Kafka Connect is an API and ecosystem of 3rd party connectors that enables Apache Kafka to be scalable, reliable, and easily integrated with other heterogeneous systems (such as Cassandra, Spark, and Elassandra) without having to write any extra code. This blog is an overview of Kafka Connect Architecture with a focus on the main Kafka Connect components and their relationships. We’ll cover Source and Sink Connectors; Connectors, Plugins, Tasks and Workers; Clusters; and Converters.
For an example of how to use Kafka Connect see Apache Kafka “Kongo” Part 4.1 and 4.2: Connecting Kafka to Cassandra with Kafka Connect.
1. Source and Sink Connectors
At a high level, “Source connectors” pull data from an external system (the Source) and write it to Kafka topics. “Sink connectors” read data from Kafka topics and push it to an external system (the Sink). Each connector flavour is unidirectional, you can’t go against the flow. Here’s a simple diagram showing the high level Kafka Connect architecture with Source (green) and Sink (blue) data flows:
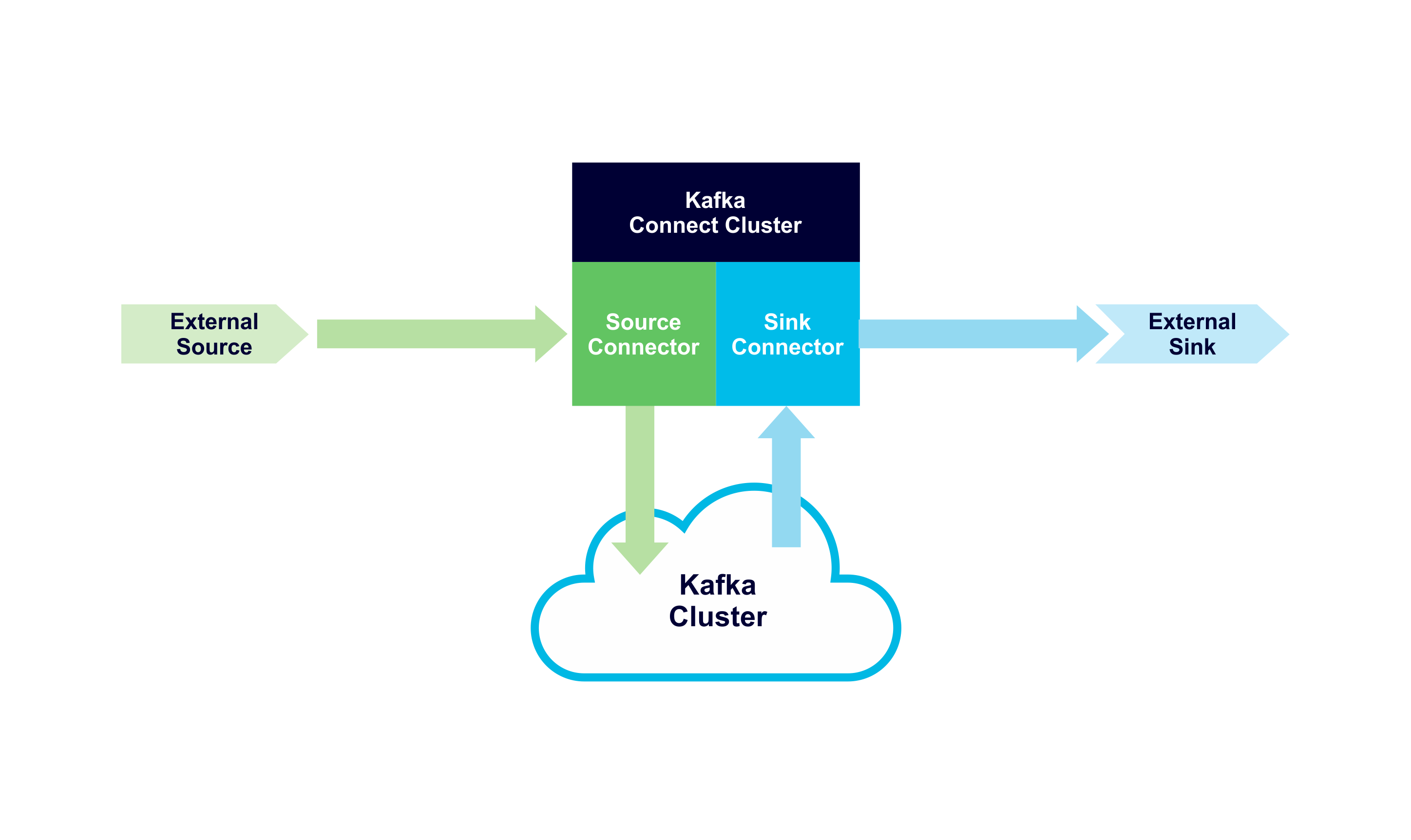
2. Connectors, Plugins, Tasks & Workers
There are three main components to the Kafka Connect API, each with a different role: Connectors, Tasks, and Workers.
