Setting the Scene
I was born in the 80’s and growing up I lived through many defining events: multiple financial crises (ongoing), the explosion and decline of Facebook, the birth of the iPhone, and the rise of the CAPTCHA, to name a few.
That last one isn’t as sexy as the iPhone, I admit. Although the first iPhone wasn’t a barnburner, it was the first exposure I had to practical machine learning and AI in the real world.

CAPTCHAs, at the time, took the form of text recognition. As a user, I would look at pictures of text and guess what the second bendy one was. This, of course, was to defeat bots from spamming forms or buying all the tickets to the Foo Fighters concert.
The company behind CAPTCHAs was bought by Google, and the text was sourced from the vast Google Books archive. The books were scanned by Optical Character Recognition (OCR) technology, but older books were faded, smudged or otherwise difficult to read.
Any text that couldn’t be clearly scanned and converted to text were candidates for RECAPTCHA, and the job was offloaded onto the soft, human brains of the world. We filled the gap in the developing world of machine learning algorithms.
Modern Day
Fast forward to today, machine learning and artificial intelligence are much more sophisticated, so advanced now that text recognition is largely solved, and CAPTCHAs needed to evolve.
This year, the covers have come off some truly impressive AI systems. ChatGPT, Stable Diffusion, and others have captured the attention of mainstream audiences like nothing we’ve ever seen before, and the impact will be on the scale of Google mastering search.
These technologies seem poised to revolutionize how we use the internet, and computers in general, and with that in mind, I decided there has never been a better time to go down this rabbit hole myself.
But how easy is that?
I have never taken a machine learning class and have had no real reason to dive into these technologies in my career as a developer. What is the barrier to entry for someone like me—an experienced, handsome, software developer?
In this series, I will be descending into the world of machine learning. Join me as I start from the bare basics and try to build something truly valuable with machine learning.
What is Machine Learning?
The first step is to understand what machine learning is and how it compares to a traditional software application.
A software application contains a set of instructions that the computer needs to perform. These instructions can have decision logic in them and be as complex as you need them to be.
For example, we can create a software application that is designed to identify that a particular two-dimensional shape is a triangle or quadrangle like this:
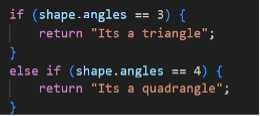
A machine learning solution works differently. Instead of providing the computer with the instructions of how to classify these shapes, you instead provide it with a dataset. In our example, we would create a dataset containing a variety of different examples of triangles and quadrangles, each of which are labelled appropriately.
A machine learning system takes the dataset and a set of parameters from the user and applies tests to the data in order to build itself an internal logic that is able to classify the shapes.
The system iterates over the training data and each time it compares the results it generated to the actual labels of the data until it reaches a threshold of correctness that the user has configured. This is known as the “model,” and what is produced is a piece of code. The end result would look different to our above example, and they generally aren’t designed to be human readable.
The model can then be provided with new images it hasn’t seen and will attempt to classify them using the set of rules it developed during the training process.
What is the Difference Between Machine Learning and AI?
AI (Artificial Intelligence) is a broad field of computer science that includes technologies that attempt to emulate human thought and decision making.
An advanced AI system could understand natural human language, process questions and formulate answers; modern day examples are Apple’s Siri or Google Assistant.
Machine learning is a subset of AI technologies, one piece of the puzzle that is used to develop artificial intelligence systems. Machine learning can assist AI technologies by studying your browsing history and developing a model that would suggest news articles you might like to read or products you want to purchase.
What’s the Plan?
Now that we understand the fundamentals – but before we head out on our learning adventure – it’s helpful to have a goal in mind. It will help focus our journey and allow us to put some of the things we learn into context.
For this, we need data, lots of it, and then we do something useful with that data. Luckily, I already have some data in mind.
I am going to use Instaclustr’s vast real-time metrics stream to create a system that can make predictions about the state of the node or cluster. These types of predictions can add value for our Support team and customers by helping identify potential issues before they become problems.
Instaclustr has thousands of nodes under our managed service. They are spread across different cloud service providers, regions, products, and addons. All these nodes are generating metrics data every second that is being processed by our central metrics processing pipeline.
