What is a vector database?
A vector database in the context of retrieval augmented generation (RAG) is a specialized database designed to efficiently store, index, and query high-dimensional vector embeddings. These embeddings are numerical representations of various data types, such as text, images, or audio, capturing their semantic meaning.
How vector databases facilitate RAG:
- Data ingestion and embedding: External knowledge bases (documents, articles, etc.) are first broken down into smaller chunks. Each chunk is then converted into a vector embedding using an embedding model (e.g., a neural network). These embeddings are then stored in the vector database.
- Query embedding: When a user poses a query, that query is also converted into a vector embedding using the same embedding model.
- Similarity search: The vector database performs a similarity search, comparing the query embedding with the stored data embeddings. It identifies the most semantically similar data chunks based on vector distance metrics (e.g., cosine similarity).
- Retrieval and context provision: The text content corresponding to the most similar data embeddings is retrieved from the vector database. This retrieved text serves as relevant context for the Large Language Model (LLM).
- Augmented generation: The retrieved context, along with the original user query, is fed to the LLM. The LLM then uses this augmented information to generate a more accurate, relevant, and contextually grounded response, reducing the likelihood of hallucinations.
What is Retrieval-augmented generation (RAG)?
Retrieval-augmented generation (RAG) combines traditional generative models with retrieval mechanisms to enhance the quality and relevance of generated responses. In a RAG workflow, a model retrieves relevant contextual information from a knowledge base or database, often one designed for fast vector similarity search, before generating an answer. This method allows the system to ground its outputs in up-to-date, factual, or domain-specific data.
RAG pipelines inject retrieved text, documents, or data into the prompt or context given to a generative model. The generator (such as a transformer-based LLM) can use this information to produce more accurate, relevant, and context-aware responses. This is especially useful for domains where knowledge changes frequently or where answers must be tailored with specific or proprietary data, such as in technical support, legal, or financial applications.
How vector databases facilitate RAG
Data ingestion and embedding
Vector databases begin their role in RAG systems with data ingestion and embedding. During this stage, raw data such as articles, documents, or other text is collected and processed through embedding models. These models typically use machine learning algorithms to convert each data item into a high-dimensional vector that encodes its semantic features, capturing the inherent meaning and relationships between pieces of information.
Once embedded, these vectors are ingested into the vector database, which indexes them for fast similarity retrieval. The database must handle high-throughput operations at scale, maintain consistency, and support updates as new documents or data arrive.
Query embedding
When users interact with a RAG system, their queries, typically in natural language, must also be transformed into vector representations. This is achieved by passing the query through the same or a compatible embedding model used during ingestion, generating a comparable high-dimensional vector. This ensures that similarity search is meaningful, as queries and stored data share the same embedding space.
By embedding queries in this way, the vector database can leverage mathematical distance or similarity measures (such as cosine similarity or Euclidean distance) to efficiently match the query vector against stored document vectors. The precision of this step is critical: the closer the query and document vectors, the more relevant the retrieved information will be.
Similarity search
Similarity search is central to a vector database’s operation in RAG workflows. Once a query has been embedded, the database performs a nearest neighbor search to quickly retrieve the top-k most similar data points. This process relies on advanced indexing structures and search algorithms designed to operate efficiently, even as the dataset scales to millions or billions of vectors.
Efficient similarity search not only determines RAG’s speed but also its practical effectiveness. High-performance vector databases must balance retrieval speed with accuracy, ensuring that relevant documents are found without exhaustive scans.
Retrieval and context provision
After identifying the most relevant vectors, the corresponding original documents or data entries are retrieved from the database and prepared for use by the generative model. This retrieval process may involve additional filtering, ranking, or preprocessing steps to ensure the output is both high quality and formatted appropriately for downstream tasks or model consumption.
These retrieved documents are then used to construct or augment the context fed to the language model. By providing external, up-to-date, and often domain-specific information, the system ensures that generated responses are not only coherent and plausible but also informed by the latest or most relevant knowledge.
Augmented generation
In the augmented generation stage, retrieved data is supplied as context or incorporated into the prompt used by the language model. The model leverages this additional information to generate outputs that are both contextually richer and more accurate. This hybrid process allows the model to answer queries with facts and context that it might not have seen during pretraining.
The integration between vector database retrieval and text generation is what defines the RAG approach. By using vector search to bring relevant supporting data, the model’s generative capabilities become more reliable, transparent, and usable for enterprise or specialized tasks. This elevates the quality and trustworthiness of AI-driven responses and helps ensure outputs meet application requirements or compliance constraints.
Tips from the expert

David vonThenen
Senior AI/ML Engineer
As an AI/ML engineer and developer advocate, David lives at the intersection of real-world engineering and developer empowerment. He thrives on translating advanced AI concepts into reliable, production-grade systems all while contributing to the open source community and inspiring peers at global tech conferences.
In my experience, here are tips that can help you better build and operate RAG systems with vector databases:
- Stand up a retrieval QA rig before launch: Create a gold set of user queries labeled by intent (navigational, exploratory, troubleshooting) and score retrieval with nDCG/Recall@k plus an LLM-as-judge calibrated by humans. Gate any change (model, chunking, index params) behind this harness.
- Practice embedding governance, not just versioning: Store
model_id,preprocess_hash,dim, andembed_timewith each vector; dual-write during upgrades and measure overlap@k between old/new embeddings. Flip traffic only when overlap and answer quality clear thresholds; archive drift reports. - Route queries to specialist indexes (mixture-of-experts retrieval): Train a lightweight router to send each query to domain-specific indexes (policies, product docs, code) instead of one mega-index. You’ll cut k, latency, and cross-talk while boosting relevance with domain-tuned parameters.
- Make reranking constraint-aware, not just neural: After ANN recall, use a cross-encoder (or ColBERT-style) reranker that also enforces hard constraints: ACLs, freshness windows, jurisdiction, PII flags. If a candidate violates constraints, downrank or drop before it hits the generator.
- Replace fixed top-k with calibrated radial thresholds: Learn per-index distance distributions and set dynamic score/radius cutoffs. When no candidate clears the “trust radius,” fall back to lexical or ask for clarification; this is the single best guardrail against off-topic citations.
Advantages of using vector databases in RAG
Vector databases provide a critical infrastructure layer for retrieval-augmented generation (RAG) systems. Their architecture and capabilities enable RAG models to deliver accurate, real-time, and domain-aware outputs by simplifying the retrieval of semantically relevant information.
Key benefits include:
- Semantic precision: Vector databases retrieve documents based on meaning rather than exact keyword matches. This enables more relevant and nuanced context for generation, especially when queries are phrased differently from source documents.
- High-speed retrieval at scale: Built for fast nearest neighbor searches in high-dimensional spaces, vector databases maintain low-latency performance even with millions of records.
- Real-time updates: Many vector databases support dynamic updates, allowing new information to be embedded and queried without retraining or redeployment.
- Multi-modal support: They handle vectors from various data types (text, images, audio) allowing RAG systems to operate across multiple input and output modalities.
- Flexible similarity metrics: Developers can configure similarity calculations (e.g., cosine, Euclidean) to suit their retrieval needs, optimizing for precision, recall, or specific domain behaviors.
- Improved context grounding: Retrieved vectors link back to raw data, enabling models to ground outputs in verifiable sources, which improves accuracy and user trust.
- Scalability and distributed architecture: Designed for large-scale deployments, modern vector databases support sharding, replication, and horizontal scaling, ensuring performance and reliability in production environments.
Common vector databases for RAG
1. Apache Cassandra
![]()
Cassandra introduced vector search in version 5.0, allowing it to store and compare high-dimensional embeddings for similarity search. This capability is enabled through a new vector data type in CQL and relies on Storage-Attached Indexing (SAI), which supports fast and scalable indexing of vector columns.
Key features include:
- Native vector data type: Stores and retrieves high-dimensional embedding vectors directly in CQL tables
- Storage-Attached Indexing (SAI): Provides scalable, column-level indexing for vector data to support efficient similarity queries
- Semantic search support: Embeddings preserve structural and semantic relationships, allowing for meaning-based retrieval
- LLM-ready architecture: Designed to integrate with contextual embeddings from large language models for tasks like classification and retrieval
- Distributed scalability: Maintains Cassandra’s core strengths of high availability and distributed scale for production-grade vector workloads
2. OpenSearch
![]()
OpenSearch Vector Search is part of the OpenSearch platform and supports fast similarity search across high-dimensional data. It’s optimized for unstructured data types like text, images, and audio, and includes native support for semantic and hybrid search.
