Data Exploration into the cutting-edge technology of Apache Zeppelin
 (Source: Shutterstock)
(Source: Shutterstock)
The catastrophic crash of the Hindenburg in 1937 ended the era of luxury travel in the colossal fast ships of the air that were pushing the boundaries of air travel technology. Zeppelins had many experimental innovations like an auto-pilot, were made from Duralumin girders (a new alloy), and were powered by Blau gas engines (Blau gas had the same weight as air, so that as fuel was consumed they didn’t have to vent Hydrogen to keep airborne, which was a significant problem with petrol engines). Welcome on board!

What is Apache Zeppelin?
Apache Zeppelin in an Open Source Web-based Data Analytics Notebook. Zeppelin is designed for easy interactive exploration for Data Ingestion, Data Discovery, Data Analytics, Data Visualization & Collaboration. It supports multiple interpreters for different languages and backend technologies (including Cassandra and Elasticsearch), and built-in Apache Spark integration. Scala and Python are supported for Spark programming.
Inside Apache Zeppelin
“The principal feature of Zeppelin’s design was a fabric-covered rigid metal framework made up from rings and girders containing a number of individual gasbags.” (Source: wikipedia)
Just like the original Zeppelin design with multiple gasbags (16 for the Hindenberg), an Instaclustr managed cluster provisioned with Zeppelin, Spark, and Cassandra provides services deployed on multiple nodes for improved scalability and reliability. Apache Zeppelin support is currently limited (as it’s in development status—version 0.7), but we provide enterprise Spark and Cassandra level support with high availability.
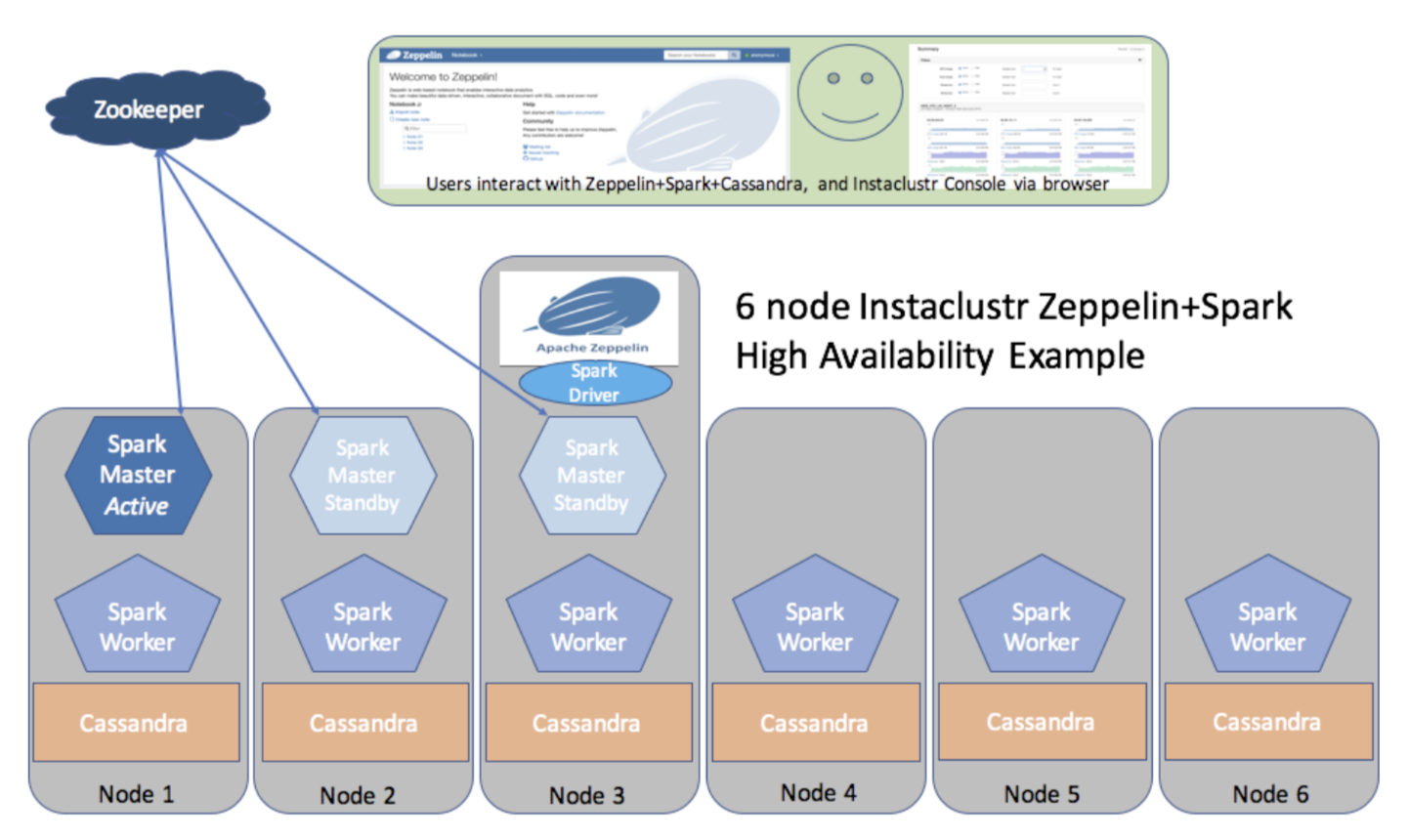
Below is a simplified high-level architecture of an Instaclustr high availability six node cluster with Zeppelin, Spark, and Cassandra running. The Spark Master runs on three nodes and one is elected leader by ZooKeeper and becomes “Active”. If the leader fails then another is elected leader within 1-2 minutes. Existing running jobs are not impacted, only new jobs will be delayed until a new leader is elected. The Zeppelin server has a web server to enable client connection via browser, and the Spark Driver which connects to the current Spark Master Leader (Active Spark Master). Each node has a Spark Worker, one or more executors (configurable but not shown), and Cassandra running as well. Spark workers are resilient to failure by design. The documentation of Spark High Availability with Zookeeper is here.