Connectors are either Source or Sink Connectors and are responsible for some of the task management, but not the actual data movement.
Tasks come in two corresponding flavours as well, Source and Sink Tasks. A Source Task will contain custom code to get data from the Source system (in the pull() method) and uses a Kafka producer which sends the data to Kafka topics. A Sink Task uses a Kafka consumer to poll Kafka topics and read data, and custom code to push data to the Sink system (in the put() method). Each Sink Task has a thread, and they belong to the same consumer group for load balancing.
The components work together like this (with inspiration from “Kafka: The Definitive Guide”):
Connector “Plugins” (Collections of Connectors and Tasks)
A Connector Plugin is a collection of Connectors and Tasks deployed to each Worker.
Connector
Connectors are responsible for the number of tasks, splitting work between tasks, getting configurations for the tasks from the workers, and passing it to the Tasks. E.g. to decide how many tasks to run for a Sink, a Connector could use the minimum of max. tasks set in the configuration and the number of partitions of the Kafka topic it is reading from). The workers actually start the Tasks.
Tasks
Tasks are responsible for getting data into and out of Kafka (but only on the Source or Sink side, the Workers manage data flow to/from Kafka topics). Once started, Source Tasks poll Source systems and get the data that the Workers send to Kafka topics, and Sink Tasks get records from Kafka via the Worker, and write the records to the Sink system.
Workers
Workers are the processes that execute the Connectors and Tasks. They handle the REST requests that define connectors and configurations, start the connectors and tasks and pass configurations to them. If using distributed workers, and a worker process dies, then the connectors and tasks associated with the failed worked will be taken over and load balanced among the remaining workers.
3. Kafka Connect Clusters
