Another day, another article about Cadence® but this time we are going to look at something a little bit different.
One of the best features of open source software, such as Cadence, is that the community can contribute improvements in lots of ways—from small contributions like bug fixes and implementing feature enhancements, all the way to larger paradigm shifts like the one we are looking at today.
Interpreter Workflow engine (iWF) is a new project that comes to us from Indeed, and its goal is to use Cadence as a base and take it to the next level by making it simpler to use for the consumer.
Cadence iWF Mission Statement
So, what drives the iWF project? Let’s look at the design document.
“Here proposes a new way of using Cadence. It’s not to replace or deprecate Cadence. It rather builds a new layer on top of Cadence to provide a more friendly API for better experience. It keeps almost the same power of using Cadence workflow in the original way.”
If we dig a little deeper, we learn more about why this project was created. Cadence is simple to get started with an easy-to-use SDK. But as workflows become more and more complex, it can become increasingly challenging to maintain them.
The Cadence iWF project aims to keep most of the functionality of Cadence while providing a simpler interface, making it easier to build workflows that avoid some of these issues.
What Are the Components?
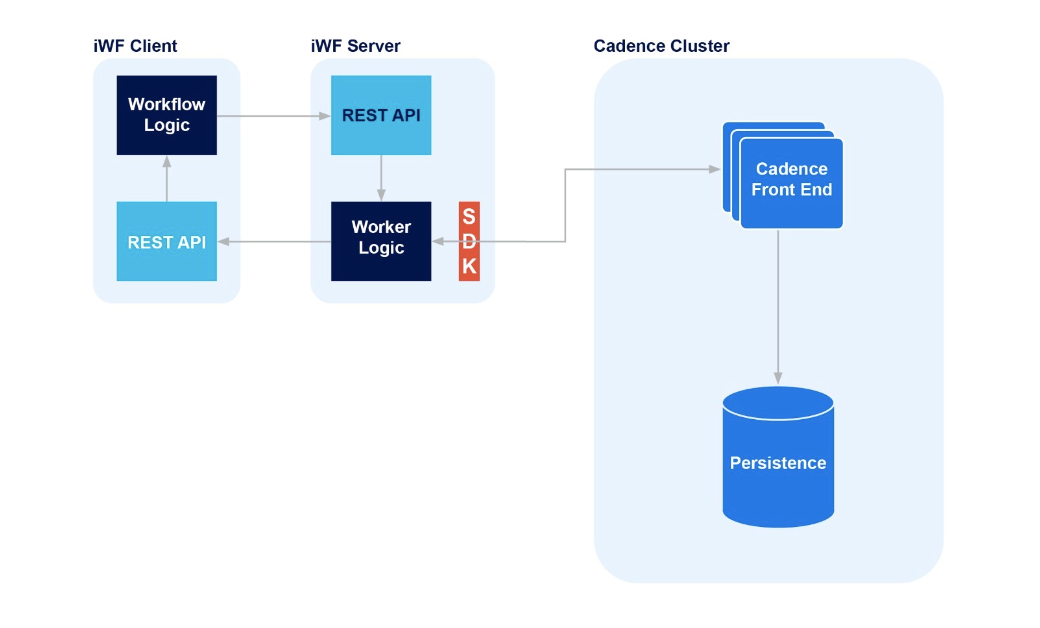
First, there is no change to the Cadence infrastructure. We still use a Cadence cluster with a persistence store, such as Apache Cassandra®.
On top of this we add the iWF Server. This is an application that sets up two components: a standard Cadence worker process and a REST API.
The iWF server is configured with a connection to a Cadence cluster and once it’s running, it doesn’t require any other input.
The other half of the solution is an iWF client application. This client also has 2 components: the workflow code and a REST API.
 How Does It Work?
How Does It Work?
State Definitions
In the world of iWF, workflows are defined as a set of states. Each state implements some business logic and then returns the desired next state for the workflow or completes.
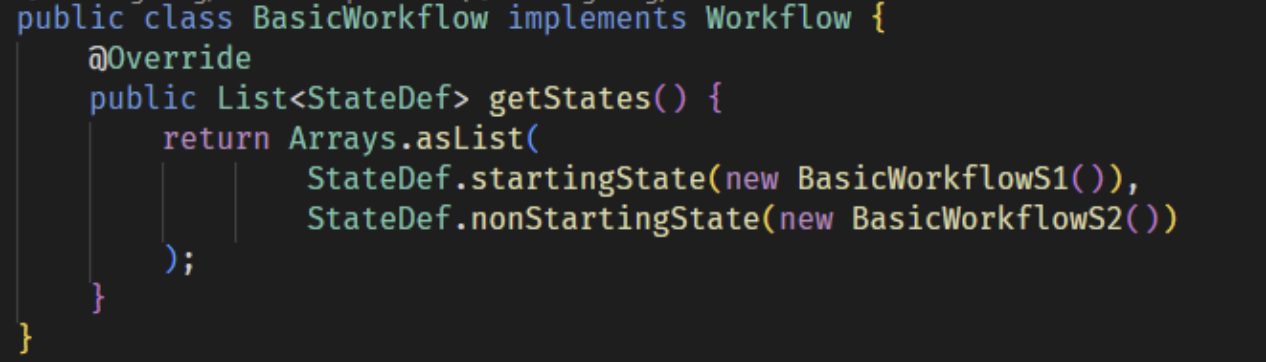
State definitions implement 2 interface functions:
- a start function—this determines the circumstances or schedule for when this state will execute. If there are no settings, it executes immediately.
- a decide function—this implements the business logic for the state and returns the next state to progress to.
Starting Workflows
Using state definitions, we can build a workflow by defining all its possible states, and a client can start a workflow by using the workflow definition and defining the starting state.
The iWF server receives this request, processes the arguments, and then makes a downstream call to the Cadence cluster. This call is made using the standard Cadence client SDK.
From here, the iWF server orchestrates calls between itself and the iWF client via REST API calls.
Example Walkthrough
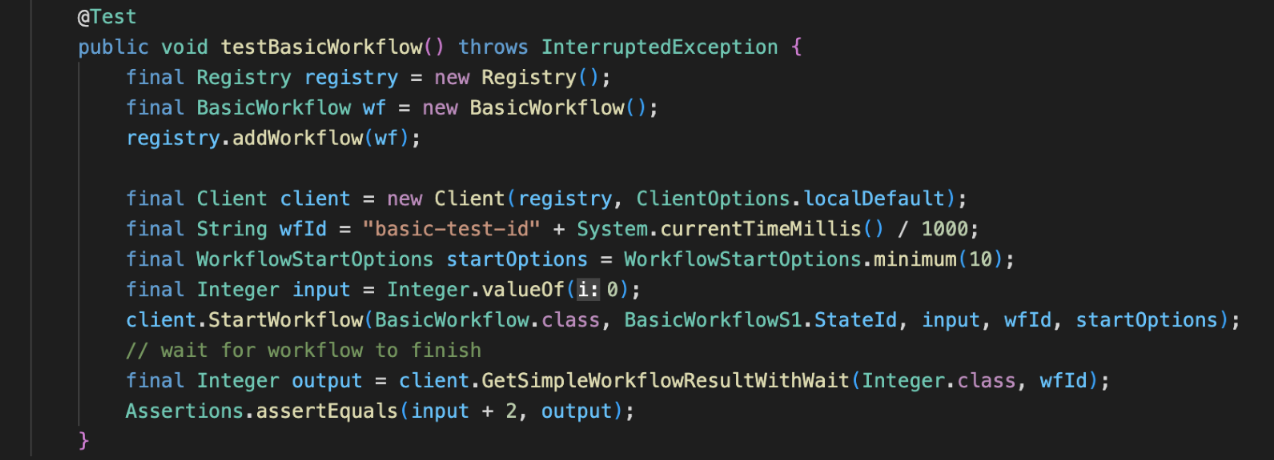
In the above sample code, our client invokes a BasicWorkflow, starting at the BasicWorkflowS1 state with an input value of 0. Cadence receives the request and then starts orchestrating the workflow activities, communicating with the iWF Server. Then the iWF Server and iWF Client coordinate the execution of the workflow states by calling each other’s REST API.
In our example, BasicWorkflowS1 will take the input value of 0 and increment it by 1. The function returns the next state to move to, BasicWorkflowS2, and the parameters for it.

The cycle continues for BasicWorkflowS2. This is the final state for our sample workflow, so instead of progressing to the next state, it simply returns the result and completes the workflow.
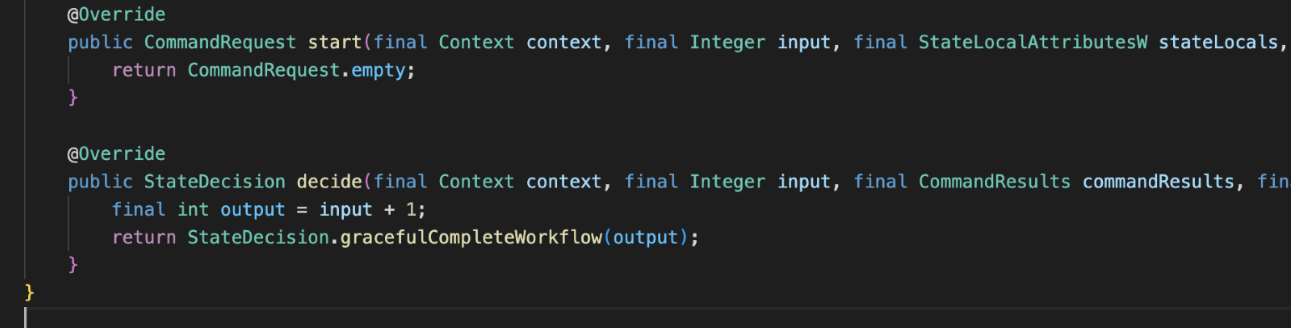
The client, which is waiting for the result, receives it and then completes.
iWF Benefits
Now that we have a basic understanding of how iWF works, let’s look at some of the differences between it and native Cadence.
Client SDK and REST API
The first interesting thing about this solution is that the iWF Client code has no knowledge of the Cadence cluster or the Cadence SDK. All the communication with the iWF Server happens via the REST APIs.
This key detail means it would be significantly simpler to create iWF clients in any language, as REST libraries are everywhere.
In contrast, when creating new Cadence client libraries, we need to implement the gRPC interface and become intimately familiar with the operation of Cadence and its commands to get it off the ground in a new language.
This means that iWF has the potential to lower the barrier to entry for people looking to join the Cadence community.
Removing the Non-determinism Requirement
One of the most important requirements when writing Cadence workflow code is that it must be entirely deterministic; given the same inputs and activity results, it should always return the same result.
The reason being is that if a Cadence worker fails, the workflow state is recovered by replaying the workflow logic and restoring activity results.
If the code in the workflow isn’t deterministic, it’s possible the result could change which means that your workflow would not recover correctly. Let’s look at a very simple example.
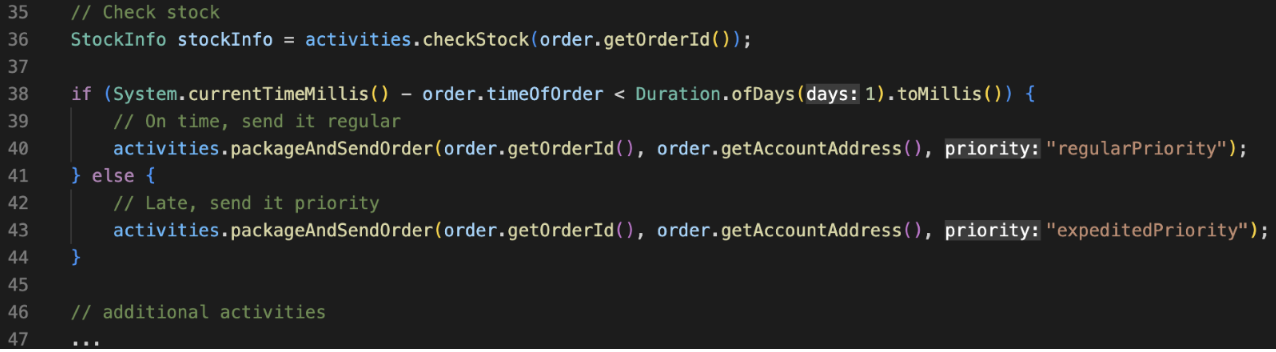
In this example, we receive the stock information (line 36) then decide how quickly we need to send a notification.
- If the order was made within the last day, it’s on time and we send it regular mail.
- If it’s older than 1 day, it’s late and we send it priority. (Lines 38-41).
This code looks fine, it’s a simple decision tree, but for Cadence there is a problem.
If the worker fails further down the workflow, the state will be rebuilt on a new worker when it comes online. If the new worker recovers 12 hours later, when rebuilding the state, this decision may end up with a different result—it was previously on time but now it’s late!
If that happened, Cadence would realize the activities attempting to be called are different to what is in the history, and it throw a non-determinism error and the developer will have to figure out what happened.
This is a simple example but even so it’s not necessarily obvious there is a problem. There is currently no Cadence linter that will alert you to these issues, so they are easy to make.
iWF solves this because it essentially removes the workflow code itself. An iWF state, as Cadence sees it, is an activity. It will return a result which is the next state to move to. Once complete, this result is persisted in Cadence.
If the iWF worker dies and comes back, the activities are replayed and since they are all persisted in Cadence, it’s not possible for the result to change.
This could be a huge benefit and save a lot of headaches for Cadence developers, new and experienced.
Removing the Versioning Requirement
Another issue that can be particularly difficult is versioning workflows. At some point the logic in a workflow will need to change, because of changing requirements or a bug is found, and it can be tricky to update when there are thousands of workflows already in flight.
Cadence provides a versioning API to handle version control, which allows workflows to incorporate diverging code depending on what version it is currently running and ensure everything remains deterministic.
Still, it would be easier if a developer didn’t have to think about this at all, and iWF solves this problem as well.
Let’s look at another example.

Above is our code for BasicWorkflowS1 and it works as we expect. But suddenly we need to change how the workflow operates, and we update it to this:

We’ve introduced a new possible state to move to depending on the computed result of output.
In iWF, we redeploy our client and that’s it, there’s nothing left to do. As mentioned above, iWF workflow states are executed as activities in Cadence, they benefit from all the guarantees Cadence provides. Individual activity execution results are immutable and persisted.
If our workflow ran BasicWorkflowS1 before the update, failed, and restored after the update, it would be unaffected. The history of the workflow is replayed out of the Cadence persistence store and the original result is returned, which would be to move to the state BasicWorkflowS2.
Any new execution of BasicWorkflowS1 would incorporate the changes and could return BasicWorkflowS3.
This is another potentially huge benefit for iWF, removing the backwards compatibility concern of complex workflows.
iWF Downsides
All the above-mentioned benefits do come with some cost—there’s no such thing as a free lunch after all!
While attempting to port a sample workflow from Cadence native to iWF, we ran into a few problems that made it cumbersome to use.
Workflow Code Structure
One of the key benefits that Cadence provides to developers is that workflow code is “normal looking” code. Non-determinism can be challenging to keep track of, but if you show a developer a workflow class, it will be easy to understand the business requirement being addressed because the code is easily understood.
iWF changes this structure, instead of a single class, business logic is spread between the various state classes and chained together. Attempting to understand the business logic is difficult because you must switch between files, and then if you encounter a decision you need to trace down one tree and then potentially back up and down into the other.
This problem is doubly annoying when you are writing the logic. iWF state definitions return a result which is a reference to the next state. In Java, this means we need to at least create the file for the next state before we can finish the first one, then we need to ensure we get the correct parameters.
This doesn’t sound too bad on paper, but in my experience, it was quite annoying and difficult to keep track of everything.
Workflow Contextual Data
Another problem was how we make values available to downstream states.
Take this Cadence native workflow code
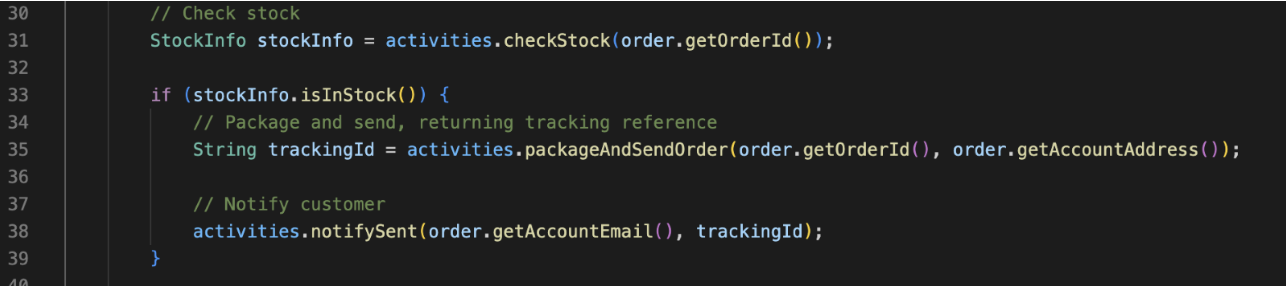
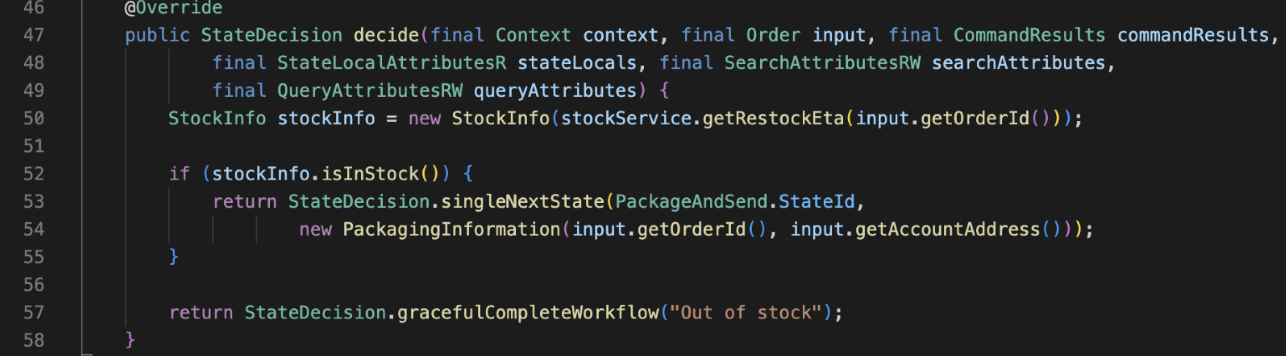
In iWF, we would represent this as 3 states, 2 of which have their decide function shown here:
CheckStock
PackageAndSend
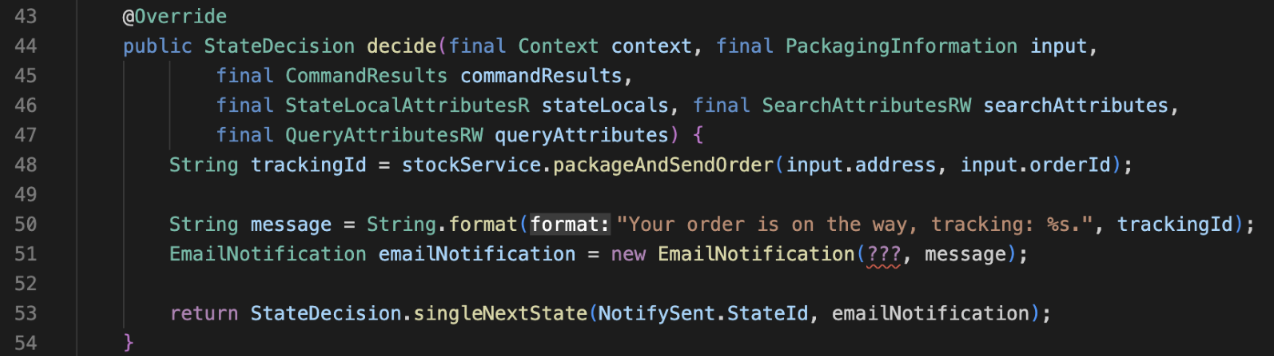
On line 51 of PackageAndSend we see the problem. I want to progress to the NotifySent state, but it requires an email address to send to.
The PackageAndSend state doesn’t know the email address—and it shouldn’t! It doesn’t need that information to complete its requirement. But if I want to progress, I need it to.
Another option, the NotifySent state could call a service to discover the email address for the given order Id—if NotifySent even expects an order Id!
We already had the email address when the workflow was started so we either pass it down a chain of functions until it’s needed, or we re-discover it when it’s needed. Neither solution is particularly appealing.
In contrast, the Cadence native solution has a running context because it’s a normal java function. Activities are only ever 1 step removed from the workflow context and all the relevant variables, so we can write regular, efficient code.
Another Alternative: Combine into One State
The interface pattern used by Cadence encourages users to build activities that encapsulate a single concern like we have above: Checking stock, notifications, packaging, and sending.
I believe this is the optimal way to design your workflows, and it allows them to take full advantage of Cadence.
However, it’s not mandatory. An activity can execute any logic you want, including making multiple API calls if you decide that is a fair encapsulation of the work you want to perform.
If we take that approach, we can avoid some of the downsides of iWF by combining all the logic into a single state. This would resolve having to manage multiple files and would also allow us to keep contextual data together.
Conclusion
The Interpreter Workflow engine is a very interesting project. In this article we have taken a surface level look at some of the benefits and downsides of using it to drive Cadence workflows.
The iWF project is clearly in the early stages of development, and some of the rough edges will certainly get smoothed out over time and some of the annoyances I have with it will go away.
Additionally, there is nothing preventing someone from taking advantage of both Cadence native client/workers and iWF based ones. They are not mutually exclusive and there will be scenarios where one is a better fit than the other.
As a Cadence and Open Source evangelist, I think that the iWF project espouses the best aspects of the community and what it means to work with Open Source technologies.
Hopefully you will join Instaclustr and follow along with the project as they iterate and improve—or jump in and start contributing today!