In Part 1 of this two-part blog series we discovered that Debezium is not a new metallic element (but the name was inspired by the periodic table), but a distributed open source CDC technology, and that CDC (in this context) stands for Change Data Capture (not Centers for Disease Control or the Control Data Corporation).
We introduced the Debezium architecture and its use of Kafka Connect and explored how the Debezium Cassandra Connector (on the source side of the CDC pipeline) emits change events to Kafka for different database operations.
In the second part of this blog series, we examine how Kafka sink connectors can use the change data, discover that Debezium also propagates database schema changes (in different ways), and summarize our experiences with the Debezium Cassandra Connector used for customer deployment.
1. How Does a Kafka Connect Sink Connector Process the Debezium Change Data?
At the end of Part 1, we had a stream of Cassandra change data available in a Kafka topic, so the next question is how is this processed and applied to a target sink system? From reading the Debezium documentation, the most common deployment is by means of Kafka Connect, using Kafka Connect sink connectors to propagate the changes into sink systems:
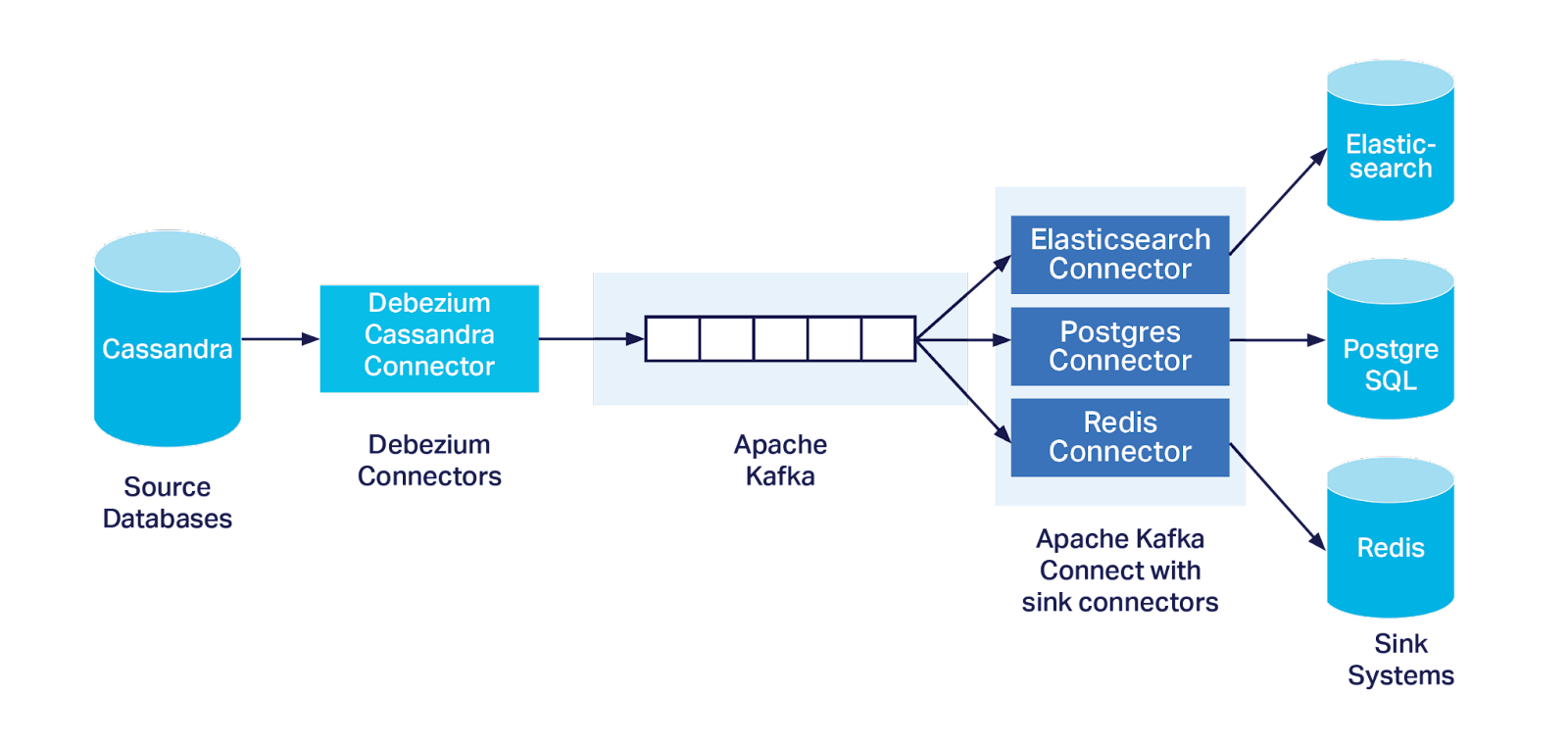
But Debezium only comes with source connectors, not sink connectors; the sink connectors are not directly part of the Debezium ecosystem. Where do you get sink connectors that can work with the Debezium change data from?
