In this second part of the Apache Kafka Castle blog we contemplate the being or not being of Kafka Event Reprocessing, and speeding up time!
Reprocessing Use Cases
Reprocess:
/riːˈprəʊsɛs/
verb
Process (something, especially spent nuclear fuel) again or differently.
Repeat event processing is called reprocessing (or sometimes replaying or rewinding), and some reprocessing use cases driving the evolution of Kafka are documented here. For the purposes of generality, I’ll also include examples of other temporal distortions in this blog (e.g. out of order processing, skipping events, etc. i.e. anything that deviates from processing each event once only in order).
Let’s explore some use cases for event reprocessing, starting with “normal” (non-failure) use (a Netflix clone).
Reprocessing Use Case 1 (Normal): Streaming Video to Many Consumers

(Source: Shutterstock)
An illustrative use case is using Kafka for streaming video (although you probably wouldn’t actually use Kafka for streaming video, as the latency requirements and larger than average message sizes may not be a good fit). This is, however, a good example for illustrating a “normal” reprocessing application resulting from having multiple consumers:
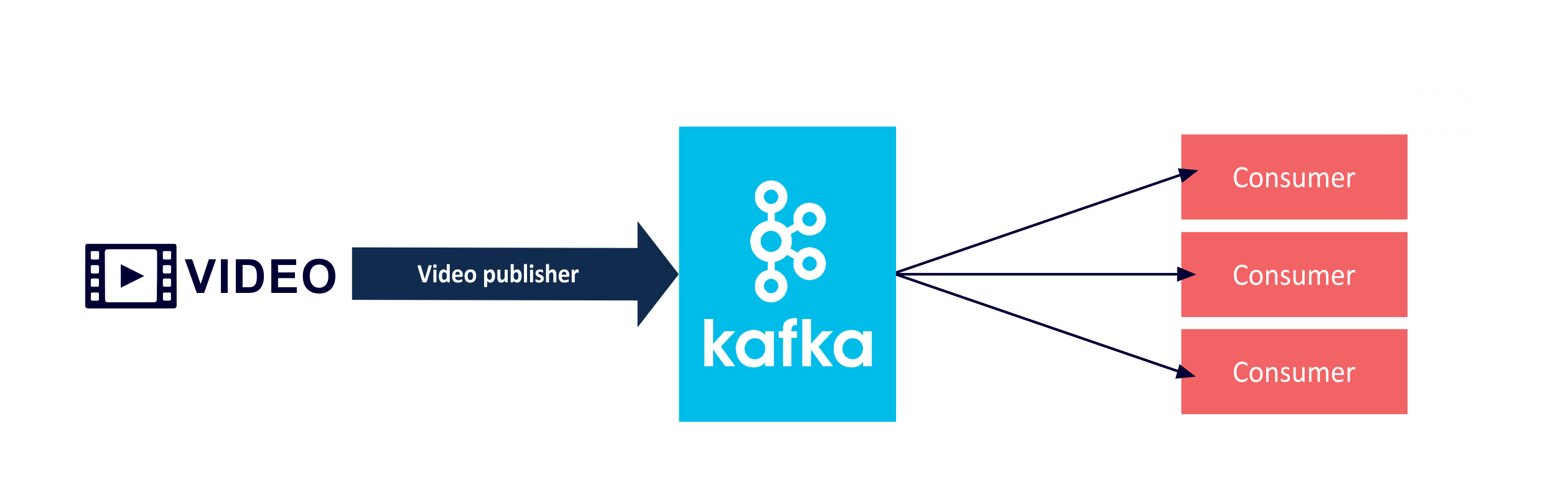
The requirements for streaming video are simple: Multiple consumers can view different parts of movies at once, consumers can start and stop watching anywhere, and rewatch movies multiple times. Videos are uploaded to Kafka topics by the streaming video provider (via Kafka publishers, one movie per topic). We assume that videos are divided into frames, with one frame per event. Once a movie upload has started to a topic, multiple consumers can subscribe to the topic and view the movie up until the (moving) point that the upload has reached. Once the complete movie has been uploaded the whole movie can be watched, from any position, multiple times, by multiple consumers.
Let’s explore some other reprocessing use cases. In order to illustrate what’s going on we’ll use a diagram for each use case. The orange table at the top of each diagram shows events being published to a topic, with the oldest (a) on the left and the newest on the right (j). During normal processing the consumer receives one event a time from left to right and processes it. The events processed during each “step” (1 to 10) are shown in the blue table at the bottom.
Here’s the diagram for the streaming video use case (normal reprocessing):
Apart from “normal” application uses for reprocessing (e.g. streaming video), other use cases are motivated by consumer choice, failures or changes including consumer failure, data failures, and application changes and alternatives.
