
USS Enterprise NCC-1701 Warp Drive
(Source: Bryan Alexander, CC BY 2.0, via Wikimedia Commons)
{kind=link}
As every “Trekky” (a fan of Star Trek) knows, in the Star Trek universe spaceships can travel at speeds faster than light using warp engines fuelled by antimatter. It turns out that antimatter is real enough in our universe, but very rare—luckily for us the universe is mainly made up of matter (or we wouldn’t exist).
In the Apache Kafka® universe, you also want to keep the quantity of anti-patterns to a minimum. What are Kafka anti-patterns? Basically, any Kafka design that can negatively impact the performance, scalability, and reliability of applications built using Kafka. Over the last 6 years building multiple Kafka demonstration applications and blogging and talking about Kafka I’ve inevitably made some mistakes and introduced anti-patterns. In this blog, I’ll recap some of the most serious Kafka anti-patterns that I’ve encountered, and hopefully prevent you from blowing up your warp drive—or, in the words of Scotty (the Enterprise’s Chief Engineer):
“She cannae take any more, Cap’n! She’s gonna blow!”
Scotty
1. Too Many Topics: One or Many Topics? (The more topics the merrier vs. one topic to rule them all)
Our first topic is topics—one or many. Topics are a logical place to start with Kafka anti-patterns, as topics are the primary mechanism that Kafka has for message routing from producers to consumers.
Way back in 2018, I built an IoT/logistics demonstration Kafka application called “Kongo” (an early name for the Congo river, as the name “Amazon” was taken). One of the critical design choices I faced was around the data model, or how many topics to use—one or many.
