A few years ago I built a “zero-code” data processing pipeline with Apache Kafka® and related open source technologies like OpenSearch®, PostgreSQL®, and Apache Superset™. Here’s the first blog in that series (there were 10 in all; the links to each can be found at the bottom of this page).
It was designed to use an open source Kafka REST source connector to ingest tidal data from the NOAA REST API into Kafka topics for downstream parts of the pipeline to process. I used this REST connector at the time, but when I downloaded it again, it failed to build.

Camels drinking from a leaking pipe (Source: Wikimedia)
{kind=link}
After a bit of hunting, I tracked down another potential candidate connector: the Apache Camel HTTP Source Kafka Connector.
Apache Camel™ Kafka connectors
Previously I had used some of the Apache Camel™ Kafka connectors. They have the biggest pool of open source Kafka connectors anywhere (here’s the list), which they achieve by automatically generating them from the main Camel components. Given that camels are good at drinking lots of water very quickly (200L in 3 minutes!), this connector was potentially worth trying.
But first things first: here are the basic steps required to set up the system.
First, you need to create a Kafka cluster in the Instaclustr console.

You would need a lot of water bottles to satisfy a camel, but we are only using S3 “buckets” to make the connectors available to the Kafka connect cluster (Source: Adobe Stock)
Because we are going to use an open source Kafka connector, the next step is to follow our instructions to create an AWS S3 bucket (there are other approaches if you are not using AWS) to act as the intermediate storage for the connector(s). Simply upload the connector(s) to S3, and then our Kafka® Connect cluster can retrieve and deploy them automatically.
The instructions provide a CloudFormation template. You will need to run this in an AWS account that has permission to run CloudFormation, create an S3 bucket, and create and use an IAM User, AccessKey, and Policy. You also need to change the S3 bucket name to something unique, otherwise the creation will fail.
Once the CloudFormation completes, look at the Outputs and record the AccessKey, S3BucketName, and SecretKey (you can come back later if you prefer).
The next step is to create an Instaclustr for Kafka Connect cluster that is connected to the Kafka cluster already created above (Kafka Target Cluster). The instructions are here.
Make sure you tick th This is the only opportunity you will have to configure the AWS S3 bucket, and you need to fill in the Custom Connector Configuration details (AccessKey, S3BucketName, and SecretKey from the CloudFormation template Output).
Once the Kafka Connect cluster is running, click on the “Connectors” tab where you will see a list of built-in open source connectors.
However, there’s no REST/HTTP source connector, so this is where we need to do some behind-the-scenes work.
Download the Camel HTTP Source Kafka Connector code found here. Unzip the file into a handy directory and you will see lots of jar files (96 of them in total)!
Which one is the correct file? Well, basically, you need ALL of them. Find the AWS S3 bucket you created above and upload the directory containing all the Camel jar files.
Next, go back to the Instaclustr Kafka Connect cluster connector tabs, and click on the After a short wait, the list of Available Connectors will be updated and include the Camel connectors.
Here’s a screenshot:
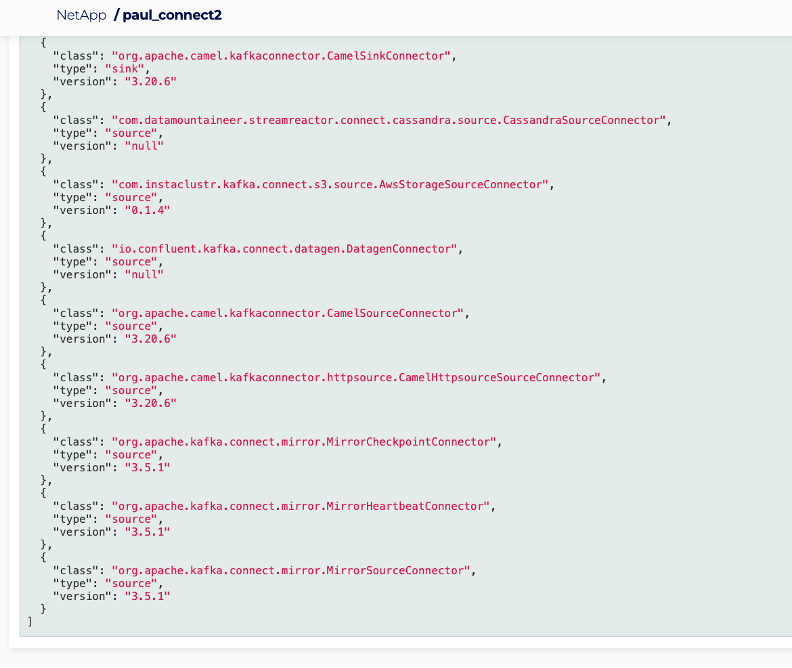
But watch out! There are at least 3 new connectors. I accidentally used the first on the list, the CamelSinkConnector by mistake—this will not work as a Source connector (but didn’t give any errors).
Why? I guess because it’s trying to read records from the Kafka topic and write to the HTTP URL, but as there were no messages in the new topic it just sat there and did nothing.
So, given that we want the HTTP Source connector, the correct class to use is:
|
1 |
"org.apache.camel.kafkaconnector.httpsource.CamelHttpsourceSourceConnector" |

Running camels (Source: Adobe Stock)
The next step is configuring and running the connector. Good luck, as this is often tricky and with little debugging help available. The documentation only mentions 3 configuration options, including period, contentType, and url.
But which URL are we planning on calling? It’s actually the OpenWeatherMap API we need to use. You need to sign up and get a key which allows a limited number of free calls per day, such as:
|
1 2 |
https://api.openweathermap.org/data/2.5/weather q=London,uk&APPID=yourkeyhere |
That call returned this JSON data:
|
1 2 3 4 5 6 7 8 9 |
{"coord":{"lon":-0.1257,"lat":51.5085},"weather" [{"id":803,"main":"Clouds","description":"broken clouds","icon":"04n"}],"base":"stations","main" {"temp":271.83,"feels_like":267.95,"temp_min":270.01,"temp_max":273.81,"pre ssure":995,"humidity":83},"visibility":10000,"wind": {"speed":3.13,"deg":49,"gust":6.26},"clouds": {"all":69},"dt":1705531760,"sys": {"type":2,"id":2075535,"country":"GB","sunrise":1705478291,"sunset":1705508 528},"timezone":0,"id":2643743,"name":"London","cod":200} |
Wow! That’s hot, even for a desert with camels! But the temperature is in Kelvin, so it’s actually pretty cold (–1.32 C or 29.6 F).

Some camels like the cold (Source: Jim Winstead Jr., CC BY 2.0, via Wikimedia Commons)
With a bit of trial and error, I finally got the connector configured and running with a CURL command from a command line as follows:
|
1 2 3 4 5 6 7 8 9 10 11 |
curl https://IP:8083/connectors -X POST -H 'Content-Type: application/json' -d '{ "name": "camel-source-HTTP", "config": { "connector.class": "org.apache.camel.kafkaconnector.httpsource.CamelHttpsourceSourceConnector" , "topics": "test2", "key.converter":"org.apache.kafka.connect.storage.StringConverter", "value.converter":"org.apache.kafka.connect.converters.ByteArrayConverter", "camel.kamelet.http-source.contentType": "application/json", "camel.kamelet.http- source.url":"https://api.openweathermap.org/data/2.5/weather?q=London,uk&AP PID=yourkeyhere", "tasks.max": "1" } }' -k -u ic_kc_user:yourconnectclusterkeyhere |
The Kafka Connect cluster-specific connection information (with examples) is found under the Kafka Conne
It’s tricky to get the syntax right and provide all the required configuration options, but once it works you see the connector appear in the “Active Connectors” tab (where you can restart or delete it).
Given that it’s a Kafka source connector it’s mandatory to specify a topic (or more, with a comma-separated list) using “topics.”
But it was also tricky to find the correct value.converter.
String and JSON options produced garbage record values, but ultimately ByteArrayConverter worked fine. Since the last time I used Apache Camel Kafka connectors there’s something new: Kamelets!
Some of the configurations require “camel.kamelet.” prefixes (more about Kamelets is here). This source connector doesn’t appear to produce Kafka record keys, so if you need them (e.g., for ordering or partition handling) you may need another solution.
To sum up the steps required to get a Camel HTTP Kafka source connector running:
- Create a Kafka cluster
- Create an AWS S3 bucket
- Create a Kafka Connect cluster, using (1) as the target Kafka cluster, and details from (2) as the Custom connector configuration
- Download the Camel HTTP Kafka connector code, and upload to the S3 bucket from (2)
- “Sync” the Kafka connect cluster to get the new custom connectors
- Work out the connector configuration and cluster connection details and run a CURL command to configure/run the connector
- Check that the connector is active
- Check that the data is arriving in the Kafka topic correctly.
Some other things to consider include:
- Scalability—this example shows only 1 task running, if you need more you can restart the connector with more tasks
- Is there any chance of exceptions occurring, and how are they handled?
- For each weather location we will need a different connector configuration and instance running. What if we need 100 locations? 1000s? And what if we need to dynamically request data from different locations, potentially for only a few hours at a time, and then delete the corresponding connectors? There is potential to use a workflow engine for this (e.g. Cadence® or AirFlow etc.)
That’s it for now! Keep an eye out for my next blog on Apache Camel.
In the meantime, here are the links to my Data Processing Pipeline series:
- Part 1: Building a Real-Time Tide Data Processing Pipeline: Using Apache Kafka, Kafka Connect, Elasticsearch, and Kibana
- Part 2: Building a Real-Time Tide Data Processing Pipeline: Using Apache Kafka, Kafka Connect, Elasticsearch, and Kibana
- Part 3: Getting to Know Apache Camel Kafka Connectors
- Part 4: Monitoring Kafka Connect Pipeline Metrics with Prometheus
- Part 5: Scaling Kafka Connect Streaming Data Processing
- Part 6: Streaming JSON Data Into PostgreSQL Using Open Source Kafka Sink Connectors
- Part 7: Using Apache Superset to Visualize PostgreSQL JSON Data
- Part 8: Kafka Connect Elasticsearch vs. PostgreSQL Pipelines: Initial Performance Results
- Part 9: Kafka Connect and Elasticsearch vs. PostgreSQL Pipelines: Final Performance Results
- Part 10: Comparison of Apache Kafka Connect, Plus Elasticsearch/Kibana vs. PostgreSQL/Apache Superset Pipelines