Kafkaesque:
\ käf-kə-ˈesk \
Marked by a senseless, disorienting, menacing, nightmarishly complexity.
One morning when I woke from troubled dreams, I decided to blog about something potentially Kafkaesque: Which Instaclustr managed open-source-as-a-service(s) can be used together (current and future)? Which combinations are actually possible? Which ones are realistically sensible? And which are nightmarishly Kafkaesque!?
In previous blogs, I’ve explored Instaclustr managed Apache Cassandra, Spark (batch), Spark Streaming, Spark MLLib, and Zeppelin.
Instaclustr also supports managed Elassandra and Kibana. Elassandra is an integrated Elasticsearch and Cassandra service that computes secondary indexes for data and supports fast queries over the indexes. Kibana is an open source data visualization plugin for Elasticsearch. Together with Logstash, they form the “Elastic Stack” (previously the ELK stack).
Apache Kafka, a distributed streaming platform (massively horizontally scalable, high-throughput low-latency, high-reliability, high-availability real-time streaming data processing), is another popular service in the same Open Source ecosystem as Cassandra, Spark and Elasticsearch. Kafka is on the Instaclustr product roadmap for 2018, and we have a tutorial on spark streaming with Kafka and Cassandra to whet your appetite.
Rather than jumping straight into a deep dive of Elassandra and/or Kafka, I’m going to take a more architectural perspective. I started by putting all the services of interest on a diagram, and then connecting them together based on documented support for each integration combination and direction (source and/or sink):
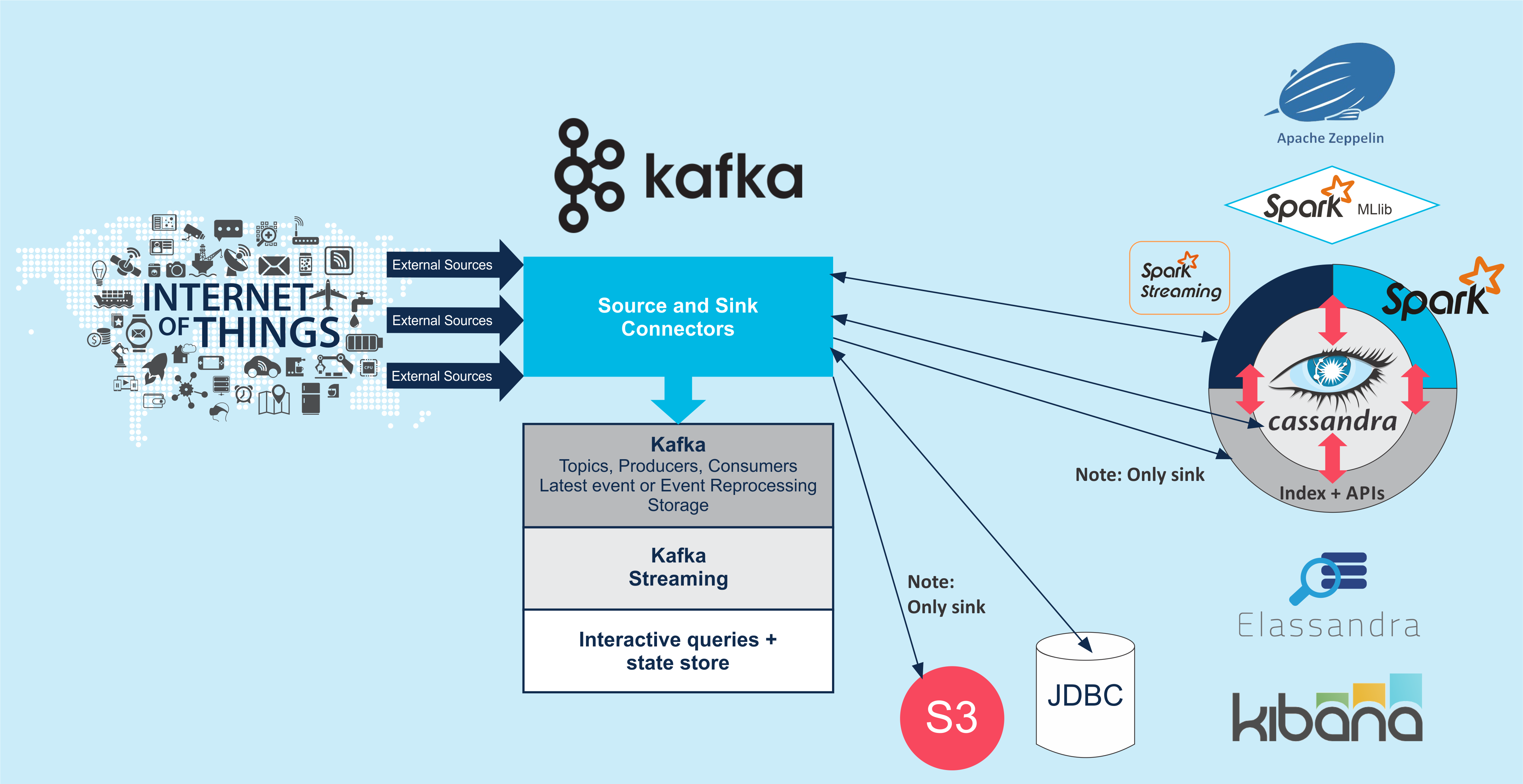
Note that Cassandra, Elassandra, Spark (batch) and Spark Streaming, Spark MLLib, Zeppelin and Kibana are tightly integrated, and support the most logically possible interactions. Instaclustr also co-locates all of these services on the same nodes by default.
