
A (futuristic!) tandem bike (Image generated using DeepAI)
Apache Spark™ and Apache Kafka®: Some History and Context
In an era when becoming data-driven is a top priority for all companies, open source software (OSS) distributed frameworks like Apache Spark and Apache Kafka have become driving forces—the former for Big Data workloads and the latter focusing on event streaming.
With remarkable (and not to mention rapid) advancements in AI (ChatGPT being just one among many new offerings), Machine Learning (ML) is gaining significant interest and traction with the public, both data experts and curious users alike.
It is increasingly important to understand not only how AI and ML models work, but also the technical concepts of how to process the data, train them, and put them into production (live serving and inference).
This is where the unique power of open source comes in.
With the ability for large scale data processing, training, and storing, open source—Spark and Kafka in particular—is a key player in the biggest trends right now in technology.
Having accumulated years of experience in the “data industry” (an admittedly catch-all term for pretty much anything data-related), I’ve had the privilege of witnessing the entire spectrum of data projects and AI implementations (Il buono, il brutto, il cattivo), ranging from the good, the ugly, and everything in-between.
Setting aside certain organizational factors required to make any project successful, it becomes clear (at least to me) that the main factors issue contributing to these outcomes often revolves around the judicious selection of the data tech stack. A delicate balance between the project’s requirements, scalability, compatibility with existing systems, and the overall strategic vision is required.
Spark and Kafka are often used in tandem in big data processing pipelines due to their complementary strengths and capabilities. By combining the real-time data streaming capabilities of Kafka with the powerful distributed computing capabilities of Spark, organizations can build robust and scalable big data pipelines.
Through their integration with various other big data tools and a rich tech ecosystem, Spark and Kafka make it easier to build end-to-end big data processing and ML pipelines.
And that’s exactly what I’ll be doing with this series: exploring the exciting advancements in ML through a real-life production scale use case through the synergy of Spark and Kafka. I’ll be going to the heart of a use case I encounter practically every day: do I need to wear an air filter mask on my bike ride today?
So, put your helmet on for a (bicycle) ride as I unravel the layers of this use case, and gain some practical implementation experience along the way.
Why Spark and Kafka?
Before I investigate the latest integration features, let me reiterate on the key advantages of using Spark and Kafka:
- Scalability: Both Spark and Kafka are highly scalable and can handle large volumes of data streams.
- Real-time processing: Kafka is designed for real-time data streaming, while Spark Structured Streaming provides a powerful stream processing engine that can process data streams in real-time with low latency.
- Fault-tolerance: Both Spark and Kafka provide fault-tolerant mechanisms to handle failures in the system.
- Integration with other systems: Spark and Kafka can integrate with a wide range of data sources and sinks, including Hadoop, Amazon S3, Cassandra, and others.
- Support for complex transformations:
- Spark Structured Streaming provides a powerful SQL-like API for stream processing, which allows for complex transformations, aggregations, and analytics on real-time data streams.
- Kafka provides a simple message passing mechanism, which can be easily integrated with Spark to perform these transformations. Adding to its flexibility, Kafka works for both Online and Offline Message Consumption.
What’s New with Spark and Kafka Integration?
Improving the integration between Spark and Kafka has been an ongoing process. Both OSS communities focused on enhancing each platform with new features, optimizations, and compatibility. Spark and Kafka are also top level projects at the Apache Software Foundation and are backed by big tech companies who actively support the projects with enhancements and integrations.
My focus here will only be on the features that matter when using Kafka and Spark together to build data stream pipelines. One important fact to keep in mind is that the integration features and settings are mainly (logically) developed by the Spark OSS community and not the other way around!
Beside all the key configs and settings needed to smooth the integration of Spark and Kafka, the latest Spark-Streaming-Kafka-0.10 (at the time of writing this article) comes with several improvements. Here is a non-exhaustive list of some key features of Spark-Streaming-Kafka-0.10:
- Upgrade Apache Kafka to 3.3.2 (a bit behind the latest stable version)!