The most natural design was to have a large number of topics (100s) to enable the relevant subset of messages to be delivered to a subset of recipients (consumers). There were 100s of warehouse and truck locations, and rules associated with Goods (10s of thousands) to check environmental and transportation conditions, but only for events produced by locations where the Goods were located, and events from other locations could be ignored (but events from each location had to be delivered to many consumers, so 1-many delivery). I called this the “location specific” pub-sub pattern, as each topic was used to deliver events for one location only as shown in this diagram:
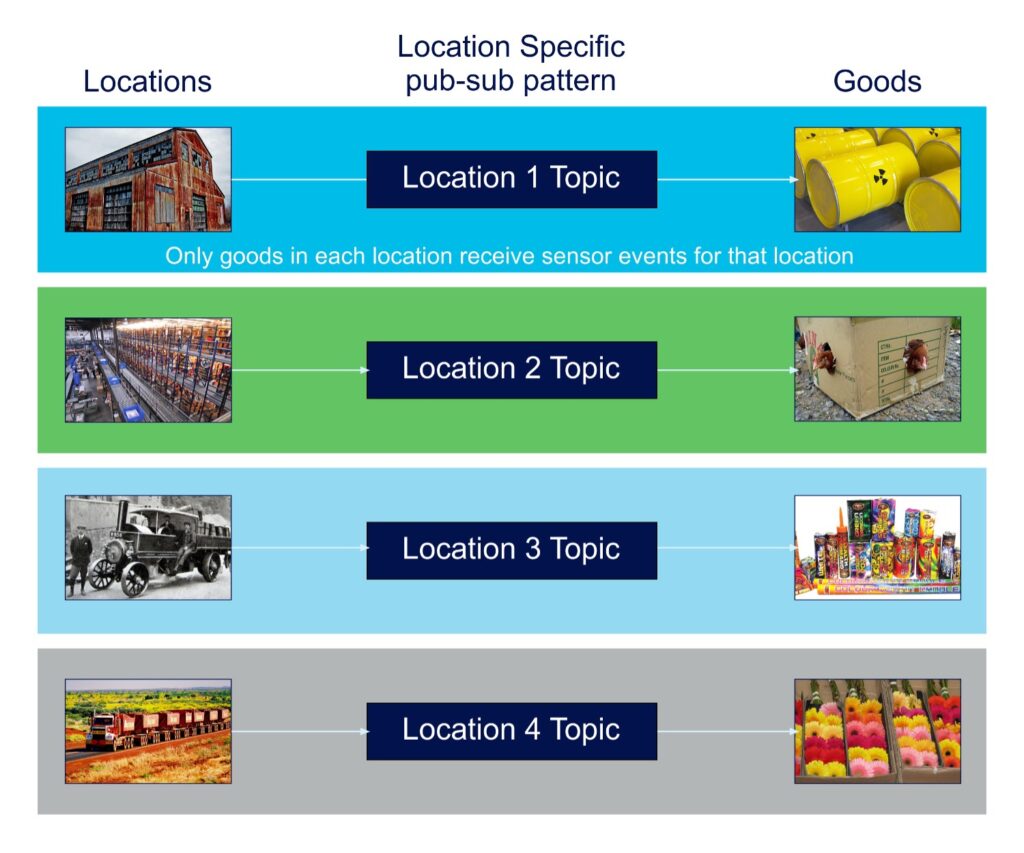
However, even though this was the most natural design, initial performance benchmarking revealed that the scalability suffered. So, taking inspiration from the Dark Lord Sauron, I changed the design to the other extreme—one topic (to rule them all). The problem then was how to route the messages for each location to the Goods in each location. To do this I introduced another technology (the Guava EventBus) to provide content-based routing. Here’s the “one topic” design diagram:
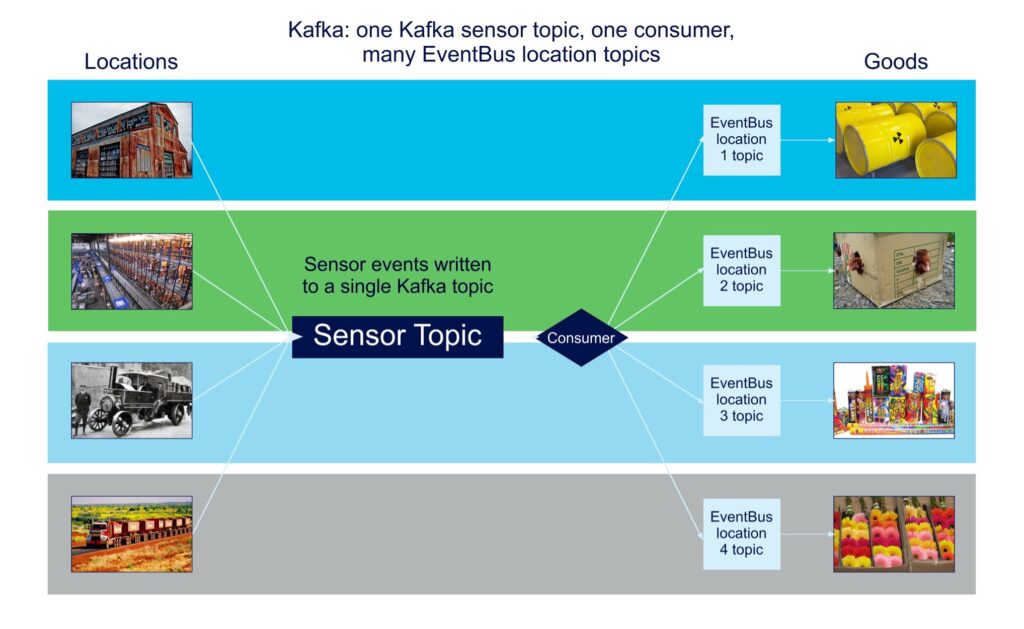
Benchmarking revealed a significant improvement.
So, the first anti-pattern we’ve identified is having too many topics. But how many topics is too many? Well, it depends. When I built the “Kongo” application the hardware and version of Kafka were older. The problem with too many topics was potentially also related to the number of partitions. Each topic has 1 or more partitions—partitions are the basic unit of concurrency in Kafka. They enable concurrency in the cluster and consumers—the more partitions a topic has the more consumers and therefore concurrency/throughput it can handle. So, 1,000 topics have at least 1,000 partitions. So, let’s have a look at the problem of too many partitions in more detail.
2. Too Few or Too Many Partitions
(Source: Stilfehler, CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons)
This may look like a hair wig, but it’s actually a prop Tribble from the Star Trek episode “The Trouble with Tribbles”. Tribbles are cute furry creatures that rapidly multiplied on the USS Enterprise, threatening to overwhelm the crew.