Note: There are three different ways of submitting Spark jobs: Zeppelin, Spark-jobserver, and spark-submit. Spark-jobserver runs on a node (not the node with Zeppelin). This provides a REST interface for submitting Spark jobs (but is not used by Zeppelin). We’ll look at the alternatives to Zeppelin for running Spark in more detail in another blog.
Launching Apache Zeppelin

“If a gust of wind lifts us off the ground, should we hang on or let go?” (Source: Wikimedia)
Launching a Zeppelin like the Hindenburg was probably tricky! It was enormous, bigger than the Titanic! It was 250m (800 ft) long, with a diameter of 40m (135 ft), and a volume of 200,000 cubic metres of Hydrogen (7 Million cubic feet). And it had a tendency to want to take off (it was lighter than air)!
 USS Los Angeles (only 200m long) over New York (Source: Wikimedia)
USS Los Angeles (only 200m long) over New York (Source: Wikimedia)
A significant benefit of an Instaclustr managed cluster with the add-on Apache Zeppelin service is that launching is automatic!
Note that for production clusters we recommend a minimum instance size of AWS r4.xlarge (4 CPU cores, 30GB RAM and 3,200GB SSD per node). Smaller instances may work for development or experimentation, but the simple answer to “how much memory is enough for Spark?” is “more than you have now”, so bigger is better.
Once the cluster is running, these documents have instructions for connecting to Zeppelin (basically click on the link which opens a browser tab, enter credentials and it’s launched).
What is a Data Analytics Notebook?
A traditional paper notebook is good for quickly scribbling down improvements to an idea and showing them to others. Zeppelin has a similar concept. You can create (import and export) a notebook. Export is useful for backing up notebooks, as we currently support limited automatic backup and restore of notebooks. A notebook can be understood as a collection of related statements (paragraphs) that can be executed together to achieve some useful combined result. The idea is to keep each notebook short, and use multiple notebooks together to solve more complex problems. For example, I created separate notebooks for: importing and cleaning data, creating a pivot table, and running different MLLib algorithms.
