Apache Cassandra is a distributed database management system where data is replicated amongst multiple nodes and can span across multiple data centers. Cassandra can run without service interruption even when one or more nodes are down. It is because of this architecture that Cassandra is highly available and highly fault tolerant.
However, there are a number of common scenarios we encounter where nodes or data needs to be recovered in a Cassandra cluster, including:
- Cloud instance retirement
- Availability zone outages
- Errors made from client applications and accidental deletions
- Corrupted data/SStables
- Disk failures
- Catastrophic failures that require an entire cluster rebuild
Depending on the nature of the issue, the options available for recovery include the following:
Single Dead Node
Causes for this scenario include cloud instance retirement or physical server failure.
For Instaclustr Managed Cassandra clusters, this is detected and handled automatically by our Support team. Outage or data loss is highly unlikely assuming Instaclustr’s recommended replication factor (RF) of three is being used. The node will simply be replaced and data will be streamed from other replicas in the cluster. Recovery time is dependent on the amount of data.
This could be due to rolling restart, cloud availability zone outage, or a number of other general errors.
For this scenario:
- It is handled automatically by Cassandra
- Recovery time is dependent on downtime in this case
- There is no potential for data loss and no setup required
If a node in Cassandra is not available for a short period of time, the data to be replicated on the node is stored on a peer node. This data is called hints. Once the original node becomes available, the hints are transferred to the node, and the node is caught up with the missed data. This process is known as hinted handoffs within Cassandra.
There are time and storage restrictions for hints. If a node is not available for a longer duration than configured (i.e. hinted handoff window), no hints are saved for it. In such a case, Instaclustr will make sure repairs are run following best practices to ensure data remains consistent.
Restore Keystore, Corrupted Tables, Column Factory, Accidentally Deleted Rows, Transaction Logs, and Archived Data
In this case, if you are a Managed Cassandra customer:
- Email Instaclustr
- Recovery time dependent on amount of data
- Anything after the last backup will be lost
- Setup involves backups, which is handled by Instaclustr
- Causes include general error, human error, testing, and even malware or ransomware
Note:
- Corrupted Tables/Column Factory: This assumes corruption is at the global cluster level and not at the individual node level
- Accidentally deleted rows: This is not as straightforward as you would potentially need to restore elsewhere (either to another table/keyspace or cluster) and read from there. Instaclustr can help with this.
- Transaction logs: Not a common restore method
- Archived data: Backups only go back 7 days, so another method to handle this must be used
Rebuild an Entire Cluster With the Same Settings
You may need to rebuild a cluster from backup due to accidental deletion or any other total data loss (e.g. human error). Another common reason for using restore-from-backup is to create a clone of a cluster for testing purposes.
All Instaclustr-managed clusters have backups enabled, and we provide a self-service restore feature. Complex restore scenarios can be achieved by contacting our 24×7 support team.
When restoring a cluster, backups can be used to restore data from a point-in-time to a new cluster via the Instaclustr Console or Provisioning API. See the following from Instaclustr’s Cassandra Documentation:
“When restoring a cluster, you may choose to:
- Restore all data or only selected tables
- If restoring a subset of tables, the cluster schema will still be restored in its entirety and therefore the schemas for any non-restored keyspaces and tables will still be applied. However, only backup data for the selected tables will be restored.
- Restore to a point-in-time
- The restore process will use the latest backup data for each node, up to the specified point-in-time. If restoring a cluster with Continuous Backup enabled, then commit logs will also be restored.
Once the Restore parameters are submitted, a new cluster will be provisioned under the account with a topology that matches the designated point-in-time.”
For clusters with basic data backups enabled (once per node per 24 hour period), anything written after the last backup could potentially be lost. If the “continuous backup” feature is enabled, then this recovery point is reduced to five minutes.
Recovery time is dependent on the amount of data to be restored. The following chart aims to detail the restore download speeds for different instances provided in the Instaclustr managed service offering:
| Instance | Download Speed* | Commit Log Replay Speed | Startup Speeds (No Commit Logs) |
| i3.2xlarge | 312 MB/s | 10GB (320 Commitlogs): 12 seconds20GB (640 Commitlogs): 28 seconds30GB (960 Commitlogs): 1 minute 7 seconds | 82 seconds per node |
*The download speed is the approximate rate that data is transferred from cloud provider storage service to the instance. It may vary depending on region, time of day, etc.
