Context
In my previous multi Data Center blog post ‘Multi data center Apache Spark and Apache Cassandra benchmark’, I compared the performance and stability of running Spark and Cassandra collocated on the same Data Center (DC), versus running a second DC that is aimed towards analytic jobs with Spark. This gives some breathing space to the main DC running exclusively Cassandra for more critical/time sensitive operations. This is achieved by using the NetworkTopologyStrategy, and performing critical read/writes on the primary DC with a LOCAL consistency level (LOCAL_QUORUM or LOCAL_ONE). The benchmark demonstrates that running an intensive Spark job on a dedicated DC would marginally impact the read/write performances of the main DC, while completing the job in half the time it would be on a single DC.
A few readers made the excellent point that the comparison was done between two configuration of different price, and ultimately, one would want to know what are the advantages and drawbacks of running 1 single DC vs 2 DC of the same price. So now I will answer those questions in this post.
Goal
The aim of this benchmark is to compare the performance between two cluster topology running both Spark and Cassandra. The first configuration is a single Data Center (Single DC) with 6 nodes, where each node runs both the Cassandra and Spark service. The second configuration has two Data Centers, one with 3 nodes running exclusively on Cassandra, and one with 3 nodes running Spark and Cassandra collocated.
Benchmark Setup
- All the nodes were m4xl-400, which corresponds to AWS m4.xlarge with 400GB of EBS storage. That’s 4 CPU / 15GB of RAM / 400GB of AWS EBS storage per node.
- Both the Spark test job, and Cassandra stress command, were run from a separate stress box (one for each cluster) that were connected to it’s cluster via VPC peering, in the same AWS region of the cluster.
- As done in my previous benchmark, all the Cassandra stress and Spark benchmark jobs were executed at the same time against the two clusters. This is important is it ensures that the background Cassandra operations (such as compaction) both have the same amount of time to complete, and this is even more important when using AWS EBS volumes in order to give the same amount of time for the cluster to recover its EBS credits, when some of the EBS burst capacity has been used.
- All Cassandra-stress command and Spark jobs were run after the cluster had time to catch up on compaction and recover its EBS credit, if it had been used previously.
- Finally, operations that should be running in production, such as backups, or read repairs, have been disabled, as they might otherwise run at different time on the two clusters, impacting differently on the performance. It is important to understand that in production, those operations cannot be disregarded, and would consume some of the cluster resource.
Benchmark
Initial loading: write performance
For each cluster, two set of data (“data1” and “data2”) were created using the cassandra-stress tool. “data1” will be used for read operation and by the Spark job, while “data2” will be used during the read/write test, and therefore grow in size. The cassandra-stress command was:
|
1 |
cassandra-stress write n=400000000 no-warmup cl=LOCAL_QUORUM -rate threads=400 -schema replication\(strategy=NetworkTopologyStrategy,spark_DC=3,AWS_VPC_US_EAST_1=3\) keyspace=”data1” -node $IP |
It is worthwhile recalling that we explicitly set a very high number of write, so that the data set cannot fit in the memory. Indeed, when inserting a small number of rows, the resulting Cassandra stable file will likely be cached in memory by the OS, resulting in performance much better than usually seen in production.
The write performance that was reported by cassandra-stress were:

Unsurprisingly, we observed the linear scaling in write performance that Cassandra architecture has been designed for: The Single DC has twice the amount of nodes compared to the Cassandra-only data center of the multi-DC. With a replication factor set to 3 in both cases, the Single DC has a write throughput twice faster than the multiDC. It is important to understand that in the case of the multi-DC, each insert is effectively written to all the 6 nodes, while in the case of the single-DC, the data ends up in only 3 nodes. In other words, if the data was inserted in the Single DC with a replication factor of 6, we would observe exactly the same write throughput on both clusters.
Maximum read performance
The read performance was assessed against “data1” for both clusters, using the following cassandra-stress command:
|
1 |
cassandra-stress read n=400000000 no-warmup cl=LOCAL_QUORUM -rate threads=500 -schema keyspace="data1" -node $IP |

As what was observed with the write test, the number of read per seconds that Cassandra can deliver scales with the number of nodes in the data center being used for the read.
