Recently Instaclustr announced the general availability of the Open Source (Apache 2 license) Karapace Apache Kafka® Schema Registry add-on service for our Managed Kafka service. Now, you don’t often hear the words “Kafka” and “Schema” in the same sentence, unless the sentence is something like “Kafka is a Schemaless open source distributed event streaming platform”! This is because Kafka itself does not know or care what data records contain, it’s just binary data from Kafka’s perspective. Kafka producers and consumers for each topic must have a common understanding of what the data means in order to send and receive records, so they need to have defined Serializers and Deserializers, and for Kafka Streams, SerDes.
But technically Kafka is still Schemaless. However, I do recall coming across Schemas in Open Source Apache Kafka over the last few years. For example, Kafka® Connect supports Schemas, and I came across a potential need for Schemas in my Kafka Connect pipeline series when records didn’t conform to the expected format. And finally in my Debezium series I came across change data events with explicit in-line Schemas.
So what does Karapace do to support Schemas as “first-order” entities in Kafka? Fundamentally it is a registry to store schemas common to all the topics of a Kafka cluster in a central location, so that clients (producers and consumers) can access them to correctly serialize and deserialize messages. How are Schemas defined? Karapace supports multiple Schema types, Apache Avro, JSON Schema, and Protobuf. At the start of this series I didn’t know much about Avro, so for the first 2 parts of this blog series we’ll introduce Apache Avro to serialize and deserialize a Platonic Solids example, before looking at how it works in the context of Kafka and Karapace in more detail in part 3.
1. Marshaling and Serialization

Train marshaling yards are used to put wagons into the correct order for each train.
The rules for marshaling can be complex!
(Source: Shutterstock)
Winding back the clock around a quarter of a century, there were a whole bunch of cutting-edge distributed systems technologies that I spent lots of time working with, including Corba, IDLs, Enterprise Java, XML, SOAs, WSDL, and Web Services. Marshaling and unmarshaling—converting in-memory machine or language-specific data type representations (particularly objects, including executable code) to and from other formats for storage and transmission across heterogeneous platforms—was a major challenge that these approaches tackled.
Serialization and deserialization are a subset of this problem, and are focused on the transmission of data across the network layer by converting complex data types (e.g. objects) to and from transmissible sequences of bytes and bits. The flow looks like this: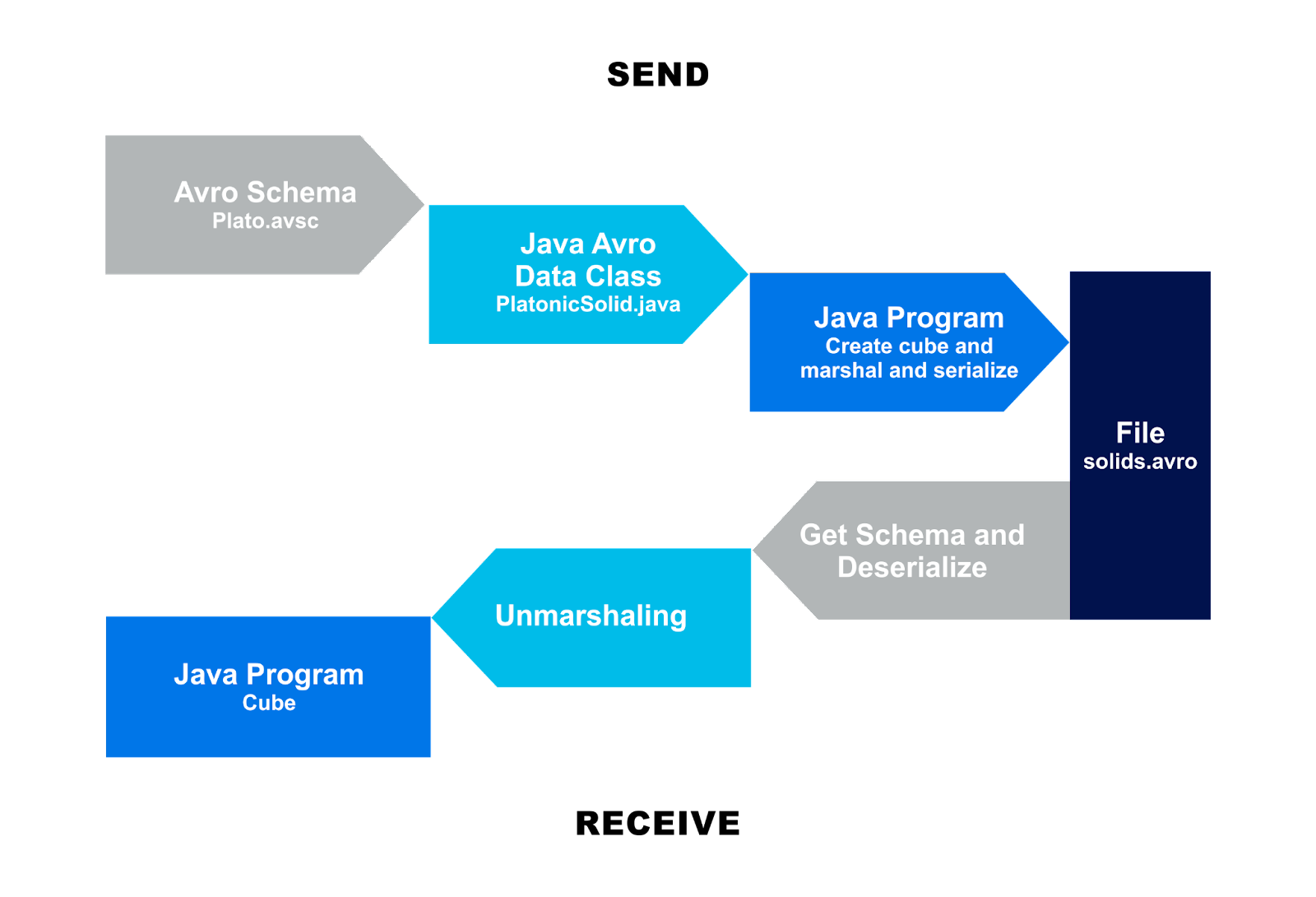
You can think of this process in terms of the steps of the old Telegram service—a service that enabled written messages (Telegrams) to be sent and received over the even older Telegraph (morse code base) service:
- The sender writes their message on the Telegram form (our first schema—it has fields for meta-data, recipient and message data), gives it to the Telegraph operator, and pays some money = Marshaling

A Telegram announcing the end of WWI
(Source: https://www.flickr.com/photos/archivesnz/10699846964, licence https://creativecommons.org/licenses/by/2.0/)
2. The Telegraph operator sends your message in Morse code = Serialization

