In this blog (parts 6.1 and 6.2) we deploy the Kongo IoT application to a production Kafka cluster, using Instraclustr’s Managed Apache Kafka service on AWS. In part 6.1 we explored Kafka cluster creation and how to deploy the Kongo code. Then we revisited the design choices made previously regarding how to best handle the high consumer fan out of the Kongo application, by running a series of benchmarks to compare the scalability of different options. In this part (6.2) we explore how to scale the application on the Instaclustr Kafka cluster we created, and introduce some code changes for autonomically scaling the producer load and optimizing the number of consumer threads.
Scaling Kongo for Production
As a result of the benchmarking in 6.1 we are more confident that the design we used, Option 3, is a good choice for the production version of Kongo.
For production, some extra changes were made to the Kongo code including:
- Adding the Kafka broker bootstrap server IPs and the SCRAM username/password;
- Adding the ability to spin up multiple consumers for Sensor and RFID topics;
- Introducing a wait before starting the simulation to ensure the target number of Consumers are created and working
- Introducing a timeout for the Sensor and RFID consumers to ensure that they have processed all the available events before closing down correctly
- Adding latency and throughput metrics for producers, consumers, and total events.
- Latency is measured in a similar way to the benchmarks (time from event production to being sent to each Goods object at the same location as the event).
All seven topics produced or consumed by Kongo were created manually with sensible default partitions (9 to start with).
The goal is to deploy Kongo and achieve maximum throughput and minimum end-to-end latency.
Initially running Kongo with guessed fixed numbers of consumers highlighted several problems:
- The producer was running flat out and overloaded the Kongo cluster. This introduced long delays between event production and consumption, and an inability to increase the number of consumers with any meaningful results.
- It’s hard to guess the correct number of consumer threads. They may need to be higher than guessed, and may not be in the exact ratio of the number of events received by each consumer type (5:1 RFID to Sensor ratio) as each consumer type may take a different time to process events.
Here’s the Sankey diagram showing the fan-out problem and different rates of rfid and sensor events from a previous blog:
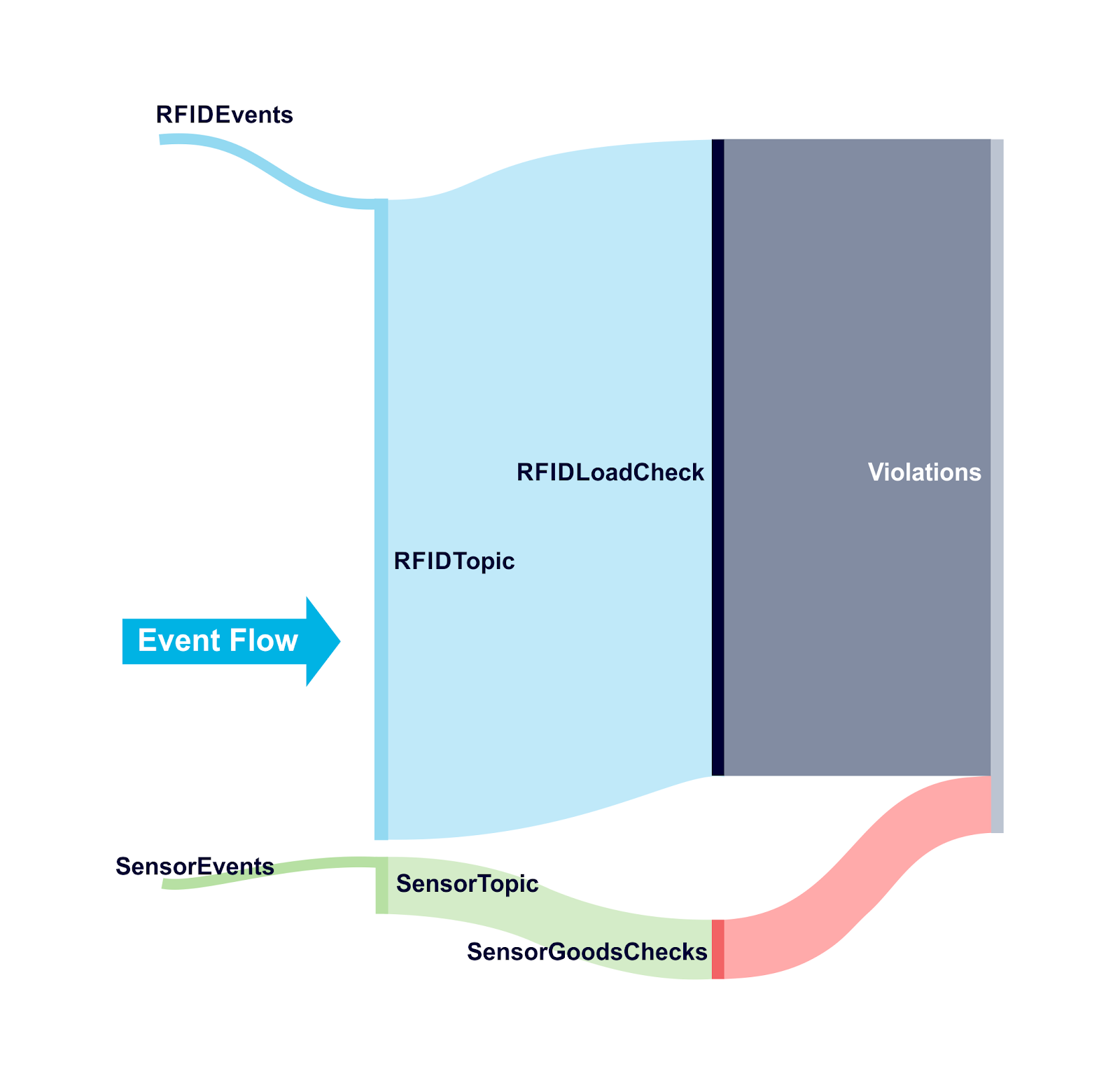
To manage the 1st problem I added a “sleep” to the Kongo simulation code to run a simulated hour and produce the output, and then delay for a while before repeating. This enables us to limit the producer throughput, and ensures that the consumers can consistently keep up with the production rate.
