In Part 1 of this blog series, we focused on MirrorMaker 2 theory (Kafka replication, architecture, components and terminology) and invented some MirrorMaker 2 (MM2) rules. In this part, we will be more practical, and try out Instaclustr’s managed MirrorMaker 2 service and test the rules out with some experiments.
1. Configuring Instaclustr Managed MirrorMaker 2 Mirrors

All of the software you need to run MirrorMaker 2 is Apache-licensed (Apache Kafka, Apache Kafka Connect, Apache MIrrorMaker 2), so you can run it yourself, or use a managed service such as Instaclustr’s managed MM2. This is what I used to try some experiments, and here are the steps you need to follow.
- Step 1: Log in to the Instaclustr management console
- Step 2: Create a Kafka cluster, e.g. kafka_1 (this will be the Kafka target cluster)
- Step 3: Create a Kafka Connect cluster, with kafka_1 as the target cluster (under Kafka Connect Options on Kafka cluster creation page).
- Step 4: Create another Kafka cluster, e.g. kafka_2 (this will be the source cluster)
- Step 5: Create a MirrorMaker 2 mirror (Kafka Connect -> Mirroring -> Create New Mirror).
- Step 5 (a): Configure the mirror
On Instaclustr managed MM2, the available mirror configuration options are as follows:- Kafka target: kafka_1 (fixed)
- Rename mirrored topics: True/false (default true)
- Kafka source: Instaclustr managed/other
- Source cluster name: kafka_2 (the cluster you want to replicate topics from)
- Connect via private IPs: true/false (default false)
- Source cluster alias: kafka_2 (the default is the source cluster name)
- Topics to mirror: “.*” (all by default)
- Maximum number of tasks: 3 (default, and also the maximum value, is the number of partitions in the source topic)
- Step 5 (b): Create mirror
Here’s a diagram showing what we end up with:
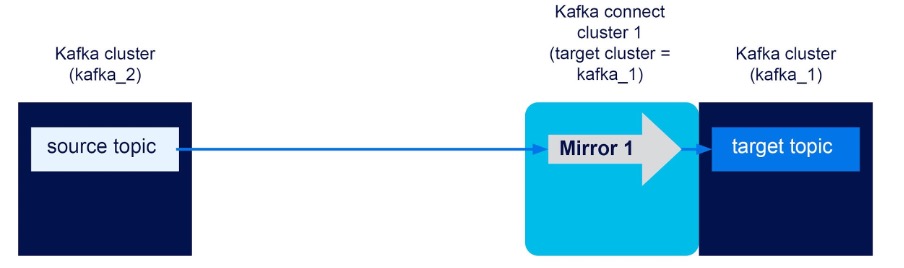
Note that we assume the source topic exists or is created automatically when an event is written to it the first time.
Under Kafka Connect->Mirroring you can see a useful summary of the existing mirrors including: data flow, topics, sync state, and actions (details and delete).
Under Mirror details you can see much more, including the mirror connector status, how many tasks are running (mirror and checkpoint), and a list of all the replicated topics (with renaming if applicable, e.g. A.topic1) and latencies (useful if you’ve used a regular expression and aren’t 100% sure what topics match it), and the full mirror configuration.
There are also useful mirroring metrics available in the console. For a given data flow and mirrored topic, metrics available are record count, record rate, byte count, byte rate, record age (avg, min, max), and replication latency (avg, min, max). These are actually just the generic source connector metrics.
Note that once you create a Kafka connect cluster, the target Kafka cluster cannot be changed. In the mirror configuration also note that the target cluster alias can’t be changed, and for the time being we will leave the source cluster alias unchanged. The configuration for the maximum number of tasks determines the scalability of each mirror and must be less than or equal to the number of partitions in the topic. The MM2 connector uses a multi-topic consumer, so it will work fine if the topics have different numbers of partitions, as long as the number of tasks is configured based on the topic with the most partitions.
2. Experiments With Instaclustr Managed MirrorMaker 2
(Source: Shutterstock)
I tried several experiments with different combinations of The number of Kafka clusters (1-3); the number of Kafka connect clusters (1,2); topic renaming on/off, and mirror flows (uni and bi-directional). Some of the experiments were a bit random, and perhaps not useful in practice, but did result in some surprising discoveries. I’ll add to the above RULES when I find that the existing rules are incomplete.
For each experiment, I created a new topic with three partitions on the source cluster(s) and produced and read events to/from it and other remote topics using the Kafka producer and consumer console tools. This approach was sufficient to check that the remote topics had been created as expected and that events were being replicated correctly between the source and target topics.