(Source: Shutterstock)
3. At the other end of the line, another Telegraph operator decodes the Morse code back into words = Deserialization
4. And writes them down on a Telegram form, and the form is delivered to the recipient (typically by the postal service) = Unmarshaling
Marshaling and Serialization are equally important in current distributed systems as they enable heterogeneity (e.g. polyglot programming and integration/interoperability across multiple technologies), and compact/efficient network traffic and storage.
2. Apache Avro: Schema-Based Data Serialization

Plato’s philosophy of Forms (from the Greek for schema, σχῆμα) posits that ideal Forms (Ideas, Patterns, or Schemas) exist independently of their physical manifestations.
(Source: Shutterstock)
Recently I attended ApacheCon NA 2022 in New Orleans, where I came across this talk on Apache Avro by Ryan Skraba and Ismaël Mejía, “Dive into Avro: Everything a Data Engineer needs to know”. Avro is a concrete example of a serialization protocol that is also relevant to Kafka, and Karapace supports it as 1 of 3 Schema types. It therefore seemed like as good a place as any to start a more detailed investigation into Schemas. Their talk provided a good motivation and overview of Avro—it’s designed for efficient data serialization and language interoperability, and the key is that it’s designed to use Schemas. The serialization format is binary by default (it also supports JSON encoding) and is therefore extremely fast and compact. However, this means that there is insufficient meta-data available in the data to enable a random client to decode it without some extra information (e.g. there is no order, name, or type information). Help comes in the form of the Schema. Data is always written/serialized with a Schema, and the same Schema must be used when reading/deserializing the data to make sense of it.
I took Avro for a test run to make sure that I really understood what’s going on. For my first experiment, I tried the simple Java serialization example (which includes instructions for where to get Avro from), and then came up with my own version. I discovered that you start out defining an Avro Schema for your data, and that Schemas are defined using JSON—here’s the Schema specification. You can have primitive data types (null, boolean, int, long, float, double, bytes, and string) and complex data types (record, enum, array, map, union, and fixed). Unions can have any of the types listed. There are also Logical Types that allow you to define Decimal, UUID, Date, and Time data types.
3. A Platonic Avro Example: Schema and Data Class

A “Hexahedron” is known as a Cube to most people. Plato believed that the Form of the element Earth was the Cube.
(Source: Shutterstock)
A Schema has a namespace, a type, a name, and fields. Fields are an array of objects of names and types (either primitives or complex). Here’s an example Schema for the Platonic Solids (which Plato believed were Forms of the elements):
|
1 2 3 4 5 6 7 8 9 10 |
{"namespace": "example.avro", "type": "record", "name": "PlatonicSolid", "fields": [ {"name": "figure", "type": "string"}, {"name": "faces", "type": "int"}, {"name": "vertices", "type": "int"}, {"name": "volume", "type": ["float", "null"]} ] } |
The last field, volume, defines a union type with one value “null”, thereby making it an optional field (perhaps allowing for the fact that volume depends on the length of the edges for a particular object).