Based on my previous experiences with Kafka Connect Connectors, I wondered which open source sink connectors are possibly suitable for this task, given that:
- The Debezium change data format is a complex JSON structure
- It isn’t based on a standard
- Each database produces a different format/content, and
- The actions required on the sink system side will depend on:
- The sink system,
- The operation type, and
- The data values
What’s perhaps not so obvious from the example so far is that Debezium also detects and propagates schema changes. In the above example, the schema is just sent explicitly in each message as the Kafka key, which can change. For example, if columns are added to the database table that is being monitored, then the schema is updated to include the new columns. So the sink connector will also have to be able to interpret and act on schema changes.
The Debezium documentation does address at least one part of this puzzle (the complexity of the JSON change data structure), by suggesting that:
“… you might need to configure Debezium’s new record state extraction transformation. This Kafka Connect SMT (Single Message Transform) propagates the after structure from Debezium’s change event to the sink connector. This is in place of the verbose change event record that is propagated by default.”
Another relevant feature (in incubation) is Debezium Event Deserialization:
“Debezium generates data change events in the form of a complex message structure. This message is later on serialized by the configured Kafka Connect converter and it is the responsibility of the consumer to deserialize it into a logical message. For this purpose, Kafka uses the so-called SerDes. Debezium provides SerDes (io.debezium.serde.DebeziumSerdes) to simplify the deserialization for the consumer either being it Kafka Streams pipeline or plain Kafka consumer. The JSON SerDe deserializes JSON encoded change events and transforms it into a Java class.”
I had a look at Kafka Streams Serdes in a previous blog, so the Debezium Deserializer looks useful for Kafka Streams processing or custom Kafka consumers, but not so much so for off-the-shelf Kafka sink connectors.
2. Single Message Transforms
Let’s have a look at a simple SMT example from this blog.
As I discovered in my last blog, Kafka Connect JDBC Sink Connectors make different assumptions about the format of the Kafka messages. Some assume a flat record structure containing just the new names/values, others require a full JSON Schema and Payload, others allow custom JSON sub-structure extraction, and others (e.g. the one I ended up using after customizing the IBM sink connector) allow for arbitrary JSON objects to be passed through (e.g. for inserting into a PostgreSQL JSONB data type column).
These differences are due to the fact that they were designed for use in conjunction with different source systems and source connectors. All of the connectors I looked at only allowed for insert or upsert (insert if the row doesn’t exist, else update) operations, but not deletes. Some customization would therefore be required to cope with the full range of operations emitted by Debezium source connectors.
For a simple use case where you only want to insert/upsert new records, Debezium provides a bridge between the complex change message format and simpler formats expected by JDBC sink connectors, in the form of a “UnwrapFromEnvelope” single message transform. This can be used in either the source or sink connector side by adding these two lines to the connector configuration:
"transforms": "unwrap", “
transforms.unwrap.type": "io.debezium.transforms.UnwrapFromEnvelope"
Note that by default this SMT will filter out delete events, but there is an alternative, or possibly more recent SMT called io.debezium.transforms.ExtractNewRecordState, which also allows optional metadata to be included
3. Data Type Mappings
The Debezium Cassandra connector represents changes with events that are structured like the table in which the row exists, and each event contains field values and Cassandra data types. However, this implies that we need a mapping between the Cassandra data types and the sink system data types. There is a table in the documentation that describes the mapping from Cassandra data types to literal types (schema type) and semantic types (schema name), but currently not to “logical types”, Java data types, or potential sink system data types (e.g. to PostgreSQL, Elasticsearch, etc.). Some extra research is likely to be needed to determine the complete end-to-end Cassandra to sink system data type mappings.
