What is Apache Cassandra?
Apache Cassandra is a free, open-source, NoSQL distributed database designed to handle massive amounts of data across multiple commodity servers. It features a masterless, peer-to-peer architecture that eliminates single points of failure, providing linear scalability and continuous, mission-critical availability.
Cassandra has gained popularity and is used by giants like Netflix, Twitter, and Apple for mission-critical applications. Backed by an active open source community and multiple vendors, it offers robust tooling, comprehensive documentation, and a flexible, schema-less data model that supports evolving application requirements without downtime.
Core architecture highlights:
- Masterless peer-to-peer: Every node in a Cassandra cluster is equal, so any node can serve read and write requests.
- Horizontal scalability: You can add more nodes without downtime, and the system automatically repartitions and balances the data.
- Multi-datacenter replication: Data replicates across multiple datacenters or cloud availability zones, so applications survive regional outages.
Common use cases:
- Time-series data: Storing logs, financial ticks, or Internet of Things (IoT) sensor data.
- Fraud detection and messaging: Applications that require high write throughput and low-latency reads.
- Global systems: E-commerce platforms and content management systems spanning multiple continents.
This is part of an extensive series of guides about open source.
History of Apache Cassandra and advancements in recent versions
Apache Cassandra was first developed at Facebook in 2007 by Avinash Lakshman, one of the authors of Amazon’s Dynamo, which later became DynamoDB, and Prashant Malik. It was designed to solve the scalability challenges of Facebook’s inbox search feature, which required high write throughput, fault tolerance, and the ability to scale across data centers.
In 2008, Facebook released Cassandra as an open source project. The broader community quickly recognized its potential, particularly for applications requiring high write performance and geographic distribution. In 2009, Cassandra was accepted into the Apache Incubator, and by 2010, it became a top-level project of the Apache Software Foundation.
Since then, Cassandra has matured and rapidly iterated, with major version releases improving core capabilities. Notably:
- Cassandra version 3.0 introduced the Cassandra Query Language (CQL), which provided a more SQL-like interface, making it easier for developers to interact with the database.
- Cassandra 4.0 introduced features like virtual tables for accessing internal metrics via CQL, audit and full query logging, zero-copy streaming to accelerate data transfers and support for Java 11.
- Cassandra 5.0 introduced Storage Attached Indexes (SAI) for efficient secondary indexing, trie-based memtables and SSTables to improve read/write performance, vector search capabilities enabling AI and machine learning applications, and Unified Compaction Strategy (UCS) for automated data compaction and dynamic data masking.
Key features of Apache Cassandra
Here are some of the main features offered by Apache Cassandra.
Distributed architecture
Apache Cassandra’s distributed architecture allows it to scale horizontally across many nodes, offering integration of additional nodes without downtime. In Cassandra, there is no master node—every node in the cluster plays an equal role in storing and serving data. This peer-to-peer architecture enables true distribution of data and workloads.
Data in Cassandra is distributed across nodes using a consistent hashing mechanism, which ensures that data is evenly spread across all nodes in the cluster. When new nodes are added or removed, Cassandra automatically rebalances the cluster, redistributing data with minimal impact on performance.
Replication and tunable consistency
Cassandra remains operational even when individual nodes or entire data centers go offline. Thanks to its peer-to-peer architecture, no node is more critical than another, which eliminates any single point of failure. Data is replicated across multiple nodes, and users can configure the replication factor to meet their needs, ensuring data redundancy and availability.
In addition to replication, Cassandra’s tunable consistency levels allow developers to prioritize either consistency or availability, depending on the application’s requirements. By adjusting the consistency level, you dictate how many replicas must acknowledge an operation before it is considered successful. For example, critical applications can use a higher consistency level, ensuring that all replicas are in sync, while less critical applications can opt for lower consistency to prioritize availability and performance.
Wide column store
Cassandra uses a wide column store model, which provides flexibility in how data is stored and retrieved. Unlike traditional relational databases, Cassandra does not require a fixed schema, making it suitable for handling dynamic or evolving data structures. Each row in a Cassandra table can have different columns, allowing for efficient storage and retrieval of sparse data.
In a wide column store, data is organized into rows and columns, but each row can have a unique set of columns, optimizing storage for datasets with irregular structures. This flexibility is particularly beneficial for applications that need to store time-series data, sensor data, or data with varying attributes. This design also supports quick lookups of large datasets.