Key features include:
- Native support for vector embeddings: Index and search dense vector representations for similarity-based retrieval
- Hybrid and multimodal search: Supports semantic, keyword, and neural sparse search across text, audio, and images
- Real-time ingestion and indexing: Continuously processes incoming data with built-in pipelines for transformation and enrichment
- GPU-accelerated search: Speeds up indexing and querying at scale for large vector workloads
- LLM integration: Compatible with leading LLM frameworks for building end-to-end generative AI pipelines
{kind=link}
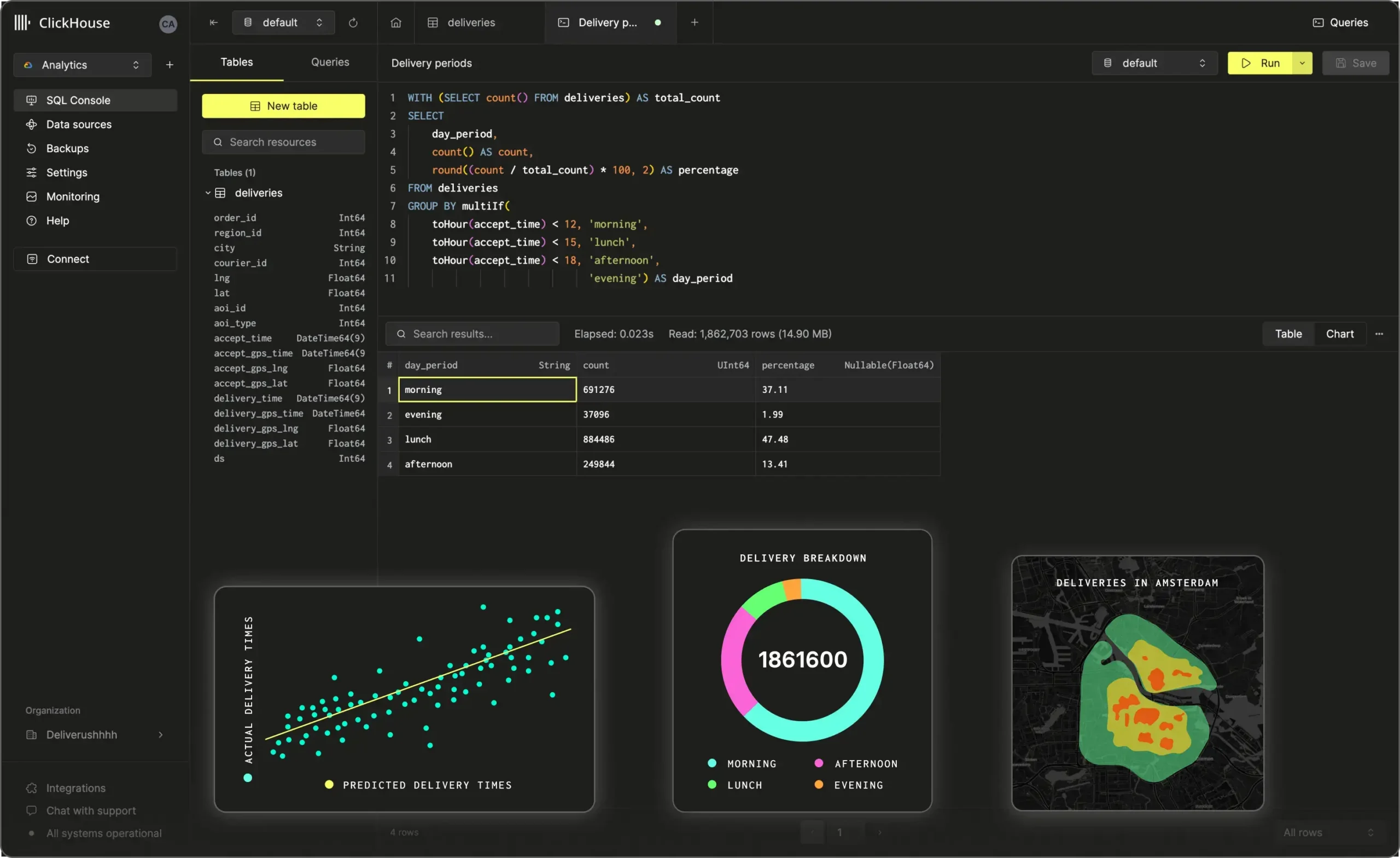
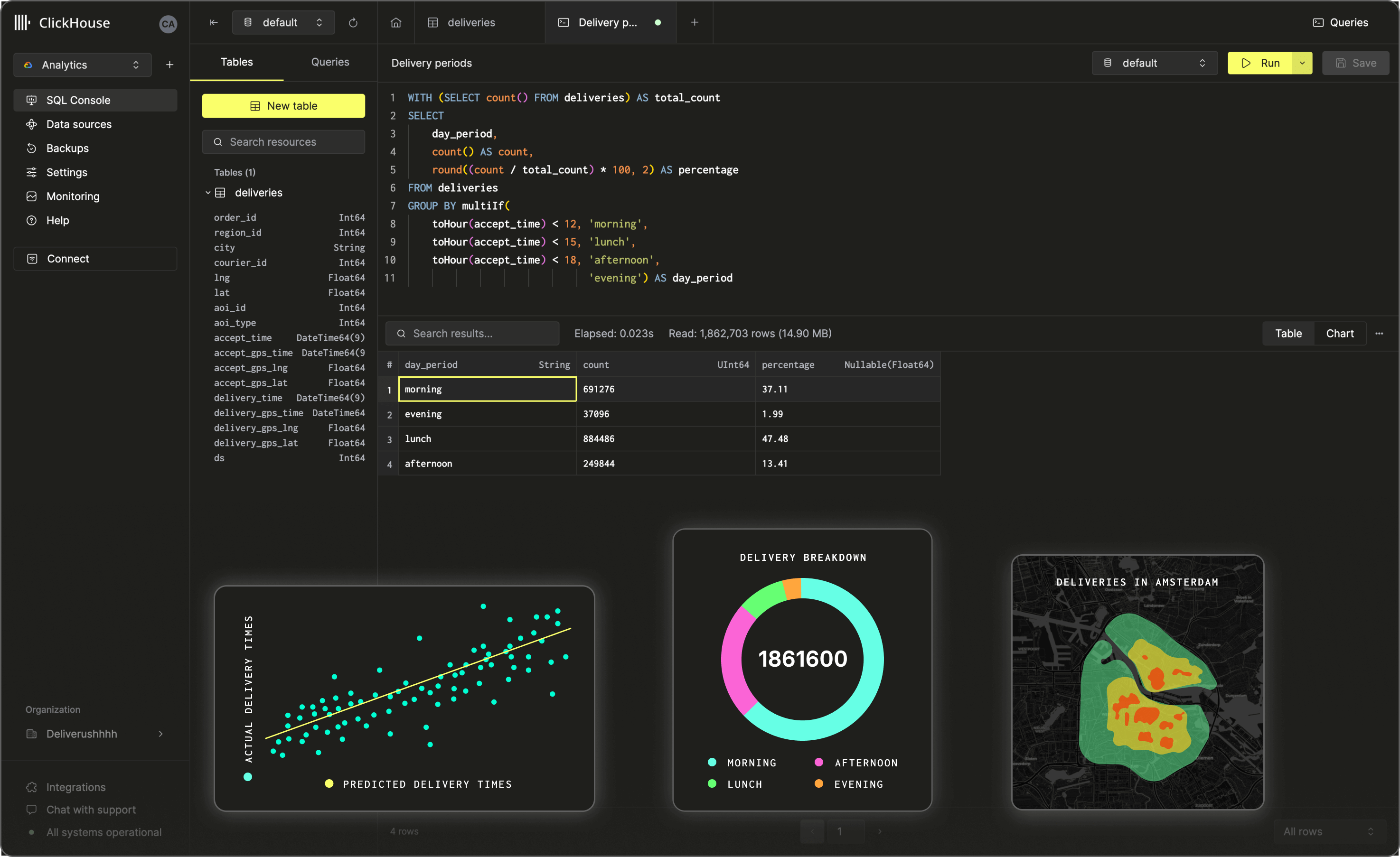
3. ClickHouse
![]()
ClickHouse is a columnar database that supports native vector search. It allows storage and querying of embedding vectors using functions like cosineDistance, enabling real-time RAG workflows. It offers a distributed architecture, efficient compression, and compatibility with open source AI tools.
Key features include:
- Native vector functions: Built-in support for cosine and L2 distance calculations over high-dimensional vectors
- High-throughput architecture: Columnar storage, compression, and parallelism enable fast retrieval at scale
- Integration with AI frameworks: Compatible with tools like Hugging Face and LangChain for embedding pipelines and model inference
- Efficient storage optimization: Supports compression and quantization for better storage efficiency
- Distributed scalability: Handles billions of vectors with horizontal scaling and multi-core processing
{kind=link}
4. PostgreSQL (pgvector)

pgvector is a PostgreSQL extension that adds native vector similarity search to the Postgres ecosystem. It supports exact and approximate nearest neighbor search with distance metrics like cosine, L2, and inner product. With full ACID compliance and SQL support, pgvector allows developers to manage structured and unstructured data in a unified relational model.
Key features include:
- Multiple distance metrics: Supports cosine, L2, inner product, and more for flexible similarity comparisons
- Exact and approximate search: Includes HNSW and IVFFlat indexes for speed-recall tradeoffs
- Postgres-native integration: Leverages all core Postgres features such as joins, filtering, transactions, and indexing
- Support for high-dimensional vectors: Handles dense, sparse, binary, and half-precision vectors across thousands of dimensions
- Flexible indexing and filtering: Enables hybrid search and filtering using standard SQL and partial indexes for domain-specific tuning
5. Chroma
![]()
Chroma is an open source vector database for AI applications that require fast, reliable, and scalable retrieval. It supports vector, full-text, metadata, and regex search, making it suitable for diverse use cases, from prototyping on a laptop to serving production-scale RAG workloads across petabytes of data in the cloud.