The example shows how to compile a schema into an Avro-specific Java data class which can then be used in a Java application to create Java objects, and then serialize them (in this case, into a file). Here’s the command line to do it (assuming the above Schema is in a file called plato.avsc):
|
1 |
java -jar avro-tools-1.11.1.jar compile schema plato.avsc . |
The Java Avro data class file is written to example/avro/PlatonicSolid.java with this initial comment/warning:
|
1 2 3 4 5 |
/** * Autogenerated by Avro * * DO NOT EDIT DIRECTLY */ |
Upon inspection, it is considerably more complex than the original Schema as it contains numerous helper methods and other Avro specific methods, and is 563 lines of code for this example.
4. A Platonic Avro Example: Serialization
 (Source: Shutterstock)
(Source: Shutterstock)
Now let’s create a 2x2x2 cube and serialize it. The sending Java application (PlatonicSolids.java) uses the generated Java Avro data class (PlatonicSolid.java), and DatumWriter, DataFileWriter Avro classes to write a serialized file (solids.avro) as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
package example.avro; import java.io.File; import java.io.IOException; import org.apache.avro.file.DataFileWriter; import org.apache.avro.io.DatumWriter; import org.apache.avro.specific.SpecificDatumWriter; public class PlatonicSoilds { public PlatonicSolids() { } public static void main(String[] args) { // this will be the name of the serialized data file String fileName = "solids.avro"; // create a cube, with a volume of 8.0 (and therefore with edges of length 2) PlatonicSolid cube = new PlatonicSolid(“cube”, 6, 8, (float) 8.0); DatumWriter<PlatonicSolid> solidDatumWriter = new SpecificDatumWriter<PlatonicSolid>(PlatonicSolid.class); DataFileWriter<PlatonicSolid> dataFileWriter = new DataFileWriter<PlatonicSoild>(soildDatumWriter); try { dataFileWriter.create(cube.getSchema(), new File(fileName)); dataFileWriter.append(cube); dataFileWriter.close(); System.out.println("Created file " + fileName); } catch (IOException e) { e.printStackTrace(); } } } |
The serialized data file (solids.avro) contains a JSON encoded schema and the binary data, so you can’t read it without some assistance.
5. A Platonic Avro Example: Deserialization
To deserialize the serialized data, the receiving Avro Java application (ReadPlatonicSolids.java, which uses DatumReader and DataFileReader classes) also needs to have the Java Avro data class (PlatonicSolid.java) to unmarshall the data into. It then reads the data, using the schema included in the data (to determine the order of fields) and the target data class (for type and name information). Here’s the example code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
package example.avro; import java.io.File; import java.io.IOException; import org.apache.avro.file.DataFileReader; import org.apache.avro.io.DatumReader; import org.apache.avro.specific.SpecificDatumReader; public class ReadPlatonicSolids { public ReadPlatonicSolids() { } public static void main(String[] args) throws IOException { // name of the serialized data file String fileName = "solids.avro"; DatumReader<PlatonicSoild> solidDatumReader = new SpecificDatumReader<PlatonicSolid>(PlatonicSolid.class); DataFileReader<PlatonicSolid> dataFileReader; dataFileReader = new DataFileReader<PlatonicSolid>(new File(fileName), solidDatumReader); PlatonicSolid solid = null; while (dataFileReader.hasNext()) { solid = dataFileReader.next(solid); System.out.println(solid); } } } |
It produces the following output:
|
1 |
{"figure": "cube", "faces": 6, "vertices": 8, "volume": 8.0} |
So, we’ve successfully recreated our “physical” cube from the Form of the Platonic Solids (Schema), and the specifics of this particular cube. Although, as we didn’t specify physical attributes such as color or orientation in the Schema, the appearance of the reconstituted object could be a surprise!