- Direct Approach: This version uses a direct approach, where the data is consumed directly from Kafka. This eliminates the need for receivers and thus saves resources.
- End-to-End Exactly-Once Guarantee: It provides an end-to-end exactly-once processing semantics. This means that each record will be processed exactly once, eliminating the possibility of duplicates.
- No Apache ZooKeeper™ Dependency: It doesn’t depend on ZooKeeper for offset management, which reduces the points of failure.
One downside to note is:
- Complexity: 0.10 offers more features and better performance but is a bit more complex.
My aim throughout this series is to go through the steps needed to build an end-to-end Air Quality (AIQ) prediction for bicycle riders (and anyone else exposed to the elements: scooter users, skateboarders, pedestrians…even horseback riders)! I will explain how Kafka and Spark can work together to process different data sources, like weather data streams, and ultimately build a real time data processing pipeline and create a model that predicts consistently the AIQ.
The purpose of the series is to demonstrate the concepts of constructing a streaming application, and to provide a brief overview of its core principles using real-world data. (And, just to clarify, this is not for scientific or health purposes, it’s just for fun!)
Alright then, it’s time to embark on our ride to explore the heart of this use case—and where the potential for tandem will be in action.
Do I Need an Air Filter Mask? Let’s Predict the Air Quality!

(Image generated using DeepAI)
Technology aside, riding a bicycle in a big city can pose several challenges due to the urban environment, the heavy traffic, and different human activities (see Human activities emissions below). This is why every morning I have to check multiple sources to find out about:
- Weather (the more precise the better)
- Traffic congestion—which can cause car and truck drivers to go mad!
- The state of the dedicated cycling routes—are they closed for work?
- Air pollution (which can be heavily affected by all the above)
There are dozens of other factors I could consider (such as special events going on, or if tourists are out in full force), but for the sake of simplicity, I’ll focus on these.
The Data

(Image generated using DeepAI)
To successfully determine whether I should wear an air filter mask or not, we need to explore the correlation between weather conditions (which is a prominent factor), geographical location, traffic patterns, human activities, etc., and the AIQ.
It’s already well-known that elements such as temperature and wind speed can significantly impact specific air quality indicators. However, predicting air quality implies the application of sophisticated and complex techniques due to the complex nature of the phenomenon involved.
Sure, there are forecasting tools available, but they tend to be quite rigid (for an everyday cyclist like me), especially when it comes to incorporating certain useful assumptions (like traffic).
Furthermore, most of them suffer from the drawback of being black boxes (I’ll elaborate more on this in future articles, but basically, they’re models that generate predictions without offering any explanation or understanding of the underlying logic behind those predictions.
By embracing the principles of open source, open data, and a culture of knowledge sharing, this series will further develop the concepts and ideas from previous excellent research work (focused on predicting AIQ).
These resources in particular have provided knowledge and inspiration, all of which are public datasets (with a couple exceptions):
1. Weather Forecasts – AIQ is greatly influenced by meteorological conditions (this is maybe a strong assumption at this point, in some cases it may help improve the model). For instance, wind can transport certain pollutants over long distances.
2. The open platform for French public data, and specifically the real-time data of measurements for regulated atmospheric pollutant concentrations (pardon the length—it’s translated from its original French name)! It consists of hourly summaries from various sensors (unfortunately I live in a remote area which doesn’t have one nearby). The concentrations of the following atmospheric pollutants are measured:
a. Ozone (O3)
b. Nitrogen dioxide (NO2)
c. Sulfur dioxide (SO2)
d. Particles with a diameter less than 10 µm (PM10)
e. Particles with a diameter less than 2.5 µm (PM2.5)
f. Carbon monoxide (CO)
3. Airparif—Open air quality data, similar to the French national database but with a focus on the Île-de-France region (Greater Paris area).
