1. Introducing Karapace
As we saw in Part 1 and Part 2 of this blog series, if you want to use a schema-based data serialization/deserialization approach such as Apache Avro, both the sender and receiver of the data need to have access to the schema that was used to serialize the data. This could work in a number of ways. The schema could be hardcoded on both sides, or it could be embedded in the data (which was how it worked for the example we used writing and reading the data from a file—this would work fine if the volume of data exceeds the size of the schema, and ensures that the schema is always available when it needs to be deserialized). Alternatively, the schema can be made available from another source, such as a registry service. This is the approach used by the open source Karapace Apache Kafka® Schema Registry service.
Because Apache Kafka is “schema-less”, and doesn’t know or care about the content of records, the main function of a Schema Registry Service is to act as an intermediary between Kafka producers and consumers, enabling simple sharing (e.g. registration and lookup) of schemas. Here’s a high-level diagram showing the various roles and interactions:
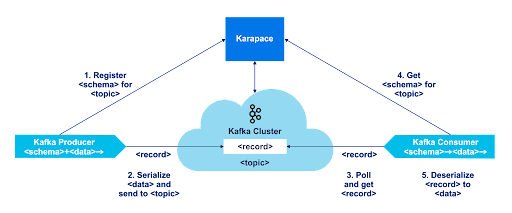
The (simplified) steps are as follows:
- A Kafka producer wants to send data (with a schema) to a topic. It registers the schema for the topic in Karapace
- The producer serializes the data using the schema and sends it to the topic
- A Kafka consumer polls the topic and gets a record
- It gets the schema for the topic from Karapace, and
- Deserializes the data using it
This was a pretty standard approach to service publication, discovery and consumption for Service Oriented Architectures (SOAs)—registry services (e.g. UDDI) were a critical component for connecting large scale heterogeneous distributed services—and used the publish-find-bind pattern; service producers published service descriptions in a registry service, and service consumers discovered the service in the registry service and called the service with the registered protocols and interface.
Some of the Kafka/Karapace specific aspects that are worth mentioning include:
1. Producers and consumers do not communicate with Karapace for every record sent/read. This would overload Karapace and introduce unacceptable latencies into an otherwise low-latency system. Instead, producers and consumers cache schemas locally.
2.The use of schemas for topics is not enforced by Karapace or Kafka—it’s only a “convention”. Producers and consumers are free to ignore Karapace and schemas, allowing them to write and read data in any format they like.
 Not playing with your food is just a convention.
Not playing with your food is just a convention.
(Source: Shutterstock)
3.The Kafka cluster is not directly involved—apart from storing the schemas for Karapace. In the proprietary Confluent version of the Kafka Schema Registry there is an optional Broker-Side Schema Validation mode, which means that the “convention” is enforced by the Kafka cluster. However, this mode is not available for Karapace.
4. Because the use of Karapace and Schemas adds new restrictions on client behavior (interactions with Karapace, and writing and reading data), there may potentially be more exceptions than normal in the producers and consumers depending on client and Karapace settings, and combinations of data and schemas, etc (due to schema, topic, data, and code incompatibilities—see the next parts in this series for examples). These will need to be recorded and handled appropriately.
The mapping from schemas to topics is a simplification, it actually maps from schemas to subjects, see below.
Some of the main features of Karapace are:
- It’s an open source Apache 2.0 licensed Schema Registry for Kafka
- It supports 3 Schema registry types, Apache Avro, JSON schema, and Protobuf
- It provides a REST interface for schema management (e.g. using curl)
- It can be configured for HA.
For more information on Karapace, see the documentation, and Instaclustr’s Karapace support documentation (this explains how to create a Kafka cluster with the Karapace add-on option, and how to configure Kafka clients to use it).
2. A Platonic Solids Kafka Karapace Example

The great Tetrahedron of Giza—more commonly known as a Pyramid!
It has a volume of approximately 92 million cubic feet (2.6 million cubic meters).
(Source: Shutterstock)
As we saw in the previous blog, Apache Avro can be used to Serialize and Deserialize lots of things, including Platonic Solids. With the Karapace Schema Registry we can also use Kafka with Avro to demonstrate this. Details of how to configure the required producers and consumer properties and Maven dependencies to use Karapace are here. The critical properties are setting schema.registry.url for producers and consumers, setting value.serializer to KafkaAvroSerializer for producers, and value.deserializer to KafkaAvroDeserializer for consumers.