Maximum read/write performance
The read/write cassandra-stress command allows to test the cluster’s performance by mixing reads and writes, as would be done in a production environment. The maximum read/write performance was assessed with:
|
1 |
cassandra-stress mixed ratio\(write=1,read=3\) n=400000000 no-warmup cl=LOCAL_QUORUM -rate threads=500 -schema replication\(strategy=NetworkTopologyStrategy,spark_DC=3,AWS_VPC_US_EAST_1=3\) keyspace=”data2″ -node $IP |
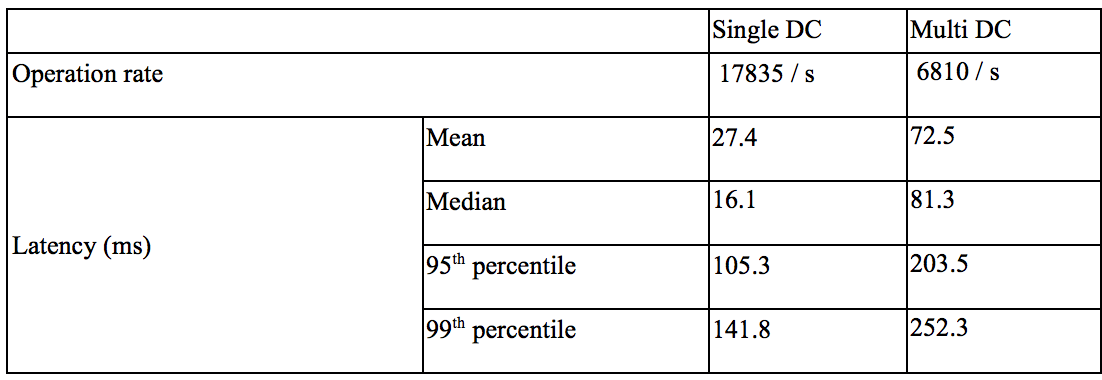
Note that the performance above has to be considered as a maximum peak performance. The number of sustained operations per second in production should be much lower, especially to allow backgrounds maintenance activities such as node repair, backup, and large compaction to run.
Spark benchmark with increasing background Cassandra activity.
In order to assess the Spark performances in single and multi DC settings, we used a simple Spark application that uses a combination of map and reduceByKey that are commonly employed in real life Spark applications, querying data stored in the “data1” column family. The Scala code used for this job is shown below for reference.
|
1 2 3 4 5 |
val rdd1 = sc.cassandraTable("data1", "standard1") .map(r => (r.getString("key"), r.getString("C1"))) .map{ case(k, v) => (v.substring(5, 8), k.length())} val rdd2 = rdd1.reduceByKey(_+_) rdd2.collect().foreach(println) |
The job is using the key and the “C1” column of the stress table “standard1”. The key is shortened to the 5 to 8 characters with a map call, allowing a reduce by key with 16^3=4096 possibilities. The reduceByKey is a simple yet commonly used Spark RDD transformation that allows to group keys together while applying a reduce operation (in this case a simple addition). This is somewhat a similar example as the classic word count example. Notably, this job will read the full data set.
We ran this job on each cluster, with an increasing level of background Cassandra read/write operations, ranging from no activity at all (Spark job running alone), to 300, 4000, 5000 and 6000 read/write per seconds (approaching the limits of the single DC read/write operation per seconds found in the previous section).
Figure 1. Performance is measured in seconds: on the Y-axis, lowest values correspond to better performances. The X-axis indicates the amount of cassandra-stress activity active during the test. A value of 0 indicates no Cassandra read/write at all.