Reprocessing Use Case 2: Normal Processing
We’ll start with the base case, which has no reprocessing at all, just normal processing (each consumer processes each event once only in order):
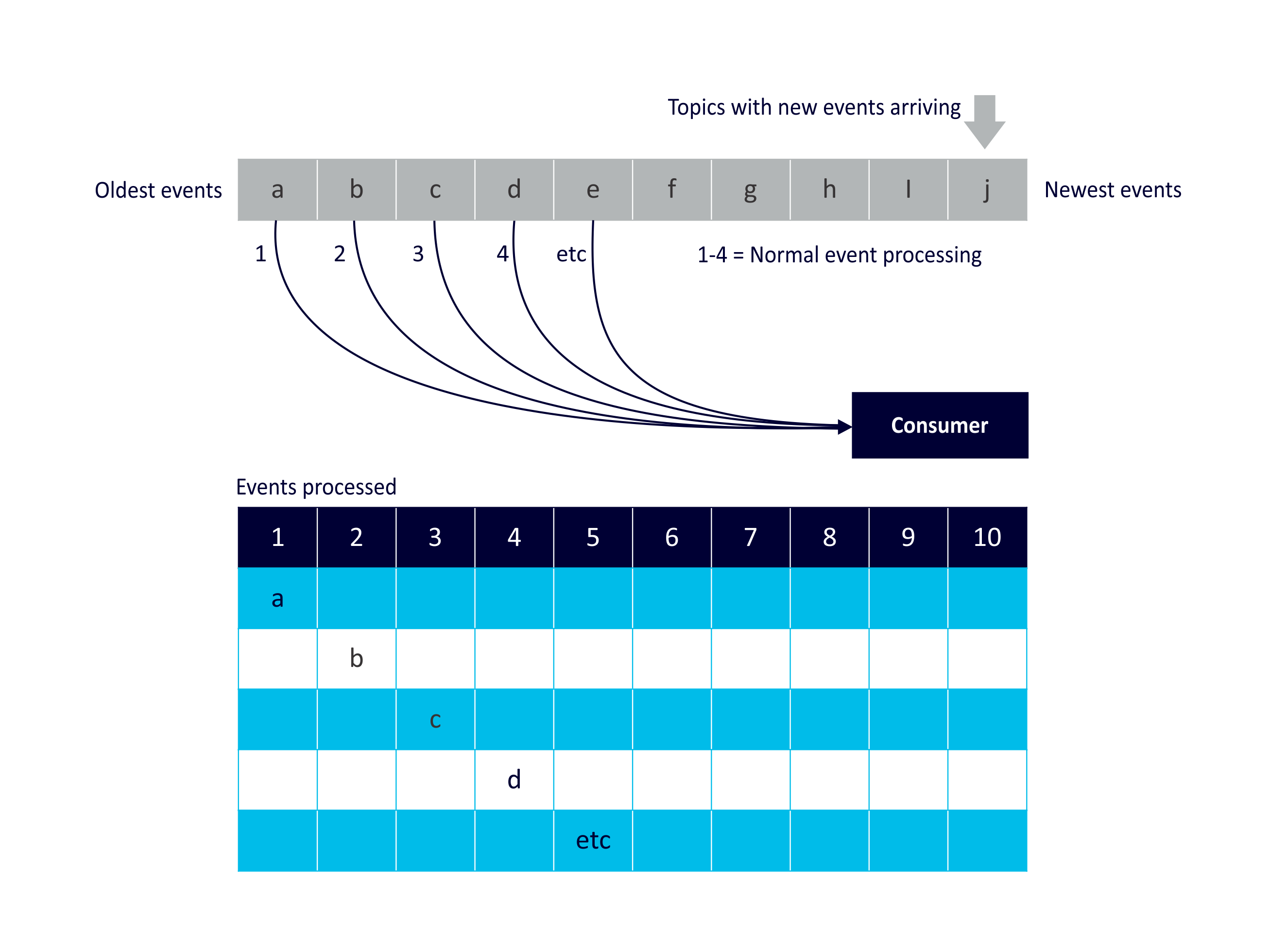
This is the simplest example and is useful to compare the more complex use cases against.
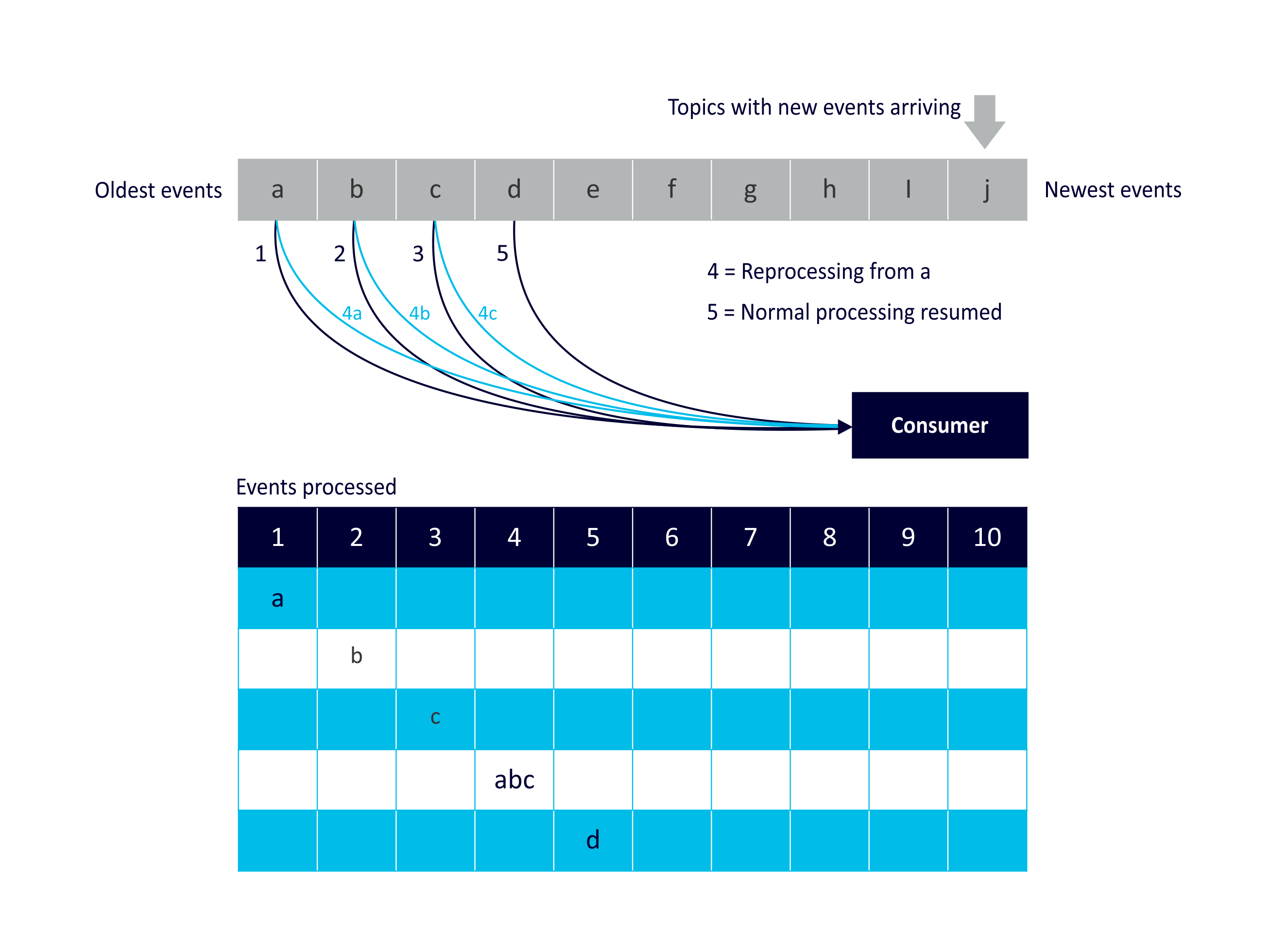
Reprocessing Use Case 3: Consumer Failure
Reprocessing of events due to consumer failure. Consumer fails during processing of