Kafka Mirroring with Kafka Connect
Mirroring is the process of copying your Kafka data from one cluster to another. This can be for a variety of reasons including:
- Data backup
- Creating a Failover cluster
- Moving data between geographical regions for local production/consumption
- Creating Active/Active highly available cluster topologies
Instaclustr uses Mirror Maker 2 on top of Kafka Connect to provide a mirroring capability.
Prerequisites
You can use the Instaclustr dashboard to start the required mirroring connectors to create mirroring between two Kafka clusters. In order to do so you will need as a prerequisite:
- A source Kafka cluster (i.e. where your data is coming from )
- A destination Kafka cluster (i.e. where your data is going to)
- A Kafka Connect cluster targeting your destination Kafka cluster (to run the connectors). Note that since the Kafka Connect cluster must be connected to the destination Kafka cluster, it is strongly recommended that the Kafka Connect cluster be provisioned in the same region as the destination Kafka cluster. The source cluster need not be in the same region.
If you have not yet set these up, do so first, using the following pages to help you:
- https://www.instaclustr.com/support/documentation/kafka/getting-started-with-kafka/creating-a-kafka-cluster/
- https://www.instaclustr.com/support/documentation/kafka-connect/getting-started-with-kafka-connect/creating-a-kafka-connect-cluster/
Creating the connectors
Navigate to the mirroring page for your Kafka Connect cluster on the console and click Create New Mirror.
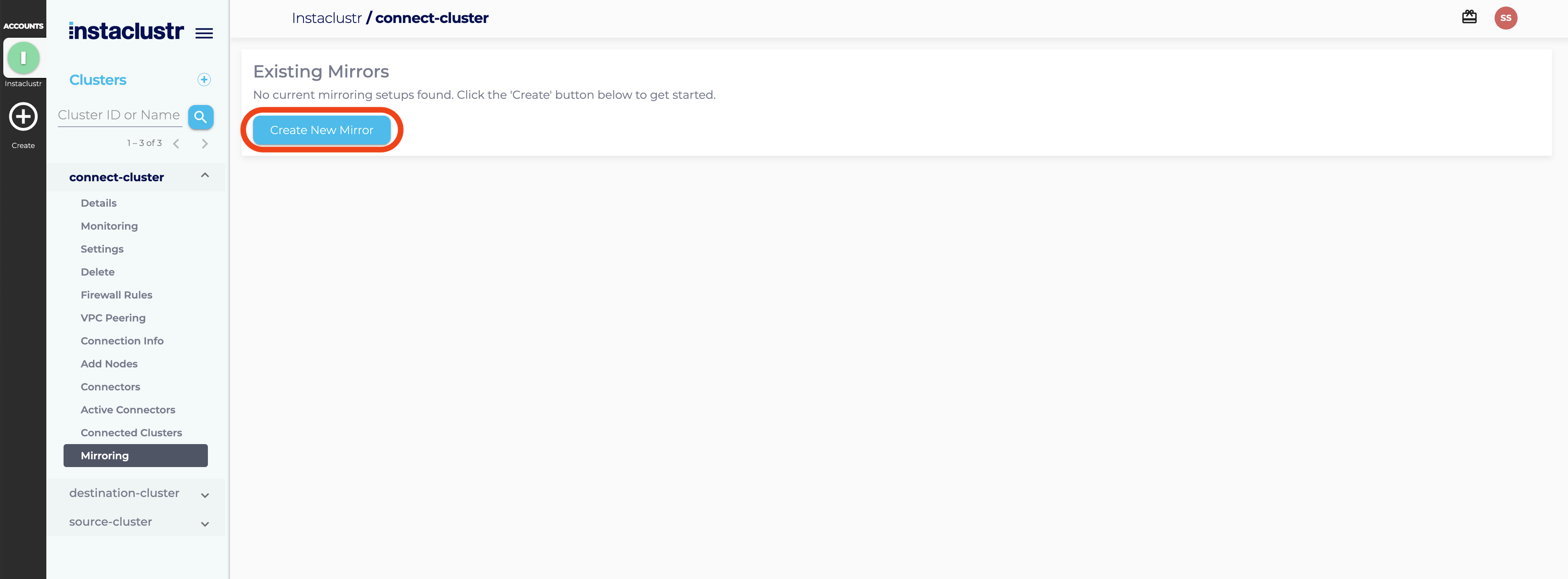
Enter the required information. You will need to specify:
- The source Kafka cluster. (If this is not an Instaclustr managed cluster then you will need to specify connection properties similar to what you would use in a consumer configuration)
- Whether or not to rename the mirrored topics. Topics named ‘abc’ in the source cluster will become named ‘alias.abc’ in the destination cluster (where ‘alias’ is the alias for the source cluster). Renaming topics is the default and is useful for creating active/active setups or moving data between geographic areas. This helps prevent mirroring loops and identifies where data has come from. Turning renaming off is useful for straight data backups or creating failover clusters that consumers can use without needing to be topology aware.