Application Effect
This really is a question about quorum, consistency level, and fault tolerance. Assuming a replication factor of three and LOCAL_QUORUM consistency is being used (as per Instaclustr’s Cassandra best practices), your application will not see any outage.
Instaclustr Managed Cassandra Backup and Restore Options
The following are some of the different Cassandra backup and restore options available for Instaclustr’s customers.
Snapshot Backup
By default, each node takes a full backup once per 24 hours and uploads the data to an S3 bucket in the same region. Backup times are staggered at random hours throughout the day. The purpose of these backups is to recover the cluster data in case of data corruption or developer error (the most common example being accidentally deleting data). Backups are kept for seven days (or according to the lifecycle policy set on the bucket). For clusters that are hosted in Instaclustr’s AWS account, we do not replicate data across regions.
Continuous Backup
Continuous Backup can optionally be enabled to perform backups more frequently. Enabling Continuous Backup for a cluster will increase the frequency of snapshot backups to once every three hours, and additionally, enable commit log backups once every five minutes. This option provides a reduced window of potential data loss (i.e. a lower RPO). This feature can be enabled on any cluster as part of the enterprise add-ons package, for an additional 20% of cluster monthly price, or as per your contract.
Restore (Same Region)
Cluster backups may be used to restore data from a point-in-time to a new cluster, via the Console or using the Provisioning API. Data will be restored to a new cluster in the same region. This feature is fully automated and self-serve.
Customized network configurations created outside the Instaclustr Console are not automatically restored, including peering.
For more information, read our documentation on Cassandra cluster restore operations.
Next up, we’ll review some common failure scenarios and how they are resolved in greater detail.
Scenario 1: AZ Failure
For maximum fault tolerance, a Cassandra cluster should be architected using three (3) racks, which are each mapped to AWS Availability Zones (AZs). This configuration allows the loss of one AZ (rack) and QUORUM queries will still be successful.
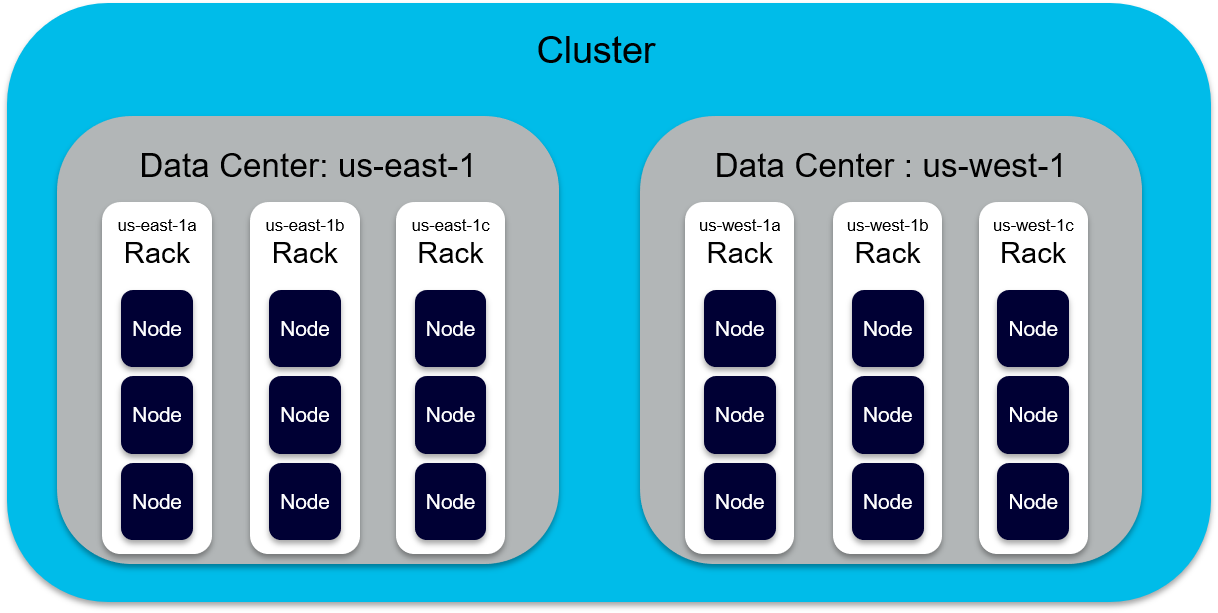
Testing AZ Failure
Instaclustr Technical Operations can assist with testing a disaster recovery (DR) situation by simulating the loss of one or more AZ. This is achieved by stopping the service (Cassandra) on all nodes in one rack (AZ) to simulate a DR situation.
Below are two tests to consider:
First test: Stop Cassandra on all nodes in one rack
- Rack = AZ
- Simulates case where some or all nodes become unreachable in an AZ, but not necessarily failed
- Measures impact to the application (we assume you’ll run some traffic through during the simulated outage)
Second test: Terminate all instances in one rack
- Simulate a complete AZ failure
- Instaclustr will replace each instance until the cluster is recovered
- Measures recovery time
Our process in the case of an instance failure is:
- Alerts would be triggered to PagerDuty detecting nodes down
- Rostered engineer would investigate by:
- Attempting to ssh to the instance
- CheckingAWS instance status via CLI
- Replace instance if it is unreachable (uses restore from backup).
- Notify the customer of actions
Scenario 2: Region Failure
Failover DC in Another Region
In this option, another data center (DC) is added to the cluster in a secondary region. All data, and new writes, are continuously replicated to the additional DC. Reads are serviced by the primary DC. This is essentially a “hot standby” configuration.
Advantages:
- Full cross-region redundancy
- Very low Recovery Point Objective (RPO) and Recovery Time Objective (RTO).
- RPO: Frequency of backups
- RTO: Amount of tolerable downtime for business
- Simple to set up
- Guaranteed AWS capacity in secondary region should the primary region become unavailable
- Each DC is backed up to S3 in the same region
- Protects against data corruption (at SSTable level)
Disadvantages
- Does not protect against accidental deletes or malicious queries (all mutations are replicated to the secondary DC)
Cost
- There is a potential to run the secondary DC with fewer or smaller instance types. At the very minimum it will need to service the full write load of the primary DC, as well as having sufficient storage for the data set.
- Cost includes additional AWS infrastructure cost, as well as Instaclustr management fees
Testing Region Failure
Similar to simulating an AZ failure, a region outage can be simulated by:
First test: Stop Cassandra on all nodes in primary region
- Quickest simulation, allows you to test how your application will respond (we assume you’ll run some traffic through during the simulated outage).
Second test: Terminate all instances in one region
- Simulate a complete AZ failure (particularly where ephemeral instances are used)
- Allows you to test how your application will respond (we assume you’ll run some traffic through during the simulated outage).
- Measures recovery time for primary region after it becomes available again
- All instances replaced or rebuilt from secondary DC
- A repair would (likely) be required to catch up on writes missed during the outage.
Scenario 3: Accidental/Malicious Delete, Data Corruption, etc.
For these scenarios, typically a partial data restore is required. The recovery method, as well as the amount of data that can be recovered, will invariably depend on the nature of the data loss. You should contact [email protected] as soon as possible for expert advice.
We have extensive experience in complex data recovery scenarios.
Case Study: Accidentally Dropped Table
Problem: Human error caused a production table to be accidentally dropped.
Solution: Instaclustr TechOps was able to quickly reinstate the table data from the snapshots stored on disk.
Recovery time: Less than one hour.
Case Study: Data Corruption Caused by Cluster Overload
Problem: Unthrottled data loads caused SSTable corruption on disk and cluster outage.
Solution: Combination of online and offline SSTable scrubs. Some data was also able to be recovered from recent backups. A standalone instance was used to complete some scrubs and data recovery, in order to parallelise the work and reduce impact to live prod clusters.
Recovery time: Approximately 90% of the data was available within the same business day. Several weeks to recover the remainder. A small percentage of data was not able to be recovered.
Conclusion
In this post, we discussed common failure scenarios within Apache Cassandra, their respective causes and recovery solutions, as well as other nuances involved. Instaclustr has invested the time and effort to gain industry-leading, expert knowledge on the best practices for Cassandra. We are the open source experts when it comes to architecting the right solution to protecting and managing your data within Cassandra.
Have more questions on Cassandra disaster recovery and other best practices? Reach out to schedule a consultation with one of our experts. Or, sign up for a free trial to get started with Cassandra right away.