event ‘c’, requiring reprocessing of event ‘c’ before resuming processing of ‘d’:
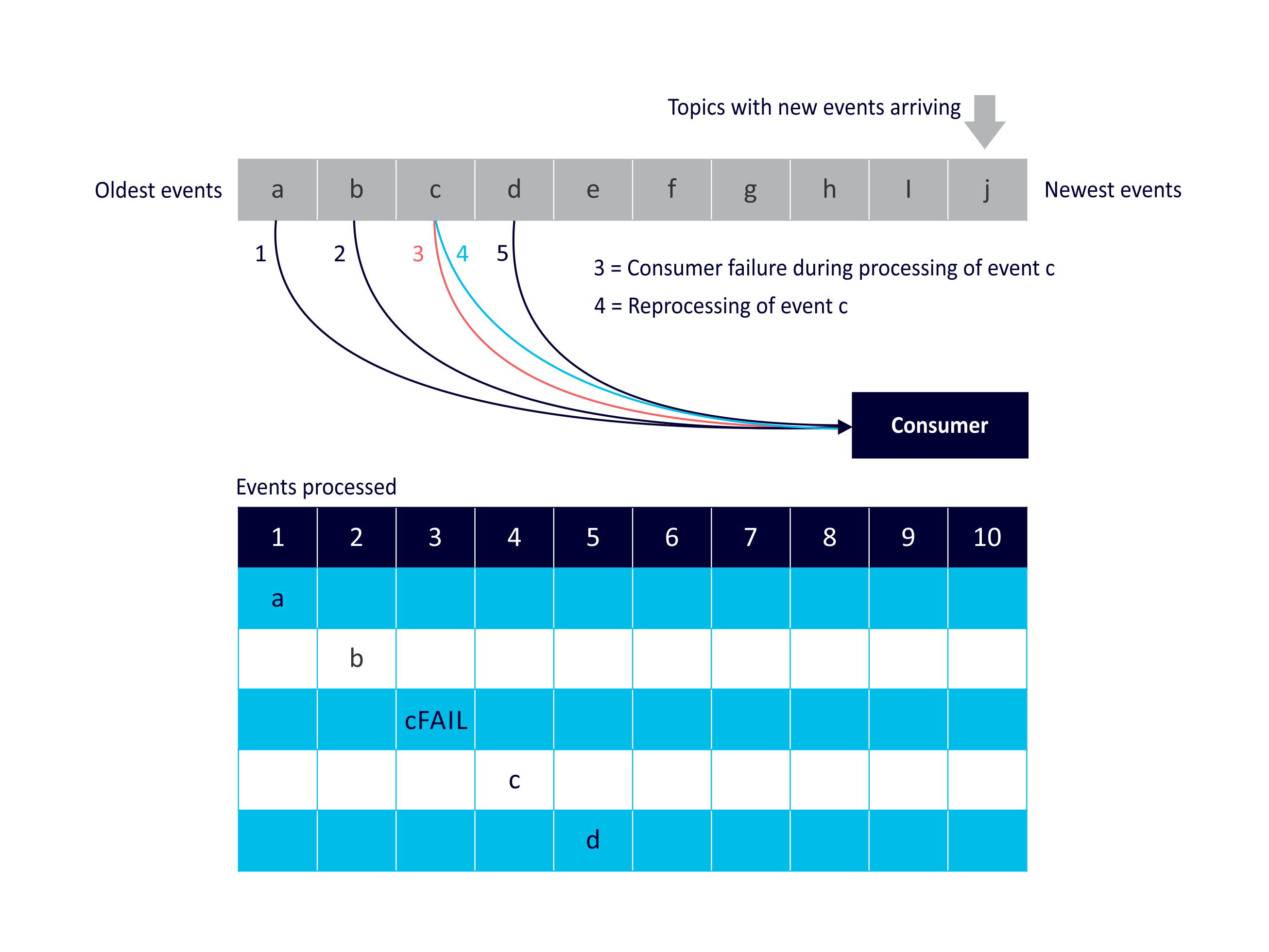
This use case is motivated by failure or unavailability of consumer(s). For example, failure of consumers (either due to failure of drivers, application code, network, etc) which may require reprocessing of events. This will also work with some non-Kafka consumers, for example Spark streaming. You can even use Kafka itself to store the Spark streaming offsets.
