Kafka 4.0 was recently released (March 2025) with many new features and improvements (see the release notes for more details), closely followed by general availability on the NetApp Instaclustr Managed Platform. So, what features are both new and released in general availability in 4.0? This blog focuses on KIP-848, the next generation consumer rebalance protocol—which is a bit of a mouthful—how about NGCRP for short? Maybe not… ChatGPT suggested “Kafka Turbo Rebalance” which is cool!
The next generation consumer rebalance protocol (actually called “consumer” for short in the documentation—even though it’s now managed on the server side) first appeared in Kafka 3.7.0 as an early release (release notes and instructions here). Previously, KIP-429 (the Kafka consumer incremental rebalance protocol) was the best rebalancing protocol available, having appeared in Kafka 2.4.0, replacing the original “stop-the-world” rebalancing protocol.
So, what’s the big deal?
The primary mechanism that Kafka uses to achieve high scalability is topic partitions. Each topic is split into 1 or more partitions to enable high concurrency on both the cluster and consumer sides. To achieve consumer concurrency, consumers run in a cooperative group called a consumer group. The number of consumers in a group is limited only by the number of partitions.
Each consumer is single-threaded, and can be allocated 1 or more partitions, but partitions can only be allocated to a single consumer, and every consumer should have at least 1 partition. For maximum concurrency and throughput, the best case is exactly one consumer per partition. Here’s a summary of the rules:
- >= 1 partitions per topic
- consumers <= partitions
- >= 1 partition per consumer (else the consumer will time out and be removed from the group)
- Exact 1:1 mapping between partitions and consumers (i.e. every partition has a consumer, but sharing of the same partition between consumers)
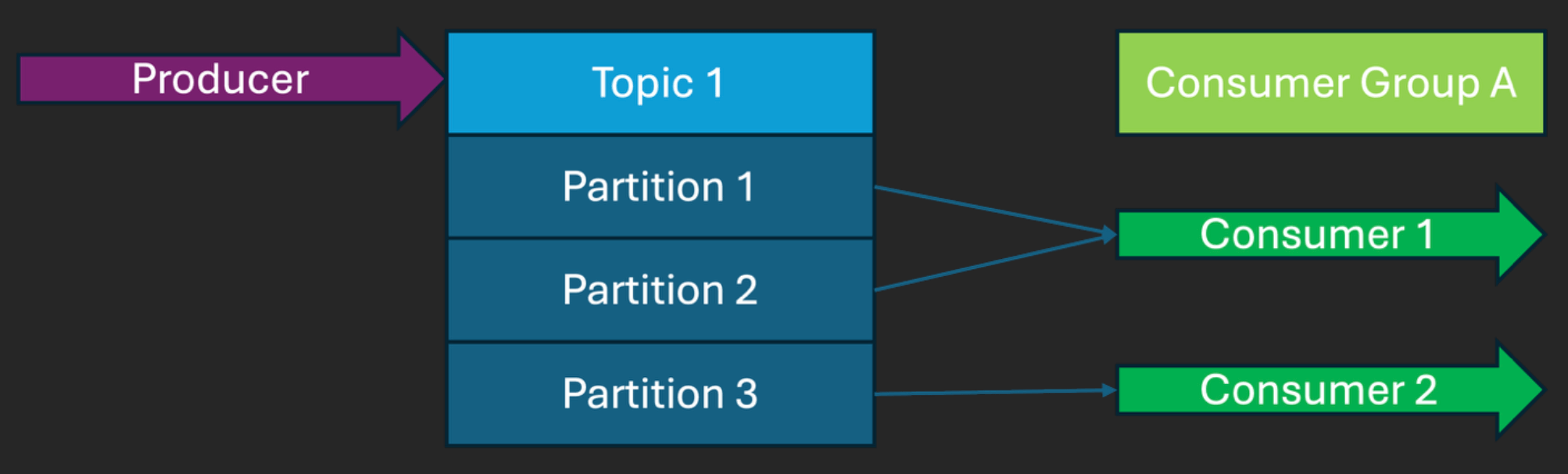
The following diagram shows a correctly balanced consumer group – each partition has exactly 1 consumer, and the partitions are as evenly distributed as possible (given the odd number of partitions,3, and even number of consumers, 2) across the available consumers:
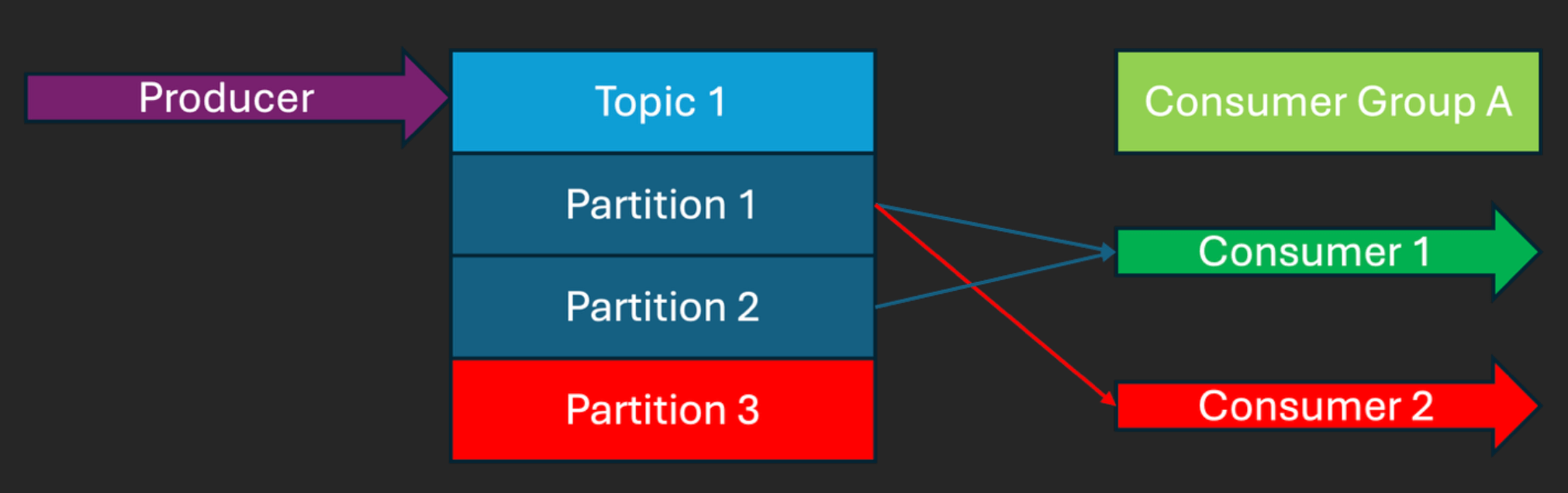
However, the following example breaks the rules (Partition 1 is mapped to 2 consumers, so in practice Consumer 2 has no partitions, and Partition 3 is mapped to no consumers):