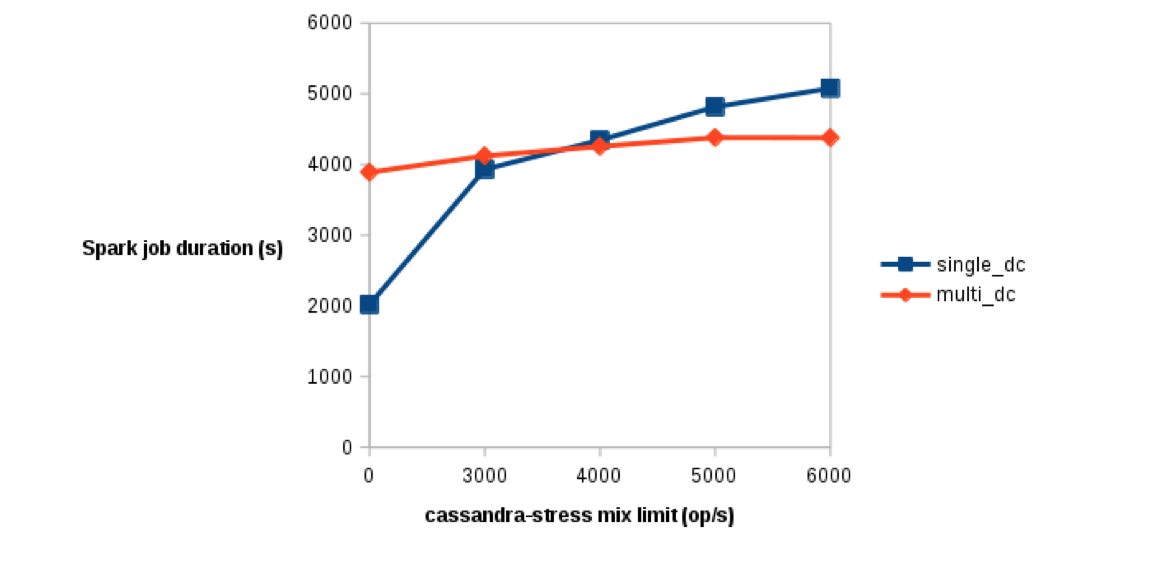
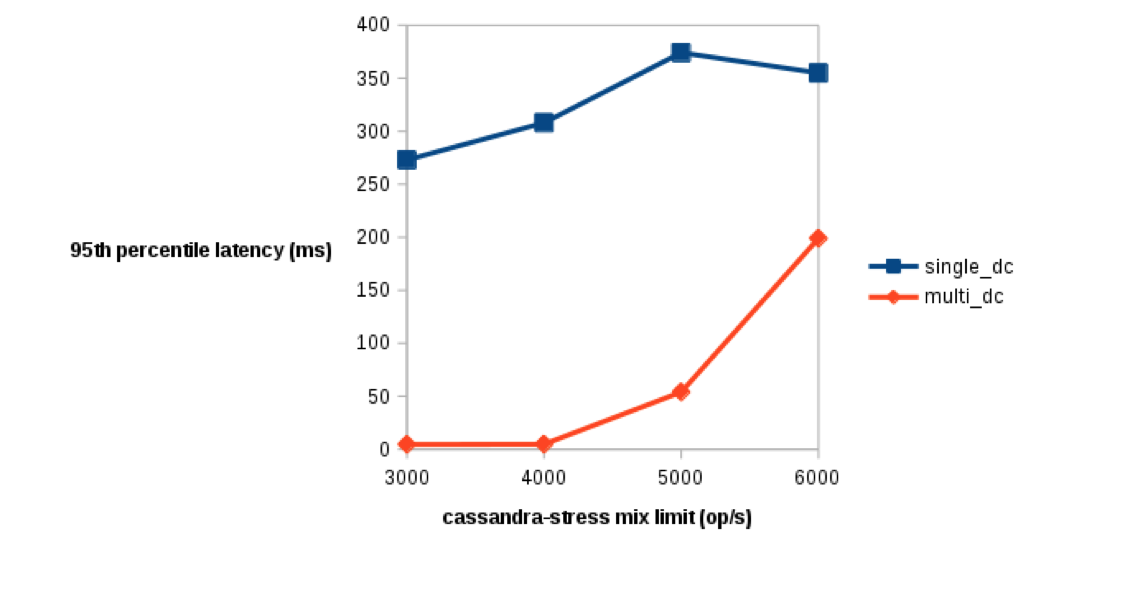
Figure 2. 95th percentile latency at various levels of cassandra-stress limit (x axis). Lower values of latency (y axis) are better.
