Late last year we published our first round of benchmarking for Apache Kafka running on our managed service. At the time, we flagged an issue that the approach we adopted did not balance reads and writes to a cluster. We’ve now completed another round of benchmarking with a balanced read and write load and Kafka 2.0 and 2.1.
The approach we followed was similar to our previous benchmarking with a change to step 4 to ensure a balanced load:
- Provisioned the required Apache Kafka cluster using the Instaclustr Managed Platform. All clusters had TLS enabled for broker to broker and client to broker communication and used Kafka 1.1.0.
- Create a test topic with RF=3 and partitions equal to the number of nodes in the cluster.
- No compression was used and batch.size was the default (16384)
- We used the rdkafka_performance tool to generate load with 512 byte messages and ran the load for 1 hour.
- The number of stress clients was determined by increasing the number of clients machines in use until maximum throughput was reached (the number of clients therefore varied depending on the cluster under test and readers and writers were adjusted to produce a close to equal number of reads and writes for the test).
Following this approach we achieved the following results:
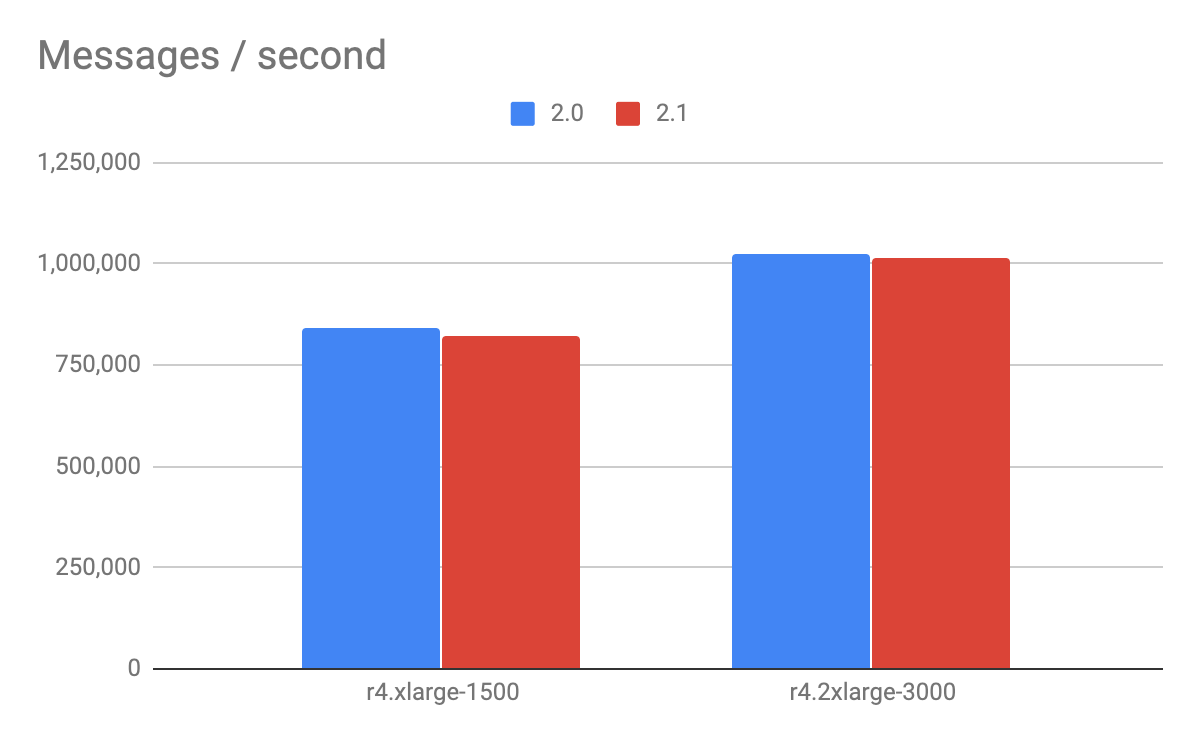
Overall, the 3 node clusters processed just over 800k messages / second for the r4.xlarge and just over 1 million messages/sec for the r4.2xlarge. There are a couple of interesting observations here:
- Performance was roughly equal between 2.0 and 2.1 although there was a very small degradation in both tests.
- The r4.2xlarge produce a relatively small increase in throughput for hardware costing 2 times the cost of the r4.xlarge. This was a lower scale-up than experienced with write-only tests (which did approximately double). We will do some more investigation on this point.
As always, these benchmarks can provide an initial estimate for sizing but testing should be undertaken for your particular application scenario. If you have any question regarding this benchmarks then please feel free to drop them in the comments section below or email [email protected].