Scalability
Scalability is one of Apache Cassandra’s defining features, allowing it to handle the explosive growth of data that many modern applications experience. Cassandra achieves horizontal scalability, meaning that as the amount of data increases, more nodes can be added to the cluster to share the load. This process is seamless, requiring no downtime or major reconfiguration. Each node in a Cassandra cluster is identical, with no single point of failure, and the data is automatically distributed across the nodes based on a consistent hashing mechanism.
As new nodes are added, Cassandra automatically redistributes the data to ensure even load balancing, which maintains high performance regardless of the cluster size. This linear scalability is not limited to a single data center but can extend across multiple data centers, making Cassandra an excellent choice for global applications that require data locality and fast access times in different geographic regions. Whether handling a few terabytes or scaling up to petabytes of data, Cassandra’s architecture ensures that the system can grow organically with the needs of the business without significant operational overhead.
Seamless replication
Cassandra’s replication model is designed for fault tolerance and high availability. Data is automatically replicated across multiple nodes in a cluster, and potentially across multiple data centers, using a configurable replication factor. This ensures that even if one or more nodes fail, the system can continue to operate without data loss or downtime. The eventual consistency model allows Cassandra to balance performance with availability, providing tunable consistency levels based on application requirements. This replication capability is crucial for organizations that need to maintain data availability and integrity in distributed environments.
How Cassandra works
Cassandra has been designed with scale, performance, and continuous availability as the foundation architecture principles. It uniquely blends the distributed storage techniques of Amazon’s Dynamo with the data model of Google’s Bigtable. Cassandra operates using a masterless ring architecture—it does not rely on a master-slave relationship.
In Cassandra, all nodes play an identical role; there is no concept of a master node, with all nodes communicating with each other via a distributed, scalable protocol. Writes are distributed among nodes using a hash function and reads are channeled onto specific nodes.
Cassandra stores data by dividing the data evenly around its cluster of nodes. Each node is responsible for part of the data. The act of distributing data across nodes is referred to as data partitioning.
Cassandra uses a flexible schema model based on a partitioned row store, which is well-suited for write-heavy workloads. Its eventual consistency model allows for high availability and performance, though it may sacrifice immediate consistency under certain conditions. This design makes Cassandra ideal for use cases where scalability and uptime are prioritized over strict consistency, such as in big data applications, real-time analytics, and distributed systems.
Common use cases for Apache Cassandra
Cassandra is the database of choice for internet-scale, high-velocity data. Common scenarios include:
- Time-series data: Storing logs, financial ticks, or Internet of Things (IoT) sensor data, where writes arrive continuously and in high volume.
- Fraud detection and messaging: Applications that require high write throughput combined with low-latency reads to act on data in real time.
- Global systems: E-commerce platforms and content management systems spanning multiple continents that need data locality and continuous availability across regions.
Cassandra vs. MongoDB: Key differences
Apache Cassandra and MongoDB are both popular NoSQL databases, but they are optimized for different types of workloads and architectures.
Data model
Cassandra is a wide-column store designed for high-volume write operations and fast retrieval at scale. It organizes data into tables with rows and dynamic columns, making it suitable for time-series data and applications with fixed access patterns.
MongoDB is a document store that uses JSON-like BSON documents. Its schema-less design makes it well-suited for applications with flexible or evolving data structures, such as content management systems or product catalogs.
Consistency and availability
Cassandra prioritizes availability and partition tolerance under the CAP theorem. It offers tunable consistency, allowing applications to balance between consistency and availability based on needs.
MongoDB traditionally emphasizes strong consistency but can be configured for eventual consistency in distributed setups. It uses replica sets for high availability and automatic failover.
Scalability and performance
Cassandra excels in horizontal scalability across multiple regions and data centers. Its write-optimized architecture supports massive write throughput with minimal latency.
MongoDB can scale horizontally using sharding, but this typically requires more manual configuration and operational overhead. MongoDB’s performance favors read-heavy workloads with secondary indexes and rich queries.
Use cases
Cassandra is ideal for IoT data ingestion, telemetry, real-time analytics, and scenarios requiring constant uptime across geographies.
MongoDB fits well with applications needing flexible schemas, such as social media apps, catalogs, and user-generated content platforms.
While both databases offer high performance and flexibility, the choice depends on workload characteristics—Cassandra for high-write, distributed environments, and MongoDB for flexible, read-heavy applications.