- A source cluster alias. This is a short name used to describe the source cluster in various places and defaults to the cluster’s name.
- Whether or not to use private IPs. Use private IP’s only if your source and destination clusters can be routed between using private IPs (e.g. via VPC peering). Connecting via private IPs may save on traffic costs.
- The topic to mirror. This can be a regular expression to cover mirroring multiple topics.
- The maximum number of Kafka Connect tasks to use. We recommend that this not be less than the number of workers in your Connect cluster.
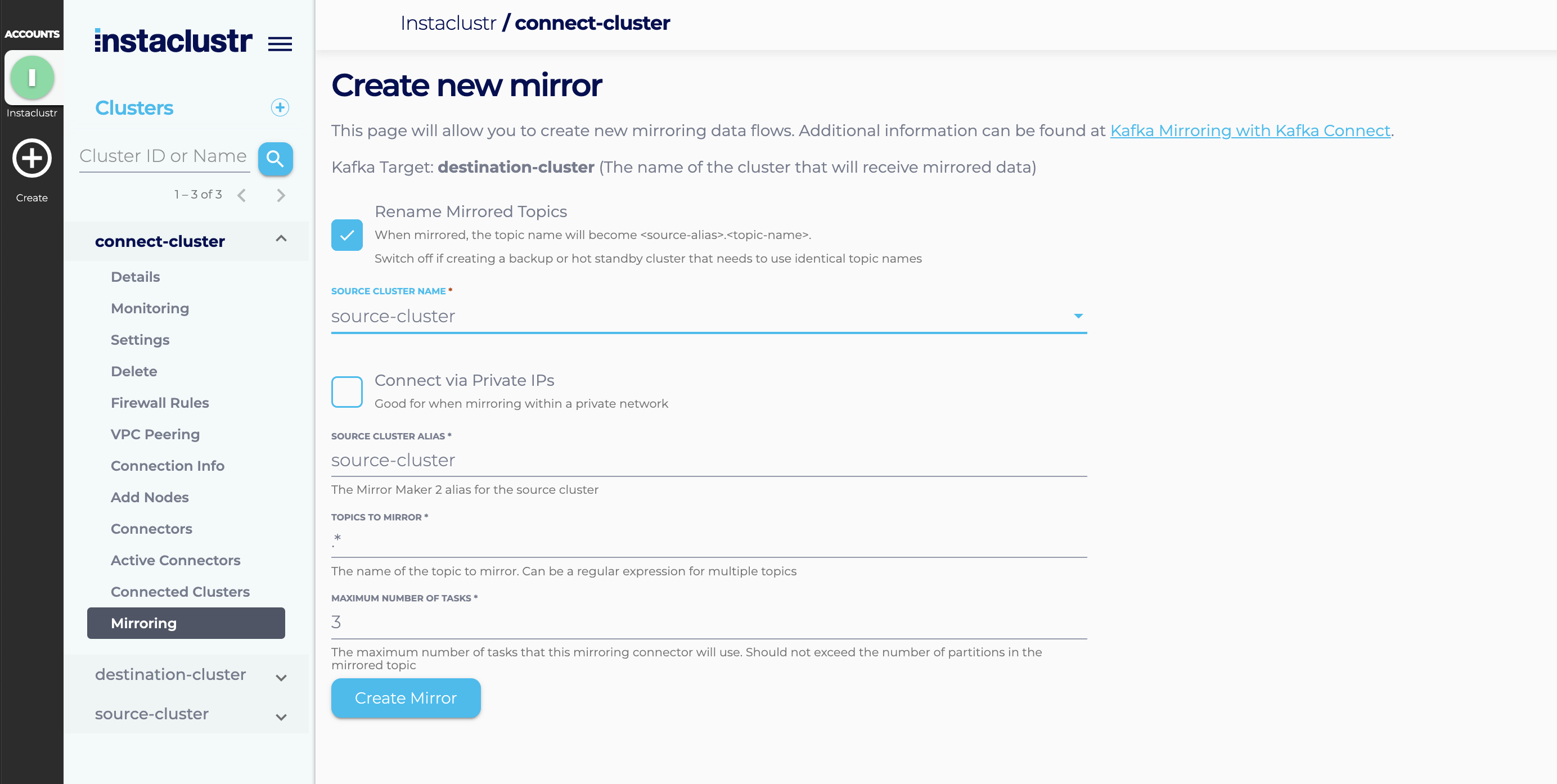
Press the Create Mirror button. Creating the mirror may take a minute or two, particularly if this is your first mirror, and your source cluster will be automatically set up as a ‘connected’ cluster. Refer to our support article on Connecting to Instaclustr managed Clusters for more details on this feature.
