What Is Amazon OpenSearch Serverless?
Amazon OpenSearch® Serverless is a cloud-native service that simplifies deploying and maintaining OpenSearch clusters. It manages the infrastructure, so users focus on deploying their search applications without handling server maintenance or scaling concerns. Being serverless, it automatically adjusts resources in response to workload demands.
This service integrates with AWS, providing access to OpenSearch functionalities. With its simplified deployment, users can build data-rich applications.
This is part of a series of articles about OpenSearch
How Amazon OpenSearch Serverless works
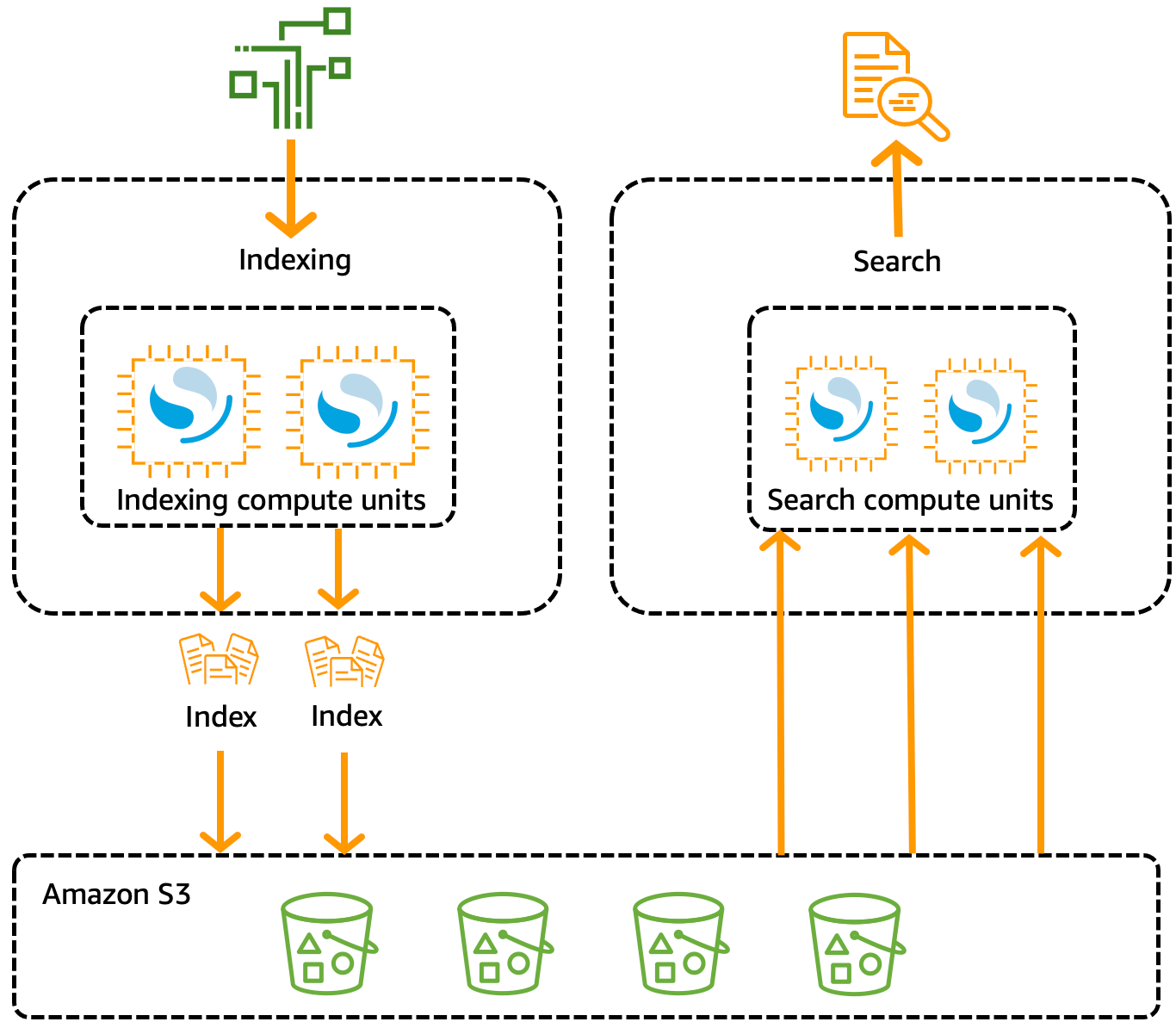
Amazon OpenSearch Serverless uses a cloud-native architecture that decouples indexing (ingesting data) from search (querying data). This separation allows each function to scale independently, unlike traditional OpenSearch clusters where indexing and search operations share the same infrastructure. OpenSearch Serverless stores index data in Amazon S3.