However, there is a problem. To ensure that the mappings between partitions and consumers follow the rules and goals (every partition has exactly one consumer, every consumer has at least one partition, and partitions are evenly balanced across all the available consumers) there needs to be a mechanism to do the mapping initially and ensure that the mapping is still correct even after changes to the number of partitions, consumers timing out or failing, consumers being created and destroyed, etc. This is called consumer rebalancing.
Rebalancing must be performed under all these circumstances and can take significant amounts of time when there are many partitions, many consumers, or rapid changes in partitions or consumers.
For example, in the past, I’ve encountered multiple rebalancing issues and challenges. Problematic rebalancing is often detected by a reduction in throughput and an increase in consumer latency and lag during a rebalancing operation for a consumer group.
Watch out for the Kafka key “parking” problem, rebalancing storms, slow consumers, millions of partitions and ephemeral consumers!
From past experience scaling Kafka applications, there are many things to watch out for that can exacerbate Kafka consumer rebalancing including:
- Knuth’s “car parking” (hash collision) problem
- Ensure you have many more keys than partitions to prevent consumer starvation and timeouts
- Rebalancing storms
- Don’t ramp up the number of consumers in a group too quickly
- Slow consumers
- Try to minimize the time to process records for consumers
- A large number of partitions increases rebalancing time
- e.g. it’s possible to have way more partitions with KRaft c.f. ZooKeeper
- Ephemeral consumers
For more information, see my Apache Kafka Anti Patterns blog.
Incremental rebalancing protocol improvements
The original rebalancing algorithm was a “stop the world” (or eager) approach—once a change requiring a rebalance was detected in a group, the consumers were all stopped, partitions were recomputed and reassigned, and finally the consumers were restarted, and this was all controlled by the consumer group leader. There were lots of steps and communication between consumers, and consumers could not process records during the rebalancing. During the rebalancing, throughput for the group was therefore reduced to zero, and latency increased significantly during the pause in processing.