I’ve spent some time examining the Kafka documentation to check what related ecosystem services it can connect to, and in what direction. Kafka supports Source and Sink Connectors which enable integration with numerous other services. Lots of different event sources are supported, enabling data to be ingested from both external and internal devices and systems. AWS S3 is supported as a Kafka sink only, and JDBC as both source and sink. Elassandra is supported as a sink only, and Spark Streaming and Cassandra as source and sink.
Also, note that implicitly most services can “talk to” themselves (i.e. read data from, process data, and write data back. This is what the card replacement rule achieves). What’s more interesting is that they can also interact with themselves on the same or different clusters, and for the same or different locations (e.g. in another AWS AZ, or in another region). The diagram shows a Service interacting with itself (same cluster), another instance of the service in the same location (different cluster), and another instance in a different cluster and location (different location):
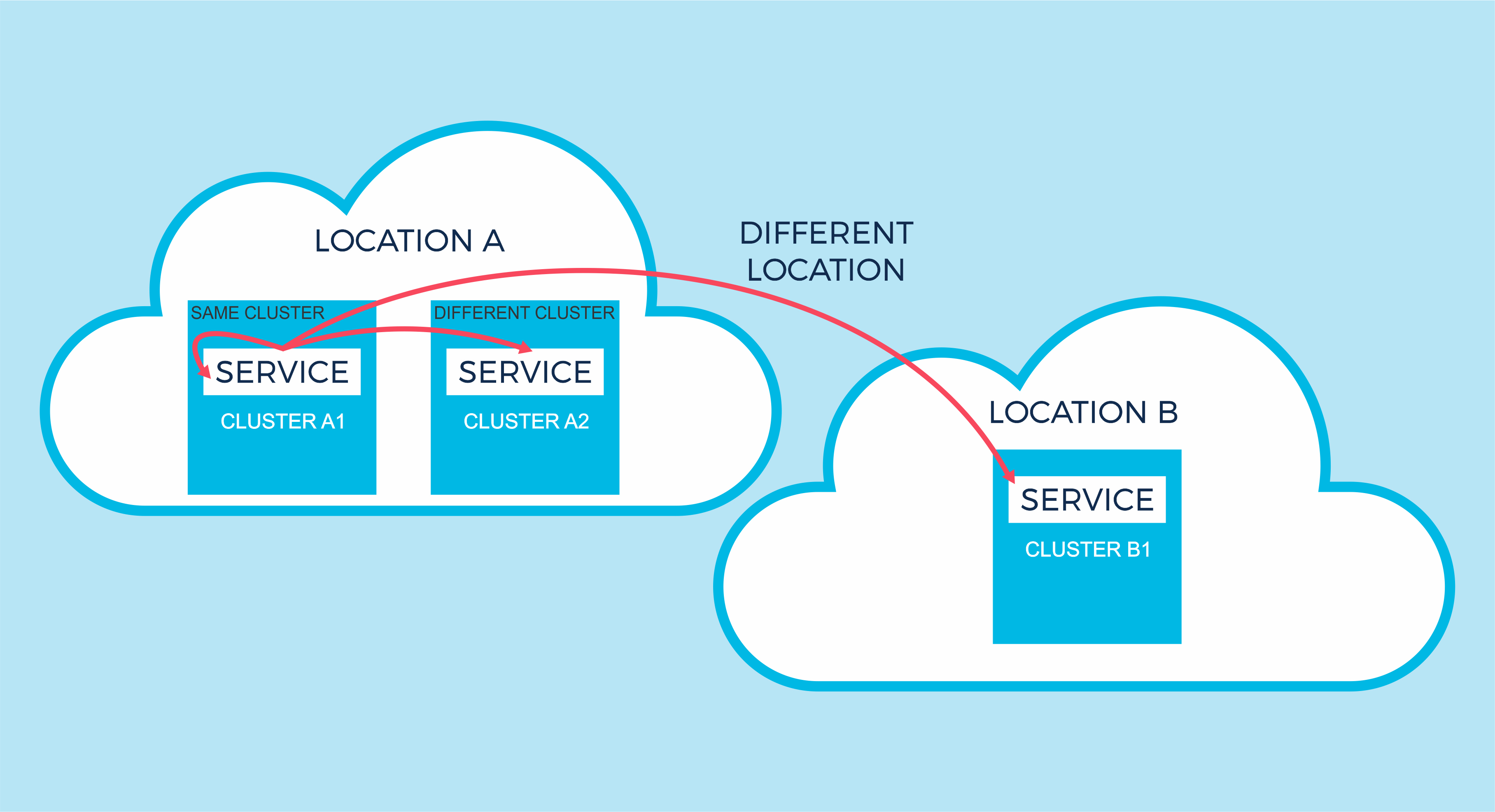
This opens up powerful internal service architectural richness and uses cases. For example Differentiation of clusters running the same service (e.g. write-intensive Cassandra cluster feeding data into a read-intensive Cassandra cluster); A Kafka cluster dedicated to ingestion only, connecting to others for processing; mirroring or replicating data from one Cassandra cluster (location) to another (e.g. using Spark to read from a Cassandra cluster in one location and write to a Cassandra cluster in another location); Peer-to-Peer Kafka clusters, where each cluster subscribes to events that are local to all other Kafka clusters and aggregates the events locally), etc.
Kafka: Some Key Features
The main Kafka APIs are Connectors, Producers, Consumers and Streams. Kafka is stream event-based, and producers publish events onto one or more topics. Topics are multi-subscriber and can have zero or more consumers that process events. Kafka maintains a (partitioned) immutable commit log of events for each topic and therefore keeps all published events for a specified retention period. This approach for message processing has a number of benefits. The more obvious benefits are speed, fault-tolerance, high concurrency and scalability. The surprising benefits are that consumers and producers can be very loosely coupled, and events can be shared! More than one consumer can consume the same event, and consumers also control which events to consume – they can consume new events and also re-consume past events.
Kafka’s performance is claimed to be constant with respect to data size, so storing events for an arbitrary length of time (as long as you have disk space!) is encouraged, by design. Because events can be processed more than once, by the same or different consumers, what do we end up with? A database for streaming events!
Let’s explore some permutations of the ecosystem of services (not all permutations will be covered in this blog), starting with Kafka. In answer to the question “What is Kafka good for?”, the Kafka documentation suggests two broad classes of application. The focus of this blog is on the first use case – getting (streaming) data between systems.
- Building real-time streaming data pipelines that reliably get data between systems or applications (this blog)
- Building real-time streaming applications that transform or react to the streams of data (next blog).
Use Case: Kafka as a Database (Teenagers bedroom. Stuff goes in, stuff rarely comes out).
 (Source: Shutterstock)
(Source: Shutterstock)
Kafka only, one or more source connectors, producer(s) publishing to the topic(s). No consumers:
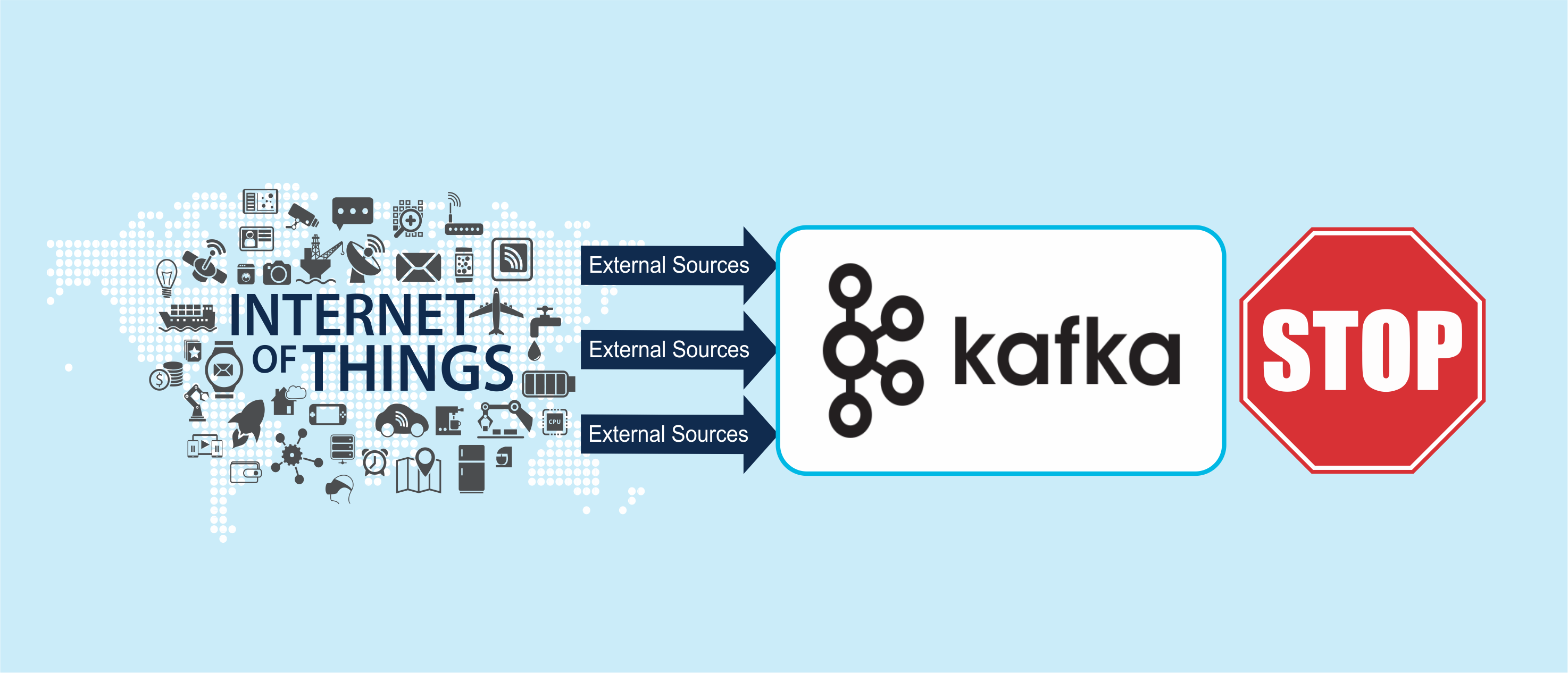
This is a trivial, and somewhat counterintuitive use case for Kafka but illustrates one of the surprising benefits of the architecture, that it is designed from the “bed” up as an event streaming database – not just for event movement. All the events arriving will be published to the topic(s), and persisted to disk. Events can subsequently be consumed multiple times by multiple consumers, who do not have to be subscribed yet. Is this interesting? Yes! It suggests lots of powerful use cases around event persistence, and reprocessing/replaying of events, and adding derived events (e.g. failure handling, support for multiple consumers and purposes for DevOps to maintain derived stateful data back in Kafka for future use, as well as for processing events from past, present and future, including predictions, in a unified manner).
Use Case: Kafka as a Temporary Buffer (Doctors Waiting Room)
 (Source: Shutterstock)
(Source: Shutterstock)
This pattern has one Kafka cluster feeding into another one:
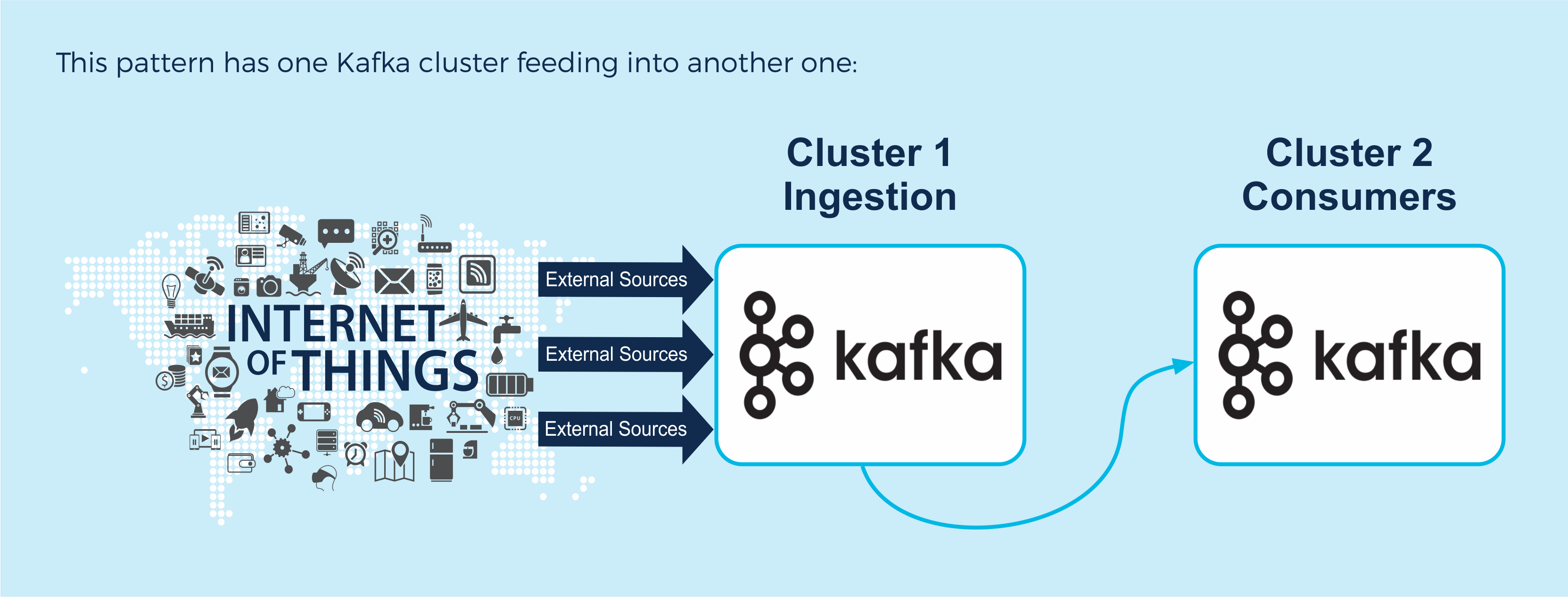
This “Buffer” (waiting room) pattern has a Kafka cluster dedicated solely to event ingestion, and another cluster for the event consumers. This leverages the ability of Kafka to store events indefinitely, and isolate event producers from consumers. The event production and consumption rates can be significantly different with no loss of events or overloading of consumers. This pattern is ideal for use cases where an incoming event storm can temporarily exceed the processing capacity of the consumers’ cluster, or if there is some other temporary failure or slowdown preventing the consumers from processing events in real-time. The Ingestion cluster buffers all the events until the consumers are ready to process them again. In the wild, this buffer pattern is used by Netflix.
Kafka can act as an event buffer, concentrator, and router in front of other services in our ecosystem as well. For example, Cassandra, Spark streaming or Elassandra can all be sinks for Kafka events.
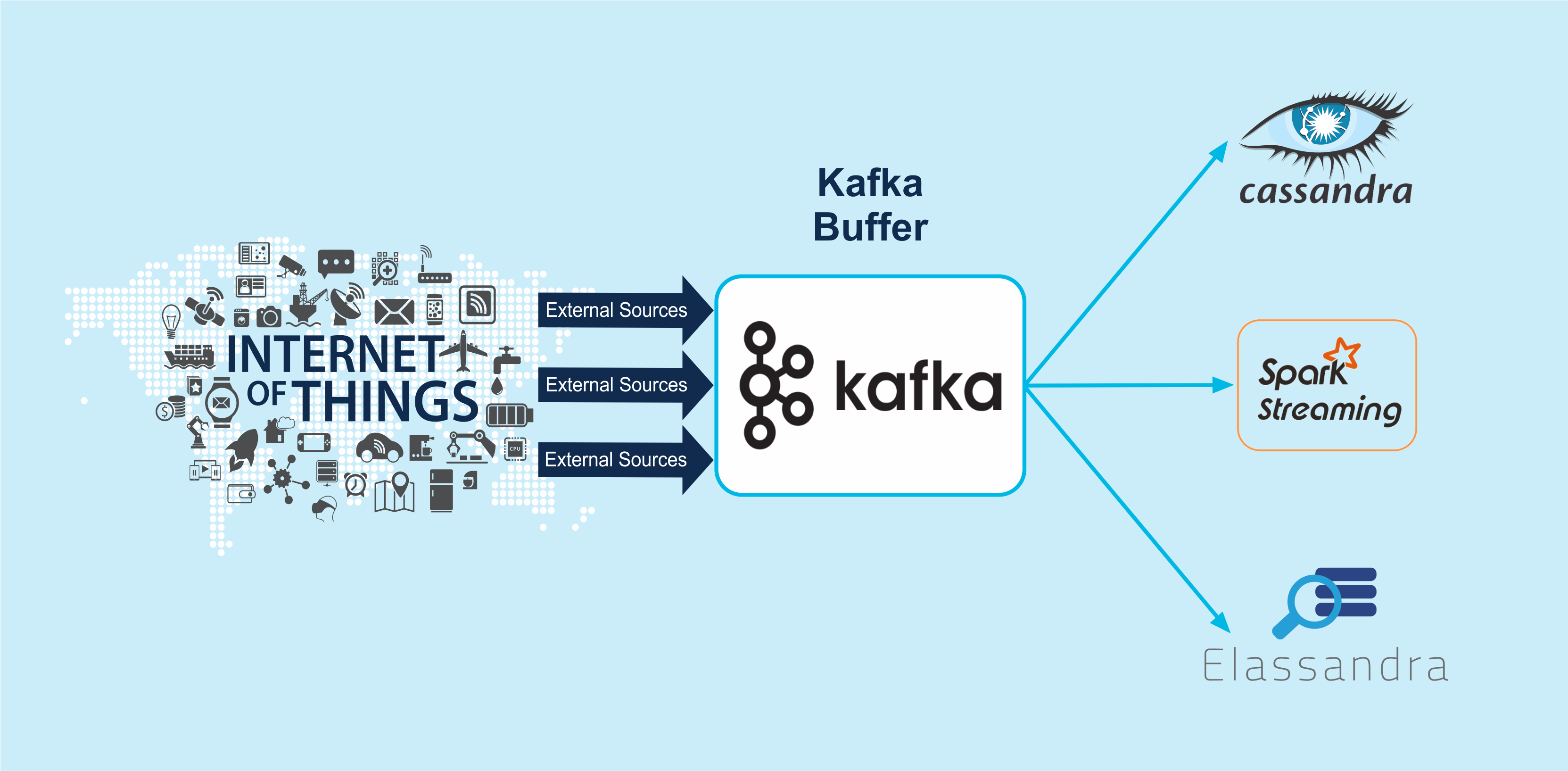
Use Case: Kafka Active-Passive Replication
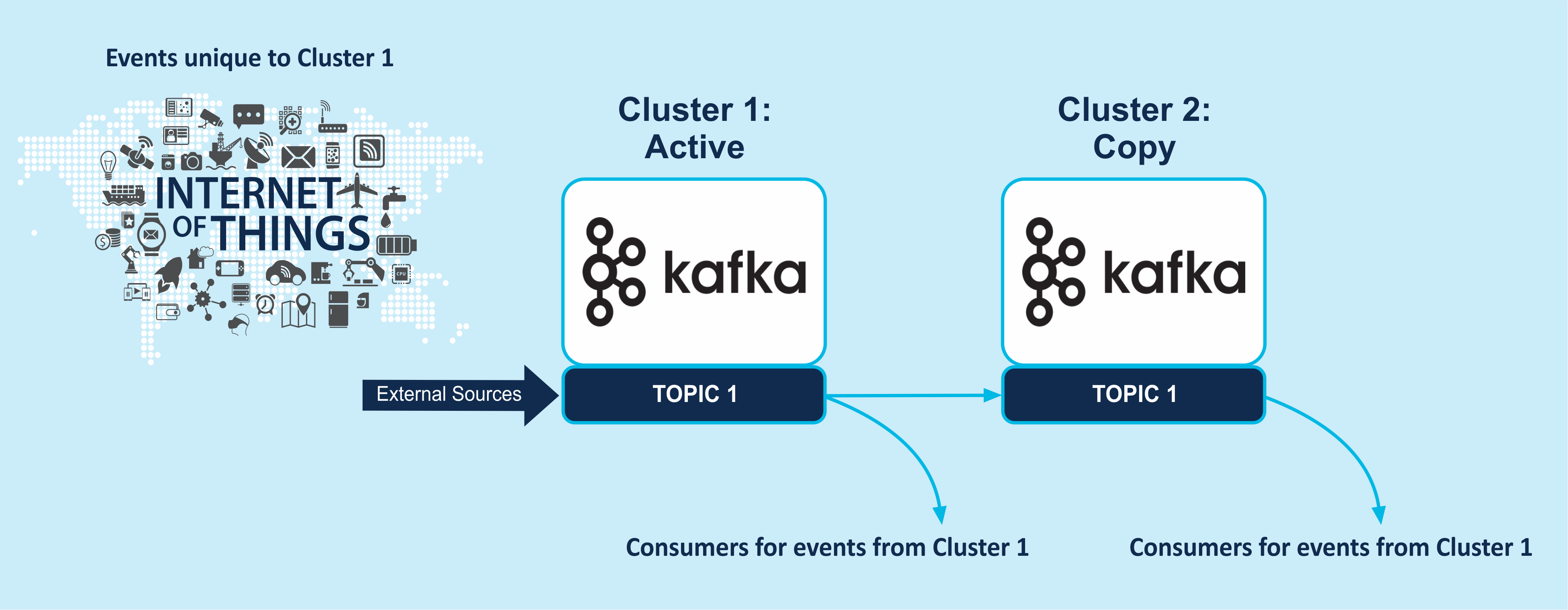
In the Use Cases so far we’ve only used Kafka as a pass-through buffer or longer term persistence mechanism. Kafka producers and consumers can publish/subscribe to/from multiple topics, enabling more complex topologies to be created. In particular, some less obvious patterns can be used to support data replication across multiple Kafka clusters and locations.
There are a couple of use cases for data replication across clusters/locations. One is for reliability/redundancy and is often called active-passive replication. Data from the source (active) cluster is copied to the passive (target) cluster. The “passive” cluster can be used in case of failure of the active cluster, or it can be used to reduce latency for consumers that are geo-located near it.
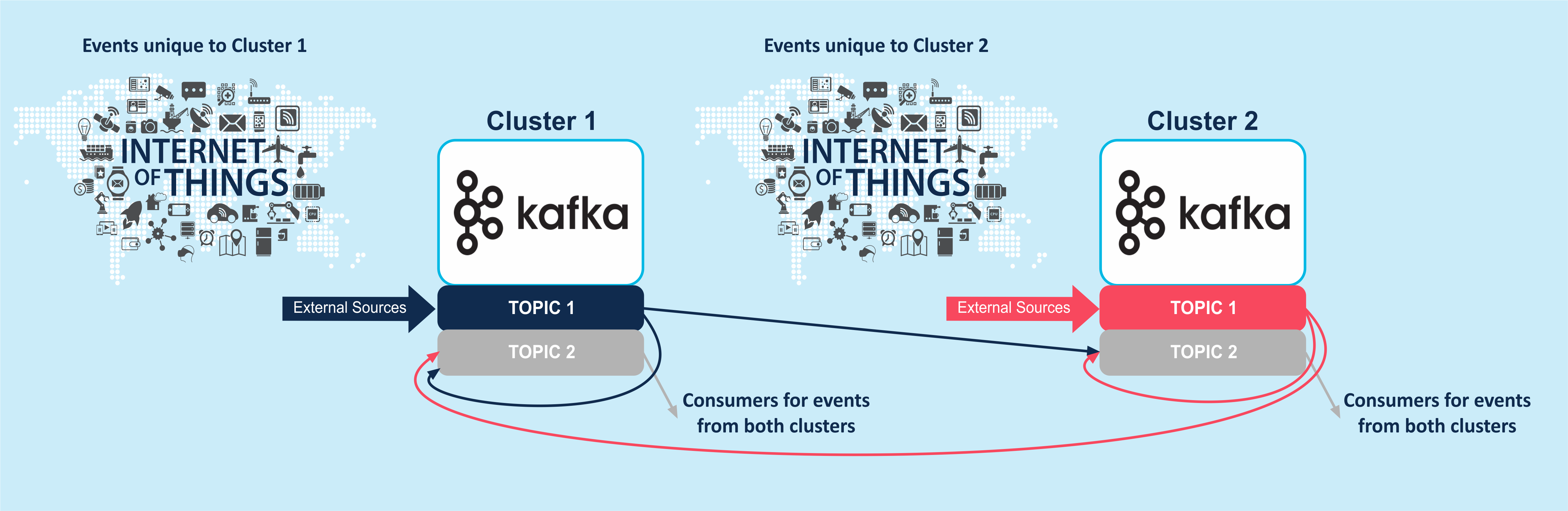
Use Case: Kafka Active-Active Replication
A more interesting use case is when unique events are collected at different locations and must be shared among all the locations. This can be between just two locations, or many (P2P). This is an active-active pattern and can be viewed as a generalisation of the active-passive pattern as each cluster acts as both a source and a target for every other cluster, and the events copied from other clusters need to be merged with the events from the local cluster in a new topic (Topic 2 in the diagram below), from which consumers can get all the events. Note that it has to be a different topic otherwise you get an event loop!
(Magic) Mirror Maker
In Japan, bronze mirrors are known as magic mirrors, or makkyo (魔鏡). One side is brightly polished, while an embossed design decorates the reverse side. Remarkably, when light is directed onto the face of the mirror and reflected to a flat surface, an image “magically” appears (usually the one featured on its back):
![]() 阿弥陀魔鏡-Magic Mirror with Image of the Buddha Amida (Source: Wikimedia)
阿弥陀魔鏡-Magic Mirror with Image of the Buddha Amida (Source: Wikimedia)
{kind=link}
For the use cases involving events being moved between Kafka clusters, how can this be achieved? One obvious mechanism is just to pretend that the clusters are “local”, and read data from the source cluster topic with a consumer and publish it to another topic on the target cluster. This approach can work with low-latency WANs (e.g. clusters on the same AWS AZ). However, there are also a number of more sophisticated solutions. A mirrormaker can be used (which also just reads data from the source cluster using a consumer and publishes it to the target cluster using a producer!). Will mirror maker actually work for the active-active use case given that mirror maker can only read/write to/from topics of the same name? Maybe, here’s a trick. More sophisticated solutions exist, including uReplicator from Uber.
- https://eng.uber.com/ureplicator/
- https://github.com/uber/uReplicator
- https://github.com/uber/uReplicator/wiki/uReplicator-Design