A common example of this use case is when consumers are managing stateful data (e.g. Kafka streams using KTables, which are created from streams, and redundantly maintained in Kafka brokers. If the consumer fails and/or wants to recompute the KTable state, it can rebuild the KTable by reprocessing the stream events.
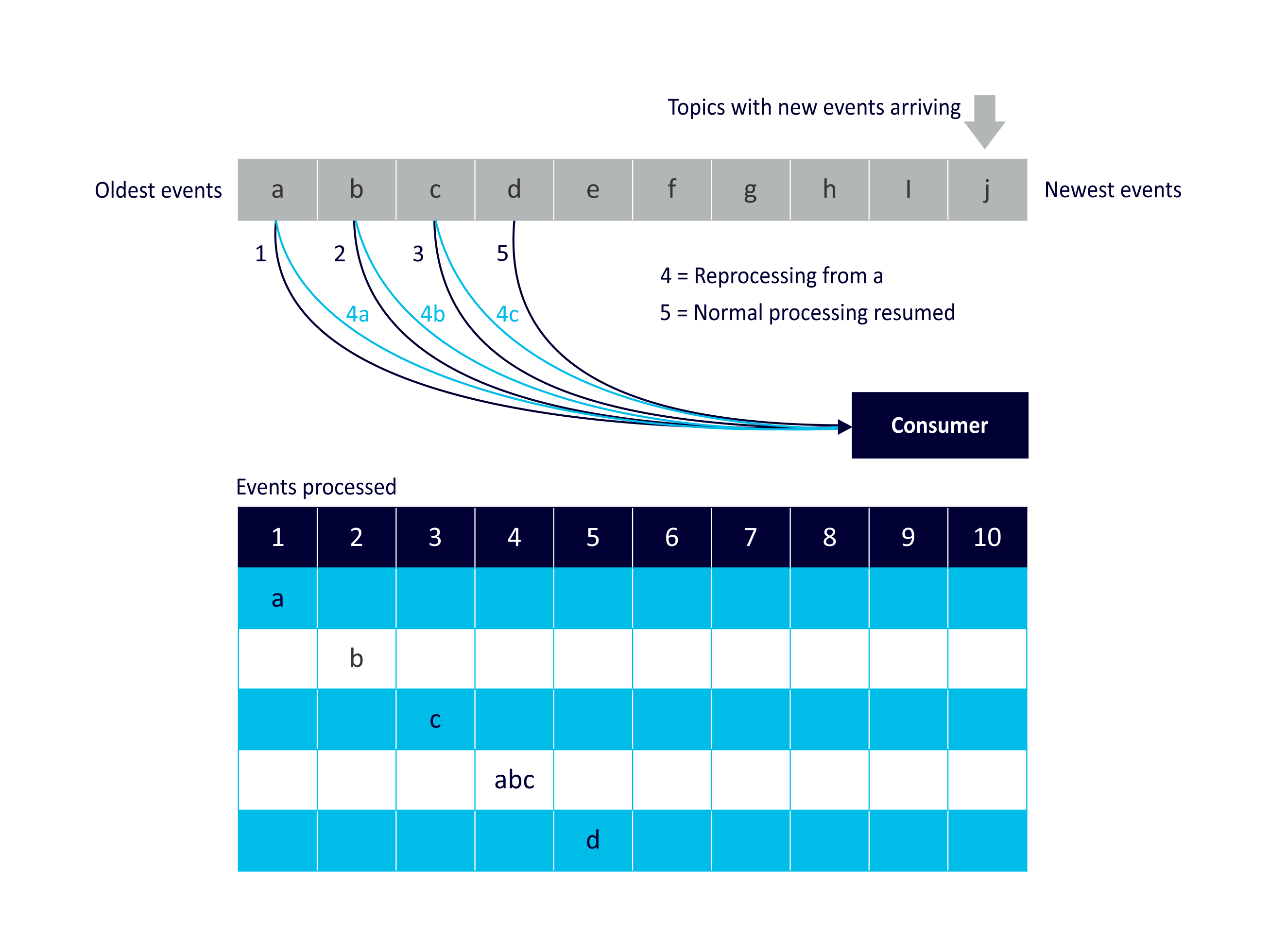
Reprocessing Use Case 4: Changes in Data
Reprocessing of events due to data changes or “errors”. In this example an out of order event. Event ‘a’ arrives out of order (after ‘c’), and consumer reprocesses events ‘a’, ‘b’, and ‘c’ before resuming processing of ‘d’:
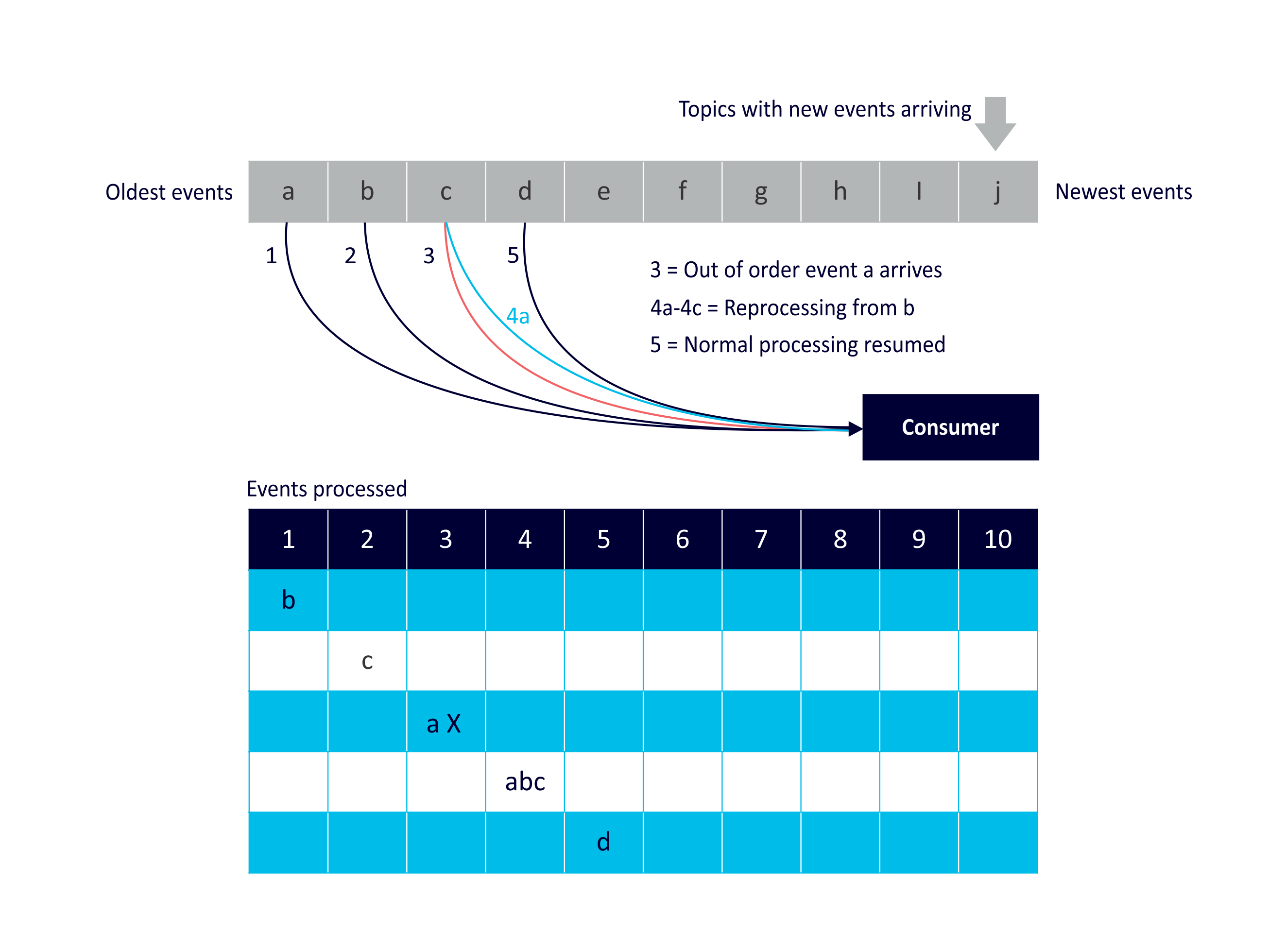
There are many scenarios involving problems with the event stream data itself that may require reprocessing. These include missing events, erroneous events, spurious events, fraudulent events, out of order events, late events etc. Sensors are distributed and are often connected over unreliable, intermittent or slow networks. This can mean that sensor events are missing for periods of time and never arrive, or delayed and arrive late or out of order. There can be problems with the sensors themselves. For example, sensors can get stuck and send the same value repeatedly, send incorrect or random values, miss recording significant events altogether (e.g. RFIDs out of range), etc. Other sensor types can suffer from noisy environment and give off spurious readings. Some events may even be spoofed. This all adds to up the fact that you can’t always trust the event stream, and the stream processing system needs to be designed to detect, ignore, raise-alarms, fill-in or infer, correct or even reverse deficiencies in event data.
