Apache HBase® and Apache Cassandra® are both open source NoSQL databases well-equipped to handle incredible amounts of data–but that’s where the similarities end.
In this blog, discover the architectures powering these technologies, when and how to use them, and which option may prove to be the better choice for your operations.
What is Apache HBase?
Apache Hbase is an open source NoSQL database built on top of the Hadoop Distributed File System (HDFS). It is a fault tolerant, distributed system designed for random read/write of large volumes of data.
What is Apache Cassandra®?
Apache Cassandra is an open source, non-relational (or NoSQL) database that supports continuous availability, tremendous scale, and data distribution across multiple data centers and cloud availability zones.
HBase vs. Cassandra: The Difference
Both HBase and Cassandra were born from the same requirement: Storing and processing immense amounts of sparse data. However, they achieve this requirement by different means.
Architectures
HBase
HBase is built on top of HDFS, which is used to store the data that is being processed by HBase. HDFS is a distributed file system used by Apache Hadoop®.
HBase acts as an in-memory layer for reading and writing the data to HDFS.
An HBase deployment requires servers performing 3 roles: HMaster, Region Server, and Apache ZooKeeper™. These roles can be performed by a single node, but for a cluster of any reasonable size these roles should be assigned to individual servers.
HMaster Server
The HMaster is responsible for region assignment. In HBase, a region is a group of lexicographically adjacent rows. The HMaster is responsible for distributing regions evenly across the available region servers and keeping their sizes roughly equivalent.
Additionally, the HMaster handles the DDL commands such as creating and deleting databases.
Finally, the HMaster server is constantly observing the region servers and handling load balancing and failover operations for the cluster.
Region Server
The primary role of these servers is to serve read and write requests. Each region server is responsible for the data that falls within its assigned region. A single region server can serve data for multiple regions, into the thousands.
Apache ZooKeeper™
ZooKeeper is used as the central source of truth for the health of the cluster, and the current state of the tenant servers within it. When a change in configuration is observed in the cluster, such as a region server becoming unavailable, it will notify the HMaster which can take the appropriate action.
ZooKeeper itself is often deployed in a cluster formation of at least 3 nodes, where it can effectively perform fault tolerant configuration management via consensus among its servers.
Apache Cassandra®
A Cassandra cluster is comprised of homogenous servers, called nodes, connected to each other and all performing the same role. Cassandra is a masterless system, meaning no single node is the sole source of truth for the data within the cluster.
Data in a Cassandra cluster is split between the nodes using the primary key that is then hashed and assigned to the node or nodes which are responsible for serving that hash.
Cluster administration and failover is handled internally by the cluster nodes themselves, communicating via the gossip protocol. This system can coordinate shuffling data to new nodes, marking nodes as offline and failing over in the event of an outage.
Data Models
HBase
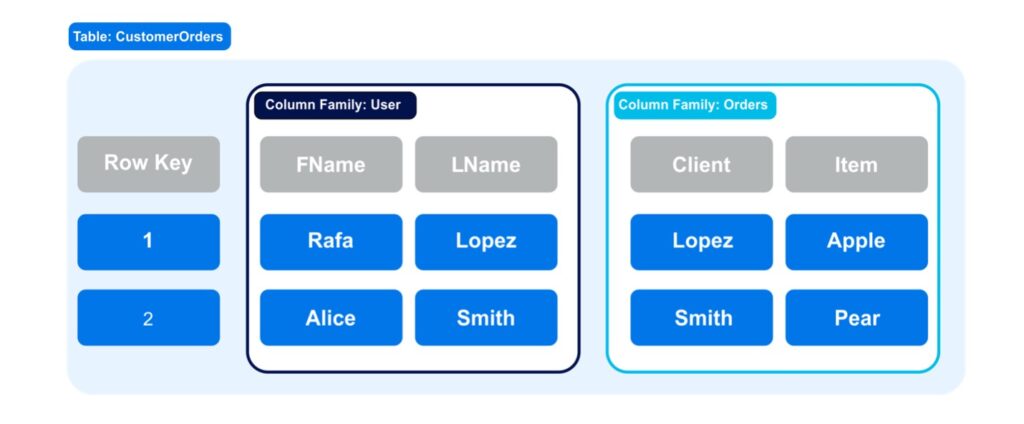
At the top level of the HBase data model is the column-oriented Table. Each table has a set of row-keys which can be thought of as a primary key in a traditional relational database.
Rows are divided into related columns of data called column families.
This data structure allows related information to be stored close to each other on disk which makes reads more efficient.