The first thing to note from those graphs is that with no cassandra-stress activity (0 op/s), the single-DC cluster runs the Spark job twice faster than the multiDC cluster. This is expected as there are 6 Cassandra nodes (single-DC) serving read requests from Spark vs only the 3 local Cassandra nodes (multi-DC).
The second point to note is that unlike the single-DC cluster, the multiDC cluster capacity to process the Spark job is much less affected by the increase of Cassandra stress activity. The Spark processing time was 3890 s with no read/write, up to 4378 s with a 6000 read/write op/s, while the processing time for the multi DC ranged from 2018 s to 5078 s. Figure 2 also demonstrates that the Cassandra operation latency isn’t affected much during the Spark activity in the multiDC settings, at least until the number of operation per seconds approach the limit of the multiDC capacity as determined earlier. On the other hand, the Cassandra latency in the singleDC gets immediately and strongly affected by the Spark job, even at a low number of cassandra-stress operation per seconds.
Finally, there is a tipping point (at about 3800 op/s) at which this Spark job starts to get processed faster in the multiDC setting than the singleDC setting. The Cassandra nodes of the singleDC cluster have difficulty serving both the read/write request of cassandra-stress, and the read requests from Spark. On the other hand, the multiDC setting ensure that in the analytical DC, Spark has fully access to Cassandra resources, without being too affected by the background cassandra-stress activity running against the Cassandra-only data center, and being streamed in the background to the analytical DC.
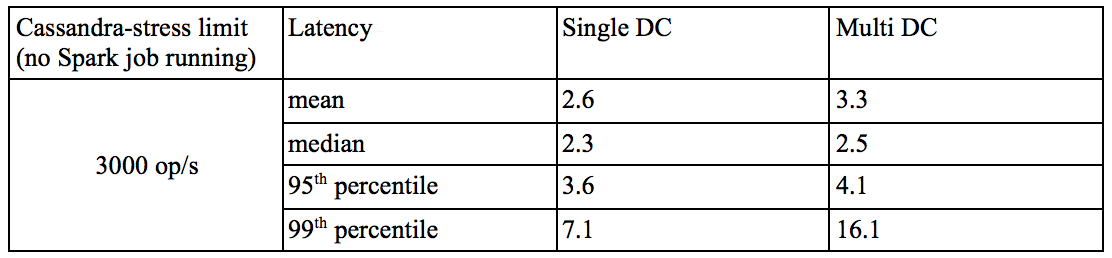
The next table presents the latency of the Cassandra operation observed on the two cluster, while running cassandra-stress at various level of operation / second, and during the execution of the Spark job.