 (Source: Shutterstock)
(Source: Shutterstock)
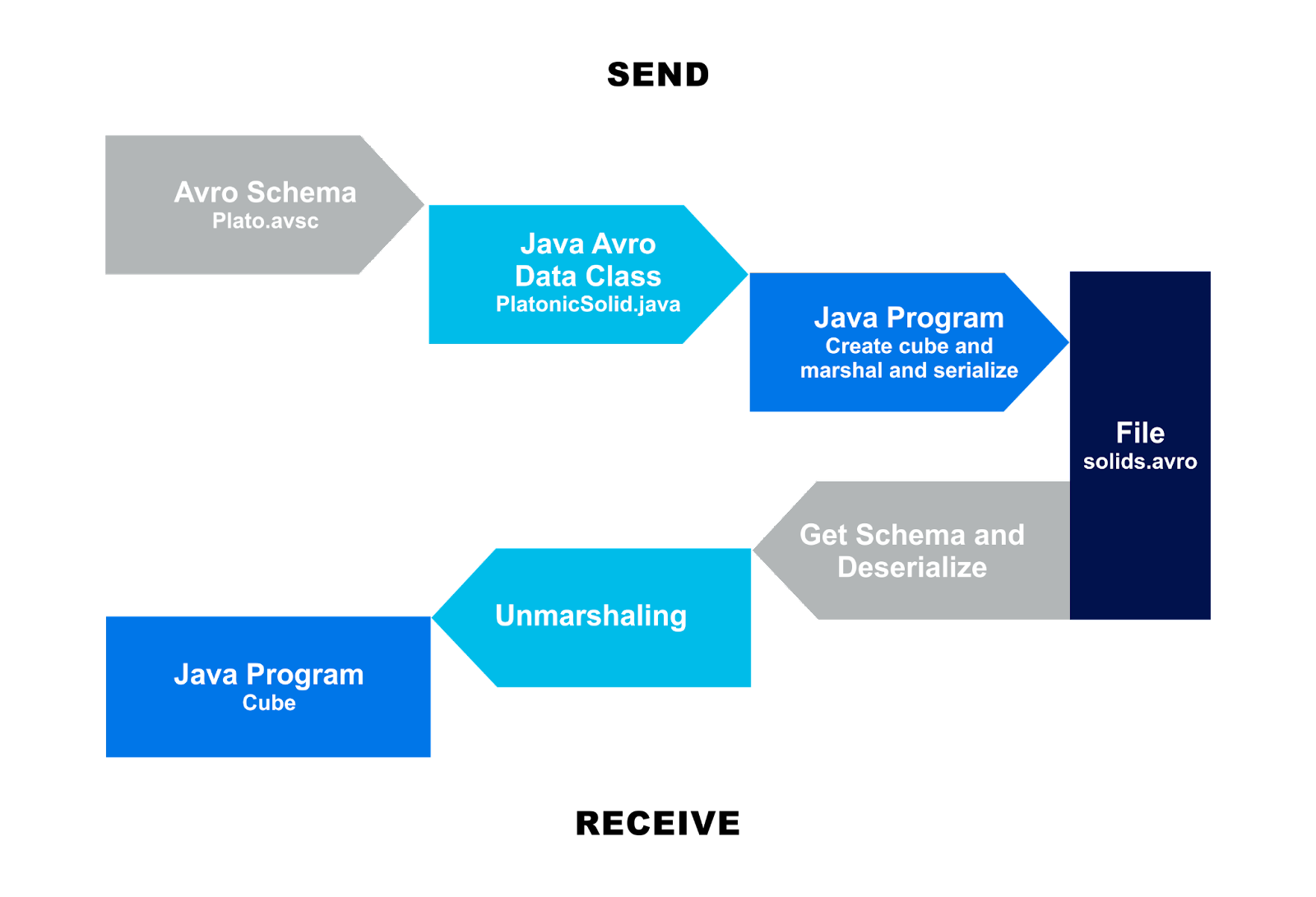
To summarize, here is a diagram of Serialization and Deserialization paths that we have explored so far.
The Send steps are:
- Starting with the Avro Schema (in JSON, plato.avsc)
- Generating the Java Avro data class (PlatonicSolid.java)
- The Java sending program creates a “cube” instance of this data class, and marshals and serializes it into a file (solids.avro).
The Receive steps are:
- The Java receiving program reads the file (solids.avro)
- extracts the schema from it, and
- deserializes and unmarshals it into
- an instance of the platonic data class, a cube.
In Part 2 of the series, we’ll have a look at Avro IDL, revisit our NOAA Tidal data pipeline example with Avro, and more!
Follow the Karapace Series
- Part 1—Apache Avro Introduction with Platonic Solids
- Part 2—Apache Avro IDL, NOAA Tidal Example, POJOs, and Logical Types
- Part 3—Introduction, Kafka Avro Java Producer and Consumer Example
- Part 4—Auto Register Schemas
- Part 5 —Schema Evolution and Backward Compatibility
- Part 6 —Forward, Transitive, and Full Schema Compatibility

Master Apache Kafka with expert insights
Struggling to strike the perfect balance between performance, scalability, and reliability in your Kafka ecosystem? Whether you're optimizing for zero downtime or maximizing resource efficiency, this guide has you covered.