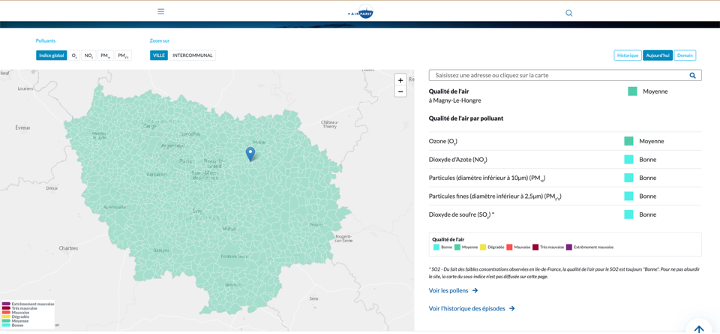
Source: AIRPARIF
4. GIS applications API has a diverse array of environmental data from Europe available as map services. These APIs provide access to a wide source of geographical information such as land use, air quality, water resources, and more.
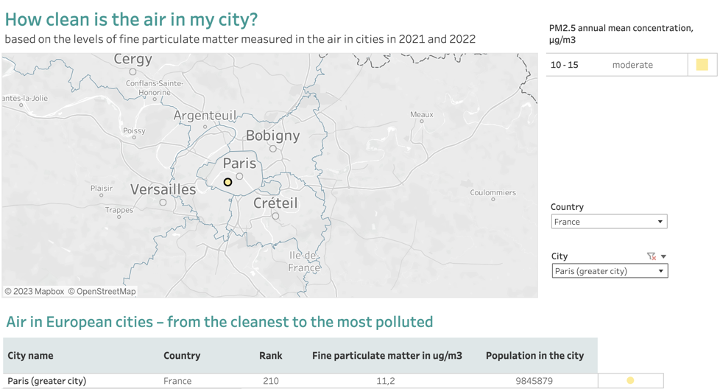
European city air quality viewer.
(Source: https://www.eea.europa.eu/themes/air/intro)
5. Human activities emissions data or anthropogenic emissions (scholarly words!), resulting from human activities like road traffic, heating, heavy industry and fossil fuel-based factories (there are many big smoking chimneys along my route) and agriculture (still a lot of dangerous pesticides in use). This data is the hardest one to obtain easily and freely, so I will utilize multiple datasets to try and capture some of these emissions:
a. Real-time road traffic data
b. EDGAR and related data sources—from the official website: “EDGAR is a multipurpose, independent, global database of anthropogenic emissions of greenhouse gases and air pollution on Earth. EDGAR provides independent emission estimates compared to what reported by European Member States or by Parties under the United Nations Framework Convention on Climate Change (UNFCCC).”
Having all this data may seem quite overwhelming–and maybe even unnecessary–at first, but it really is all necessary for my project. I need data that is:
- Ingested in near real-time (I will elaborate more on this in the following parts of the series),
- Processed,
- And used to train a ML model to predict air quality
Next, let’s look at the heavy machinery (the underlying components and architecture) that I will use to make it all happen.
Components and Architecture

Image generated using DeepAI
The design (to use Data Architect’s jargon) I want to create must be composed of
- an incoming event stream
- storage of events for model training (and long-term storage since I will be doing some offline training or batch training)
- a consistently updated and accessible model, and
- the capability to apply the model to the event stream for generating new predictions with minimal delay and on a large scale.
Let’s be honest for a moment here: Kafka and Spark are very complex tools to deploy, maintain, configure, and optimize (and the list can be longer)!
Setting aside my affiliation with Instaclustr—a company that offers managed solutions for these 2 products and others—the target architecture is predominantly based on managed services for their ease of use, rapid implementation, and their native integration with other solutions (luckily for me I have all these resources at hand).
If you’re curious and willing to experiment with the same settings that I’ll be using, feel free to contact us as we offer a free trial period on our cloud infrastructure. Otherwise, you still have the freedom to select and deploy this example on the infrastructure or configuration of your choice and you will be able to replicate the same work, with some degree of effort.
Here are the key components of our pipeline:
- Apache Spark: processing engine including Spark structured streaming, I will use Ocean for Apache Spark.
- Apache Kafka: as our streaming platform—I will use Instaclustr for Apache Kafka.
- Jupyterlab: I will use a Jupyter notebook to run the code of this blog (mainly exploration and experimentation).