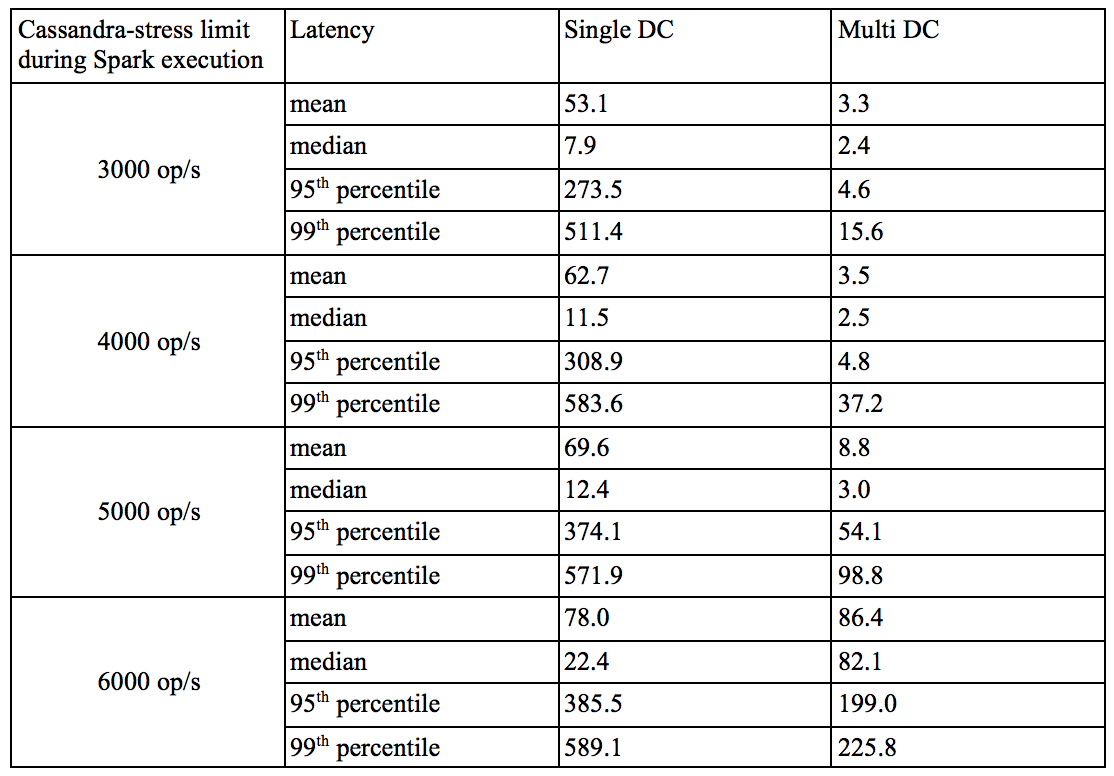
This table highlight the problems when running Spark and Cassandra on the same cluster: The latency increase as soon as Spark is performing read request on the cluster. While the performance is similar when Spark is not running (see table below), even starting at 3000 op/s we see a dramatic increase in latency in the cassandra-stress results of the Single DC. The multiDC latency, on the other hand, gets affected only when the number of operation per seconds of the cassandra-stress command approach the cluster read/write limit determined earlier.
Conclusion
This Blog was presented as a comparison of two Cluster topology of the same price. One with a single Data Center with Cassandra and Spark running on each node, and a multi Data Center cluster with one Cassandra only DC, and one analytical DC running Cassandra + Spark. The single DC cluster perform much better when running Cassandra activities only, and that’s expected as it has 6 nodes to serves writes, against 3 nodes. It also performs much better when running Spark (without background Cassandra work), and that’s normal as it has 6 Cassandra nodes to serves read requests from Spark, against 3 nodes for the single DC.
What is interesting to see is that when working with a multiDC setting, there is a separation of concerns between Spark and Cassandra activity, which ensures that the Spark jobs are marginally affected by Cassandra activities running against the Cassandra only DC, and conversely the Cassandra performances doesn’t drop on the Cassandra only DC when running Spark jobs. Even more importantly for latency sensitive application, we can see that in the singleDC cluster, the Cassandra latency of read/write requests suffers immediately when a Spark application is reading data, while this become the case in the multiDC cluster only when reaching the read/write capacity of the cluster. This drop of latency could be a major issue for example for web application that continuously queries data to display to the end user.
So, which topology to choose? It depends of your usage of the cluster. Collocating Cassandra and Spark is attractive if for example you want to have a maximum Cassandra capacity when Spark is not running, and if you can accept performance degradation from time to time, as could be the case if your application is mostly transaction oriented in, say the day, or the working week, and the usage of your cluster becomes analytic oriented in the night or the weekend. In other cases, it is recommended to use separate data centers to ensure smooth, undisrupted, uninterrupted Cassandra operations, being from a latency, or throughput perspectives. This is even more the case when experimenting and developing a new Spark application where impacts can be unpredictable (and I speak from hard-won experience here).
Related Guides:
- Apache Kafka: Architecture, deployment and ecosystem [2025 guide]
- Understanding Apache Cassandra: Complete 2025 Guide
- Complete guide to PostgreSQL: Features, use cases, and tutorial