Experiment 1 (1 Cluster)
One Kafka cluster (kafka_1), one Kafka connect cluster with target cluster = kafka_1, unidirectional mirror flow kafka_1->kafka_1. Result? FAILED
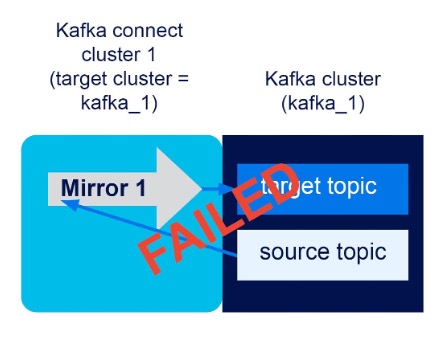
I thought that perhaps replication from/to one Kafka cluster would be a good starting point, and perhaps useful for testing. However, with topic renaming on or off the mirror fails to be created. There is a warning on the Instaclustr console, “Warning: source cluster and target cluster are the same”, which I chose to ignore for the sake of science. However, it turns out that this is more than a suggestion, and you just can’t replicate from/to the same cluster. This gives us another RULE:
RULE 8: The source and target Kafka clusters cannot be the same cluster.
Which implies a minimum of two clusters for the remainder of the experiments.
Experiment 2 (2 Clusters, Unidirectional)
Two Kafka clusters (kafka_1, kafka_2), one Kafka connect cluster with target cluster = kafka_1, unidirectional mirror flow kafka_2->kafka_1. Result? SUCCESS
This was my first experiment with two Kafka clusters, and I started by replicating from kafka_2 (the remote cluster) to kafka_1 (the local/target cluster). With topic renaming on or off this worked as expected with the following replications observed:
Renaming on: topic (kafka_2) -> kafka_2.topic (kafka_1)
Renaming off: topic (kafka_2) -> topic (kafka_1)
A new topic, kafka_2.topic was automatically created on the kafka_1 topic, and events from the topic on kafka_2 were replicated into it. The properties of the newly created topic were mostly as expected, i.e. the number of partitions was identical, however, the replication factor was 2, whereas the source topic had a replication factor of 3. What happened? It looks like MM2 has a default RF for new topics of 2, rather than copying the source RF value over. Workarounds include manually creating target topics before replication, or changing the RF value after auto creation.
From this experiment, we can also conclude that the source cluster does not need to have a Kafka connect cluster associated with it for mirroring to work.
Experiment 3 (2 Clusters, Unidirectional)
Kafka clusters (kafka_1, kafka_2), one Kafka connect cluster with target cluster = kafka_1, unidirectional mirror flow kafka_1->kafka_2. Result? FAILED
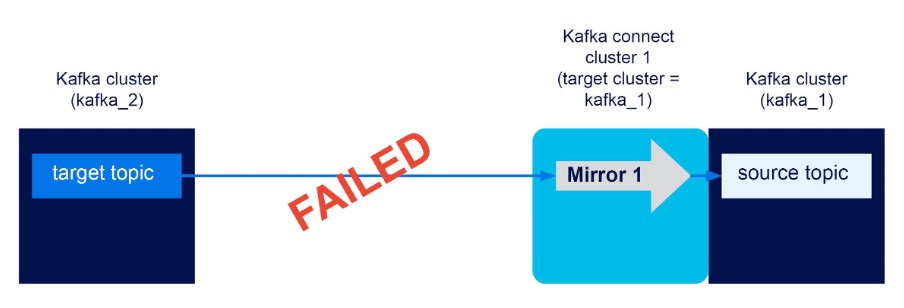
Next, I tried to reverse the flow direction to see if I could replicate from kafka_1 (the local/target cluster) to kafka_2 (the remote cluster). Using the Instaclustr managed MM2 it isn’t possible to configure this option, and it only supports a unidirectional replication flow towards the target cluster. So this gives us a new RULE.
RULE 9: One Kafka connect cluster per target cluster
Each Kafka connect cluster only supports unidirectional mirror flows to the associated Kafka target cluster from a source cluster (which as we noted above, doesn’t need a Kafka connect cluster). Flows from target to other clusters are not supported.
This also turns out to follow from the fact that the MirrorMaker 2 connector is really a Kafka source connector, so is only designed to write to a local Kafka cluster from an external source, not the other way around (which would be a sink connector).
More importantly, it’s also best practice for geo-replication (“Best Practice: Consume from remote, produce to local”) as MirrorMaker 2 is commonly used to replicate data between Kafka clusters running in different cloud regions, with potentially high latencies. Kafka producers are more sensitive to high latency than Kafka consumers, so to minimize latency on the producer size MirrorMaker 2 should be run close to the target cluster.