Apache Cassandra vs DynamoDB
One database which Cassandra is often compared with is the AWS DynamoDB. Both Cassandra and DynamoDB offer incredible scale and availability. They both can serve tens of millions of reads and writes and offer a level of resilience in the face of failure. Both technologies share a similar underlying architecture (Dynamo) but that is where the similarities end. They are different in so many ways.
Understanding Cassandra Query Language (CQL)
Cassandra Query Language (CQL) is the primary language for interacting with Apache Cassandra, designed to feel familiar to developers accustomed to SQL. While it shares a similar syntax with SQL, CQL differs in important ways to accommodate Cassandra’s distributed architecture.
CQL operates on a table-based model where tables are defined by columns, with data distributed across nodes based on a partition key. This partition key is crucial for ensuring efficient data distribution and retrieval in a distributed system. However, unlike SQL, CQL does not support complex joins or subqueries, instead encouraging denormalization to maintain performance at scale.
CQL supports standard operations such as SELECT, INSERT, UPDATE, and DELETE, but queries are optimized for access by the partition key to ensure speed and efficiency. Secondary indexes and materialized views in Cassandra offer flexibility in querying, but they should be used carefully to avoid potential performance issues. Materialized views, in particular, provide a way to maintain precomputed views of queries, which can be especially useful for optimizing read-heavy operations without requiring manual denormalization of data.
For more advanced needs, CQL includes features like batch operations, lightweight transactions (LWTs), and user-defined functions (UDFs). Batch operations allow multiple statements to be executed atomically, which is useful for maintaining consistency across related operations. LWTs enable conditional updates to enforce stronger consistency, though they come with a performance trade-off. Additionally, UDFs and user-defined aggregates (UDAs) extend CQL’s functionality, allowing custom logic and aggregation within queries, which can be critical for complex data processing tasks.
Cassandra architecture
Cassandra is a built-for-scale architecture, meaning that it is capable of handling large amounts of data and millions of concurrent users or operations per second—even across multiple data centers—as easily as it can manage much smaller amounts of data and user traffic. To add more capacity, you simply add new nodes to an existing cluster without having to take it down first. Unlike other master-slave or sharded systems, Cassandra has no single point of failure and therefore is capable of offering true continuous availability and uptime.
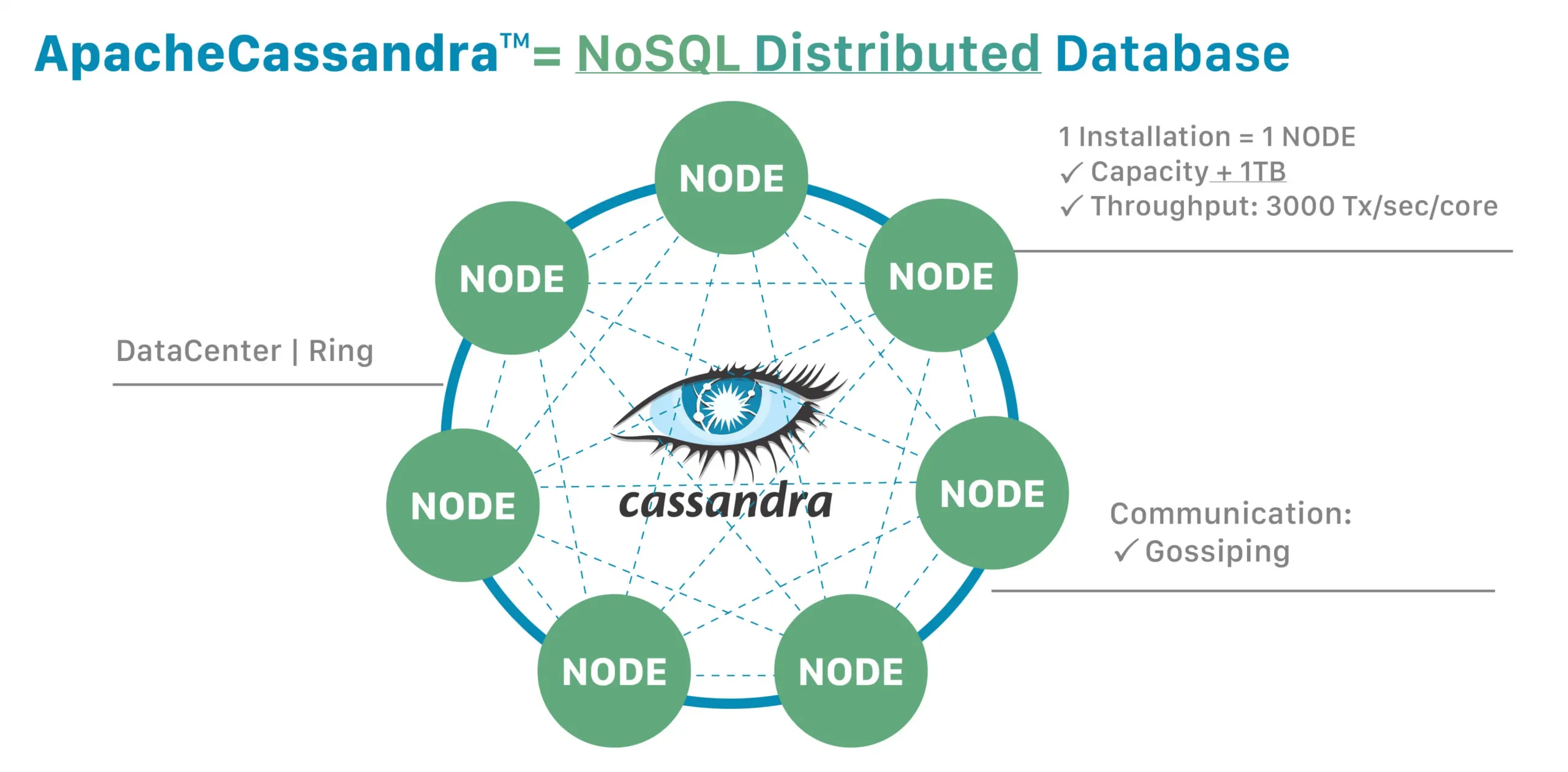
The key components of the Cassandra architecture include the following terms and concepts:
- Node: the specific instance where data is stored.
- Rack: a set of nodes with a correlated chance of failure.