Source: AWS
{kind=link}
When data is written to a collection, it is distributed to indexing compute units, which process the data and store the indexes in S3. For search queries, OpenSearch Serverless directs requests to search compute units, which fetch the indexed data from S3 if it is not already cached locally. This approach ensures that search and indexing workloads do not compete for resources, improving performance and scalability.
The service measures compute capacity in openSearch compute units (OCUs), each of which consists of 6 GiB of memory and a virtual CPU, with support for up to 120 GiB of index data. OpenSearch Serverless automatically provisions OCUs as needed based on the collection’s workload and scales them down when demand decreases, making resource management more efficient. For high availability, redundant OCUs are deployed across multiple Availability Zones by default, though this can be disabled for testing environments.
Related content: Read our guide to OpenSearch vs Elasticsearch
OpenSearch Serverless collection types
Time Series
Time series collections in Amazon OpenSearch Serverless cater to continuously generated time-based data, such as logs, metrics, and events. This functionality optimizes data retrieval and storage for time-dependent queries. By indexing data with temporal attributes, it supports efficient retrieval for data analysis and monitoring applications, offering insights into trends and system performance over time.
Designed to handle high data ingestion rates, time series collections automatically scale to accommodate data growth. This dynamic scaling reduces the need for manual adjustments, ensuring consistent query performance.
Vector Search
Vector search collections in Amazon OpenSearch Serverless enable similarity searches across vectorized data, which is important for applications like recommendation systems and image recognition. These collections store and query high-dimensional vectors, providing fast and scalable retrieval of items that are alike in the feature space.
This type of search leverages machine learning models to convert data into numerical representations for comparison. OpenSearch Serverless manages the distribution and retrieval of vectors, optimizing search performance across large datasets.
Amazon OpenSearch Serverless pricing
Amazon OpenSearch Serverless adopts a pay-as-you-go pricing model, with charges divided into compute and storage costs. Compute capacity is measured in OpenSearch compute units (OCUs), which account for CPU, memory, and storage resources required to handle indexing and search workloads. One OCU consists of 6 GB of RAM, a virtual CPU, and associated storage.
Charges are incurred on an hourly basis for OCUs, with separate rates for indexing and search operations. Each OCU is billed at $0.24 per hour, whether it’s used for data indexing or for running search queries. Data storage, on the other hand, is billed by the amount of data stored in Amazon S3, at a rate of $0.024 per GB per month.
A minimum of 2 OCUs is required per collection (1 OCU for indexing and 1 OCU for search), though a development or test mode reduces this to 0.5 OCUs each, lowering costs by cutting out redundant nodes. Additionally, OCUs can be shared across collections using the same encryption key, except for vector search collections, which must have their own dedicated OCUs.
Tutorial: Getting started with Amazon OpenSearch Service
The instructions below are adapted from the official documentation.
Step 1: Configure permissions
To use Amazon OpenSearch Serverless, the necessary Identity and Access Management (IAM) permissions must be configured. Ensure your user or role has an attached identity-based policy that grants permissions for key OpenSearch Serverless actions like creating and managing collections, access policies, and security policies. These permissions are crucial to performing operations such as indexing, searching, and deleting data.
For this tutorial, the following minimum permissions are required:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "aoss:CreateCollection", "aoss:ListCollections", "aoss:BatchGetCollection", "aoss:DeleteCollection", "aoss:CreateAccessPolicy", "aoss:ListAccessPolicies", "aoss:UpdateAccessPolicy", "aoss:CreateSecurityPolicy", "aoss:GetSecurityPolicy", "aoss:UpdateSecurityPolicy", "iam:ListUsers", "iam:ListRoles" ], "Effect": "Allow", "Resource": "*" } ] } |
After attaching the required policy, proceed to the next step.
Step 2: Create a collection
To create your first collection:
- Navigate to the Amazon OpenSearch Service console.
- From the left navigation pane, select Collections and click Create collection.
- Name the collection
movies. - Choose Search as the collection type.
- For Security, select Standard create.
- Under Encryption, select Use AWS owned key.
- Configure the network settings, and for Access type, select Public.
- Enable access to both OpenSearch endpoints and OpenSearch dashboards.
- Set up a data access policy, creating a rule named
Movies collection access. Assign the necessary permissions to the IAM user or role that will interact with the collection. - Review the settings and submit the collection creation. It will take a few minutes for the collection status to become active.
Step 3: Upload and search data
Once your collection is active, you can start uploading data:
- In the console, go to Collections, then select the movies collection.
- Open OpenSearch Dashboards via the provided URL.
- In OpenSearch Dashboards, go to Dev Tools from the left navigation pane.
- To create an index, use the following request:
PUT movies-index - To add a document to the index, use this request:
123456PUT movies-index/_doc/1{"title": "E.T.","genre": "Science Fiction","year": 1982}
- To search the indexed data, create an index pattern named
moviesunder Stack Management > Index Patterns. You can then use the Discover tool or the search API within Dev Tools to query the indexed data.
Step 4: Delete the collection
Once you’re finished, delete the movies collection to avoid incurring unnecessary costs:
- Return to the Amazon OpenSearch Service console.
- Select the
moviescollection under Collections. - Click Delete and confirm the deletion. This will remove the collection and all associated data.
Empowering organizations with comprehensive support for OpenSearch
While Amazon OpenSearch Serverless does provide organizations with a managed service for OpenSearch within AWS, there are several downsides that should be considered, including:
- Greatly reduced flexibility with choosing your preferred hosting environment outside of AWS, and added challenges in configuration
- Custom OpenSearch plugins are not supported, and many other plugins are not supported as well
- Large datasets (1TB and over) offer diminished performance
- The refresh interval for indexes in Vector Search collections is around 60 seconds
- The number of shards, intervals, and refresh intervals are not modifiable, leaving your sharding strategy dependent on the collection type and traffic.
- And more
At Instaclustr, our mission is to empower organizations with the most comprehensive support for OpenSearch–including providing users with the flexibility they need to operate their applications at scale.
We believe that successful implementation of this open-source search and analytics engine lies at the intersection of world-class managed services and expert assistance.
- Managed Services: We take over the management of your OpenSearch clusters’ underlying infrastructure to ensure high availability, scalability, and security. This means that you can dedicate your resources to your core business objectives instead of infrastructure management.
- Expert Assistance: From cluster configuration to performance tuning, our team of experienced engineers is ready to help. We are well-versed in OpenSearch and can provide valuable insights and recommendations to optimize your clusters, whether it’s fine-tuning query performance, optimizing index settings, or resolving stability problems.
- 24/7 Monitoring and Support: With round-the-clock monitoring and support, we detect and address any potential issues promptly, minimizing downtime and ensuring smooth operation of your OpenSearch clusters.
Experience the Instaclustr difference today. Schedule a free consultation with our OpenSearch experts and let us help you optimize your OpenSearch environment.
For more information please see: