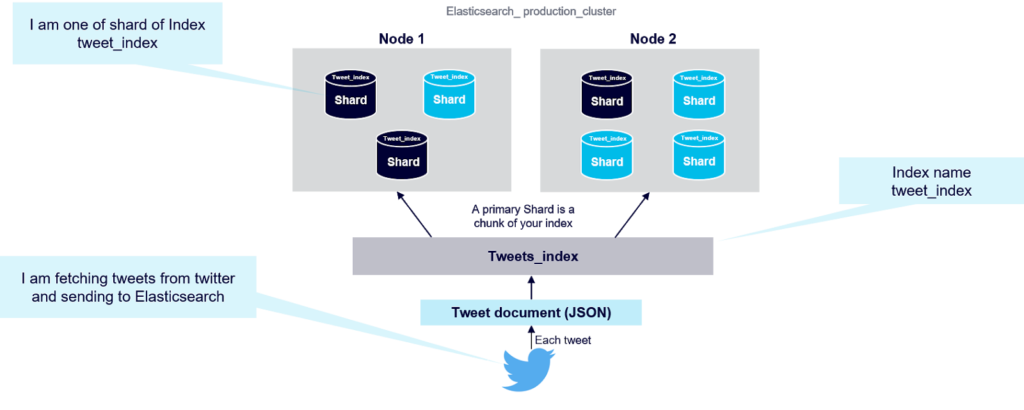
So how does Elasticsearch distribute data among the nodes in a cluster? An Elasticsearch index is a collection of documents that have somewhat similar characteristics. Index data is distributed across an Elasticsearch cluster using shards. A shard is a single piece of an Elasticsearch index. Shards are distributed across multiple nodes in Elasticsearch cluster, and redundancy is obtained by replicating shards across multiple nodes using primaries and replicas. Elasticsearch automatically manages the arrangement of these shards (see diagram below):
So where does Lucene fit in, and how do we interact with it? There’s no need to interact with Lucene directly, at least most of the time, when running Elasticsearch. As mentioned above each Elasticsearch index is divided into shards. Shards are both logical and physical divisions of an index. Each Elasticsearch shard is a Lucene index. The maximum number of documents you can have in a Lucene index is 2,147,483,519. The Lucene index is divided into smaller files called segments. A segment is a small Lucene index. Lucene searches in all segments sequentially. This diagram explains the architecture.
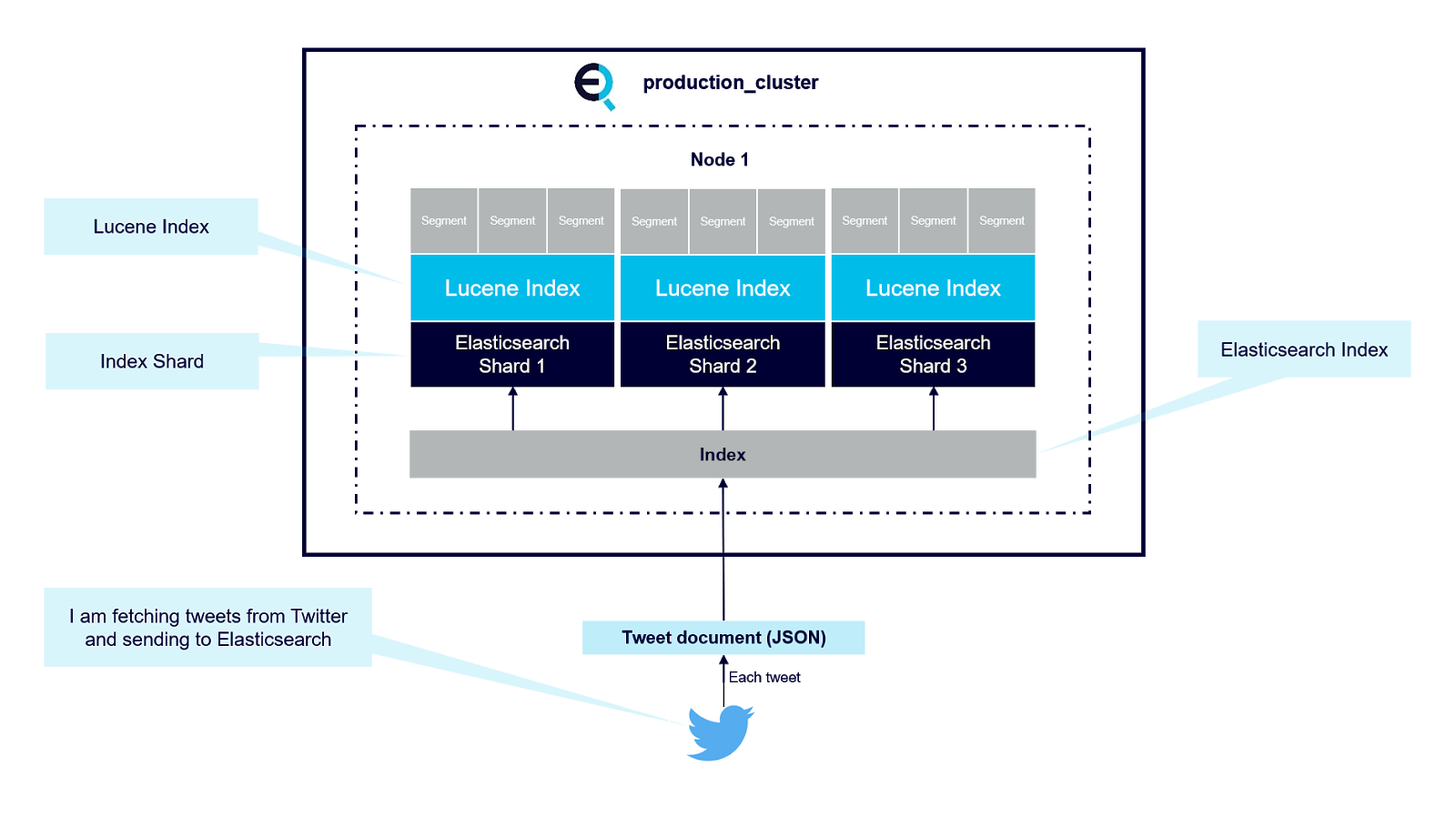