Key features include:
- Multi-modal search: Supports vector, full-text, regex, and metadata search in a unified system
- Scalable architecture: Runs locally or as a distributed system with petabyte-scale capacity using cloud object storage
- Low latency queries: Designed for fast vector similarity search over billions of records across multi-tenant indexes
- Cost-efficient storage: Utilizes object storage with automatic data tiering for lower cost
- Integrated ecosystem: Built-in support for embedding models from OpenAI, HuggingFace, and others
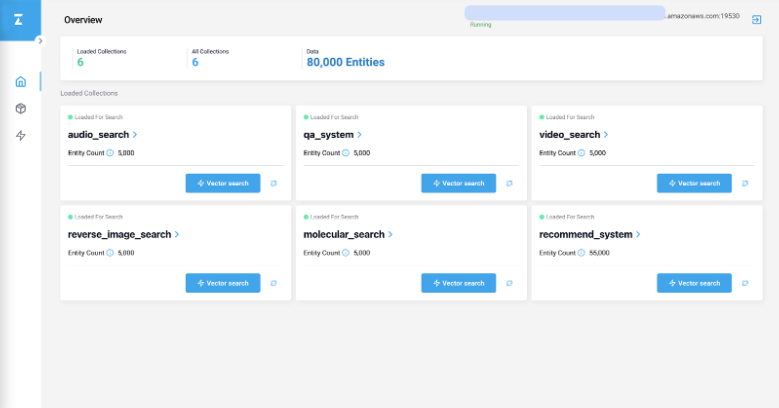
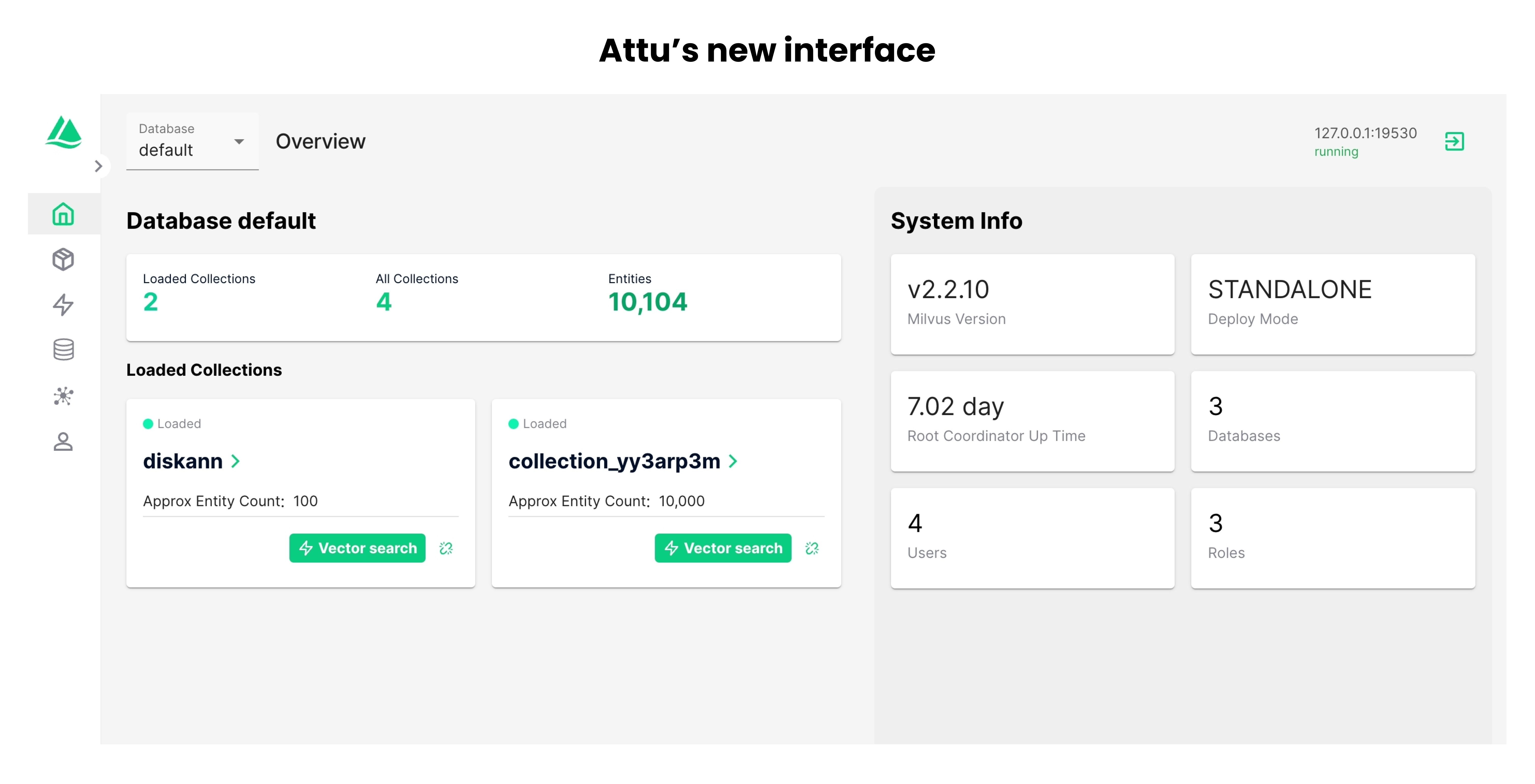
6. Milvus
![]()
Milvus is a vector database to manage, index, and search massive volumes of unstructured data using vector embeddings. It supports dense vector search at scale with high performance, thanks to a distributed, modular architecture optimized for flexibility, consistency, and compute efficiency.