KIP-429 (Kafka Consumer Incremental Rebalance Protocol) appeared in Kafka 2.4.0 and was a significant improvement. The main advantage of this new protocol was that it was incremental, not “stop the world” like the original. It prevented unnecessary partition reassignments by using an innovative partition assignment strategy, the cooperative “sticky” assignor, which tries to preserve the previous partition assignments where possible. i.e. only the change between the old and new partitions assignments needs to be revoked/migrated. And because it’s incremental, consumers can still keep processing records for unaffected partitions, so there’s less impact on throughput and latency.
Note that the sticky assignor is not directly related to the other Kafka “sticky” thing, the sticky partitioner, or more completely, the strictly uniform sticky partitioner KIP-794, which distributes non-keyed batches of produced messages evenly in batches among brokers (thereby reducing producer latency).
Also note that these two original rebalancing approaches (Classic Eager – which required consumers to revoke all owned partitions for each rebalancing; and Classic Cooperative, allowing a consumer to retain its partitions before rebalancing – are really just the same protocol but with a different partition assignor for the Cooperative version (The CooperativeStickyAssignor). The role of the ConsumerPartitionAssignor interface is to map partition assignments for Consumers, and all implementations available (in 4.0) are CooperativeStickyAssignor, RangeAssignor, RoundRobinAssignor and StickyAssignor. The ConsumerPartitionAssignor interface will be deprecated in future Kafka versions.
The next generation Consumer Rebalance Protocol
KIP-848 (The next generation consumer rebalance protocol) takes a different approach to rebalancing consumer groups. The broker-side group coordinator now manages the rebalance process, which simplifies the client-side implementation. And now the rebalancing process is completely asynchronous with no blocking, meaning that most consumers in a group will be able to continually process records without impact during a rebalance.
There are two new (server side) assignors:
- Range
org.apache.kafka.coordinator.group.assignor.RangeAssignor- An assignor which co-partitions topics.
- Uniform
org.apache.kafka.coordinator.group.assignor.UniformAssignor- An assignor which uniformly assigns partitions amongst the members. This is somewhat similar to the existing “sticky” assignor (and is the default for the consumer rebalancing protocol).
Note that they are both sticky, and the goal is to minimize partition movements. These are set with the new server-side group.consumer.assignors configuration (uniform or range, the default is uniform). The previous configuration for setting partition assignment strategies (partition.assignment.strategy) is now deprecated.
20 times faster!
From watching several talks on KIP-848, including one at Current London 2025, it was apparent that the Kafka developers behind the new protocol had goals of ensuring that there were no performance regressions, that the broker CPU wasn’t significantly higher, that the new protocol was more stable, and that for some scenarios, the performance was better (e.g. see this video). This was confirmed, with both Classic Cooperative and the new protocol being more stable than the Classic Eager, and the new protocol having a more consistent throughput than either. The Cooperative protocol performs well but requires all consumers to be responsive. If there are any slow/unresponsive consumers, the new protocol performs better, with minimal impact on latencies.
For our NetApp Instaclustr Managed Kafka service, we always perform benchmarking to detect any potential performance regressions with each new Kafka release, and Kafka 4.0 was no exception. In fact, we developed some new tests specifically to test for performance regressions for the new rebalancing protocol. We found that for the scenarios where consumers are removed or added to a group, the new protocol has better latencies than the previous version. This was to be expected, given the improved completely incremental approach.
But I wondered if the new protocol could do even better in more extreme situations?
For this experiment, I created a topic with 100 partitions, and a consumer group with 10 consumers subscribed to this topic. I then increased the number of partitions for the topic to 1000 (x10) and ran the kafka-consumer-group.sh command every second to detect how long the rebalancing takes. The results were surprising!
Rebalancing with the classic protocol took 103 seconds, but rebalancing with the new protocol only takes 5 seconds – that’s 20x faster. I wasn’t expecting such a big performance improvement, particularly given that both protocols are incremental, so this is very encouraging.
Here’s the bash script I used if you would like to repeat the experiment. For the new protocol replace --consumer-property group.protocol=classic with --consumer-property group.protocol=consumer (Note: double check that you are using --consumer-property as --property is not correct and will silently be ignored – I wasted several hours trying to work out why there was no difference in performance between the two protocols – the reason being that the default was being used for both experiments!)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
./kafka-topics.sh --bootstrap-server IP:9092 --topic test100 --create --partitions 100 for c in 1 2 3 4 5 6 7 8 9 10 do echo "consumer: $c" ./kafka-console-consumer.sh --bootstrap-server IP:9092 --topic test100 --group 101 --consumer-property group.protocol=classic >/dev/null& done sleep 10 date echo "starting producer" ./kafka-producer-perf-test.sh --producer-props bootstrap.servers=IP:9092 --topic test100 --record-size 10 --throughput 1000 --num-records 2000000& sleep 10 echo "increasing to 1000 partitions" ./kafka-topics.sh --bootstrap-server IP:9092 --topic test100 --alter --partitions 1000 counter=0 while true do echo "counter is: $counter" date ./kafka-consumer-groups.sh --bootstrap-server IP:9092 --describe --group 101 ((counter++)) sleep 1 done |
For the classic protocol, this script worked perfectly with no errors. However, for the new consumer protocol, there were some errors:
|
1 2 3 4 |
ERROR [Consumer clientId=6, groupId=101] OffsetCommit failed for member T1G-Y9lyQQKWFovmGIYHtw with stale member epoch error. (org.apache.kafka.clients.consumer.internals.CommitRequestManager) … Failed org.apache.kafka.common.errors.StaleMemberEpochException: The member epoch is stale. The member must retry after receiving its updated member epoch via the ConsumerGroupHeartbeat API. |
Note that STALE_MEMBER_EPOCH is a new error for this protocol:
FENCED_MEMBER_EPOCH– The member epoch is fenced by the coordinator. The member must abandon all its partitions and rejoins.STALE_MEMBER_EPOCH– The member epoch is stale. The member must retry after receiving its updated member epoch via theConsumerGroupHeartbeatAPI.UNRELEASED_INSTANCE_ID– The instance ID is still used by another member. The member must leave first.UNSUPPORTED_ASSIGNOR– The assignor used by the member or its version range are not supported by the group.INVALID_REGULAR_EXPRESSION– The regular expression used by the member is not a valid RE2J regular expression.
And I found out the hard way (by trying to use them) that some previous consumer configurations are now deprecated:
partition.assignment.strategysession.timeout.msheartbeat.interval.ms
The heartbeat and timeouts are now set on the server side with these configurations:
- The member uses the
ConsumerGroupHeartbeatAPI to establish a session with the group coordinator. - The member is expected to heartbeat every
group.consumer.heartbeat.interval.msin order to keep its session open (default is now 5 seconds, increased from 3 seconds in Kafka 3.X). - If it does not heartbeat at least once within the
group.consumer.session.timeout.ms, the group coordinator will kick the member out from the group. group.consumer.heartbeat.interval.msis defined on the server side and the member is told about it in the heartbeat response.- The
group.consumer.session.timeout.msis also defined on the server side (default is 45 seconds, the same assession.timeout.msin Kafka 3.X).
Other things to be aware of:
- There are no Consumer API changes, you use the same KafkaConsumer
- But you do need to update Kafka client libraries to 4.0+
- And handle any new errors and property changes (see below)
- There is no support for Kafka Connect (and therefore MM2), or Kafka Streams yet.
- The new protocol will provide good support for KIP-932 (Kafka queues).
The new protocol is available by default, but consumers need to opt-in and make the following changes:
- You need to add
group.protocol=consumerto consumer properties - Remove unsupported consumer properties such as
session.timeout.ms(default still 45s) andheartbeat.interval.ms(note change in detault time from 3s to 5s). - Handle any new error types
- Optionally, set assignor with the consumer property
group.remote.assignor - If you are using a NetApp Instaclustr managed Kafka service, you can request changes to server-side configurations.
Finally, here’s some example Java code for a Kafka 4.0 Consumer using the new protocol!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
import org.apache.kafka.clients.consumer.KafkaConsumer; import java.time.Duration; import java.util.List; import java.util.Properties; public class Test4 { public static void main(String[] args) { Properties props = new Properties(); props.put("bootstrap.servers", "IP:9092"); props.put("group.id", "test-group"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // new 4.0 rebalance protocol properties props.put("group.protocol", "consumer"); props.put("group.remote.assignor", "uniform"); // Create the Kafka consumer KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); // Subscribe to topics consumer.subscribe(List.of("t1")); // Poll for records while (true) { var records = consumer.poll(Duration.ofMillis(100)); for (var record : records) { System.out.printf("Consumed record with key %s and value %s%n", record.key(), record.value()); } } } } |
You also need this entry in your pom.xml file:
|
1 2 3 4 5 |
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>4.0.0</version> </dependency> |
Discover Kafka 4.0’s next-gen Consumer Rebalance Protocol on the Intaclustr Managed Platform and elevate your scaling efficiency today! Start your free trial today – no credit card required.