Lucene creates a segment when a new writer is opened, and when a writer commits or is closed. It means segments are immutable. When you add new documents into your Elasticsearch index, Lucene creates a new segment and writes it. Lucene can also create more segments when the indexing throughput is important. Important to note is that the more segments you have, the slower the search. This is because Lucene has to search through all the segments in sequence, not in parallel. Having a small number of segments improves search performances. That’s why it’s important we do not create unnecessary extra Elasticsearch Shards.
Paul:
Wow, that’s amazing, Elasticsearch is really clever at handling all the complexity of running Lucene in a distributed cluster! Your diagrams are very helpful to understand what’s going on under the hood.
You mentioned that nodes can have different roles? I’ve heard of “Master” nodes but I don’t know what they do, or what the other node types are. What are “Master” nodes? How many Master nodes can you have? What are the other node types called? What do they do differently?
Mussa:
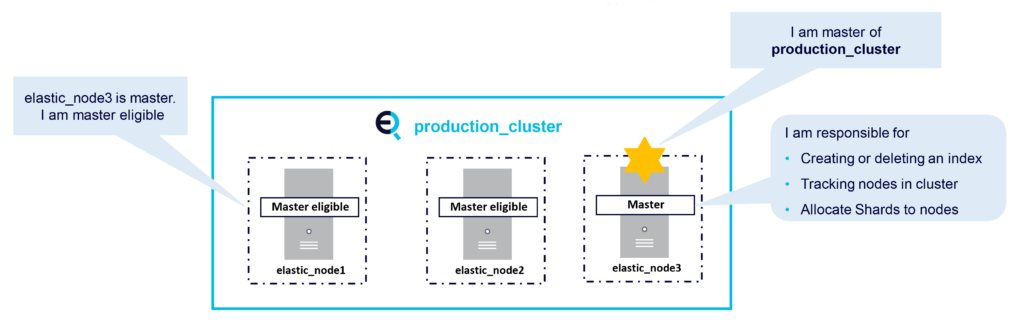
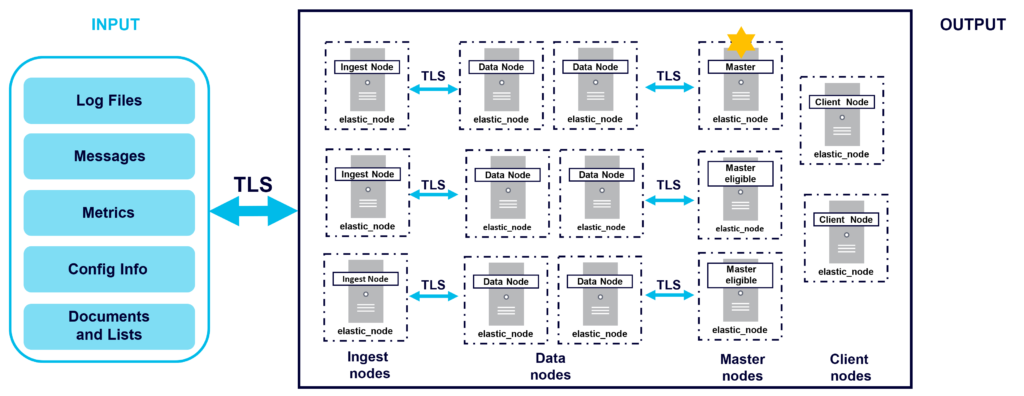
The Master node is responsible for cluster related tasks such as creating or deleting Indices, tracking nodes, and allocating shards to nodes. There can only be one master node in an Elasticsearch cluster. The Master node is elected from master-eligible nodes. It is recommended to have dedicated master eligible nodes in a large cluster.