From the main mirroring page you can see a summary of your active mirroring data flows. For each individual mirroring data flow, you can use the action buttons on the right to get more details, or to delete the mirroring data flow.
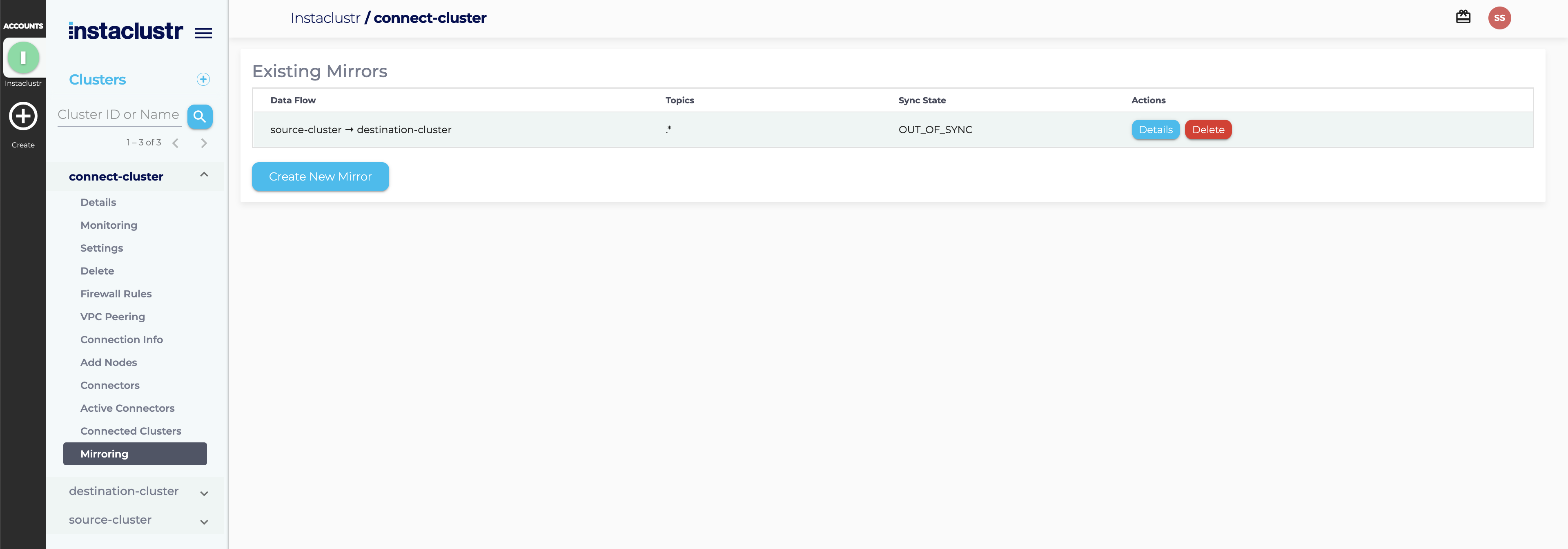
You can also see the status of all your Kafka mirrors on this page. There are three different statuses for our managed Kafka mirrors. Before introducing them, some terminologies need to be defined for your better understanding.
- Active topics: Topics have messages produced at a specific time.
- Inactive topics: Topics do not have messages produced at a specific time.
- Stale topics: Topics have messages produced before mirror creation, but don’t have new messages produced after mirror creation.
The following are 3 statuses that might be shown on the main mirroring page.
- IN_SYNC:
- All mirrored topics are active and their average replication latency values are lower than the target latency.
- All mirrored topics are active and their average replication latency values are lower than the target latency.
- STALE_TOPIC:
- Mirrored topics contain one or more stale topics.
- Mirrored topics contain one or more inactive topics, and the average replication latency values of their last messages are higher than the target latency.
- OUT_OF_SYNC:
- The mirror connector or its tasks are not running.
