






















At Instaclustr, we are often asked for comparative benchmarking between the different cloud providers we support and the different instances sizes we offer. For our Apache Kafka managed service offering, we have recently completed an extensive benchmarking exercise which we expect will help our customers in evaluating which instance types to use and differing performance between cloud providers.
We used the following methodology to conduct this benchmarking:
- Provisioned the required Apache Kafka cluster using the Instaclustr Managed Platform. All clusters had TLS enabled for broker to broker and client to broker communication and used Kafka 1.1.0.
- Create a test topic with RF=3 and partitions equal to the number of nodes in the cluster.
- No compression was used and batch.size was the default (16384)
- We used the rdkafka_performance tool to generate load with 512 byte messages and ran the load for 1 hour.
- The number of stress clients was determined by increasing the number of clients machines in use until maximum throughput was reached (the number of clients, therefore, varied depending on the cluster under test).
The graphs below show the results we measured on the different providers and different instances sizes we offer (see the table at the end of this blog post for full details). The first graph shows write-only loads and the second shows a mix of read/write.
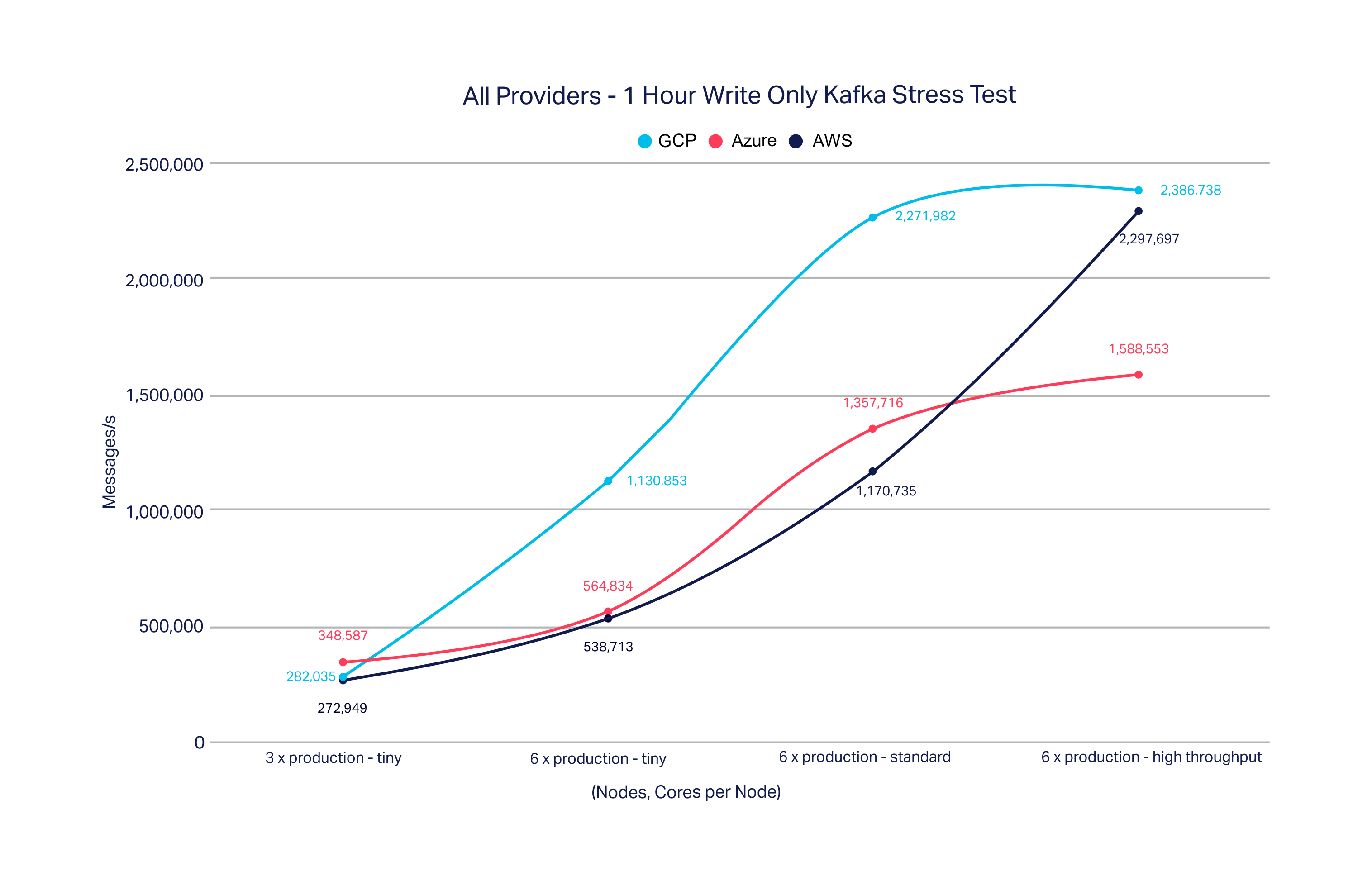