Example read:
|
1 |
get ’<table name>’,’row1’ <span data-ccp-props="{"201341983":0,"335559740":259}"> </span> |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
> get 'CustomerOrders ', '1' COLUMN CELL User: FName timestamp = 1675123184293, value = Rafa User: LName timestamp = 1675123184293, value = Lopez Orders: Client timestamp = 1675123388213, value = Lopez Orders: Client timestamp = 1675123388214, value = Apple 4 row(s) in 0.0260 seconds |
Apache Cassandra
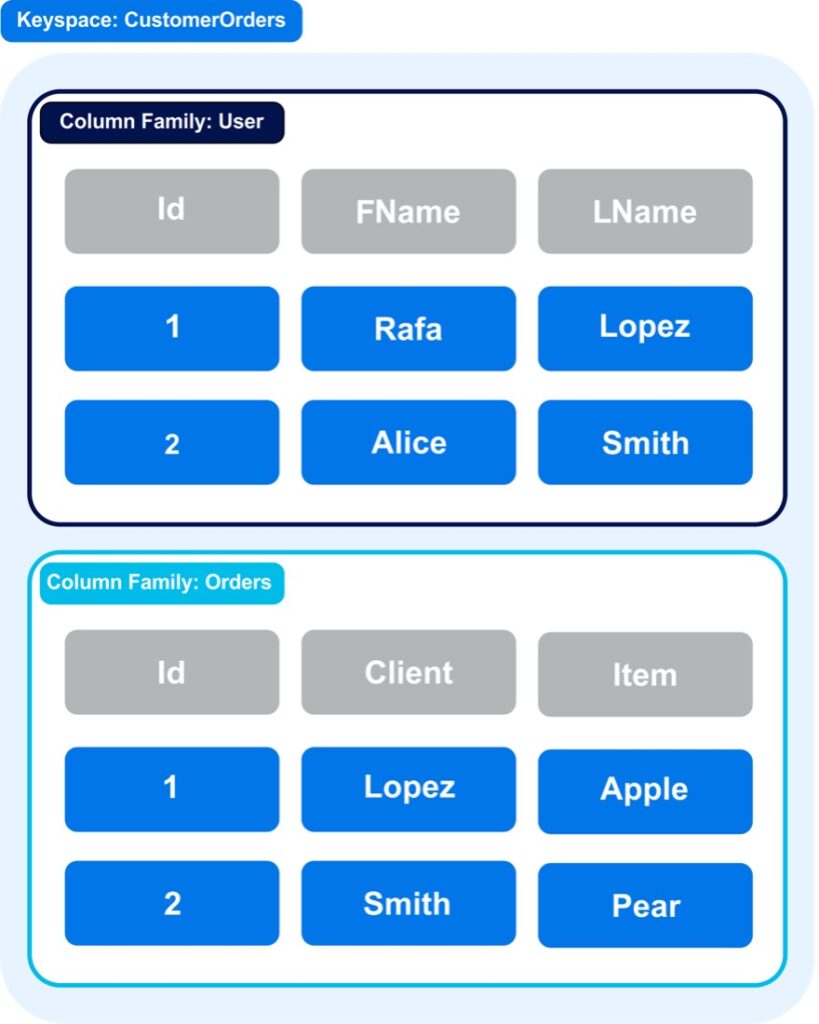
Cassandra’s data model is best described as a partitioned row store. At the top level of the Apache Cassandra data model is the Keyspace. Within a keyspace are column-families (aka tables).
In Cassandra’s partitioned row store, rows within a column-family are stored together on disk.
Example read:
|
1 |
select <columns> from <table>; <span data-ccp-props="{}"> </span> |
|
1 2 3 4 5 6 7 8 9 |
cqlsh> select * from User; id | fname | lname --------+-----------+---------- 1 | Rafa | Lopez 2 | Alice | Smith (2 rows) |
HBase vs. Apache Cassandra Security
HBase Security
HBase also supports user authentication and authorization. Client encryption is achieved in conjunction with Kerberos authentication on the cluster.
Authorization can be restricted down to the cell level, if required.
Cassandra Security
Cassandra supports basic security features such as user authentication and authorization. Users can be assigned roles, which can restrict access to records; down to specific rows in a column family, if required.
Client connections support SSL (Secure Sockets Layer) encryption, and internode communication can also be SSL encrypted.
Since Cassandra 4, audit logging can be enabled on the cluster to allow administrators to see who performed what command on the data.
Performance
Read and Write
Cassandra is designed for large scale data ingestion, and it writes data simultaneously to log and cache, making it the faster of the 2 technologies for writing data.
HBase writes must be negotiated through ZooKeeper, then the HMaster to determine where the data should be written, which negatively impacts its write speed.
Conversely, the masterless design of Cassandra makes the read path slower, as data is retrieved by consensus among the nodes that hold the data.
HBase can take advantage of the HDFS underpinnings, which include bloom filters and caches, which allows its read performance to outperform Cassandra given a similar data set.
Transactions
ACID transactions are not possible in HBase by default, but they are made possible when combined with Apache Phoenix™, although this feature is still in beta.
Cassandra does not support ACID transactions. You can update a record using compare and set, which Cassandra also calls lightweight transactions, but no rollback capability exists.
Query Language
Cassandra provides a SQL-like language called CQL. With CQL you can select, insert, update, and delete records with very similar syntax to SQL. However, care needs to be taken with large data sets, as poorly optimized queries can significantly impact cluster performance.
CQL can be used in conjunction with many other Apache Cassandra client libraries, or directly with the Cassandra cluster.
The HBase shell is the closest analogue to a query language for HBase. You can use put(), scan(), create(), and other commands to interact with your data. Apache Phoenix can be added to HBase which does give it a SQL-like query language.
A better way to use your HBase cluster is to use the Java API. While this does require you to use Java, it allows a much richer way to create, insert, and update your data in HBase.
Key Similarities Between HBase and Cassandra
Scalability
HBase can be scaled up by adding nodes to the cluster. Most of the time, we would be adding nodes to serve as region servers. HBase automatically splits data sets into new regions when they get too large, and adding region servers allows HBase to distribute the load more effectively.
It is possible to add additional HMaster nodes, but only 1 master is available at a time, so the new node would exist for failover purposes only.
Cassandra can also be scaled by adding additional nodes to the cluster. Cassandra uses a consistent hash to evenly partition the data in the cluster to the nodes within. Adding new nodes to a cluster immediately distributes data to that node. The amount of data depends on numerous factors such as how much total data exists in the cluster, number of nodes, replication settings, and others.
Both HBase and Cassandra were designed to be distributed, scalable databases and can scale to hundreds of nodes effectively.
Replication Capabilities
In HBase, data replication is handled by HDFS. HDFS replication settings can be any number, typically 3. A replication factor of 3 means there is 1 primary copy of data, which is then replicated to 2 additional servers.
HDFS Replication is rack aware, meaning when it assigns replicas it will prioritize servers that are on different networks or racks. This ensures that the system can tolerate a single network outage and not lose data.
In Cassandra, replication is handled internally. Replication settings are set on individual keyspaces, and they can also be made rack aware like HDFS.
In contrast to HBase, Cassandra doesn’t have a primary replica or master node for a particular record. If the keyspace has a replication factor of 3, a write command will be issued to all 3 nodes responsible for that data.
Unique to Cassandra, is the concept of the data center. A data center in Cassandra is how we can define a set of nodes and racks in a geographical region. A Cassandra cluster can consist of one or more data centers, and replication can be configured between them.
What this means in practice is you can have a single database with different regional localities which allows clients to achieve lower latency but still maintaining data consistency between the regions.
Common Use Cases
Both Cassandra and HBase are built to handle, store, and distribute huge data sets as their primary objective. They do differ in some areas, which may help inform which system is the best suit for you.
Application of HBase
The best reason to use HBase is to take advantage of the Hadoop and HDFS underpinnings. The main drawcard is the support for MapReduce, which is a method of processing and analyzing a huge scale of data in parallel.
The application of Hadoop and HDFS are manifold, and industries include the Financial, Healthcare, and Telecom sectors. These industries have a huge amount of data across millions of customers which presents a large set of data to store and analyze.
Application of Cassandra
Sometimes you just need to store a lot of data quickly, and that’s where Cassandra shines. Use cases like IoT (Internet of Things) devices, internet messaging, or application metrics where we need to store large amounts of data frequently but may need to access it infrequently.
That’s not to say Cassandra is not suitable for read loads. Effectively designed data models and queries can make Cassandra a great place to store and retrieve data.
Which is Better—HBase or Cassandra?
As with most things, there is not a “best” option, per se—but that does not necessarily mean that both technologies will offer equal value for you in the long run, either.
HBase and Cassandra are certainly excellent choices for big data, NoSQL databases. They are both scalable, highly available, and consistent databases that can store large amounts of data in an efficient and inexpensive way with no vendor lock-in.
If you anticipate using the features offered by Hadoop such as MapReduce, then HBase does make itself an obvious choice. But if you do not need those specific features—and don’t anticipate needing them in the future—then Cassandra can prove to be the more attractive option for several reasons.
If you have other analytics tools already or want a streamlined infrastructure deployment, Cassandra can fill that requirement. Equally, if you require data replication between geographical regions, Cassandra natively supports these deployments and is the logical choice.
But with Cassandra, you also get an incredible array of support on top of an already-robust community. This includes managed platforms to offload your entire Cassandra operations—complete with the flexibility to operate on-prem or in the cloud—leaving you to focus entirely on your applications. Expert and diverse help is also easy to come by for those inevitable situations when you run into trouble with your Cassandra clusters—a situation with which Instaclustr’s Cassandra consultants are very familiar.
Ultimately, it will come down to your particular data problems to decide which tech could be the best option for you. While both offer incredible capabilities—some distinct, others similar—if you don’t envision ever needing any of the features unique to HBase, then the wealth of additional resources and community expertise that comes with Cassandra certainly makes it the worthwhile option for long-term value.
Discover what to expect from Apache Cassandra® NoSQL for Relational DBA