Overview
In this post, we’ll be running a basic Apache Spark job that selects data from a Cassandra database using a couple of different methods. We will then examine how to compare the performance of those methods using the Spark UI.
Setup
For this post, we will use a Zeppelin+Spark+Cassandra cluster. If you’d like to try this out for yourself, you can create an account and a free 14-day trial cluster here.
The code snippets used are available in Instaclustr’s Github site as a ready-to-go Zeppelin notebook.
Inserting Data
To start things off, we will create a test keyspace and table in our Cassandra cluster, via Zeppelin (we’re using Zeppelin for this because it provides a nice, quick GUI for CQL queries):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
%cassandra // Step 1: Create table CREATE KEYSPACE IF NOT EXISTS spark_demo WITH REPLICATION = { 'class': 'NetworkTopologyStrategy', 'AWS_VPC_US_EAST_1': 1 }; CREATE TABLE IF NOT EXISTS spark_demo.test( key int, letter text, value text, PRIMARY KEY(key, letter) ); INSERT INTO spark_demo.test (key, letter, value) VALUES (1, 'a', 'test 1'); SELECT * FROM spark_demo.test; |
Now that the table has been created, let’s populate it with some test data:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
%spark import com.datastax.spark.connector._ import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.SparkContext._ // STEP 2: Populate data var testData : List[(Int, String, String)] = List() var i : Int = 0; val letters = Array("a", "b", "c", "d", "e", "f", "g", "h", "i", "j") val r = scala.util.Random for( i |
And then run a quick select query to make sure it looks as expected:
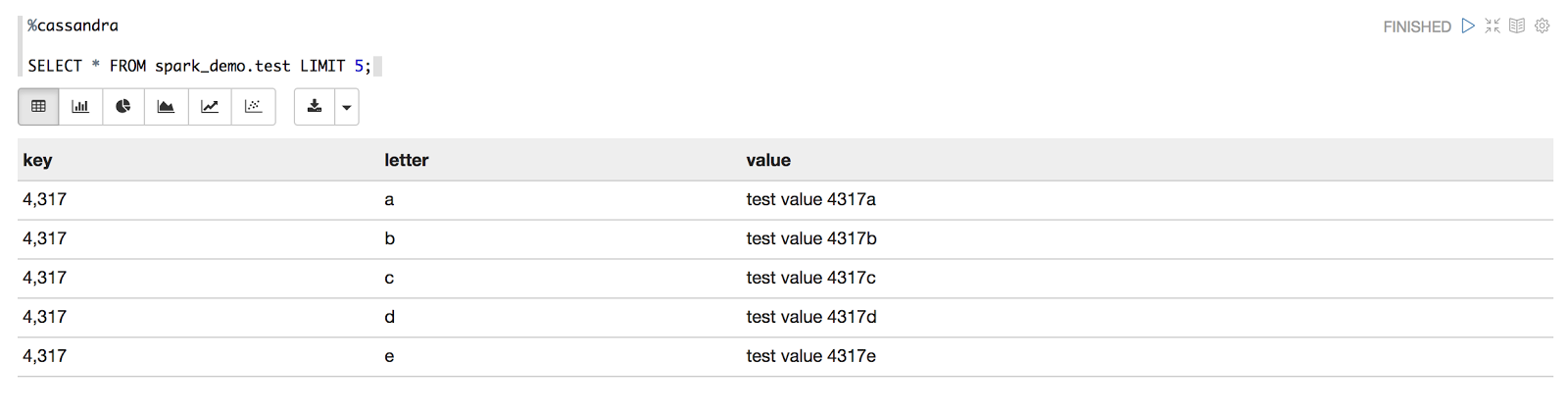
Retrieving Data
Now that we’ve got some test data, we’ll run two different methods of selecting data from the Cassandra table.
Filter
For the first method, let’s use Spark’s filter transformation to pull the data back from the “test” table to the executor, then find a partition key and then show the “letter” values for each row.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
%spark // Step 3a: Filtering using Spark import com.datastax.spark.connector._ import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.SparkContext._ val letterCountRdd = sc.cassandraTable("spark_demo","test") .filter(r => r.getInt("key").equals(1)) .map(((x: CassandraRow) => x.getString("letter"))) .map(letter => (letter, 1)) .reduceByKey{case (x, y) => x+y} println(letterCountRdd.toDebugString) letterCountRdd.collect.foreach(println) |
In addition to the letter counts, we’re also showing the RDD dependency graph (the steps required to generate my letterCountRdd) using the toDebugString method.
toDebugString uses indents to indicate shuffle boundaries (transferring data between executors), so for the lowest indent the output is showing that to generate the letterCountRdd each executor will need to:
- Perform a Cassandra table scan
- Filter all of the retrieved rows
- Retrieve the “letter” of each row
- Create tuples for each “letter” value
The transformed data is then transferred back to an executor for the reduceByKey transformation to be performed.
Spark UI
Moving across to the Spark UI, we can navigate to the Jobs page and select the Job that just ran:
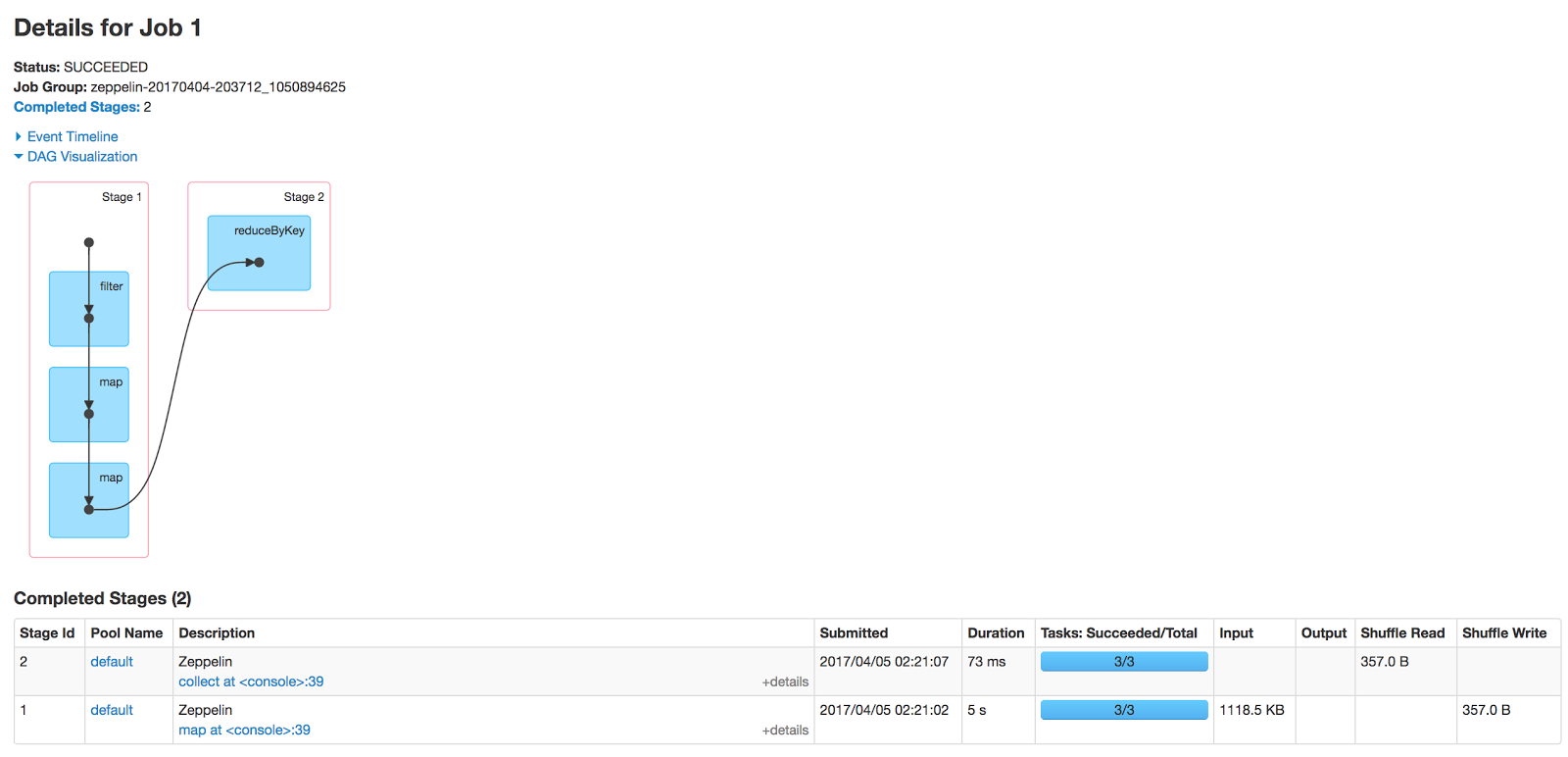
From here, we can see that the Job took over 5 seconds to complete and the bulk of that time was spent in Stage 1, gathering and filtering 1,118.5 KB of data (the DAG visualization also shows a nice graphical summary of the RDD lineage).
5 seconds and a megabyte of data seems like a lot for the single partition that we’re expecting to return. We can click on the Stage 1 link to show further details of the filtering:
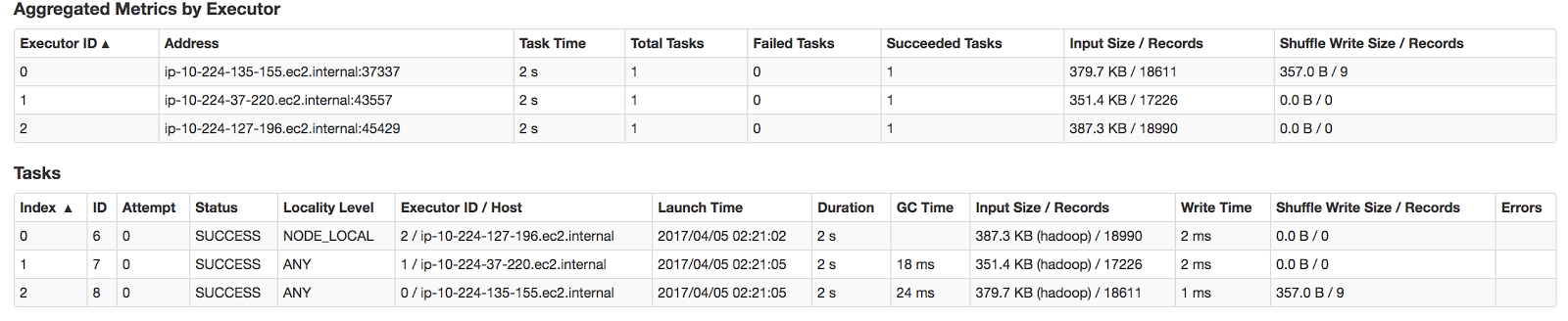
Amongst other things, the Tasks table is showing that all three of our executors processed the Stage pipeline and performed full Cassandra table scans (something that should generally be avoided), with only one of them (ip-10-224-135-155.ec2.internal) actually ending up with any data.
Where
For the second method, let’s use the Spark-Cassandra connector’s select and where methods to (hopefully!) reduce the amount of data that needs to be transferred:
- The
wheremethod informs the connector of which partitions are required and therefore which nodes need to process the task - The
selectmethod is retrieving only the column (letter) we’re interested in
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
%spark // Step 3b: Pushing filtering down to the Cassandra node import com.datastax.spark.connector._ import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.SparkContext._ val letterCountRdd = sc.cassandraTable("spark_demo","test") .select("letter").where("key = ?", "1") .map(((x: CassandraRow) => x.getString("letter"))) .map(letter => (letter, 1)) .reduceByKey{case (x, y) => x+y} println(letterCountRdd.toDebugString) letterCountRdd.collect.foreach(println) |
You can see that we’ve swapped out filter for this line:
.select("letter").where("key = ?", "1")
In the toDebugString output, it’s showing that the previous filter transformation has been completely removed, as that work has now been pushed down to the Cassandra nodes.
Spark UI
Moving back to the Spark UI, the details for this new Job reflect that the filter transformation has been dropped. More importantly, the total time has been reduced to 0.5 seconds. There’s not much difference in the reduceByKey durations (73 ms vs. 27 ms), so lets inspect Stage 1 again:

This time, only one executor has been initialized because the connector was aware of exactly which node the required partition resided on. In addition, as Cassandra was only returning the “letter” column for partition “1”, the Stage Input Size was lowered to 9 bytes.
Conclusion
Hopefully, this post has provided an interesting summary of how we can debug applications using the Spark UI! If you have any questions or feedback, please comment! or feel free to contact us directly.
Related Guides:
- Apache Kafka: Architecture, deployment and ecosystem [2025 guide]
- Understanding Apache Cassandra: Complete 2025 Guide
- Complete guide to PostgreSQL: Features, use cases, and tutorial