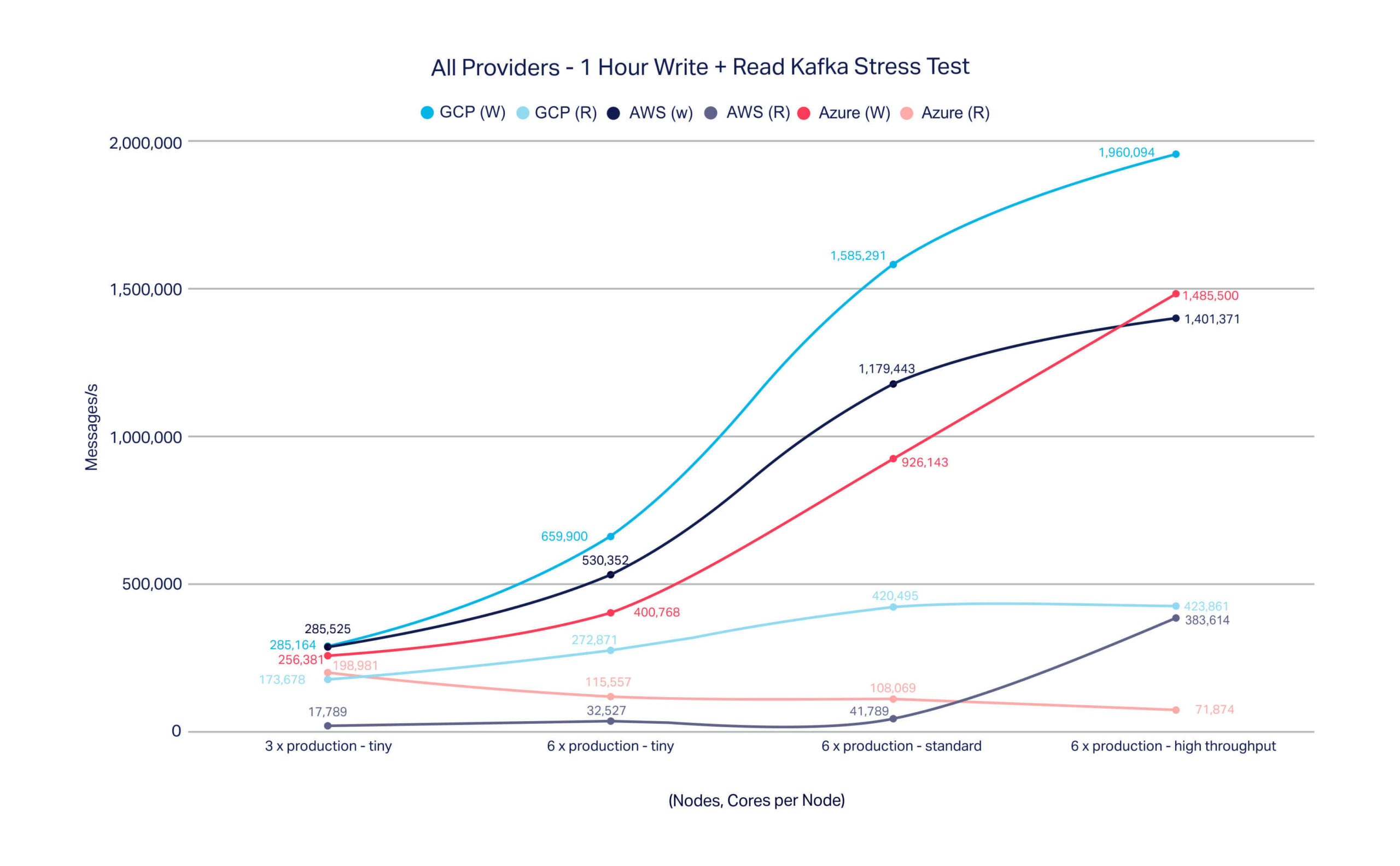 In general, we see that larger cluster sizes and more processing power produces higher throughput as expected. There are a couple of somewhat unexpected results here worth calling out:
In general, we see that larger cluster sizes and more processing power produces higher throughput as expected. There are a couple of somewhat unexpected results here worth calling out:
- Read throughput stay relatively flat in the mixed loads, even as we scale out. This is an artifact of our benchmarking approach and the fact that Kafka generally favours producers over consumers when allocating scarce compute resources. In reviewing these results, we realised that a better approach would be to control producer and consumer client resource so that read rate was approximately equal to write rate – it doesn’t make a lot of sense to be pushing a heap of messages to your Kafka cluster that you never read. Look for future benchmarks (we’re working on Kafka 2.0 at the moment) to adopt this balanced approach. In the meantime, we think the current approach still provides useful information.
- On the GCP tests, there was a very large jump in the write-only test between the three node cluster and the six node cluster. Given the 3 node write-only test achieved similar write throughput to the 3 node mixed test, this is likely down to some transient issue experienced during the 3 node write-only test.