Kafka magically handles late events, but how they are handled depends on the time semantics.
Reprocessing Use Case 5: Application Changes or Different Uses
Reprocessing of events due to application change:
Another common use case for reprocessing is due to changes in application code. Changes can result from bug fixes, improvements to the algorithms, or even just as part of normal DevOps. For example, A/B testing to compare different features. A similar use case results from using the data for multiple purposes possibly over different time spans. For example, for a logistics system some consumers process events in real time to keep track of deliveries and current state (e.g. locations, etas, etc), others may be looking for problems and produce warnings and/or correct them in real-time, others may be trying to optimise the overall system efficiency over hours or days, and others may validate that once a delivery has been made there were no problems during the delivery process. (e.g. for perishable or fragile goods).
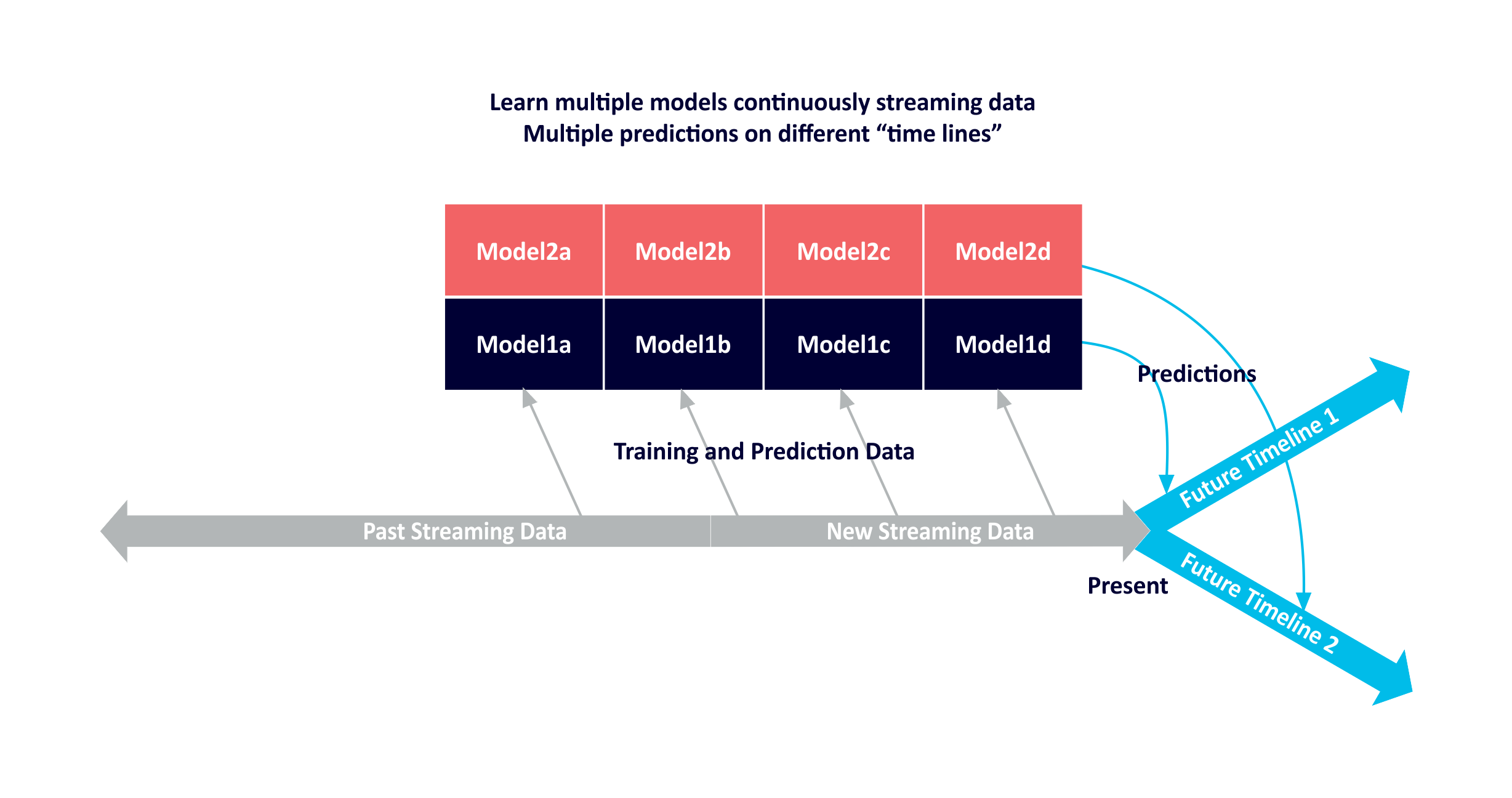
Reprocessing Use Case 6: Machine Learning Multiple Models
A concrete example of multiple uses of streaming Machine Learning. There are several different ways of using Machine Learning with streaming data.
- Learn models and test on past data (batch). Use with streaming data to make predictions. Use with streaming data to make predictions.
- Learn, test and update models continuously from streaming data. Use with streaming data to make predictions.
- Learn, test and update multiple models continuously from streaming data. Use with streaming data to make multiple predictions for different future timelines. Multiple models could be constructed to select the best model, or to compete with each other to improve the model accuracy (e.g. GANs), or could be used to predict different event types (e.g. regression models for numeric values, which could then be fed to a categorisation model to predict future failures). A separate topic would be used for each model prediction, along with a custom future timestamp extractor.
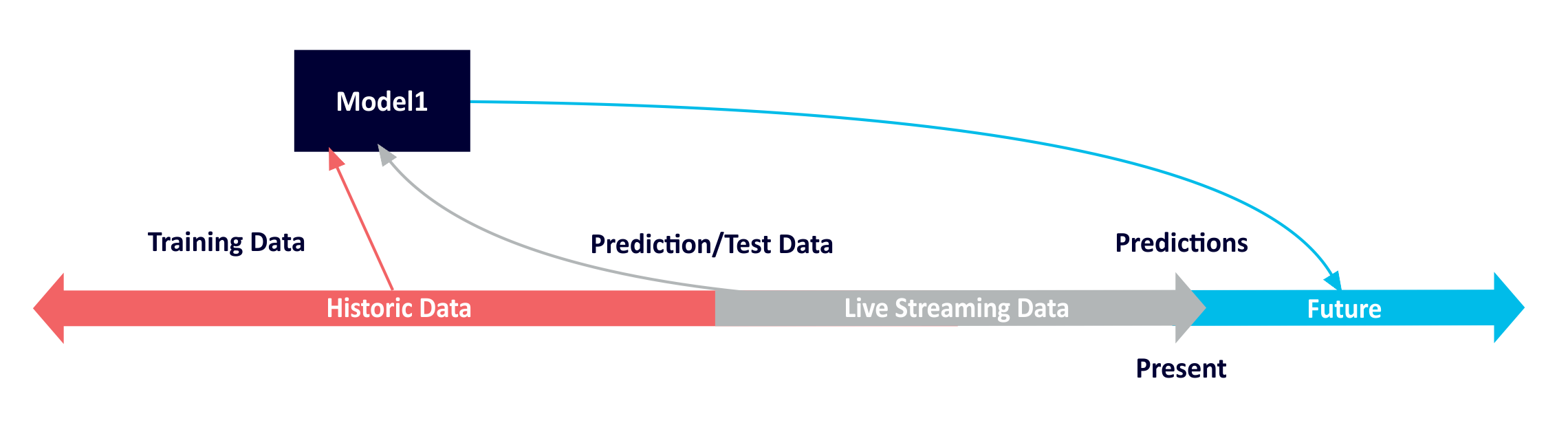
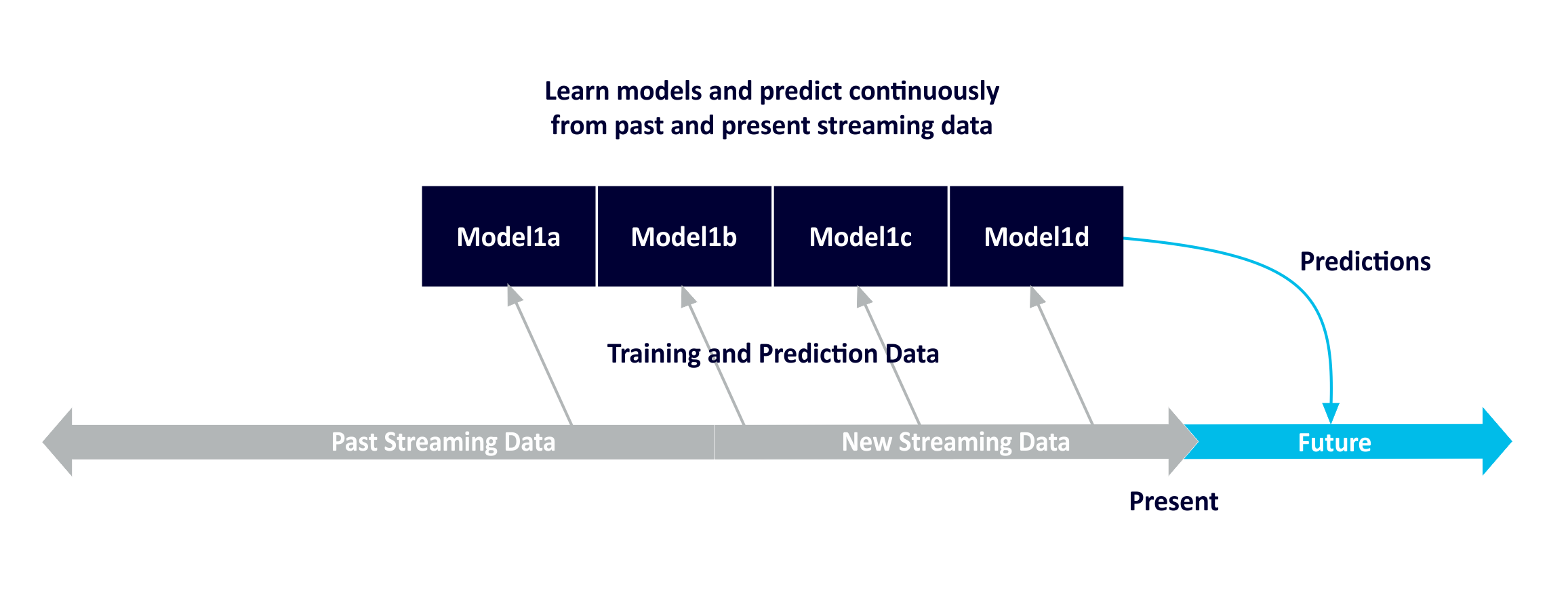
Further reading: Linkedin reprocessing scenario (ML)
Reprocessing Can Make Time Go Faster!