So, just to check, I repeated the previous experiment, but with a new Kafka connect cluster with the kafka_2 cluster as the target cluster.
Experiment 4 (2 Clusters, Unidirectional)
Two Kafka clusters (kafka_1, kafka_2), 1 Kafka connect cluster with target cluster = kafka_2, unidirectional mirror flow kafka_1->kafka_2. Result? SUCCESS
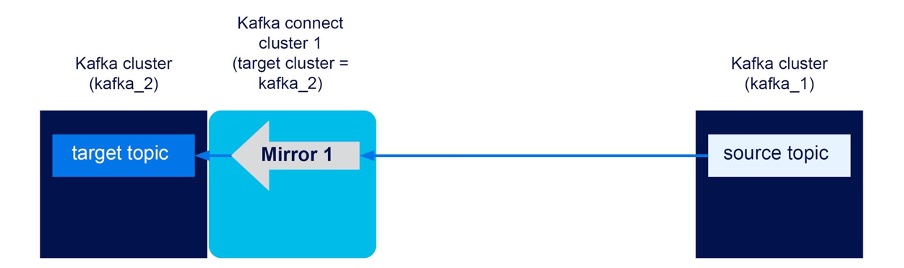
As expected, this configuration allows for unidirectional flows from the remote cluster (kafka_1) to the local/target cluster (kafka_2). And it works with both renaming on and off as expected.
There are several consequences of Kafka connect clusters supporting (only) unidirectional flows towards the target cluster as follows:
1. Kafka source clusters do not need Kafka Connect clusters
Proved by experiments 2 and 4. Q.E.D. Let’s make this a new RULE:
RULE 10: No Kafka Connect clusters are needed for Kafka source clusters
From RULES 9 and 10, you can predict how many Kafka connect clusters are needed for any given pattern, simple!
2. Efficient fan-in replication (only one Kafka connect cluster required)
It’s possible to efficiently support fan-in replication, with multiple unidirectional MirrorMaker 2 flows from many source clusters (A, B, C) to one target cluster, with a single Kafka connect cluster (Connect) running with the target cluster (X), e.g.
A->(Connect) X
B->(Connect) X
C->(Connect) X
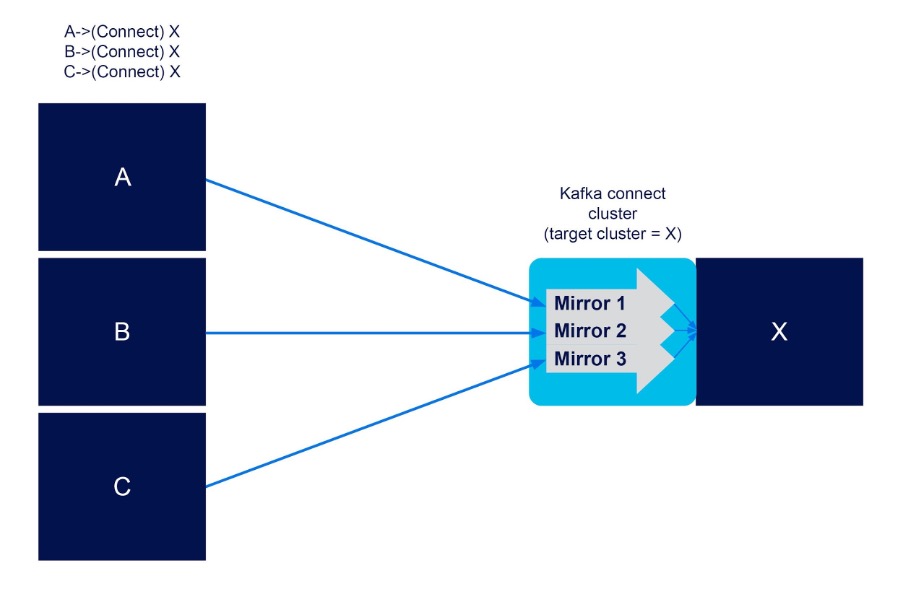
i.e. you only need one Kafka connect cluster on the target end of fan-in flows, and not on each source end.
3. Inefficient fan-out replication (multiple Kafka connect clusters required)
The downside is that for fan-out patterns you need more Kafka Connect clusters, one per Kafka target cluster. For example, for a fan-out from two source clusters (X) to three target clusters, you need three Kafka Connect clusters, one for each target cluster (ConnectA, ConnectB, ConnectC).