Overall, these benchmarks provide an indication for potential throughput for different environments and instance sizes. Performance can vary significantly depending on individual use cases and we always recommended benchmarking with your own specific use case prior to production deployment. Kafka throughput is particularly sensitive to message size and we would particularly recommend factoring expected throughput based on expected message size (ie we test with 512 byte message payload, if you expect your payload to be 1024 bytes then you should halve expected throughput).
If you have any question regarding this benchmarks then please feel free to drop them in the comments section below or email [email protected].
Tested Instance Configurations
- AWS
| Name | Cores | Memory | Disk | Instance |
| Production-tiny | 2 | 15.25GB | 500GB | r4.large |
| Production-standard | 4 | 30.5GB | 1500GB | r4.xlarge |
| Production-highthroughput | 8 | 61GB | 3000GB | r4.2xlarge |
AWS instances use ST1 EBS volumes
- GCP
| Name | Cores | Memory | Disk | Instance |
| Production-tiny | 2 | 13GB | 400GB | n1-highmem-2 |
| Production-standard | 4 | 26GB | 1500GB | n1-highmem-4 |
| Production-highthroughput | 8 | 52GB | 3000GB | n1-highmem-8 |
GCP instances use SSD persistent disk
- Azure
| Name | Cores | Memory | Disk | Instance |
| Production-tiny | 2 | 14GB | 512GB | Std_DS11_v2 |
| Production-standard | 4 | 28GB | 1500GB | Std_DS12_v2 |
| Production-highthroughput | 8 | 56GB | 3000GB | Std_DS13_v2 |
Azure instances use Azure Premium Storage
Monthly pricing for Instaclustr Managed Kafka using these instances, including all cloud provider charges, is available by logging in to the Instaclustr Console.