A Kafka Connect Cluster has one (standalone) or more (distributed) Workers running on one or multiple servers, and the Workers manage Connectors and Tasks, distributing work among the available Worker processes. Note that Kafka Connect does not automatically handle restarting or scaling of Workers, so this must be handled with some other solution.
The following diagram shows the main relationships and functions of each component in a connected cluster. A Kafka Connect cluster can be run on one or more servers (for production these will be separate to the servers that the Kafka Brokers are running on), and one (but potentially more) workers on each server. Data movement is shown with green lines:
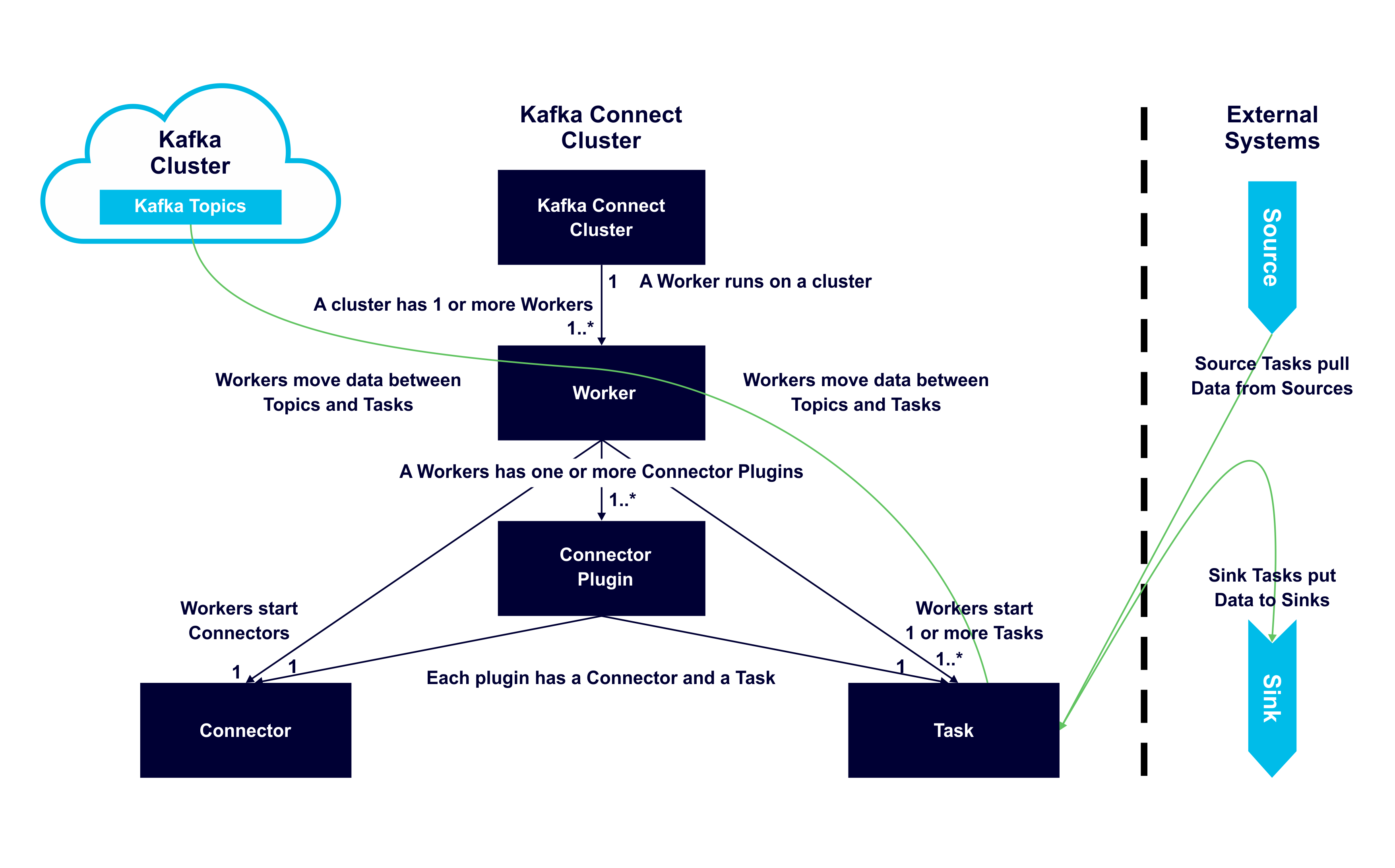
Apache Kafka Connect Architecture UML Diagram
4. Kafka Connect Converters
Just like Catalytic Converters for cars, converters are also a key part of the Kafka connector pipeline! I initially found converters perplexing as Kafka consumers and producers already have (De-)Serializers. Are converters the same or different? Kafka doesn’t know anything about the data format of topic keys and value, it just treats them as byte arrays. So consumers and producers need to be able to convert objects to and from byte arrays, and that’s exactly what the (De-)Serializers do.
Doing some more research on Converters I found that the converter interface docs say:
“The Converter interface provides support for translating between Kafka Connect’s runtime data format and byte. Internally, this likely includes an intermediate step to the format used by the serialization layer.”
I also found that Converter has fromConnectData() and toConnectData() the method that must be implemented for converting byte arrays to/from Kafka Connect Data Objects. Connect “Data Objects” have schemas and values, and a SchemaBuilder which provides a fluent API for constructing Schema objects. Schemas are optional to support cases with schema-free data. ConnectRecords (subclasses SinkRecord and SourceRecord) are analogous to Kafka’s ConsumerRecord and ProducerRecord classes and contain the data read from or written to Kafka.