- Mirrored topics contain one or more active topics that have their average replication latency values higher than the target latency.
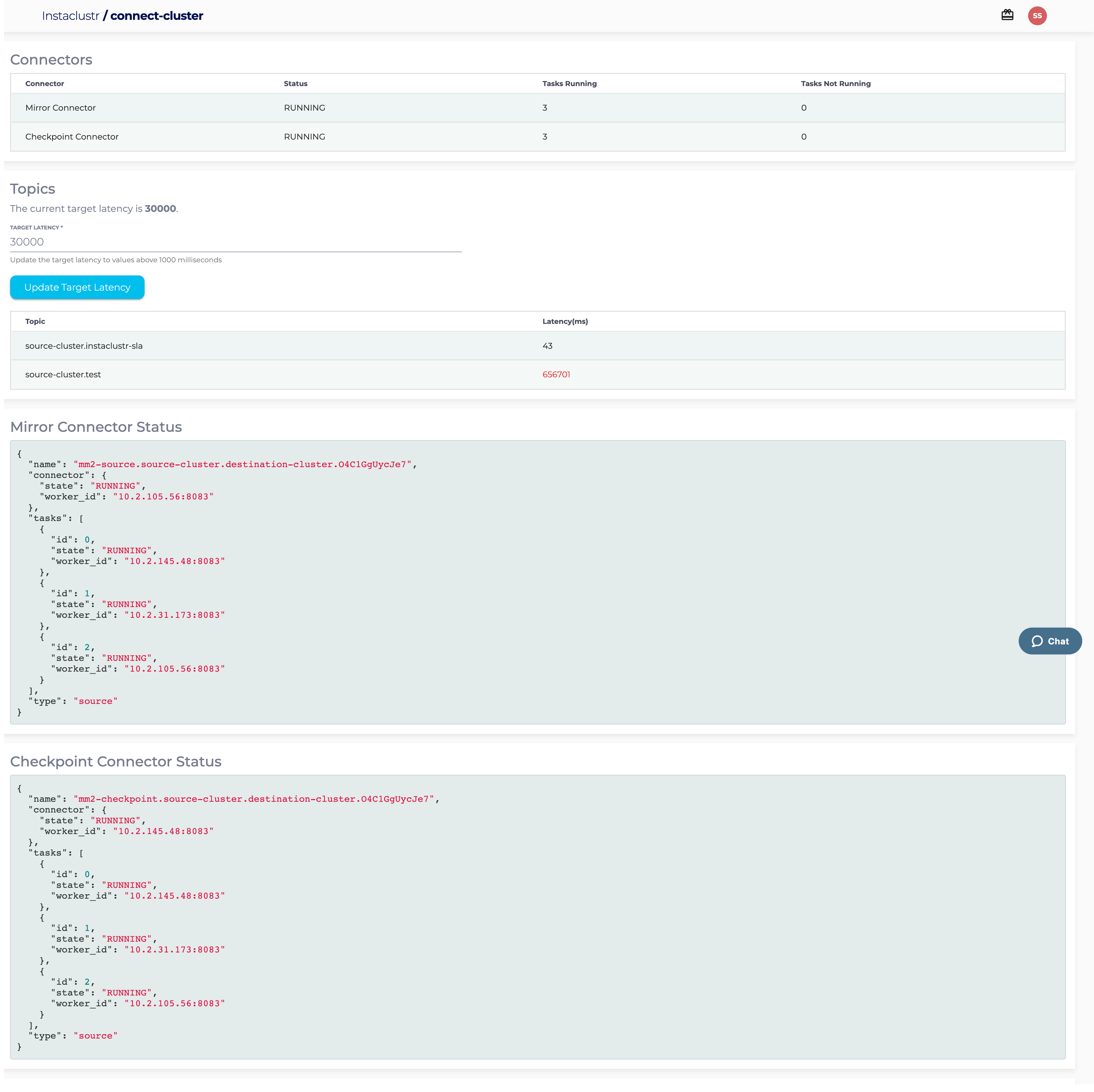
The details page will show you additional information about a particular flow, including:
- The latest latency measurements for copying of data from source cluster to target cluster.
- The status of each of the Mirror Maker 2 connectors and tasks
- The configuration used to create each of the Mirror Maker 2 connectors
Additionally, you can optionally update the target latency for the data flow. This value is used to control when to alert the support team to high latency issues. We recommend you only change it in consultation with our support team.