In Kafka, you must keep the number of partitions (not Tribbles) under control. I conducted some detailed benchmarking in 2020 which revealed that the optimal number of partitions was between the number of cores in the Kafka cluster (typical 10s) and 100. Any more than 100 partitions resulted in a significant reduction in throughput as shown in this graph of Partitions (log10) vs. Throughput:
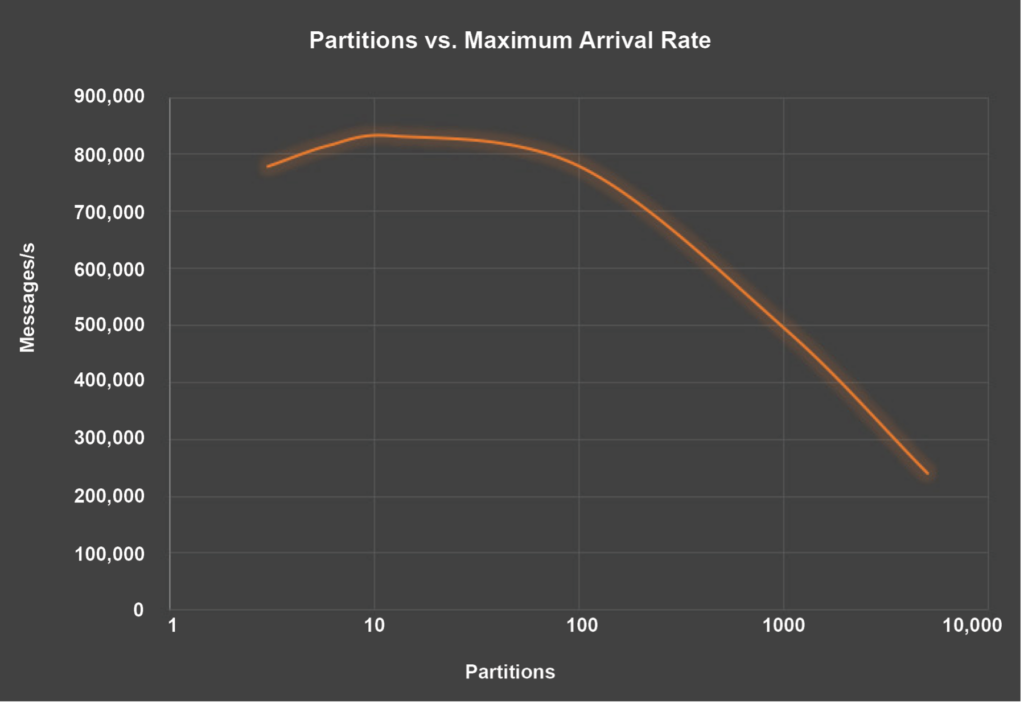
However, Kafka has recently been upgraded with a KRaft mode to replace Apache ZooKeeper which speeds up meta-data operations and allows for more topics and partitions. Our newest benchmarking shows that it is possible to have 1000s of topics and partitions now, but throughput does still drop off when there are more than 1,000 topics. Of course, a bigger cluster will help. Here are the updated results of benchmarking Partitions (log10) vs. Throughput (Millions of messages/s)—which also shows that for data workloads there’s no difference between KRaft and ZooKeeper modes:
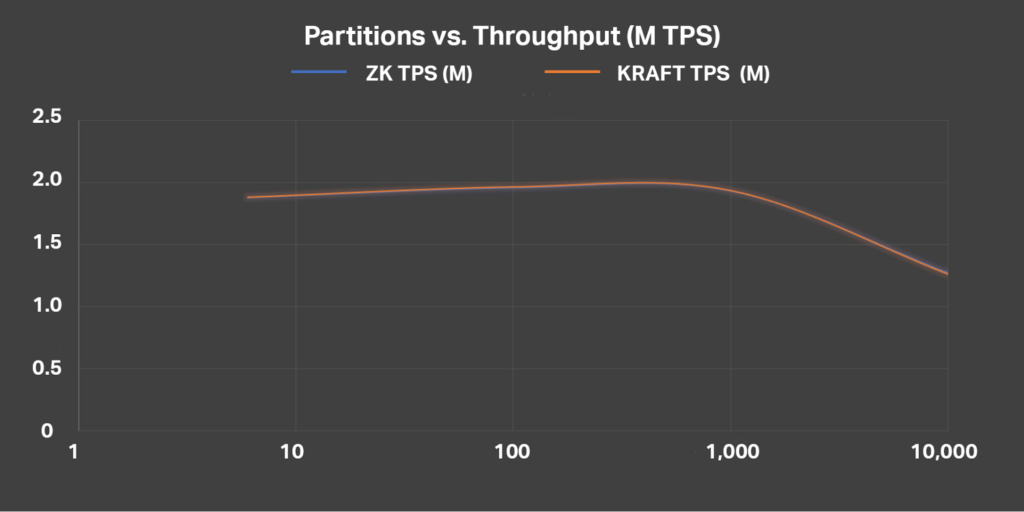
But how can you keep the number of partitions under control?