Key features include:
- Elastic and scalable design: Separates storage, coordination, and compute into independent services
- Rich indexing options: Supports over 10 index types, including HNSW, IVF, PQ, and GPU-accelerated methods, allowing developers to tune for speed, accuracy, or memory usage
- Flexible search functions: Offers top-K and range ANN, metadata filtering, and upcoming support for hybrid dense-sparse search, enabling control over search behavior
- Tunable consistency model: Implements a delta consistency model, allowing queries to tolerate staleness as needed
- Hardware acceleration: Optimized for AVX512, Neon, GPU execution, and quantization techniques to maximize throughput and minimize latency
{kind=link}
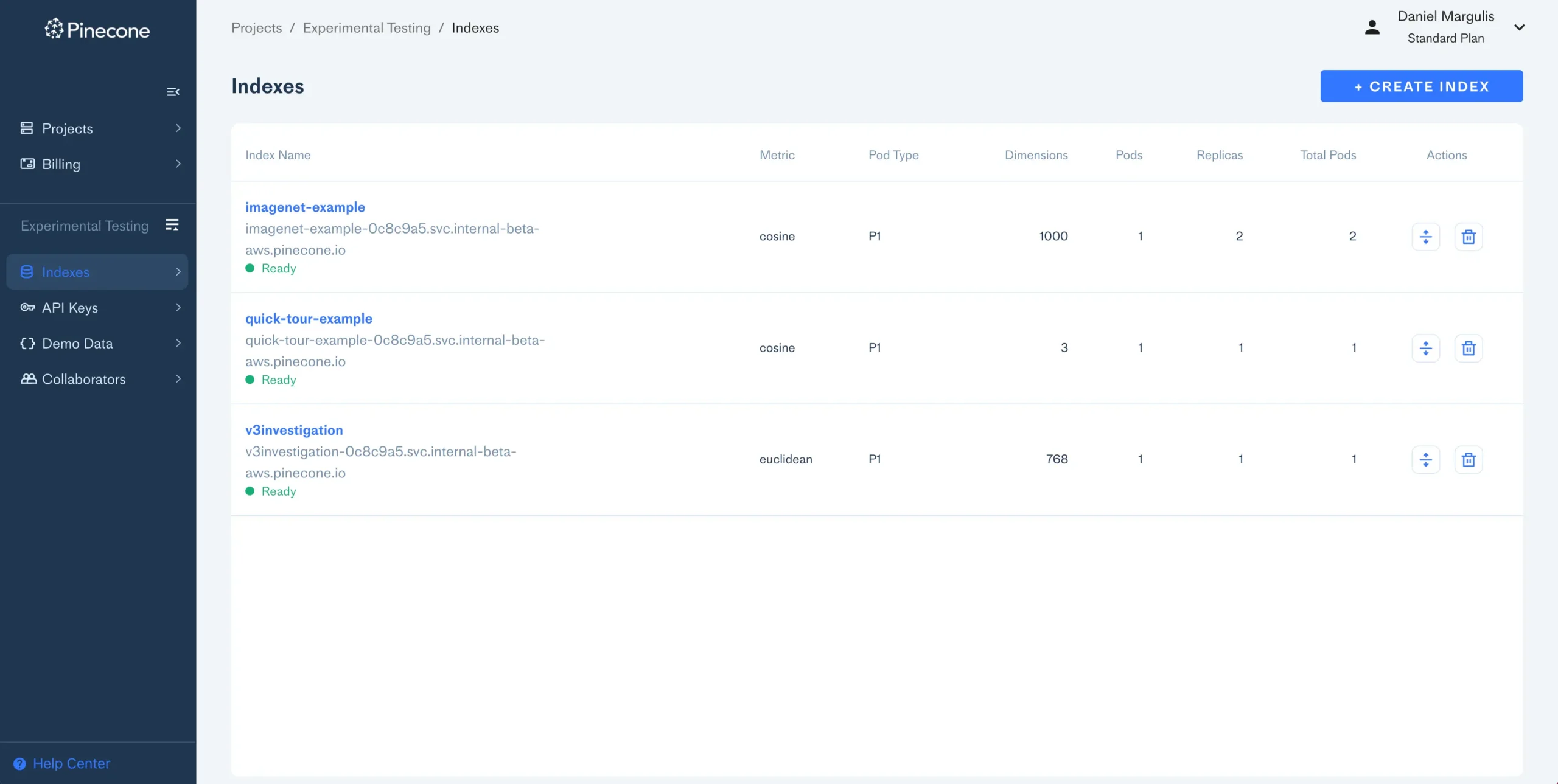
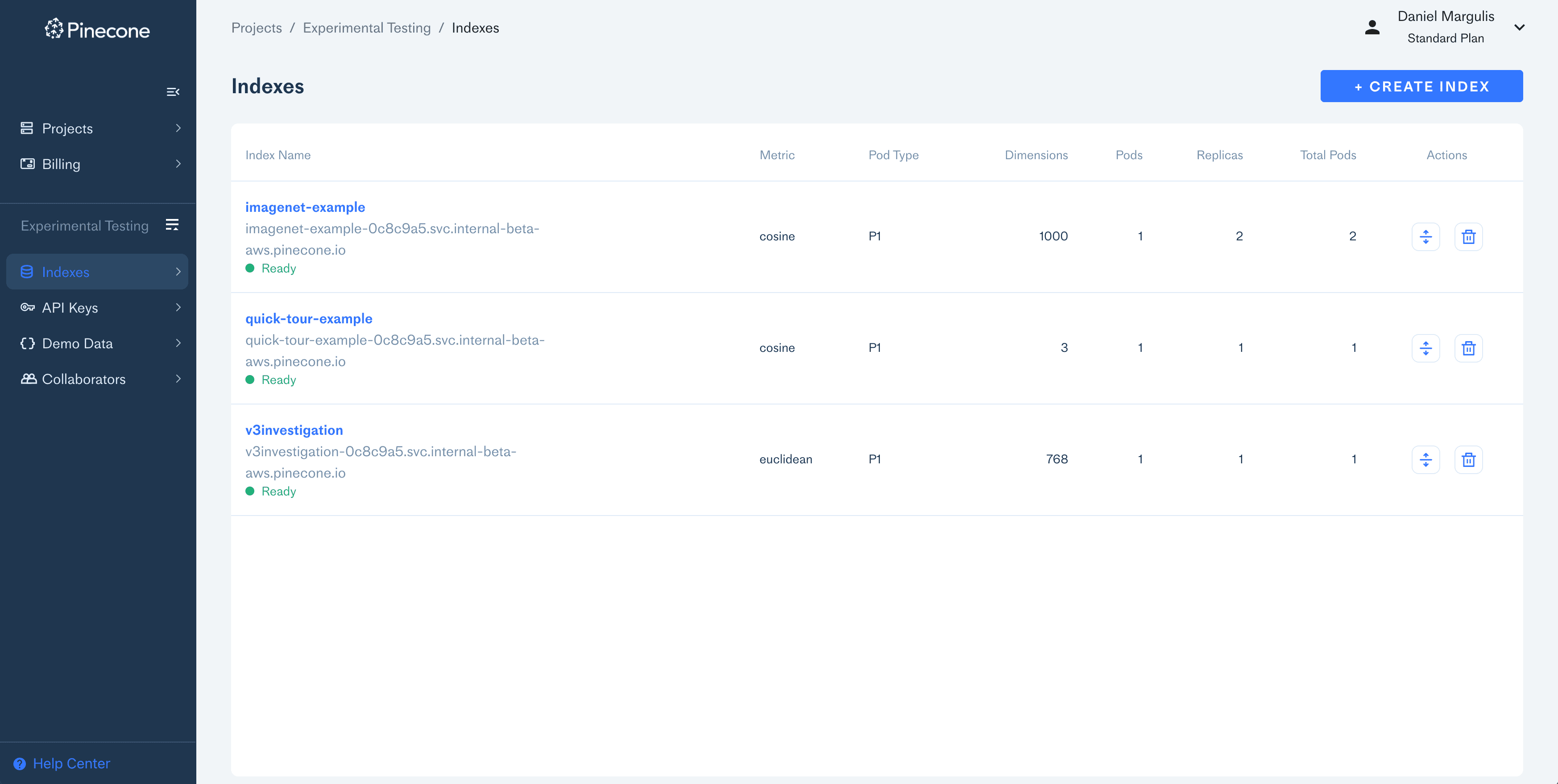
7. Pinecone
![]()
Pinecone is a fully managed, serverless vector database for AI applications like semantic search, recommendations, RAG, and autonomous agents. Its architecture is designed to deliver high recall, low-latency search over billions of vectors with minimal operational overhead.
Key features include:
- Serverless and fully managed: Infrastructure scales automatically with traffic and data volume, eliminating the need to manage clusters or capacity planning
- Real-time indexing: Vectors are indexed immediately upon upsert or update, ensuring results reflect the freshest data without manual re-indexing
- Hybrid search support: Combines sparse (keyword) and dense (semantic) embeddings to improve retrieval accuracy across a broader range of queries
- Optimized for recall and latency: Leverages leading vector search algorithms with performance tuned for high recall and sub-second query times
- Namespace partitioning: Enables clean separation and isolation of multi-tenant or multi-domain datasets using logical partitions
{kind=link}
8. Qdrant
![]()
Qdrant is an open source vector database and similarity search engine for high-performance AI applications. Designed to manage high-dimensional vector data efficiently, Qdrant combines Rust-based speed with features that support real-time, production-grade search.