- Datacenter: a collection of related nodes with a complete set of data.
- Cluster: a component that contains one or more data centers.
- Commit log: it is a crash-recovery mechanism in Cassandra. Every write operation is written to the commit log.
- Mem-table: a mem-table is a memory-resident data structure. A mem-table is a write-back cache residing in memory that has not been flushed to disk yet.
- SSTable: a sorted string table (SSTable) ordered immutable key value map. It is basically an efficient way of storing large sorted data segments in a file. Read our behind the scenes look at getting ready for Cassandra 5.0 for more info on SSTables.
- Bloom filter: is an extremely fast way to test the existence of a data structure in a set. A bloom filter can tell if an item might exist in a set or definitely does not exist in the set. Bloom filters are a good way of avoiding expensive I/O operation.
These components work together to give Cassandra its write performance. Cassandra excels at write-heavy workloads because writes are sequentially appended to the on-disk commit log and written to an in-memory structure called a memtable before being flushed to immutable disk files (SSTables).
Cassandra data modeling
Cassandra is a wide column store database. Its data model is a partitioned row store with tunable consistency. It is highly query-centric, trading away relational joins and foreign keys for high write and read throughput. Data is grouped into keyspaces (similar to a schema) and organized into tables. Rows are organized into tables; the first component of a table’s primary key is the partition key (which determines the physical node where the data lives); within a partition, rows are clustered by the remaining columns of the key (the clustering columns, which determine the sort order within that partition). Other columns may be indexed separately from the primary key. Tables may be created, dropped, and altered at run-time without blocking updates and queries.
Cassandra cannot do joins or subqueries. Rather, Cassandra emphasizes denormalization through features like collections. A column family (called “table” since CQL3) resembles a table in an RDBMS. Column families contain rows and columns. Each row is uniquely identified by a row key. Each row has multiple columns, each of which has a name, value, and timestamp.
Unlike a table in an RDBMS, different rows in the same column family do not have to share the same set of columns, and a column may be added to one or multiple rows at any time. You can read more about data modeling recommended practices on our support portal.
Configuring and operating Cassandra
Instaclustr has authored a number of blogs that can help you get started with configuring and operating Apache Cassandra. Here are our recommended resources to learn more:
Cassandra broadcast address
When configuring Cassandra to work in a new environment or with a new application or service we sometimes find ourselves asking about the difference between broadcast_address and broadcast_rpc_address”.
Apache Cassandra compaction strategies
It is equally important to understand Cassandra compaction strategies. While regular compactions are an integral part of any healthy Cassandra cluster, the way that they are configured can vary significantly depending on the way a particular table is being used.
Apache Cassandra tombstones
Multi-value data types are a powerful feature of Cassandra. However, some of Cassandra’s behavior when handling these data types is not always as expected and can cause issues. In particular, there can be hidden surprises when you update the value of a collection type column. Our blog, How does data modeling change in Apache Cassandra 5.0 with Storage Attached Indexes?, digs deeper into collections in the latest version of Cassandra.
Apache Cassandra best practices
The right deployment strategies and best practices for Apache Cassandra can mean the difference between on-time deployment of applications that scale massively, are always available, and perform blazingly fast, and those that bring your applications to a crawl.
We have an abundance of resources on our support portal to help you with creating your cluster. Download our white paper, 10 Rules for Managing Apache Cassandra, to learn best practices to follow when managing your own cluster.
Cassandra CQL
Users can access Cassandra through its nodes using Cassandra Query Language (CQL). CQL treats the database (keyspace) as a container of tables. CQL is a typed language and supports a rich set of data types, including native types, collection types, user-defined types, tuple types, and custom types.
Programmers use cqlsh—a prompt to work with CQL or separate application language drivers. Read our support article to understand how cqlsh can be used to connect to clusters in Instaclustr, and check out how it can be used with vector search.
Exploring the power of Instaclustr Managed Platform for Cassandra
The Instaclustr Managed Platform for Cassandra is a robust and reliable solution designed to simplify the deployment, management, and scaling of Apache Cassandra clusters. With its comprehensive suite of features and tools, Instaclustr empowers businesses to leverage the full potential of Cassandra, a highly scalable and distributed NoSQL database. From startups to enterprise-level organizations, Instaclustr offers a hassle-free experience for harnessing the power of Cassandra, enabling seamless data management and unlocking new possibilities for data-driven applications.
Instaclustr takes the complexity out of deploying and managing Cassandra clusters. With just a few clicks, users can provision and launch fully managed Cassandra clusters on their preferred cloud provider, including AWS, Azure, and GCP. The platform handles all the underlying infrastructure and operational tasks, ensuring high availability, data replication, and automated backups. This allows developers and administrators to focus on their core tasks without worrying about the intricacies of cluster configuration and maintenance.
One of the key advantages of Instaclustr is its ability to effortlessly scale Cassandra clusters to meet growing demands. With a flexible architecture, Instaclustr allows users to add or remove nodes dynamically, ensuring optimal performance and accommodating changing workloads. The platform also provides seamless integration with popular monitoring and alerting tools, enabling real-time visibility into cluster health, performance metrics, and resource utilization. This empowers businesses to make data-driven decisions and proactively address any issues that may impact performance.
Instaclustr prioritizes the security of data stored within Cassandra clusters. The platform offers robust security measures, including encryption at rest and in transit, fine-grained access controls, and integration with identity and access management systems. Instaclustr also assists businesses in meeting compliance requirements by providing audit logs, data encryption, and adherence to industry best practices. This ensures that sensitive data remains protected and meets regulatory standards.
Instaclustr provides customer support and expertise in managing Cassandra clusters. Instaclustr’s team of experienced professionals is available around the clock to provide assistance, guidance, and troubleshooting. Whether it’s optimizing cluster performance, addressing technical challenges, or offering best practices, Instaclustr’s support team is dedicated to ensuring a smooth experience for users.
Related content:
- Read our guide to apache cassandra on aws
- Read our guide to apache cassandra tutorial
- Read our guide to dynamodb vs cassandra
For more information:
- Instaclustr for Apache Cassandra® 5.0 Now Generally Available
- Will Your Cassandra Database Project Succeed?: The New Stack
- Apache Cassandra 5.0: Answering Enterprises’ Biggest Questions
See additional guides on key open source topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of open source.
Authored by Instaclustr
- [Guide] Apache Kafka: Architecture, deployment and ecosystem [2025]
- [Guide] Apache Kafka tutorial: Get started with Kafka in 5 simple steps
- [Blog] How to Get the Most out of Your Kafka Cluster
- [Product] NetApp Instaclustr Data Platform | Open-Source Data Infrastructure Platform
Authored by Mend
- [Guide] When’s The Right Time For An Open Source Audit?
- [Guide] How To Prepare Your Open Source Software For a Successful Due Diligence
Authored by Mend