Using Managed Mirroring for Data Migration Between Kafka Clusters
There are 2 typical use cases where customers use Instaclustr’s MirrorMaker (MM) service within the Kafka Connect cluster:
- Scenario 1: When migrating from non-Instaclustr (external) Kafka services into Instaclustr Managed Kafka services; and
- Scenario 2: When migrating a Kafka cluster from one account to another within the Instaclustr managed system, e.g., from Bring-Your-Own-Cloud (BYOC – previously RIYOA) service to Run-In-Instaclustr-Account (RIIA) service.
In both scenarios, the Virtual Private Cloud (VPC) topology can be represented by Figure 1 below:
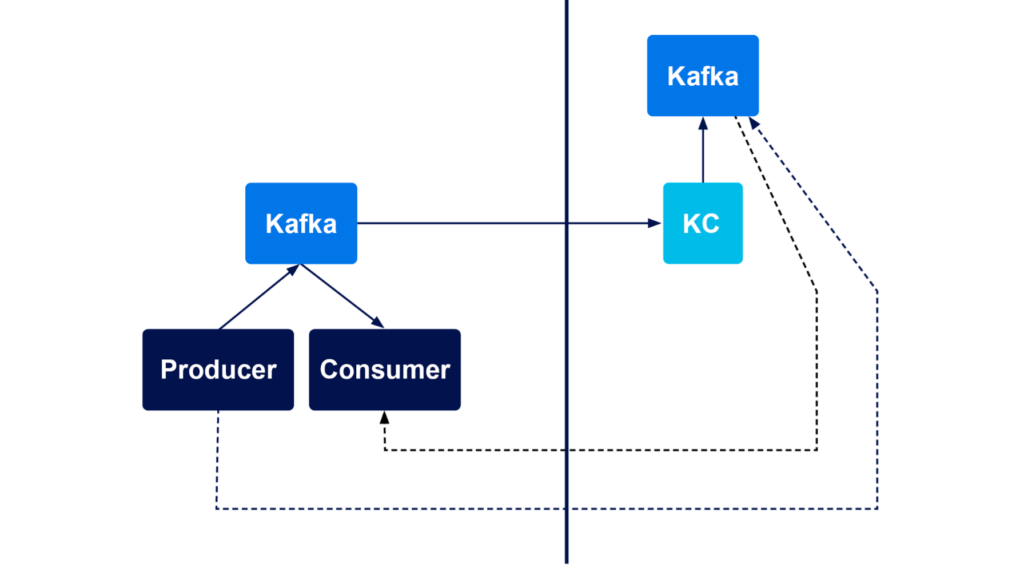
Figure 1: Source Kafka cluster is on the left and target Kafka and the Kafka Connect clusters are on the right
In Scenario 1, the source Kafka cluster is in the customer’s cloud provider infrastructure; both the target Kafka cluster and the intermediate Kafka Connect cluster are in Instaclustr’s managed cloud infrastructure (BYOC or RIIA).
In Scenario 2, the source and target Kafka clusters are in Instaclustr’s BYOC and RIIA accounts respectively, or vice-versa.
Different VPC configurations are available for our managed Kafka Connect clusters in AWS, Azure, and GCP infrastructures for establishing connection between Kafka Connect and the target Kafka cluster.
For all 3 providers, we support:
- Kafka Cluster VPC—which provisions a Kafka Connect cluster in the existing VPC of the target Kafka cluster and allows the Kafka Connect and Kafka clusters to connect over private IPs; and
- Separate VPC—which provisions Kafka Connect cluster in a new VPC and allows the 2 clusters to connect over public IPs.
For target Kafka clusters that use AWS as their provider, one additional configuration is available:
- VPC Peering, which provisions the Kafka Connect cluster in a different VPC than that of the Kafka cluster and establishes a VPC peering relationship between the 2 VPCs to allow connection by private IPs.
A visual demonstration of the infrastructures is available in this figure below:
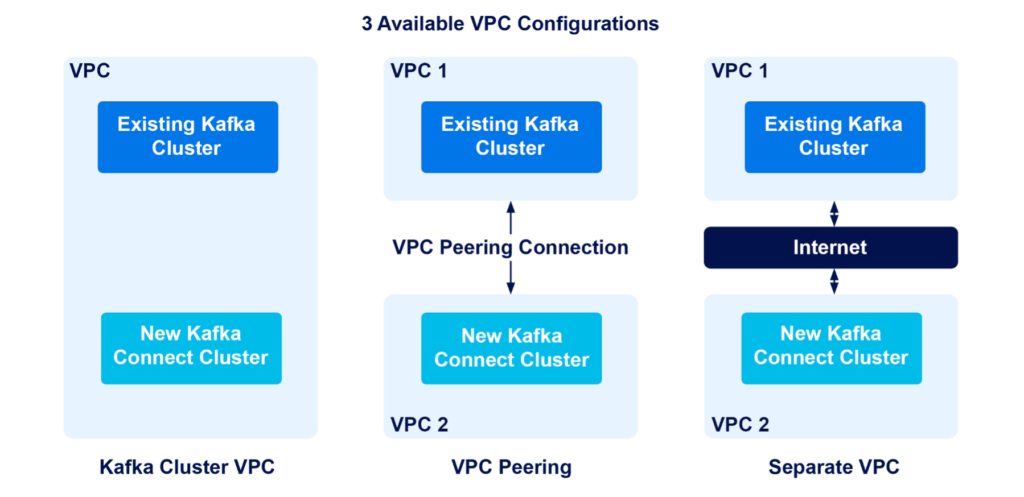
Figure 2: Different VPC configurations for setting up the Kafka Connect and target Kafka cluster
If the target Kafka cluster is a PrivateLink cluster or private network only, connection to the cluster may only be established via its private IP. Therefore, only Kafka Cluster VPC and VPC Peering are available.
Upon creation of the Kafka Connect cluster, a connection from Kafka Connect to the target Kafka cluster is established. A mirroring relationship may be created when a source Kafka cluster is specified.
Since MM can often be used for migration or scaling purposes, it is common to set up mirroring relationships between Kafka clusters that are not within the same account as the Kafka Connect cluster via our managed Kafka Connect cluster.
There are two scenarios for this:
- The source Kafka cluster is in another Instaclustr account; or
- The source Kafka cluster is hosted outside Instaclustr (e.g., a self-managed Kafka cluster)
Setup Steps
- In the Instaclustr console for the Kafka Connect cluster, record all public IP addresses of the nodes from the “Details” page
- Select the source Kafka cluster
- Go to the “Firewall Rules” page of the source Kafka cluster and add all the public IP addresses to the list
- Go to “Connection Info” page of the source Kafka cluster and copy content of the kafka.properties configuration file of the source Kafka cluster
- Go to “Connection Info” page of the source Kafka cluster and copy the node_public_ip with the public IPs of the nodes from the source Kafka cluster in the string: bootstrap.servers=<node1_public_ip>:9092, <node2_public_ip>:9092, <node3_public_ip>:9092 and add it to the start of the configuration file as an additional entry
- Go to the “Mirroring” page of the Kafka Connect cluster and select “Create New Mirror”
- Change the “Source Cluster Name” to be “Other” and put the edited configuration into the “Source Cluster Connection Properties” field. Complete other fields and click “Create Mirror”
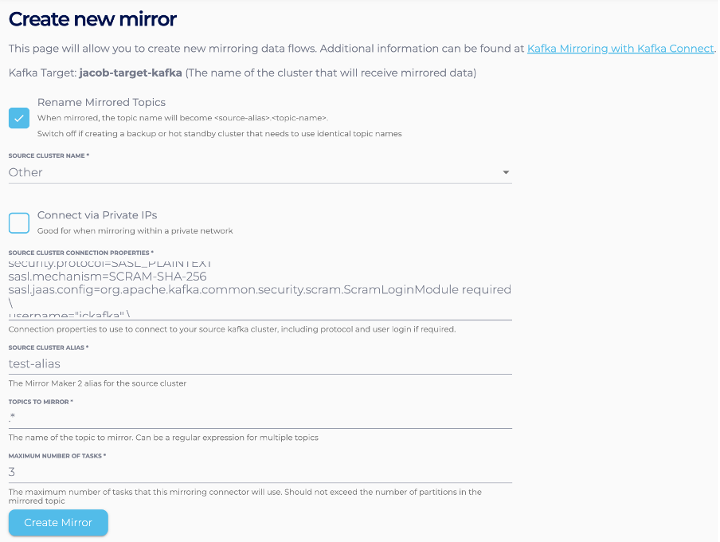
You should now see an “IN_SYNC” existing mirror on the “Mirroring” page of the Kafka Connect cluster.

Once the setup is done, customers can verify this mirroring relationship by inspecting the topics on the target Kafka cluster by running on a Kafka node:
kafka-topics.sh --list
It is expected that after a short period after this link is created (allow appropriate time for migration), there will be a replicate of the source Kafka cluster topics on the target Kafka cluster, with a prefix in their names that indicates their origin.