- Apache Cassandra: Instaclustr Managed Apache Cassandra® as a storage solution to persist the data.
- Python libraries and ML frameworks: For each framework I use in this case, I will mention and justify whenever they are employed.
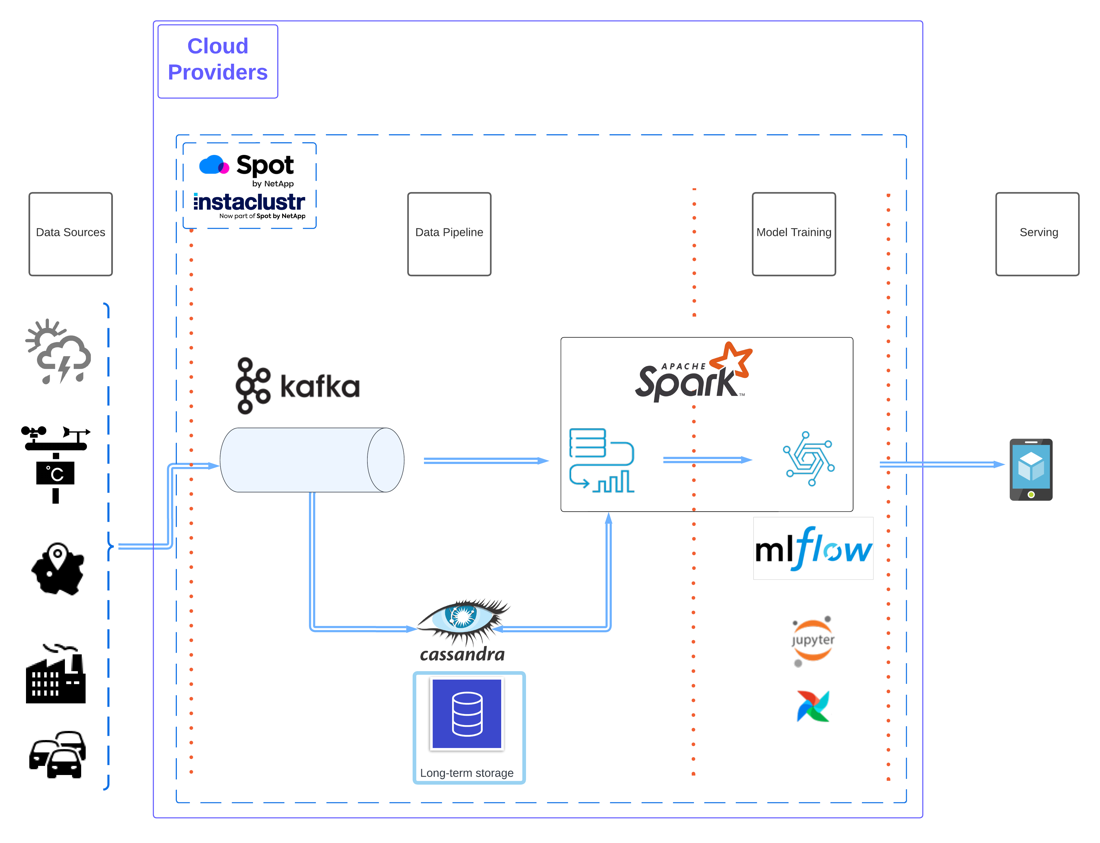
Components and Architecture
End of the First Lap, and Where I’m Cycling to Next
In this blog I’ve talked about Spark and Kafka and how I might be able to demonstrate their integration to tackle a real-life example. As an avid cyclist a great example came to mind that could help me (and hopefully many of you too!)
So, our helmet is on, our bike ready, and our route is planned. The next step is to actually get going. Come along for the ride and join me in my journey to the next part of the series. And remember, keep a lookout for any hazards…I certainly will be!
Time for ads: There are great series and articles on Kafka and ML written by my colleagues Paul Brebner and John Del Castillo. I highly recommend reading how they’re using ML!
Written By

Product Architect