3. Slow Consumers (and Too Many Partitions)

(Source: Andrzej Mirecki, CC BY-SA 3.0 via Wikimedia Commons)
{kind=link}
The USS Enterprise had an “impulse” drive for slow (sub-warp speed) travel—this is IKAROS the first successful solar-sail spacecraft, flying past Venus at km/h—very slow for a spaceship (the fastest speed by a spacecraft, the Parker Solar Probe, was 586,800 km/h).
Kafka consumer throughput depends on the ability of Kafka to support multiple consumers in each consumer group. Each consumer processes a subset of the partitions available. The maximum concurrency is achieved with a single consumer per partition. The traditional Kafka consumer is, however, only single-threaded. This means that if the thread is held up doing something slow (e.g., database access)—the so-called “slow consumer” problem— then the throughput for the consumer is reduced significantly, and you must consequently increase the number of consumers and partitions to achieve higher overall throughput.
There are a couple of ways to beat the slow consumer problem. The first is to optimize consumers for the polling loop to be as fast as possible. For example, in my Anomalia Machina application I introduced a separate thread pool to isolate the slow event processing (database access and running an anomaly detection algorithm) from the fast consumer topic polling. The second approach is to increase the concurrency in the consumer. A new Parallel Kafka Consumer recently became available, and I’ve written about it in a 2-part blog series (part 1, part 2). The new consumer is multi-threaded so has the potential to reduce the number of consumers and therefore partitions required for high throughput and slow consumer use cases.
4. Too Few Keys

Car park chaos—in Kafka you need sufficient keys to avoid
Knuth’s “spaceship” parking problem
(Source: Shutterstock)
In Star Trek, it was important to keep the warp core (the engine) balanced or you could end with a warp core breach (a catastrophic failure of the warp drive containment field)! For Kafka, it’s also important to keep the partitions balanced.
One of Kafka’s super-powers is the ability to deliver messages in order—this is one of the processing and delivery guarantees that Kafka provides (others include at-least-once or exactly-once delivery, etc.). This is often critical for event/message-based systems as order can matter. However, there is a proviso, as messages are only delivered in order within partitions. And you will need record keys to do this—messages with the same key are delivered to the same partition so will be in order—for example, if the “customer ID” is the key, then every message related to a customer will be delivered to the same partition and will be delivered in order.
Kafka also works fine without keys and uses a round-robin delivery in the absence of a key, but the messages will not be delivered in order as a result. Note that a “Sticky Partitioner” was introduced in Kafka 2.4 to improve record batching when there’s no key (but isn’t strictly round-robin). This had some performance issues so the “Strictly Uniform Sticky Partitioner” is available from 3.3.0.
The ideal key will satisfy several properties. The first is that it should be uniformly distributed, not “lumpy” or skewed—which would result in hot spots on some brokers (including more data stored on some brokers). The second is that you need sufficient key values (key cardinality) to ensure that you don’t end up with Knuth’s car parking/hash collision problem. In Kafka, this can happen if some partitions receive more events than others, and some receive no events at all in a period of time, resulting in consumer “starvation” and timeouts. The consequence is that you end up with fewer consumers than you need and consumer group rebalancing storms, as new consumers are created to try and fill the gaps resulting in consumers terminating.
My rule of thumb is that you need lots more key values than the number of partitions/consumers in a consumer group—at least 20 times more in fact. This shouldn’t be a problem with small numbers of partitions, but if you do need 1 million partitions then you need to check that you have at least 20 million key values for this to work. Here’s a blog where I discussed this in the context of the “Kongo” application (including how to choose a good key).