3. Kafka Karapace Producer Example
Reusing the automatically generated Avro-specific Java data class we made in the previous blog (PlatonicSolid.java), here’s an example producer that uses Karapace to serialize Kafka record values as Avro:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
package example.avro; import org.apache.avro.Schema; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import io.confluent.kafka.serializers.KafkaAvroSerializerConfig; import java.io.FileReader; import java.io.IOException; import java.nio.ByteBuffer; import java.util.Properties; public class AvroProducer { public static void main(String[] args) { Properties kafkaProps = new Properties(); // Auto register schemas is true by default kafkaProps.put(KafkaAvroSerializerConfig.AUTO_REGISTER_SCHEMAS, true); try (FileReader fileReader = new FileReader("producer.properties")) { kafkaProps.load(fileReader); } catch (IOException e) { e.printStackTrace(); } // volume of the great pyramid of Giza is 92M cubic feet PlatonicSolid solid = new PlatonicSolid("pyramid", 4, 4, (float) 92000000); String topic = "avrotest"; String key = null; ProducerRecord<String, PlatonicSolid> record = new ProducerRecord<>(topic, key, solid); try (KafkaProducer<String, PlatonicSolid> producer = new KafkaProducer<>(kafkaProps)) { producer.send(record); producer.flush(); System.out.println("Sent: topic " + topic + ", key " + key + ", value " + solid.toString()); } catch (Exception e) { e.printStackTrace(); } } } |
This code serializes the Great Pyramid of Giza and sends it to a Kafka topic with the following details:
|
1 |
Sent: topic avrotest, key null, value {"figure": "pyramid", "faces": 4, "vertices": 4, "volume": 9.2E7} |
Note that, unlike the Avro Schema example in the previous blog, the schema is not included inline in the data (topic record in this case), but is now automatically stored and available for reuse in the Karapace registry service. We can confirm this with a curl command:
|
1 2 3 |
curl -X GET -u schemauser:schemapassword https://schemaURL:8085/subjects/avrotest-value/versions/latest {"id": 8, "schema": "{\"fields\": [{\"name\": \"figure\", \"type\": \"string\"}, {\"name\": \"faces\", \"type\": \"int\"}, {\"name\": \"vertices\", \"type\": \"int\"}, {\"name\": \"volume\", \"type\": [\"float\", \"null\"]}], \"name\": \"PlatonicSolid\", \"namespace\": \"example.avro\", \"type\": \"record\"}", "subject": "avrotest-value", "version": 1} |
If you look more closely at this command and the result, you will notice several Karapace specific features. First, in the command, the URL is requesting the latest version of the schema associated with the subject “avrotest-value”. A karapace subject maps schemas to Kafka topics, with the addition of either “-value” or “-key” to the topic name depending on which part of the record the schema is registered for. So, there will be 2 subjects associated with a topic if there are schemas registered for both key and value parts of the record. To get the schema associated with a topic you must specify the complete subject name including the value or key portion. Note that this implicit mapping from schemas to topic names is using the default Subject Name Strategy, called the Topic Name Strategy. Other strategies are possible and may allow for sharing schemas among multiple topics, or multiple schemas per topic.
In the result, there’s also an ID field (every schema in a Karapace registry has a unique numeric ID), the subject again, and a version number. We’ll investigate versioning in more detail in another blog, but, because we asked for the latest version, we know this schema is the current one that will be used by producer/consumer pairs for simple use cases at least.
4. Kafka Karapace Consumer Example
Here’s an example consumer which deserializes PlatonicSolid.java objects from Avro Kafka records using Karapace:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
package example.avro; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import java.io.FileReader; import java.io.IOException; import java.time.Duration; import java.util.Collections; import java.util.Properties; public class AvroConsumer { public static void main(String[] args) { Properties kafkaProps = new Properties(); try (FileReader fileReader = new FileReader("consumer.properties")) { kafkaProps.load(fileReader); } catch (IOException e) { e.printStackTrace(); } String topic = "avrotest"; try (KafkaConsumer<String, PlatonicSolid> consumer = new KafkaConsumer<>(kafkaProps)) { consumer.subscribe(Collections.singleton(topic)); System.out.println("Subscribed to " + topic); while (true) { ConsumerRecords<String, PlatonicSolid> records = consumer.poll(Duration.ofMillis(100)); for (ConsumerRecord<String, PlatonicSolid> record : records) { System.out.println(String.format("topic = %s, partition = %s, offset = %d, key = %s, value = %s", record.topic(), record.partition(), record.offset(), record.key(), record.value())); } } } } } This code successfully recreated the pyramid object as follows: topic = avrotest, partition = 0, offset = 0, key = null, value = {"figure": "pyramid", "faces": 4, "vertices": 4, "volume": 9.2E7} |
But did we really end up with the great pyramid of Giza? We may be in for a surprise as we forgot to specify the units—or materials—of our Platonic Solids, and ended up with a human pyramid instead!

The Kafka-specific Karapace Schema Registry based producer/consumer send and receive process looks similar to our previous Apache Avro diagrams but now Karapace is a critical component, and the data is serialized and deserialized to/from Kafka topics as follows:
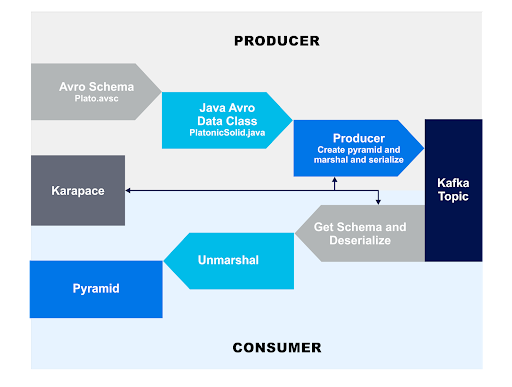 In the next part of the series, we’ll try and introduce some exceptions, to better understand the Auto Register Schema settings.
In the next part of the series, we’ll try and introduce some exceptions, to better understand the Auto Register Schema settings.
Follow the Karapace Series
-
- Part 1—Apache Avro Introduction with Platonic Solids
- Part 2—Apache Avro IDL, NOAA Tidal Example, POJOs, and Logical Types
- Part 3—Introduction, Kafka Avro Java Producer and Consumer Example
- Part 4—Auto Register Schemas
- Part 5 —Schema Evolution and Backward Compatibility
- Part 6 —Forward, Transitive, and Full Schema Compatibility
Start your Instaclustr Managed Kafka cluster today!