This diagram shows an example production cluster with a Master node and Master eligible nodes:
Other node types are as follows:
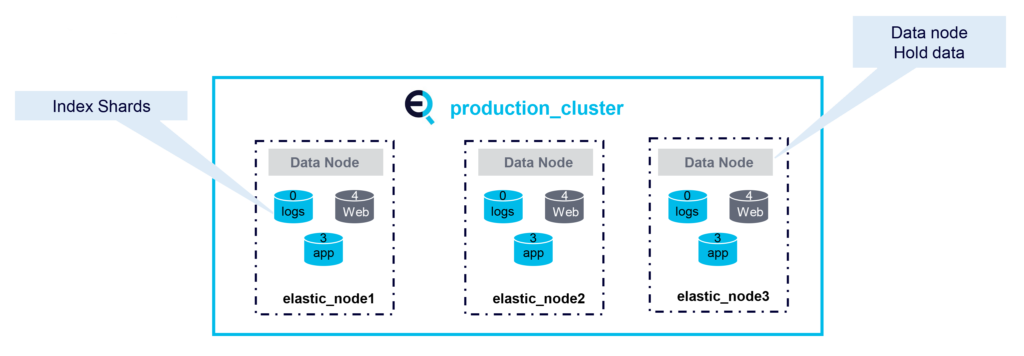
Data Nodes:
Data nodes hold data and perform data-related operations. All nodes are data nodes by default. Data nodes handle data-related tasks such as CRUD operations, search, and aggregations:
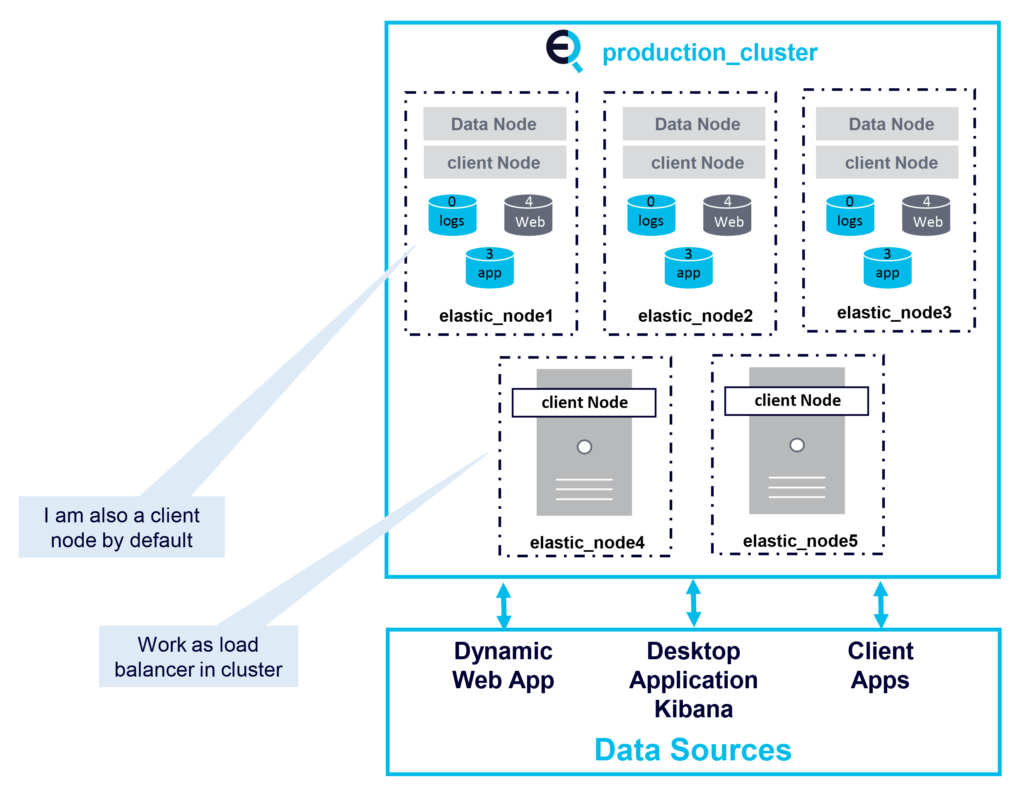
Coordinating Nodes:
Coordinating nodes forward cluster requests to master and data nodes. Every node is implicitly a coordinating node. Coordinating nodes act like a smart load balancer, so reduce load on data and master nodes on large clusters:
Ingest Nodes:
Ingest nodes are used for pre-processing documents before the actual document indexing happens. Use for transformation of document before indexing. All nodes in a cluster are Ingest nodes by default. Pipelines can be defined that specify a series of processors to enrich data before indexing:
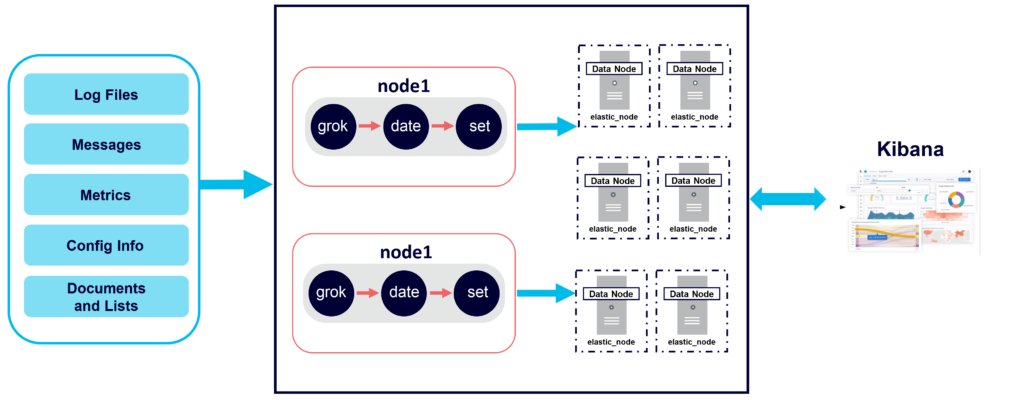
In large Elasticsearch clusters it is recommended to have dedicated nodes (e.g. Ingest, Data, Master, and Client nodes) as shown in the following diagram:
Paul:
It looks like the internal Elasticsearch architecture can be customized to fit lots of different use cases. I see from the Instaclustr Elasticsearch support documentation that you can provision an Elasticsearch cluster with three dedicated master-eligible nodes (i.e. they don’t participate in searching and indexing to ensure that they are ready and responsive if the master node fails, and they can also be smaller instance types than data nodes).
So now I’ve got a much better idea of how an Elasticsearch cluster works, but I wonder if Elasticsearch actually provides any functionality that Lucene doesn’t have?
Mussa:
Yes, lots, including:
- REST API
- Query DSL
- Distributed system (sharding, replication, cluster management)
- Facets/aggregations
- Additional features for common usage (e.g. ingest processing) and management (APIs for monitoring its relevant metrics, backup and restore, etc.)
- Graphical tools like Kibana and Grafana can connect to Elasticsearch data, so you can create powerful dashboards based on Elasticsearch data.
Paul:
Thanks Mussa! It’s very apparent that Elasticsearch is really a complete system for searching and related operations! That’s a lot to take in, so let’s pause here, put the hood down, and come back to the rest of the questions and answers in the next part (where we take Elasticsearch for a spin around a race track!)
Whether you’re looking for a complete managed solution, or are in need of enterprise support or consulting services, we’re here to help.