In conclusion, here’s how Sources, Tasks, Converters, Topics, (De-)Serializers and Sinks fit together to give a complete end-to-end Kafka data pipeline:
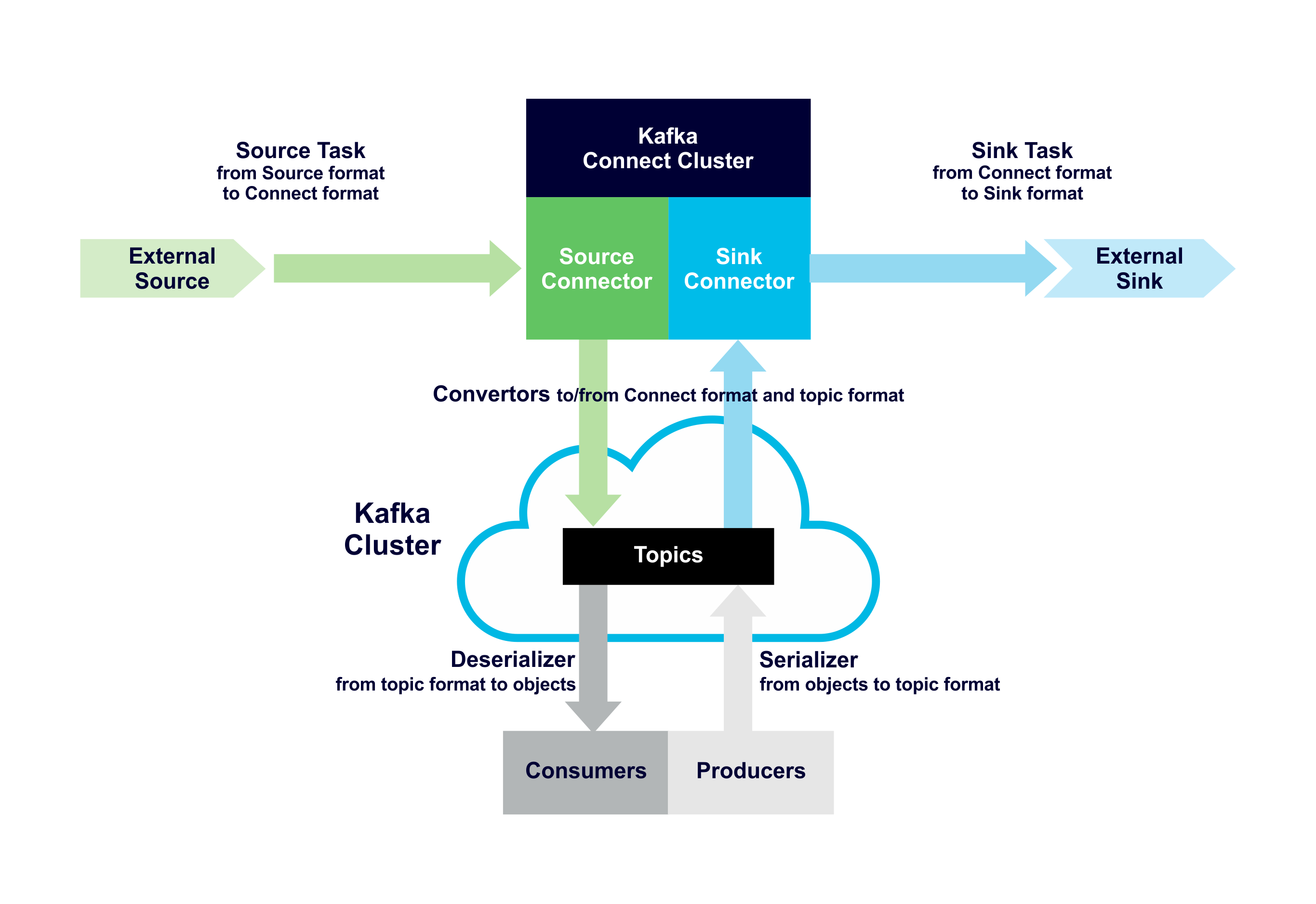
Complete end-to-end Kafka Data Pipeline
Finally, one nice feature of the Kafka Connect architecture is that because converters are decoupled from connectors, you can reuse any Kafka Connect Converter with any Kafka Connect Connector.