X->(ConnectA) A
X->(ConnectB) B
X->(ConnectC) C
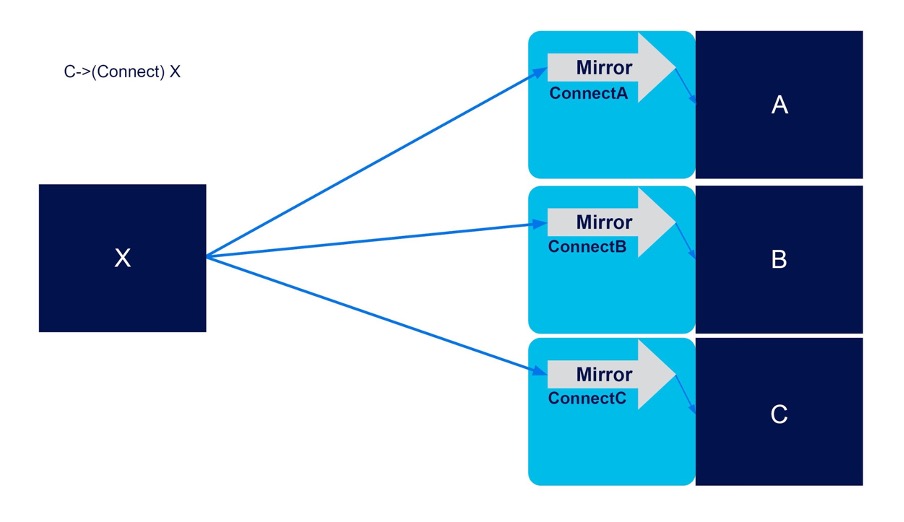
4. Bidirectional flows require a minimum of TWO Kafka connect clusters
And, to achieve bidirectional MM2 flows you need a minimum of two Kafka connect clusters. For example, for bidirectional flows between two Kafka clusters (X, Y), you need to run two Kafka connect clusters, one for each Kafka target cluster. For example, with ConnectX with target X, and ConnectY with target Y:
X -> (ConnectY) Y
Y -> (ConnectX) X
Or functionally equivalent to a bidirectional flow:
X (ConnectX) <-> (ConnectY) Y
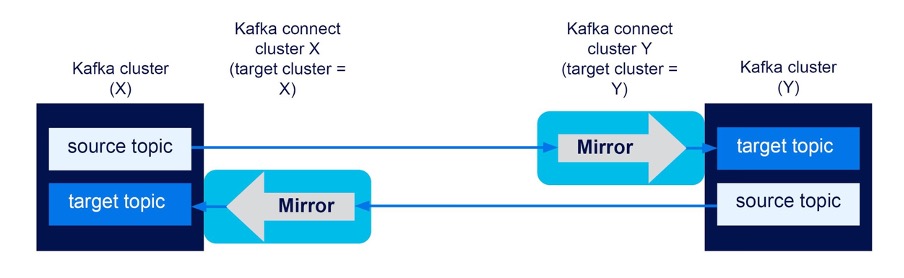
This will enable replication from X to Y, and from Y to X, and gives us another RULE (even though it’s probably redundant given that it’s really just an extension of RULE 9 for 2 target clusters:
RULE 11: Two Kafka connect clusters are required for bidirectional flow
For bidirectional mirror flows between two Kafka clusters, you need two Kafka Connect clusters, one for each target Kafka cluster.
Well, that’s the theory, time to put it to the test. Let’s check these out with some more experiments, this time with three Kafka clusters (each with a Kafka connect cluster to enable mirror flows to each target Kafka cluster) to allow for more interesting patterns.
Experiment 5 (Fan-in)
Three Kafka clusters (kafka_1, kafka_2, kafka_3), one Kafka connect cluster with target cluster = kafka_1, unidirectional mirror flows kafka_2->kafka_1, kafka_3->kafka_1. Result? SUCCESS
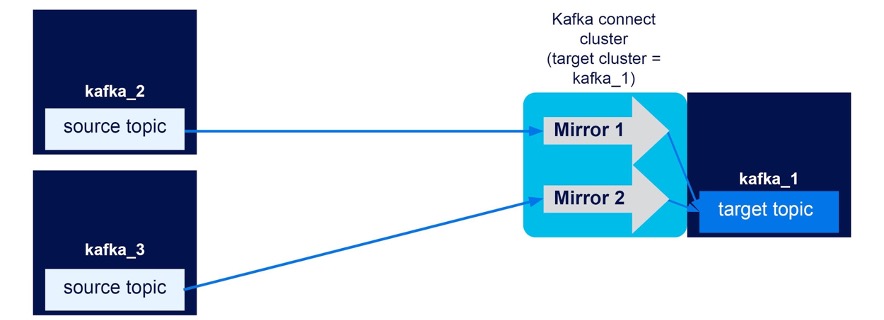
This is a test of the fan-in pattern, from kafka_2 and kafka_3 to kafka_1, with a single Kafka connect cluster with kafka_1 as the target. As expected, you can create multiple mirror flows in the connect cluster, one for each source cluster. This works for topic renaming on and off as follows:
First on:
topic (kafka_2) -> kafka_2.topic (kafka_1)
topic (kafka_3) -> kafka_3.topic (kafka_1)
Now off:
topic (kafka_2) -> topic (kafka_1)
topic (kafka_3) -> topic (kafka_1)
With topic renaming off the fan-in pattern is aggregating multiple source topics to a single replicated topic. Clever!