4. Duplicates and Ordering
The modern periodic table was invented by Mendeleev in 1869 to organize the elements, ordered by atomic weight. Mendeleev’s table predicted many undiscovered elements, including Germanium (featured in Part 1), which he predicted had an atomic weight of 70, but which wasn’t discovered until 1886. The Debezium Cassandra Connector documentation highlights some other limitations of the current implementation. In particular, both duplicate and out-of-order events are possible. This implies that the Kafka sink connector will need to understand and handle both of these issues, and the behavior will also depend on the ability of the sink system to cope with them. If the target system is sensitive to either of these issues, then it’s possible to use Kafka streams to deduplicate events:
- How to handle duplicate messages using Kafka streaming dsl functions
- De-de-de-de-duplicating events with Kafka Streams
- Deduplicating Partitioned Data With a Kafka Streams ValueTransformer
- Kafka Streams — Processing late events
- Apache Kafka order windowed messages based on their value
- Kafka streams and out-of-order events handling

5. Scalability Mismatch
Another thing you will need to watch out for is a potential mismatch of scalability between the source and sink systems. Cassandra is typically used for high-throughput write workloads and is linearly scalable with more nodes added to the cluster. Kafka is also fast and scalable and is well suited for delivering massive amounts of events from multiple sources to multiple sinks with low latency. It can also act as a buffer to absorb unexpected load spikes. However, as I discovered in my previous pipeline experiments, you have to monitor, tune, and scale the Kafka Connect pipeline to keep the events flowing smoothly end-to-end. Even then, it’s relatively easy to overload the sink systems and end up with a backlog of events and increasing lag. So if you are streaming Debezium change events from a high-throughput Cassandra source database you may have to tune and scale the target systems, optimize the performance of the Kafka Connect sink connectors and number of connector tasks running, only capture change events for a subset of the Cassandra tables and event types (you can filter out events that you are not interested in), or even use Kafka Streams processing to emit only significant business events, in order for the sink systems to keep up! And as we discovered (see below), the Debezium Cassandra Connector is actually on the sink-side of Cassandra as well.
6. Our Experiences With the Debezium Cassandra Connector
As mentioned in Part 1, the Debezium Cassandra Connector is “special” — Cassandra is different from the other Debezium connectors since it is not implemented on top of the Kafka Connect framework. Instead, it is a single JVM process that is intended to reside on each Cassandra node and publish events to a Kafka cluster via a Kafka producer. The Debezium Cassandra Connector has multiple components as follows:- Schema processor handles updates to schemas (which had a bug, see below)
- Commit log processor, reads, and queues the Commit logs (which had a throughput mismatch issue)
- Snapshot processor, which handles initial snapshot on start up (potentially producing lots of data)
- Queue processor — a Kafka producer that emits change data to Kafka
7. Conclusions
The code for our forked Debezium Cassandra Connector can be found here, but we also contributed the code for the new schema evolution approach back to the main project. Contact us if you are interested in running the Debezium Cassandra (or other) connectors, and check out our managed platform if you are interested in Apache Cassandra, Kafka, Kafka Connect, and Kafka Schema Registry. What did we learn in this blog series? Debezium and Kafka Connect are a great combination for change data capture (CDC) across multiple heterogeneous systems, and can fill in the complete CDC picture – just as Trapeziums can be used to tile a 2D plane (In Part 1 we discovered that “Trapezium”, but not Debezium, is the only official Scrabble word ending in “ezium”). M.C Escher was well known for his clever Tessellations (the trick of covering an area with repeated shapes without gaps). Here’s a well-known example “Day and Night” (which is now held by the National Gallery of Victoria in Melbourne, Australia, see this link for a detailed picture).
{kind=link}
Acknowledgements
Many thanks to the Instaclustr Debezium Cassandra project team who helped me out with information for this blog and/or worked on the project, including:- Chris Wilcox
- Wesam Hasan
- Stefan Miklosovic
- Will Massey