Key features include:
- High-performance architecture: Written in Rust to deliver low-latency search, even across billions of vectors, with efficient use of system resources
- Scalable and cloud-native: Supports both vertical and horizontal scaling, with managed cloud options for high availability and zero-downtime upgrades
- Easy deployment: Lightweight API and Docker support make Qdrant easy to spin up locally or in any infrastructure, simplifying development and testing
- Efficient storage with compression: Quantization options reduce memory footprint and enable offloading data to disk without sacrificing performance
- Reliable real-time search: Optimized for fast similarity search, ensuring real-time responsiveness for production workloads
{kind=link}
9. Weaviate
![]()
Weaviate is an open source, AI-native vector database to simplify the development of applications. With support for vector and hybrid search, integration with popular machine learning models, and features like multi-tenancy and native filtering, it enables developers to quickly build, test, and scale AI-powered systems.
Key features include:
- Hybrid search: Combines semantic vector search with BM25 keyword search to improve relevance, with re-ranking included
- ML model integrations: Connect to over 20 machine learning models or bring your own embeddings, enabling rapid experimentation and deployment
- Out-of-the-box RAG support: Designed to integrate directly with LLMs for secure and efficient retrieval-augmented generation workflows using proprietary data
- Filtering capabilities: Perform multi-attribute filtering on large datasets, improving precision and control in search results
- Multi-tenancy and tenant isolation: Resource isolation and namespace management support high-scale, multi-user environments securely
{kind=link}
Learn more in our detailed guide to vector database LLM
Considerations for choosing the right vector database for RAG
Selecting the right vector database is critical for building performant and reliable retrieval-augmented generation (RAG) systems. Different workloads and infrastructure environments may require different capabilities, so evaluation should be guided by application-specific requirements.
Key considerations include:
- Indexing and search performance: Evaluate the database’s ability to perform fast and accurate nearest neighbor searches across high-dimensional vectors. Look for support for multiple index types (e.g., HNSW, IVF, PQ) and options for tuning speed vs. accuracy.
- Scalability and deployment model: Consider whether the system supports horizontal scaling, multi-node clusters, and distributed storage. Depending on your scale, you may prefer managed cloud services, on-prem installations, or hybrid options.
- Update latency and real-time indexing: For dynamic knowledge bases, it’s crucial that new documents can be ingested and queried with minimal delay. Check how fast the system reflects updates in search results without requiring manual re-indexing.
- Query flexibility: Look for support for hybrid search (dense + sparse), metadata filtering, range search, and custom ranking. These features enable more fine-grained control over retrieval behavior.
- Multi-modal and multi-tenant support: If your RAG system needs to process text, images, or audio, ensure the database can store and search across different data modalities. Multi-tenancy features may be needed for serving multiple clients or use cases in a single instance.
- Integration and ecosystem: The database should integrate easily with your embedding models, vectorization pipelines, and RAG frameworks (e.g., Langchain, LlamaIndex). Built-in support reduces development time and complexity.
- Consistency and fault tolerance: Ensure the database provides a suitable consistency model (strong, eventual, or tunable) for your application’s correctness and performance requirements. High availability and recovery mechanisms are important for production reliability.
- Security and compliance: For enterprise or regulated environments, evaluate features like access control, encryption, tenant isolation, and audit logging. These ensure secure handling of proprietary or sensitive data.
Managed vector databases with Instaclustr
Instaclustr optimizes vector databases by providing a fully managed platform that simplifies the complexities of handling high-dimensional data. Vector databases are essential for applications like semantic search, recommendation engines, and AI-driven workloads, as they store and retrieve data in the form of high-dimensional vectors. Instaclustr ensures that these databases operate efficiently, reliably, and securely, enabling organizations to focus on innovation rather than infrastructure management.
One of the key ways Instaclustr enhances vector database performance is through its expertise in indexing. Efficient indexing is critical for reducing query times, especially in high-dimensional datasets. Instaclustr manages the creation, optimization, and maintenance of indices using advanced algorithms like Hierarchical Navigable Small World (HNSW) and product quantization. This ensures that similarity searches and other operations are both fast and accurate, even as datasets grow in size and complexity.
Scalability and reliability are also central to Instaclustr’s approach. The platform supports horizontal scaling, allowing organizations to handle large-scale data workloads seamlessly. Features like automated scaling, high availability, and 24/7 monitoring ensure that vector databases remain performant and resilient. Additionally, Instaclustr prioritizes enterprise-grade security with measures such as end-to-end encryption and data redundancy, making it a trusted solution for mission-critical applications.
By automating routine database operations like backups, scaling, and monitoring, Instaclustr frees up teams to focus on leveraging vector databases for advanced use cases. Whether it’s powering AI-driven recommendation systems or enabling semantic search, Instaclustr’s managed solutions provide the infrastructure and support needed to unlock the full potential of vector databases.
For more information: