Apache Cassandra® and PostgreSQL® are both open source databases built to handle incredible amounts of data, backed with robust communities of developers and contributors. Despite the seemingly numerous similarities between the 2 technologies, they offer different solutions for different problems that are important to consider when determining which software may be the better choice for your operations.
In this overview, discover the key differences between these powerful open source databases, their strengths that make them unique, when you would want to use them, the challenges they can pose, and which technology may be the best option for your use case.
What is Apache Cassandra®?
Apache Cassandra is an open source non-relational (or NoSQL) database that enables continuous availability, tremendous scale, and data distribution across multiple data centers and cloud availability zones. It is the database of choice for scalable, highly available, globally-distributed, always-on applications.
As a non-relational database, Cassandra stores data as rows and columns in tables. Each row is a collection of columns where a column is a mapping of a key, a value, and metadata such as creation time. Relationships between tables are not supported. Cassandra is written in Java and runs within a Java virtual machine (JVM), and it is not ACID compliant.
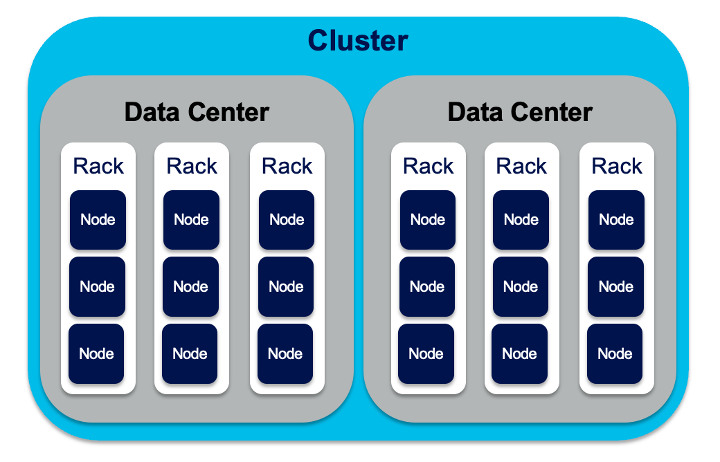
In Cassandra, all nodes play an identical role—there is no concept of a master node, with all nodes communicating with each other via a distributed, scalable protocol. Writes are distributed among nodes using a hash function and reads are channeled onto specific nodes.
Although dependent on the data model, in practice, Cassandra stores data by dividing the data around its cluster of nodes. Each node is responsible for part of the data. The act of distributing data across nodes is referred to as data partitioning.
What is PostgreSQL®?
PostgreSQL is the world’s leading object-relational database management system. It has a multi-user and highly concurrent design, allows users to store and scale complex data workloads, and is best known for its wide-ranging extensibility, reliability, and SQL (relational) and JSON (non-relational) querying. As a free and open source relational database, PostgreSQL is renowned for being highly customizable and is often used to store data for many different types of applications including mobile, web, analytic, and geospatial.
It is hardware agnostic and has the unique ability to support many different programming languages, including Python, Java, C/C++, and Ruby, among many others, offering unparalleled flexibility for your internal functions. PostgreSQL is also ACID compliant and offers full support for stored procedures, joins, foreign keys, views, and triggers in numerous languages.
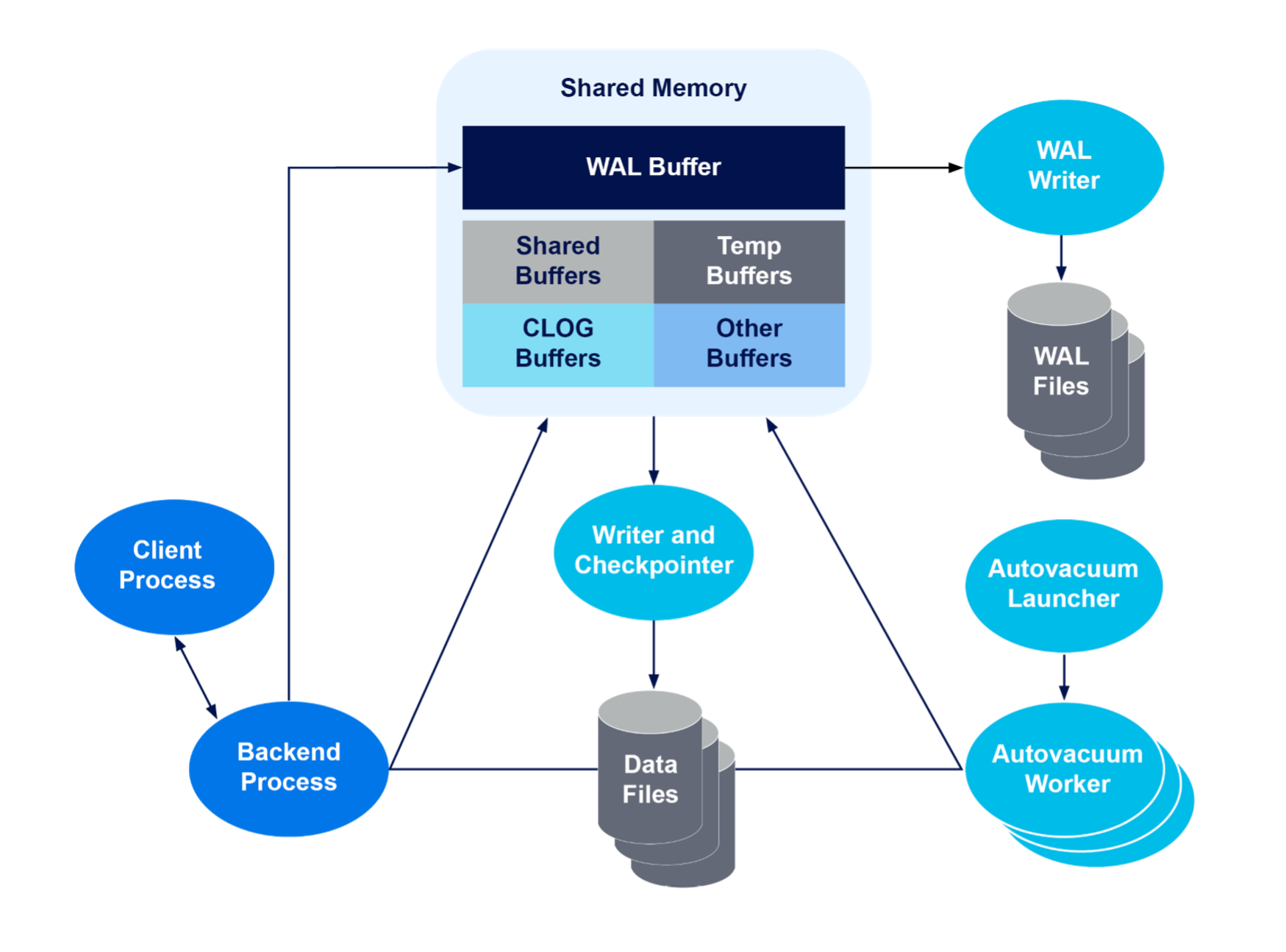
A PostgreSQL server process is a parent of all processes related to database cluster management. Each backend process handles all queries and statements issued by a connected client. Various background processes perform each feature (like vacuum and checkpoint processes) needed for database management. The replications process work with the streaming replication, while a background worker process (from version 9.3 onwards) can perform any processing implemented by users.
Difference Between Cassandra and PostgreSQL
On a surface level, it’s easy—and accurate—to say that Cassandra and PostgreSQL are both “databases,” but that doesn’t tell the complete story of either technology.
Instead, think of Cassandra more like a “data store” that is unrivaled at scaling and storing incredible amounts of data (and getting that data out again), but it is not exactly designed for querying. PostgreSQL, by comparison, is designed specifically to handle complex querying and workloads due to it being inherently customizable and extendable.
What Are Their Key Strengths?
Cassandra |
PostgreSQL |
| Flexible consistency requirements | High ACID requirements |
| Extremely high availability (100%) | High availability (99.9%) |
| Extreme horizontal scaling | Horizontal scaling achieved through additional tools |
| Distribution of replicas/masters | Single master |
| Filtering and joining application side | Filtering and data server side |
| Specific data modeling | Flexible data modeling |
|
Numerous plug-ins/tooling |
Although high availability is a key strength for both Cassandra and PostgreSQL, it is important to do a deeper dive and understand the nuances that distinguish between the 2 technologies.