Each paragraph has a code section, a result section and paragraph commands:
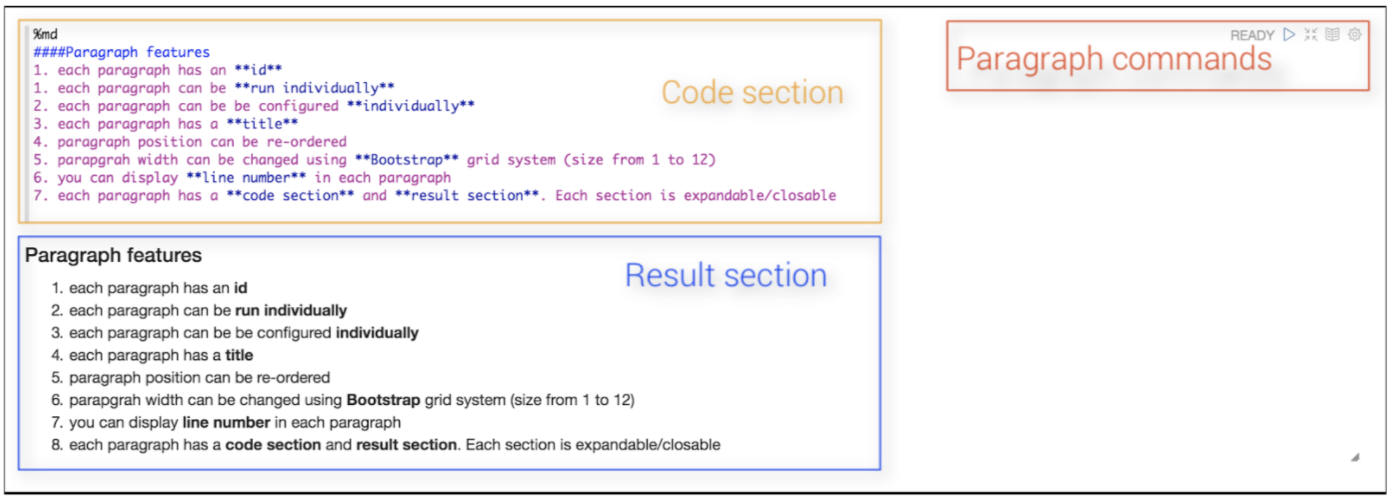
The documentation explains the paragraph commands, and in particular, features that I didn’t discover by accident, which enable you to change the order of paragraphs and disable running paragraphs. You can also insert new paragraphs between existing paragraphs (also using the “+” at the bottom of the paragraph window). These are really useful if you have been experimenting with paragraphs and have ended up with redundant code and paragraphs out of order, and can be used to get the notebook to a state where all the paragraphs can be run in sequence and exported/shared (like being able to move or tear out pages):
On the top-right corner of each paragraph, there are some commands to:
- execute the paragraph code
- hide/show code section
- hide/show result section
- configure the paragraph
- And also to Terminate running jobs.
To configure the paragraph, just click on the gear icon:
![]()
From this dialogue, you can (in descending order):
- find the paragraph id ( 20150924-163507_134879501 )
- control paragraph width. Since Zeppelin is using the grid system of Twitter Bootstrap, each paragraph width can be changed from 1 to 12
- move the paragraph 1 level up
- move the paragraph 1 level down
- create a new paragraph
- change paragraph title
- show/hide line number in the code section
- disable the run button for this paragraph
- export the current paragraph as an iframe and open the iframe in a new window
- clear the result section
- delete the current paragraph
Each paragraph can be run independently, and you can view the results and any errors immediately, make changes, and rerun the paragraph. Note that even if the paragraph is a value definition (e.g. val zeppelin = “Graf Zeppelin”), which is immutable, you can run it multiple times, even with a different value (e.g. val zeppelin = “Hindenberg”).