Currently, these metrics are being used to generate warnings and alerts to our Operations team and inform them of the general health of the clusters. We do have some time-window aware rules in place to help us make informed decisions, but nothing that can make predictions over a longer timeframe.
One of the most obvious and useful trends to analyze is storage capacity. Apache Cassandra®, PostgreSQL®, and Apache Kafka® can ingest huge amounts of data, and disk storage is an important consideration when doing capacity planning and cluster scaling.
So, this will what I’ll be using to focus on our learning path in this series of articles.
Any Framework You Like, as Long as It’s Python
A cursory survey of the machine learning landscape, and you will be likely to find examples using a variety of frameworks, but they will most likely be in Python.
TensorFlow, PyTorch, and Scikit-Learn are all Python based tools that have very polished API’s that make the task of training a machine learning algorithm very simple. They can also leverage other Python libraries which help simplify the learning process, such as mathplotlib, which can help visualize data in a human parsable format.
Of course, this is software development, so these aren’t the only frameworks available. If you want to use C++, you could use TensorFlow, which also has a C++ API, and there is also Caffe, plus solutions in Java, JavaScript, R, and anywhere else you can find a motivated developer.
For our purposes, it’s easiest to select the industry standard, or as close as we can find, so we can focus on problem solving and finding the most community support.
And for us that will be TensorFlow. It’s almost always first or second on any ML framework list and being backed by Google will give us some confidence in the longevity of the solutions we create.
Now in the interest of full transparency, I don’t love Python. The duck typing, *args and **kwargs allows you to build impressively powerful and concise programs that I often can’t figure out how they work. Not to mention how the Python versioning compatibility works!
But I digress. While I normally enjoy a bit more structure, we will persevere and perhaps I will develop a deep love for Python on our path to ML enlightenment.
TensorFlow—Hello, World and Beyond
Having selected TensorFlow as our framework of choice, it’s time to get started with some basic tutorials, and Google has provided a terrific place to start with its Codelab tutorials.
So, let’s start at the root of all programming courses, Hello, World. This tutorial is a great introduction with an easily understood problem; a number pattern that can be parsed easily by a human and can be trained with a simple set of TensorFlow instructions.
In this lab, we are introduced to core machine learning concepts, such as the concepts of training and verification data, optimizers, and loss algorithms.
It was with great enthusiasm that I progressed to the next tutorial and I was quite surprised by what I found. We have moved from a simple number pattern prediction to full on computer vision convolutional neural network.
The problem being proposed was to develop a model which classified pictures of clothing into their category, such as shoes, dresses, or coats. Such was my ignorance in this area, I had to make sure I hadn’t skipped a few steps on my way to this tutorial.
To my delight not only had I moved onto the correct tutorial, but the solution was also amazingly simple.
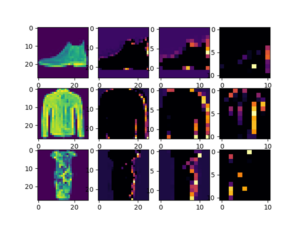
(Source: John Del Castillo)
With 30 lines of code and 20 seconds of training, we can develop a model that is around 90% accurate in categorizing a 28×28 grayscale image of a piece of clothing! And this was only the second tutorial!
Now I was hooked. Over the next few hours, my TensorFlow journey led me through building convolution filters, max pooling reductions, and more. At the end I had a model that could take any photo and determine if it was a person or a horse with 95% accuracy—amazing!
What’s Next?
Running through the Codelabs for TensorFlow was an eye-opening experience, and really showed what machine learning is capable of if you know what you are doing.
Alas, I still don’t know what I’m doing! There’s a lot of detail that is glossed over in these tutorials to get you to a result. Things like selecting effective convolutional filters, number of layers, error and activation functions just to name a few, not to mention how to effectively format and label your input data.
Finally, if we refer back to the original goal of predicting storage space in Apache Cassandra clusters and beyond, computer vision models aren’t going to be particularly useful in this area.
In the next article, we will investigate models that more closely align with our desired goals and start looking at our metrics data and finding ways to format it effectively for training our machine learning models.
Learn more about what Open Source software is and why Enterprises choose it