With Cassandra, you really do get 100% absolute availability—due to its architecture, there is no maintenance downtime that will affect its overall availability. For PostgreSQL, however, that 99.9% availability applies only to availability after planned downtime, which is usually around once per month or once every couple of months. When planned downtimes are factored in, there can become significant differences in overall availability between Cassandra and PostgreSQL—a key factor you should consider when adopting either of these technologies into your data stack.
When Should You Use Cassandra?
Cassandra is a built-for-scale architecture, meaning that it is capable of handling large amounts of data and millions of concurrent users or operations per second—even across multiple data centers—as easily as it can manage much smaller amounts of data and user traffic. To add more capacity, you simply add new nodes to an existing cluster without having to take it down first. Cassandra allows for scalability but knowing whether to scale up or out and understanding the operating procedures behind that is a common pain point for many Cassandra users. Instaclustr has added SaaS tooling capabilities around Cassandra to dynamically re-size your cluster in tune with variable workloads (Black Friday, off-peak hours, etc.). Unlike other systems, Cassandra has no single point of failure, and with additional operations being undertaken by Instaclustr, Cassandra is truly capable of offering continuous availability and uptime.
With its unique features and capabilities, Cassandra has proven to be a great general purpose database. It is an ideal technology for many different use cases, including:
- Replicating data across different environments or datacenters, creating low latency worldwide
- Storing time-series data
- Requirements for high uptime or high availability
- High write volumes commonly found in applications that must work with data from multiple devices
- Transaction logging, such as purchases made, movies, and TV shows watched on streaming apps, and more
- Tracking, like order status for goods purchased and shipped
- Weather service history
- Online gaming, especially for real-time messaging
- Social media data input and analysis
- Telematics, including IoT for cars and trucks
- Storing and retrieving healthcare data
- Messaging apps for mobile and telecom providers
- Media streaming management
Applications where Cassandra excels have a common set of characteristics: writes exceed reads by a large margin, data can be partitioned to spread the database evenly across multiple nodes, and there is no need for joins, data aggregates, or frequently updated data.
Challenges of Using Cassandra
With its unparalleled ability to handle enormous quantities of structured data spread across numerous commodity servers–all while providing highly available service with no single point of failure–there is a good reason why so many organizations choose Apache Cassandra. However, that does not mean that implementing Cassandra is a walk in the park, either.
The greatest challenge that many developers face is adapting to the profound shift of relational (SQL) database model thinking to suddenly working with non-relational (NoSQL) modeling; essentially, developers will have to un-learn their years of SQL experience in order to best adapt to NoSQL (although Cassandra’s SQL-like CQL makes this easier than some other NoSQL technologies). Apache Cassandra is architected differently from SQL databases as it addresses a different set of challenges, so applying relational modeling skills to non-relational Cassandra simply will not work.
Other mistakes that have proven challenging for developers when using Apache Cassandra:
- Modeling data around relations or objects: To reap the full power of Cassandra, data modeling must be done around the queries that will be executed, rather than around the data relations.
- Tuning before understanding: It’s common for SQL developers new to Cassandra to want to jump right in and change the default settings before they fully understand what they’re actually dealing with, but this will often result in slow cluster. Adjusting and tuning Cassandra first requires a solid understanding of many different factors including the data model, usage pattern, previous trends and how setting impacts the cluster.
- Leaving Cassandra unattended: Just because Cassandra is practically impenetrable when it comes to outages and network partitions does not mean that developers can leave their clusters unattended. Changes do occur, like a sudden surge in write operations or the type of data inserted, and these changes can negatively impact performance if neglected.
- Minimizing writes at the expense of more reads: Although writes are not free, they are extremely cheap with Cassandra. Creating a data model that minimizes writes in order to save money is entirely unnecessary, but developers too often do so.
When Should You Use PostgreSQL?
Being so extendible and customizable, it’s easier to ask what applications don’t work well with PostgreSQL—in that case, massive parallel or NoSQL data loads comes to mind, as well as seismic data processing due to issues with scaling.
But for so many other use cases, PostgreSQL is a truly great option to build and scale applications. These include:
- Enterprise Data Warehousing (DW or EDW) for a large system designed to take data from many sources and use it to make business decisions across the entire enterprise
- Operational Data Storage (ODS) for data across the organization to make fast operational decisions across teams in a live environment
- Web and JSON (non-relational) querying
- Online Transaction Processing (OTP) operational systems perform a specific business function and uses data in row form and is usually application specific
- Extract, Transform, Load (ETL or ELT) systems store data from many sources that could have conflicting data types and storage models. In order to make the data rational, some level of transformation may occur
- Geographic Information Systems (GIS)
- IoT and equipment/asset tracking
- Online Analytical Processing (OLAP) for analyzing data from multiple points of view and collected from different sources like websites, apps, internal systems, and more
There is a reason why “just use PostgreSQL” has become a popular phrase among developers: with PostgreSQL, there are no programming limits to what is possible with extensions. Some of the most popular extensions that went on to become core features of PostgreSQL include:
- GiST and GiN indexes
- Bloom indexes
- JSON
- XML
On the PostgreSQL Extension Network (pgxn) website alone, there are hundreds of extensions available. Much like gem for Ruby or pip for Python, PostgreSQL uses a tool called PGXN Client that interacts with the PostgreSQL Extension Network and allows users to easily search, compile, install, and remove extensions.
PostgreSQL also has the unique ability to install an unrivalled number of programming languages for internal functions; there is absolutely no need to learn a new programming language. Instead, all organizations need to do is simply look at what languages their staff already know and choose one of those, as the odds are it will be compatible with PostgreSQL.
Challenges of Using PostgreSQL
Stripped down to a basic level, PostgreSQL is relatively easy to get up and running; all a user has to do is simply install it and learn 5 SQL commands–that’s truly it. But using PostgreSQL on a basic level–that is, with no extensions–defeats the purpose of what makes this open source database so incredible: making it infinitely customizable to solve particular use cases in an enterprise environment.
But that’s precisely where PostgreSQL can become challenging to use: its strengths can also become its key challenges.
With a truly world-wide community constantly developing new features, utilities, enhancements and concepts to choose from, it becomes more difficult to configure for optimization and keep up with a litany of never-ending options.
The same challenge applies to scaling. Vertical scaling in PostgreSQL is done through mathematical algorithm choices in the query engine and the efficient management of the memory and file systems blocks; there is no association made between these actions and a physical piece of hardware. With an extraordinary array of hardware options available, determining the best choice for scaling becomes complicated as there are practically zero guidelines for PostgreSQL.
Cassandra or PostgreSQL? Which Technology Is Best for You?
It’s important to remember that while there certainly exists a degree of overlap between Cassandra and PostgreSQL—they are fundamentally both database systems, after all—they really are not direct competitors to each other, either; Cassandra and PostgreSQL ultimately serve different use cases. In fact, it’s not uncommon to see organizations run both Cassandra and PostgreSQL as part of a single application.
So which technology will be the best option for your data stack? The answer is entirely straightforward: the database system that will solve your particular use case.
Do you need to scale vertically, perform complex querying, have high ACID or consistency requirements, or could you benefit from different plugins for your application? Then PostgreSQL will easily get the job done.
Or does your application require rapid horizontal scaling, extremely high availability, a distributed database or specific data modeling? If so, then Apache Cassandra is the clear choice.
Both databases are 100% open source and backed by a robust and active community of developers, practically guaranteeing that new and dynamic updates will continually be released. As a managed service provider with over 220 million node hours of operational experience, Instaclustr offers fully managed platforms for Apache Cassandra and PostgreSQL with the latest and most cutting-edge upgrades and add-ons, hosted on-prem or in your cloud of choice. Focus on building your applications at scale all while knowing that your critical data infrastructure is backed with a global team of experts providing 24×7 support.
Apache Cassandra and PostgreSQL offer truly incredible and unmatched abilities to solve the most demanding use cases. Both have their unique strengths and particular drawbacks, but choosing the right open source software to implement is not a matter of which database may be the technologically superior option, but instead which database has the critical features best suited to solve the challenges you face in building and scaling your application.
Discover Apache Cassandra NoSQL for the Relational Database Administrator