A few more useful features include cloning of notebooks, running all the paragraphs in the notebook, and versioning. Instaclustr backs up Zeppelin notebooks to AWS S3 daily. But it’s probably wise to export and backup your notebooks at key points as well.
How to fly Zeppelin (without crashing!)

Some warnings! The gasbags on the Zeppelins were filled with lots of highly explosive HYDROGEN gas, but they still allowed smoking onboard! For safety, there was a pressurised smoking room, with airlocks and no open flames allowed (an electric lighter was provided).
Apache Zeppelin also attempts to prevent explosions by limiting the number of result rows displayed. However, you still have to be careful and think about how much data will be returned, particularly for wide tables (with lots of columns). If too much data is returned the notebook has a tendency to become permanently unresponsive (rather than exploding).
In case of emergency…
I’ve also noticed that the job termination isn’t reliable, and sometimes doesn’t work at all or can take a long time. It, therefore, pays to debug the notebooks on small data sets initially, and then gradually increase the data size. When a notebook does hang, you can try to terminate the running job using the paragraph controls, go to the interpreter’s page and restart the interpreter(s). You can also monitor the progress of Zeppelin Spark jobs from the Instaclustr console via the Spark Web UI and attempt to work out what’s going on/wrong. Jobs can also be killed from there. This is available from the Instaclustr management console under the Spark tab. Click on the worker ID or application ID to get the Spark Web UI. More information in our documentation. If nothing else works you can also restart the Zeppelin server (by sending a support request to Instaclustr).
Interpreters
It took me a while to understand interpreters for Zeppelin. The Interpreter Binding Mode is more relevant, and allows you to run notebooks in either shared, scoped or separate interpreters:
Each Interpreter Setting can choose one of ‘shared’, ‘scoped’, ‘isolated’ interpreter binding mode. In ‘shared’ mode, every notebook bound to the Interpreter Setting will share the single Interpreter instance. In ‘scoped’ mode, each notebook will create new Interpreter instance in the same interpreter process. In ‘isolated’ mode, each notebook will create new Interpreter process.
The newest documentation (for 9.0) is more informative.
Does Apache Zeppelin support auto/code-completion?
Partially, using the shortcut “Ctrl+.” This is documented in the list of shortcuts (click on the “keyboard icon” on right-hand side on the “note toolbar”). It’s limited to showing just the list of names and types, and doesn’t have any further documentation available on each option.
Where are my error messages?
In Zeppelin 0.7.1. I was initially frustrated because I couldn’t see any error messages. It turns out that by default error messages are turned off in this version, and you have to explicitly define a new property and set it to true as follows: Under the interpreter settings, Spark properties, Edit, Add and Set the property “zeppelin.spark.printREPLOutput” to true, and Save the settings and Restart the interpreter (this will shortly be the default for Instaclustr Zeppelin instances).
Can I run more than one Spark job at a time?
Maybe. The ability to run multiple concurrent jobs depends on interpreter and Dynamic allocation settings:
Dynamic allocation allows Spark to dynamically scale the cluster resources allocated to your application based on the workload. When dynamic allocation is enabled and a Spark application has a backlog of pending tasks, it can request executors. When the application becomes idle, its executors are released and can be acquired by other applications.
When Spark dynamic resource allocation is enabled, all resources are allocated to the first submitted job available causing subsequent applications to be queued up. To allow applications to acquire resources in parallel, allocate resources to pools and run the applications in those pools and enable applications running in pools to be preempted. See Dynamic Resource Pools.
Flying lessons: How much Hydrogen do you need? How many passengers can you take?
Flying a colossal bag of Hydrogen involved lots of crew members (39 flight crew), flight operation procedures, and technology including multiple flight and engine controls, ballast and gas venting controls (once ballast was dropped the only way down was to vent gas), and complex instrumentation, navigation, weather forecasting, and communication systems.