There are at least three approaches to solve the 2nd problem and optimize the production rate and the number of threads for each consumer type.
The first is to benchmark all the possible permutations (i.e. production rate, number of consumer threads, latencies, throughputs, etc.). I started out doing this and soon realised it was too Kafkaesque in practice, as it was time-consuming and difficult to obtain consistent results.
A second approach could be to use simple performance modeling to calculate the number of consumer threads required in advance and then just set them to this number. This is certainly possible in theory, e.g. using Little’s law which relates concurrency in a system to the response time multiplied by the throughput. The number of threads for each consumer is the average time spent processing each event times the throughput. For example, 80 is the number of Sensor Consumer threads predicted for a response time of 40ms and a throughput of 2,000 TPS. But accurately measuring the response time is tricky (you only want the time spent processing each event on the consumer side, not any delays due to queuing etc).
I therefore settled on a third option, an “autonomic” version of the Kongo application. I added code to slowly ramp up the production event rate, and automatically increase the number of consumer threads as latency increases beyond a threshold. The rate is only increased again once the latencies are consistently below the threshold, and reverts to the last sustainable rate again if the SLA cannot be achieved with increased consumers.
The number of partitions was increased to 300 for Sensor and RFID topics to ensure that this approach didn’t hit any partition related limits. The following graph shows the number of sensor and rfid consumer threads started for increasing producer event rates using this approach (with linear extrapolation above 20,000 events/s):
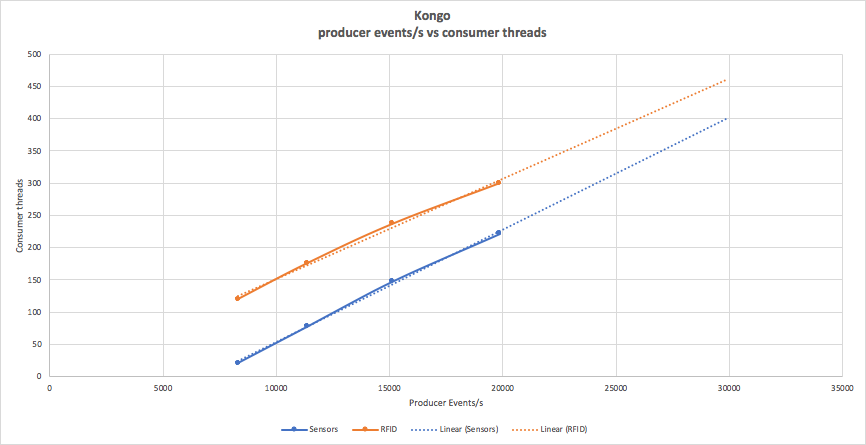
What’s interesting about these results? As expected, the number of threads for each consumer type is different, and increases with the producer rate. The ratio of RFID:Sensor consumer threads starts out higher (6:1) than predicted (5:1) but reduces to 1.3:1 (i.e. as the producer rate increases the number of sensor and rfid consumer threads tends to converge).
What’s not obvious from this graph is that Kongo is actually producing “secondary” producer events. As the application receives sensor and rfid events it checks for Sensor+Goods and Goods+Truck Location violations, and sends violations events to another Kafka topic. Currently these events are not being consumed, but are in the Kafka connector and streams extensions (disabled for these initial tests). On average (it differs across runs) the ratio of secondary producer events (violations) to primary producer events is about 1.2:1.
The following graph shows the full picture. The X axis is primary producer event rate, and the Y axis shows the rate for consumers, secondary producers, and total events in and out for the cluster. The total load is approximately 3.2 times the primary producer rate.
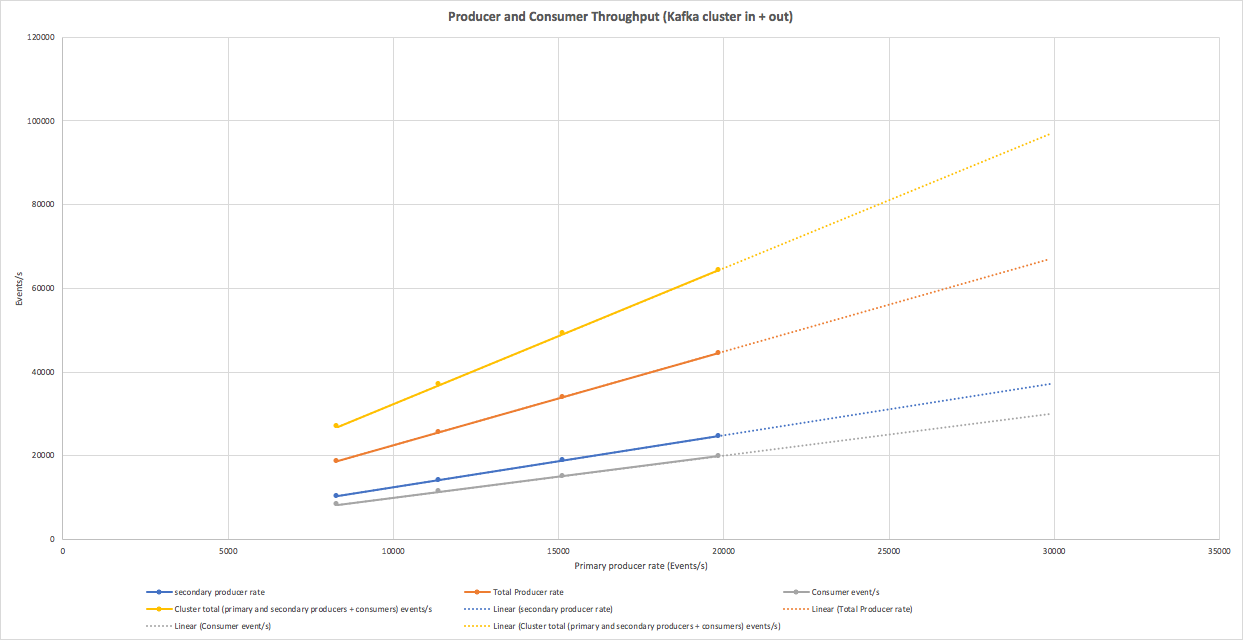
Extrapolation predicts that at 30,000 events/s primary producer load the total load will be close to 100,000 events/s. This has obvious implications for how the Kafka cluster and the Kongo application will need to scale as the load increases.
As one final check I decided to run Kongo at close to the maximum producer load with the predicted number of Consumer threads for an extended period of time (i.e. a soak test). It turns out there were still a few more surprises in store.
Creating lots of consumers takes time, and you can’t just create them all at once. I needed to add a delay between each consumer start to ensure that all the consumers were created successfully before the simulation starts.
The other problem was somewhat surprising given that the benchmarking had previously worked on the identical setup. Just before reaching the target number of consumer threads I started seeing this exception:
org.apache.kafka.common.KafkaException: java.io.IOException: Too many open files
Instaclustr techops assured me that the Kafka cluster still had plenty of spare file descriptors, so the problem was obviously on the client side. Further investigation revealed that the default number of open files for AWS Linux is only 1024 which I was exceeding.
You can increase the number of open files on AWS Linux by adding these two lines to the /etc/security/limits.conf file (nofile is the maximum number of open file descriptors):
ec2-user soft nofile 10000
ec2-user hard nofile 10000
Then logout and login and check with ulimit -n.
This worked and the Kongo application ran for several minutes at the sustained rate of 17,000 production events/s, with 222 Sensor and 300 RFID consumer threads, giving a median consumer latency of 1000ms and 99th percentile of 4800ms.
Scaling Conclusions
A small Instaclustr Kafka Production cluster is good for exploring application and Kafka cluster sizing questions before ramping up to a bigger cluster. The Instaclustr Kafka Production clusters on AWS all use r4 instances which provide predictable performance for benchmarking (and production). By comparison, the Instaclustr Kafka Developer clusters use t2 instances which provide burstable CPU, but they are limited to the base rate (e.g. 20% for t2.medium) when the CPU credits are used. These are good for application debugging and testing but not ideal for benchmarking as performance can be unpredictable.
Benchmarking some of the Kongo design options, using an autonomic version of Kongo to find the maximum throughput and optimal number of consumer threads, and final “soak” testing to find any final surprises gives us confidence that we will be able to scale the Kongo application on a larger Instaclustr Kafka cluster.
An alternative way to manage high consumer fan outs is to freeze the flow!
 Lena Delta in winter (Source: NASA Earth Observatory)
Lena Delta in winter (Source: NASA Earth Observatory)