Experiment 6 (Event Duplication)
Two Kafka clusters (kafka_1, kafka_2), one Kafka connect cluster with target cluster = kafka_1, unidirectional mirror flows kafka_2->kafka_1, kafka_2->kafka_1. Result? SUCCESS (but with duplicate events)
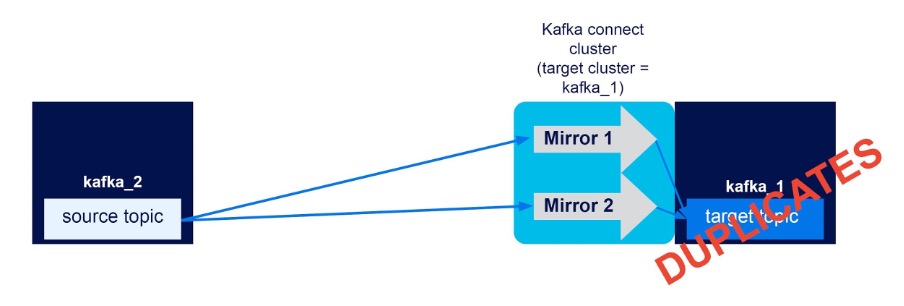
This “experiment” was actually the result of a mistake I made with the previous experiment when I accidentally created two identical mirror flows from the same source cluster to the target cluster, resulting in duplicate events, i.e. with renaming on:
topic (kafka_2) -> kafka_2.topic (kafka_1)
topic (kafka_2) -> kafka_2.topic (kafka_1)
And off:
topic (kafka_2) -> topic (kafka_1)
topic (kafka_2) -> topic (kafka_1)
Evey event produced to the topic on the source cluster is therefore duplicated to the target cluster. This is not very desirable, so gives rise to another RULE:
RULE 12: To prevent duplicate events, avoid overlapping topic subscriptions
Because you can have multiple mirror flows for the same source cluster, be careful to avoid overlapping topic subscriptions (otherwise you will get duplicate events).
Being able to duplicate events to the same topic isn’t particularly useful, but it can happen due to the flexibility of having multiple mirror flows and regular expression topic subscriptions. For example, you may have one flow subscribing to specific topics, and another using a regular expression to subscribe to others, but it may not be obvious if the pattern accidentally applies to the other flow. You can of course check in the Instaclustr console to see which topics are actually replicated for each mirror, but it may be difficult to detect a common topic if there are large numbers of topics.
Experiment 7 (Fan-out)
Three Kafka clusters (kafka_1, kafka_2, kafka_3), two Kafka connect clusters (with targets of kaka_2 and kafka_3), unidirectional mirror flows kafka_1->kafka_2, kafka_1->kafka_3. Result? SUCCESS
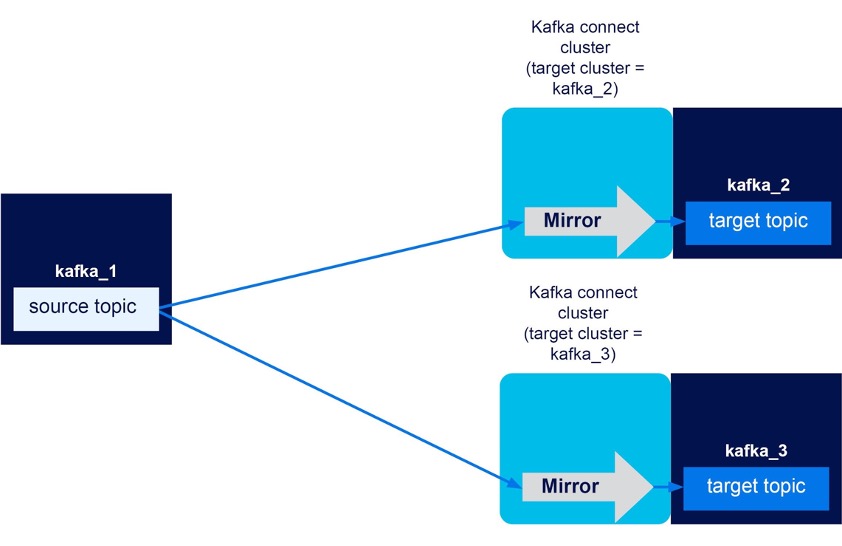
This experiment proves that you can have multiple mirror flows from a source cluster (kafka_1) to target clusters, as long as each target cluster has a Kaka connect cluster associated with it. It works for both renaming on and off as follows:
On:
topic (kafka_1) -> kafka_1.topic (kafka_2)
topic (kafka_1) -> kafka_1.topic (kafka_3)
Off:
topic (kafka_1) -> topic (kafka_2)
topic (kafka_1) -> topic (kafka_3)
This pattern provides another form of event duplication, which is probably more useful than the previous one. It’s designed to share events from a common source cluster to multiple other clusters. For example, for redundancy and failover, load-balancing, re-use in different applications, etc.
While I had three Kafka clusters available I thought I’d try another topology, a pipe.
Experiment 8 (Forwarding/Pipe)
Three Kafka clusters (kafka_1, kafka_2, kafka_3), 2 Kafka connect clusters (with targets of kaka_2 and kafka_3), unidirectional mirror flows kafka_1->kafka_2, kafka_2->kafka_3. Result? SUCCESS
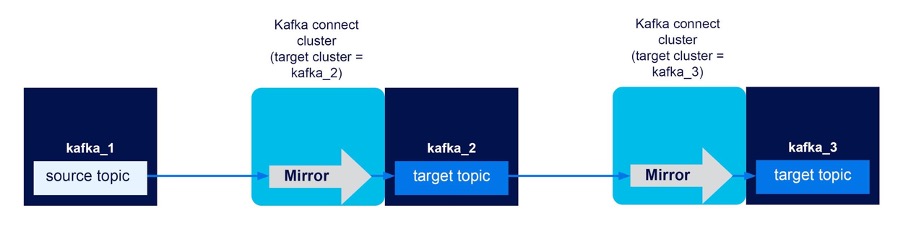
As expected, this configuration works to replicate events across multiple clusters, by forwarding them down a pipe, from kafka_1 to kafka_2 to kafka_3, as follows.
Renaming on:
topic (kafka_1) -> kafka_1.topic (kafka_2) -> kafka_2.kafka_1.topic (kafka_3)
This demonstrates how renamed topics can be renamed again with each new replicated topic name having the name of the source cluster topic, but with the source cluster name prepended.
Renaming off:
topic (kafka_1) -> topic (kafka_2) -> topic (kafka_3)
Now let’s test out some bidirectional patterns.
Experiment 9 (Two clusters, Bidirectional)
Two Kafka clusters (kafka_1, kafka_2), two Kafka connect clusters (with targets of kaka_1 and kafka_2), subscription from “all” topics, two unidirectional mirror flows kafka_1->kafka_2, kafka_2->kafka_1. Result? SUCCESS (with topic renaming on)
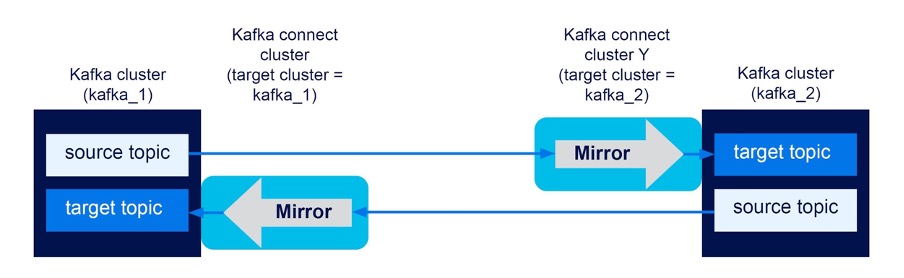
This is the simplest possible bidirectional flow test, with two Kafka clusters, a Kafka connect cluster targeting each Kafka cluster, and two mirror flows, one for each direction. If it works correctly, then events produced to the local topic will be replicated once—and only once—to the target topic. If topic renaming is enabled (default) then we expect this:
producer (kafka_1) -> topic (kafka_1) -> kafka_1.topic (kafka_2)
producer (kafka_2) -> topic (kafka_2) -> kafka_2.topic (kafka_1)
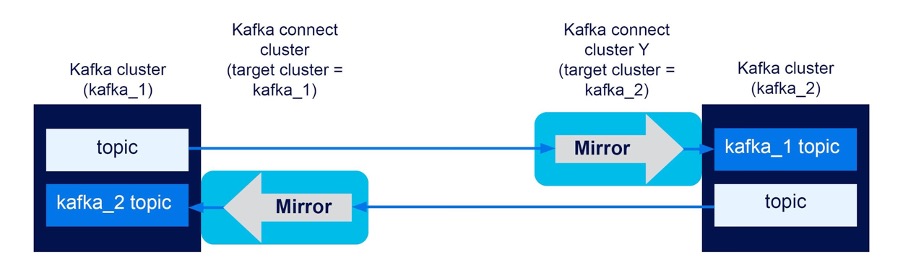
For example, after configuring the first mirror flow, the message “hello from kaka_1” was observed in topic (kafka_1), and then in the automatically created target topic, kafka_1.topic (kafka_2). After configuring the second mirror flow, the message “hello from kaka_2” was observed in topic (kafka_2), and then in the automatically created target topic, kafka_2.topic (kafka_1). We have successfully created a bidirectional flow with two unidirectional flows.
Because of the topic renaming, and the cycle prevention filtering, replication from the automatically created target topics back to their source clusters is prevented, and no cycles can occur, i.e.
kafka_1.topic (kafka_2) -> X (kafka_1) is not replicated, as the source topic contains the name of the target cluster (kafka_1)
kafka_2.topic (kafka_1) -> X (kafka_1) is not replicated, as the source topic contains the name of the target cluster (kafka_2)
But what happens when topic renaming is disabled?
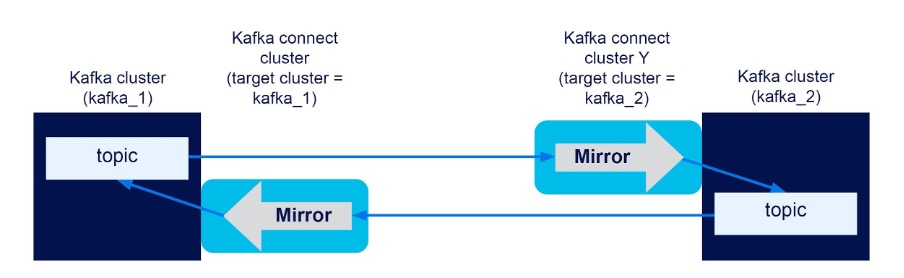
Without renaming, locally produced events on each source topic are just replicated to the target cluster topics of the same name:
producer (kafka_1) -> topic (kafka_1) -> topic (kafka_2)
producer (kafka_2) -> topic (kafka_2) -> topic (kafka_1)
This still works as expected. However, the problem now is that there’s an extra producer on each source cluster, the MirrorMaker 2 replication producer. So, as soon as the event from the local producer is replicated from kafka_1 to kafka_2 by the first mirror flow, it’s read by the second mirror flow and replicated back to kafka_1, where it came from, causing an infinite loop of duplicate events (and the same thing happens in the other direction):
producer (kafka_1) -> topic (kafka_1) -> topic (kafka_2) ->
topic (kafka_1) ->
topic (kafka_2) -> etc.
Let’s formulate a specific new RULE for cycle prevention:
RULE 13: Use topic renaming to prevent cycles
To avoid infinite event cycles with bidirectional flows (two or more unidirectional mirror flows replicating in each direction between two clusters, subscribing to all topics), then you must use topic renaming.
Experiment 10 (2 Clusters, Bidirectional, Source Cluster Alias Changed)
Result? FAILED
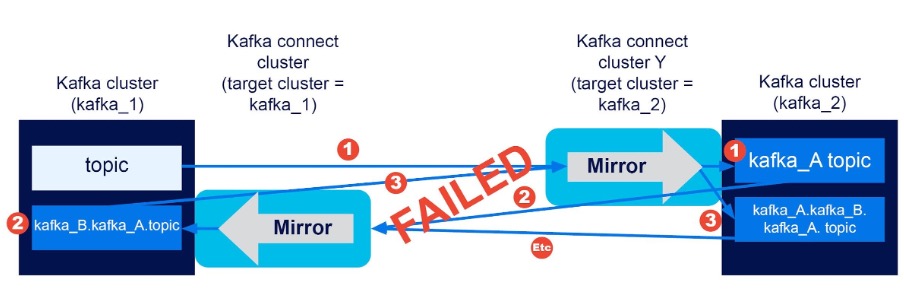
I accidentally created a variant of the bidirectional experiment 9 (i.e. with a subscription to “all” topics, bidirectional flow, two clusters, and renaming on) when I changed the source cluster alias name to something other than the actual cluster name for each, e.g. “kafka_A” instead of “kafka_1”, and “kafka_B” for “kafka_2”. Here are the expected flows with renaming now using the source cluster aliases (and the real cluster names in brackets as before):
producer (kafka_1) -> topic (kafka_1) -> kafka_A.topic (kafka_2)
producer (kafka_2) -> topic (kafka_2) -> kafka_B.topic (kafka_1)
What was the result? Something worse than infinite event loops, infinite topic creation, i.e.