An Instaclustr Apache Zeppelin, Spark and Cassandra cluster is also a large complex machine. Much of the complexity is managed by Instaclustr, particularly cluster creation, configuration and ongoing management. For example, Instaclustr automatically computes initial Cassandra and Spark memory settings dynamically for each node based on available memory. However, Zeppelin memory is currently allocated statically. ZEPPELIN_MEM is 1024m by default, and ZEPPELIN_INTP_MEM defaults to ZEPPELIN_MEM. For the MLLIB experiments conducted in the last few blogs these settings needed to be increased to 4GB.
Spark is typically faster than Hadoop as it uses RAM to store intermediate results by default rather than disk (E.g. performance modelling of Hadoop vs. Spark). Any results that won’t fit in RAM are spilled to disk or recomputed on demand. This means that (1) you need lots of RAM for it to work efficiently, and (2) in theory you can have less RAM it should still work (sort of).
As the complexity of Spark algorithms increases (e.g. some of the MLlib algorithms such as neural networks are substantially more demanding) and the data size increases, what worked with default settings with smaller problems may fail during execution or take too long to complete. During the course of running the MLLib examples in the previous blog on larger data sets, I encountered numerous and varied run-time memory errors, including out of memory and Garbage Collection errors. Some were relatively easy to fix by tuning spark parameters related to size and number of resources (pretty much trial and error, I just increased things related to the error messages until the job completed).
A more complex error occurred after running a large job for several hours was:
“Remote RPC client disassociated. Likely due to containers exceeding thresholds, or network issues.”
Googling this error find suggestions that to get rid of it you need higher parallelism to ensure that jobs are smaller:
The simplest fix here is to increase the level of parallelism so that each task’s input set is smaller. Spark can efficiently support tasks as short as 200 ms, because it reuses one executor JVM across many tasks and it has a low task launching cost, so you can safely increase the level of parallelism to more than the number of cores in your clusters.
Set the config property spark.default.parallelism to change the default. In general, we recommend 2-3 tasks per CPU core in your cluster.
I checked my settings to see if this could be the problem. My test cluster had 3 nodes with 4 cores available for Spark each, a total of 12 cores. Checking the spark.default.parallelism value with sc.defaultParallelism showed that it had a value of 12. In theory this should be increased to 3 * 12 = 36 (however, AWS cores are not a full-core, just a hyperthread, so a lower value of 2 * 12 = 24 or even 1.5 * 12 = 18 may be better). In general, tuning Spark to optimise both memory and concurrency across multiple nodes for arbitrary data set sizes and algorithm complexity is complicated and requires multiple iterations, sounds like a good topic for a future blog.
In-Flight Entertainment
Apart from the piano, lounge, dining room, smoking room, promenades, and bar (the piano was also constructed from Duralumin!), here’s some reading for the 2.5-day journey across the Atlantic.
Instaclustr Zeppelin article
Instaclustr Debugging with Spark UI
Instaclustr 5 tips on Spark and Cassandra
This caught me out! Running Spark and Cassandra together potentially requires some tuning. Saving a 28 GB file to Cassandra took 2 hours (4MB/s) as Spark overloaded Cassandra. The average write time increased to 300ms. The default setting for “cassandra.output.throughput_mb_per_sec” (per core) is unlimited. In practice you may need to limit the maximum write throughput per core, our article suggests changing the default to 5 (MB per second per core).
Instaclustr Zeppelin examples
Some of the tutorial examples that come with Zeppelin won’t work by default on Instaclustr, as the data sets need to be on the local HDFS file system. However, some of the simpler examples that don’t require input data, and Cassandra examples (above link), will work. It is also possible to read data into the cluster from an external URL, like this example which counts the number of words in my previous blog:
%spark
val html = scala.io.Source.fromURL(“https://www.instaclustr.com/blog/third-contact-monolith-part-c-pod/“).mkString
val list = html.split(” “).filter(_ != “”)
list.length
Graf Zeppelin’s Arctic Flight, 1931
Did you know that the Graf Zeppelin flew over the Arctic for a scientific expedition in 1931?
There’s even movie footage from the flight.

{kind=link}
{kind=link}
{kind=link}