 (Source: Shutterstock)
(Source: Shutterstock)
A possible downside with reprocessing events is that it normally takes extra time and resources. However, it can also make time go faster than real-time!
We’ll use these Linkedin Kafka benchmarks (somewhat old, on a 3 broker cluster, Intel Xeon 2.5 GHz processors, six cores) to estimate how long reprocessing takes. For small messages (<1KB) a 3 broker Kafka cluster with 3 consumers reading from the same topic (with 6 partitions) can easily scale to 250MBs and 2.6M msgs/s. There is about a 20% overhead if a producer is publishing to the same topic, so the consumer throughput would be reduced to 200MBs and 2M msgs/s. Scalability with increasing consumers is linear so the throughput can easily increase. The reprocessing time (minutes) for different amounts of data (window size in days) is shown on the following graph (assuming a message size of 100 Bytes). The Instaclustr central logging system (our in-house production trial of Kafka) produces around 5k msgs/s, so we’ll use 10k msgs/s as a realistic target.
On these assumptions, we can see for example that 4 days worth of data can be reprocessed in around 30 minutes. The reprocessing rate is 200 times faster than the window time (i.e. we can fast forward reprocessing time by 200 times the wall-clock time!)
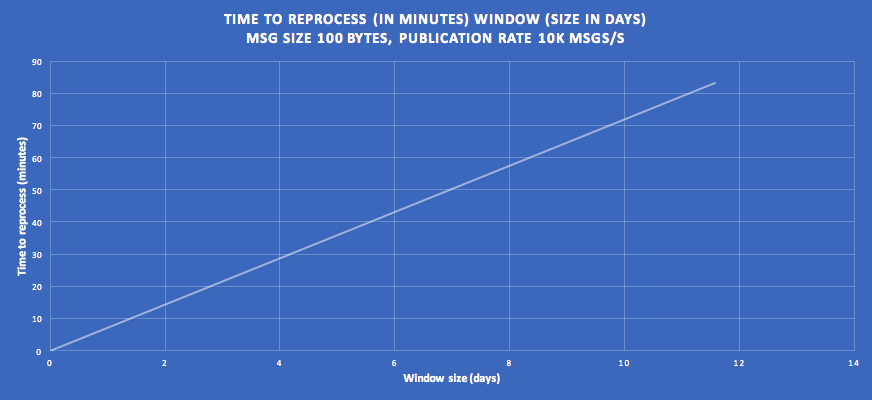
Reprocessing becomes impractical when the reprocessing time approaches or exceeds the window time, as you won’t be able to catch up or keep up with new data coming into the system. “Now” is a moving target as time advances even as you try and catch up. Of course, you can always make the window smaller and increase the consumer concurrency.
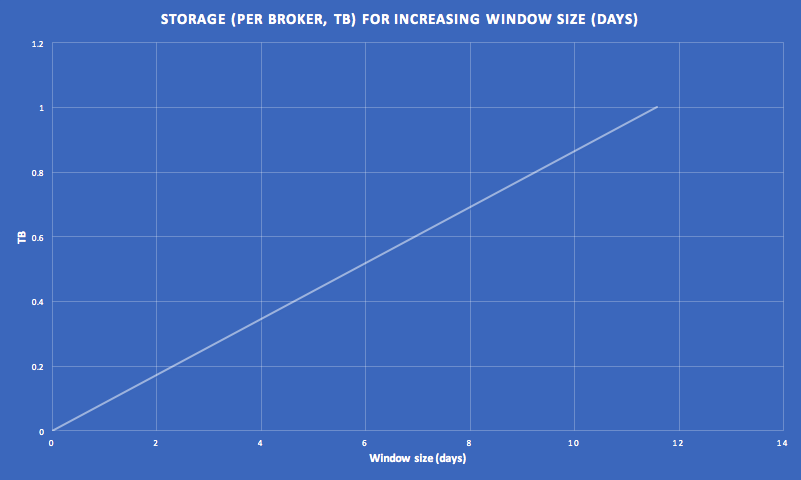
Another consequence of using Kafka as a database is that with reprocessing and increasing window sizes storage requirements go up. For example for the same scenario as above, each broker needs 1TB of storage for an 11.6 day window. This is a realistic amount, but increasing the window size, producer rate, and message size would make this quickly unrealistic. In practice, the amount of data needed to be reprocessed would typically be more limited (e.g. to the last checkpoint for a cache), and the reprocessing may only need to be performed on derived topics that are potentially a lot smaller.
PS
When I returned to work after New Year I was surprised by the materialization of a more modern-looking “time machine” in the Instaclustr office. I wonder how fast it goes?