Replication 1: kafka_A.topic (kafka_2)
Replication 2: kafka_B.kafka_A.topic (kafka_1)
Replication 3: kafka_A.kafka_B.kafka_A.topic (kafka_2)
Etc
By changing the source cluster alias name we’ve managed to break the automatic cycle detection topic filtering, as the source alias no longer matches the target cluster name, i.e.
topic (kafka_1) -> kafka_A.topic (kafka_2) is replicated, as “topic” does not contain the name of the target cluster, kafka_2 (This is correct behavior).
kafka_A.topic (kafka_2) -> kafa_B.kafka_A.topic (kafka_1) is replicated, as “kafka_A.topic” does not contain the name of the target cluster, kafka_1 (only the alias, kafka_A). Whoops!
Etc.
Evidently, I’m not the first person to have discovered this aberrant behavior.
After a while, there are lots of automatically created topics, some with very long topic names, and eventually, the mirror connector tasks all failed. I wondered why and noticed that the longest topics had just under 256 characters. Apparently, Kafka has a maximum topic length of 256 characters, so topic creation was failing once the names exceeded this maximum and the connectors failed. So obviously you don’t want to accidentally use this configuration, but there are some other configurations that may result in potentially long topic names. For example, if you have long pipelines and long cluster names you could exceed the 256 character limit. Maybe this is one occasion where shortening the cluster names by using a different alias makes sense.
Perhaps the final rules should therefore be:
RULE 13: Use topic renaming with the default source cluster alias to prevent cycles
To avoid infinite event cycles (or worse, i.e. infinite topic creation) with bidirectional flows (two or more unidirectional mirror flows replicating in each direction between two clusters, subscribing to all topics), then use topic renaming and don’t change the source cluster alias name.
RULE 14: Use a short source cluster alias to prevent long topic names
If you have long cluster names, long pipelines, and only unidirectional mirror flows, use automatic topic renaming to keep track of the pipeline dependencies, then rename source cluster aliases to something shorter to prevent the topic names from exceeding the 256 character limit. But only if you don’t need cycle prevention (see Rule 13).
7. Conclusions
Just so they are collected in one place, here’s a recap of the “15 MM2 Rules” we discovered:
RULE 0: Each mirror flow runs in a Kafka Connect cluster
RULE 1: Each mirror flow is unidirectional
RULE 2: Each mirror flow copies one or more topics
RULE 3: Each source topic is replicated to exactly one remote topic (one-to-one topic mapping)
RULE 4: MM2 supports automatic remote topic creation
RULE 5: MM2 supports automatic remote topic renaming
RULE 6: Multiple flows can be created for complex topologies and bidirectional flows
RULE 7: To prevent cycles, MM2 does not replicate source topics containing the name of the target cluster
RULE 8: Source and target clusters cannot be the same
RULE 9: One Kafka Connect cluster is needed per target cluster
RULE 10: No Kafka Connect clusters are needed for Kafka source clusters
RULE 11: Two Kafka Connect clusters are required for bidirectional flows
RULE 12: To prevent duplicate events, don’t have overlapping topic subscriptions
RULE 13: Use topic renaming with the default source cluster alias to prevent cycles
RULE 14: Use a short source cluster alias to prevent long topic names.
I was originally planning on trying MirrorMaker 2 out with Kafka clients to explore how failover and recovery actually work in practice (e.g. the clients have to be able to detect failure, decide which cluster to connect to, and what offset to start consuming from, etc.). However, after trying some experiments with MirrorMakerConfig and the helper class RemoteClusterUtils, I discovered that a future improvement is really what I needed (KIP-545: support automated consumer offset synchronization across clusters in MM 2.0). As this is only available in Kafka 2.7.0, I’ll wait until Instaclustr supports this version before testing it out.

Master Apache Kafka with expert insights
Struggling to strike the perfect balance between performance, scalability, and reliability in your Kafka ecosystem? Whether you're optimizing for zero downtime or maximizing resource efficiency, this guide has you covered.