5. Ignoring Exceptions: Failure Is Not an Option

The damaged Apollo 13 Service Module
(Source: NASAScan by Kipp Teague, Public domain, via Wikimedia Commons)
.jpg){kind=link}
After the onboard explosion of a fuel cell on the manned Apollo 13 mission, the crew had to jury rig the spacecraft to get them home safely—making the mission a “successful failure”. In the blog series “Building and Scaling Robust Zero-Code Streaming Data Pipelines with Open Source Technologies” I discovered that it was easy to build a pipeline that worked (briefly), but harder to build a robust pipeline that continued working in the presence of errors. It turned out that there were multiple potential sources of exceptions when using Kafka connectors (errors in the message format and content, errors thrown by sink systems, etc.) and you need to pay careful attention to detecting and resolving errors. I was initially surprised by the fact that Kafka connectors could fail, as previously I tried some experiments and found them to be robust—you can kill them, and they restart automatically. However, it turns out that if the connectors fail due to uncaught exceptions they don’t automatically restart (the exception is assumed to be permanent and needs human intervention). This blog covers how to introduce robust error handling using KIP-298 and a dead letter topic.
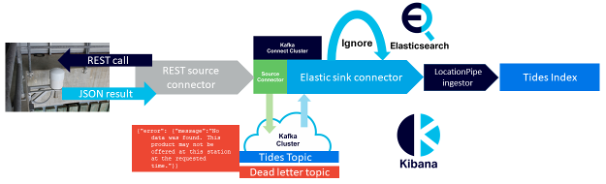
For Kafka® Connect, another thing to watch out for is the scalability of sink systems, particularly ones that use a slow protocol (e.g. Elasticsearch/OpenSearch®)—Kafka Connect can generate vast amounts of data, and the sink systems need to be resourced and configured for the expected scalability demands, and the Kafka sink connectors can also benefit from using batching.
This blog explores some of the problems and solutions around scaling Kafka Connect and various sink systems (Elasticsearch and PostgreSQL). These 2 blogs (pipeline series part 8, pipeline series part 9) explore some more scalability aspects including the use of the Elasticsearch Bulk API/sink connector.
Another source of potential failures in Kafka is the Schema Registry. I explored Karapace (Karapace the Open Source Schema Registry for Apache Kafka) in a blog series and discovered that failures can result from Schema validation and evolution. One recommendation I have is to set the auto register schemas configuration to false to prevent unwanted surprises.
6. A Single Giant Kafka Cluster: One vs. Many Cluster

Omega Centauri with 10 million stars is the largest globular cluster in the Milky Way (Source: ESO, CC BY 4.0, via Wikimedia Commons)
{kind=link}
I’m not sure if the USS Enterprise travelled to Omega Centauri, but I am sure that you shouldn’t try a 10 million broker Kafka cluster—the largest Kafka cluster we run for customers has around 100 brokers, but we do often run multiple Kafka clusters per customer.
Splitting a single Kafka cluster into multiple clusters is often a preferred architectural or deployment/operational choice. This is an alternative I explored when scaling my Kongo Kafka application, as it made sense to deploy different workloads to different clusters. High fan-in or fan-out architectures can also be optimized with layered/multiple cluster topologies. Geographical replication is one common use case that requires multiple clusters and Apache Kafka MirrorMaker2 (MM2) is commonly used for cross-cluster replication. See my MM2 blog series MM2 Theory and MM2 Practice. But watch out for MM2 Anti-Patterns—infinite event loops and infinite topic creation (MM2 has automatic cycle detection—but it is possible to still make mistakes).
7. Ephemeral Kafka Consumers
In the later series, Star Trek Voyager, the crew came across the ephemeral Ocampa who had powerful mental abilities (one of them even joined the crew). So, the final Kafka Anti-pattern is a novel one of my own invention. I needed a Kafka consumer, but only briefly, for my Drone delivery application which integrated Uber’s Cadence (workflow engine) and Kafka. An ephemeral Kafka consumer tightly coupled with a workflow is basically a bad idea for scalability and latency, as it will trigger Kafka consumer group rebalancing every time it’s created/destroyed. This blog has the solution—a long-lived consumer, not tightly coupled with workflows.
To summarize, try to avoid these Apache Kafka Anti-Patterns:
- Too many topics
- Too few/many partitions
- Slow consumers
- Too few keys
- Ignoring exceptions
- Single giant Kafka clusters
- Ephemeral consumers
Or, to annihilate these anti-patterns and get up to “warp speed”, design and tune for these Apache Kafka Patterns:
- Few topics
- Just the right number of partitions (increase as required)
- Fast consumers
- Large key cardinalities
- Expect and catch exceptions
- Multiple Kafka clusters where appropriate
- Long-lived consumers

“Give Me Warp Speed, Mr. Sulu”
(Source: Shutterstock)