Monitoring at Scale Series
In this series of blogs, explore the various ways we pushed our metrics pipeline—mainly our Apache Cassandra® cluster named Instametrics—to the limit, and how we went about reducing the load it was experiencing on a daily basis over the course of several years. Beginning in 2015 and up until now, discover how Instaclustr has continued to build and expand its metrics pipeline over the years:
Vol. 1: Monitoring Apache Cassandra® and IT Infrastructure (December 2015)
Vol. 2: Upgrading Instametrics to Apache Cassandra® 3 (November 2016)
Vol. 3: The Introduction of Kafka® (January 2022)
Vol. 4: Using Redis™ as a Cassandra® Cache (March 2022)
Vol. 5: Upgrading our Instametrics Cassandra® Cluster from 3.11.6 to 4.0 (June 2022)
In this blog we go through how our team tackled a zero-downtime upgrade of our internal Cassandra 3.11.6 to Cassandra 4.0, in order for them to get real production experience and expertise in the upgrade process. We were even able to utilize our Kafka monitoring system to perform some blue green testing, giving us greater confidence in the stability of the Cassandra 4.0 release.
One of the major projects for our Cassandra team over the last 12 months has been preparing for the release of Cassandra 4.0. This release had improved built-in auditing, made significant improvements to the speed of streaming, enhanced Java 11 compatibility, facilitated auditing out of the box, and more. However, we needed to be sure that before the version was deployed onto our customers’ production mission critical clusters, we were confident that it would have the same level of performance and reliability as the 3.X releases.
The first thing that we did was make sure that we had beta releases on our managed platform to trial, before the project had officially released 4.0. This meant that customers could provision a 4.0 cluster, in order to perform initial integration testing on their applications.
It is worth noting that as part of introducing the Cassandra 4.0 beta to the Instaclustr managed platform we did have to do some work on upgrading our tooling. This included ensuring that metrics collection continued to operate correctly, accounting for any metrics which had been renamed, as well as updates to our subrange repair mechanism. We also submitted some patches to the project in order to make the Cassandra Lucene plugin 4.0 compatible.
We knew that as we got closer to the official project release we would want to have real-world experience upgrading, running, and supporting a Cassandra 4.0 cluster under load. For this, we turned to our own internal Instametrics Cassandra cluster, which stores all of our metrics for all our nodes under management.
This was a great opportunity to put our money where our mouth was when it came to Cassandra 4.0 being ready to be used by customers. Our Cassandra cluster is a critical part of our infrastructure however, so we needed to be sure that our method for upgrading was going to cause no application downtime.
How We Configured Our Test Environment
Like most other organizations, Instaclustr maintains a separate but identical environment for our developers to test their changes in, before being released to our production environment. Our production environment supports around 7000 instances, where our test environment is usually somewhere around 70 developer test instances. So, whilst it is functionally identical, the load is not.
Part of this is a duplication of the Instametrics Cassandra Cluster, albeit at a much smaller scale of 3 nodes.
Our plan for testing in this environment was reasonably straightforward:
- Create an identical copy of our cluster by restoring from backup to a new cluster using the Instaclustr Managed Platform
- Upgrade the restored cluster from 3.X to 4.0, additionally upgrading the Spark add-on
- Test our aggregation Spark jobs on the 4.0 cluster, as well as reading and writing from other applications which integrate with the Cassandra cluster
- Switch over the test environment from using the 3.x cluster to the 4.0 cluster
Let’s break down these steps slightly, and outline why we chose to do each one.
The first step is all about having somewhere to test, and break, without affecting the broader test environment. This allowed our Cassandra team to take their time diagnosing any issues without affecting the broader development team, who may require a working metrics pipeline in order to progress their other tickets. The managed platform automated restore makes this a trivial task, and means we can test on the exact schema and data inside our original cluster.
When it came to upgrading the cluster from 3.X to 4.0, we discussed with our experienced Technical Operations team the best methodology to upgrade Cassandra Clusters. Our team is experienced in both major and minor version bumps with Cassandra, and outlined the methodology used on our managed platform. This meant that we could test that our process would still be applicable to the upgrade to 4.0. We were aware that the schema setting “read_repair_chance” had been removed as part of the 4.0 release, and so we updated our schema accordingly.
Finally, it was time to check that our applications, and their various Cassandra drivers, would continue to operate when connecting to Cassandra 4.0. Cassandra 4.0 has upgraded to using native protocol version 5, which some older versions of Cassandra drivers could not communicate with.
There was a small amount of work required for us to upgrade our metric aggregation Spark jobs in order to work with the newer version of Spark, which was required for us upgrading our Spark Cassandra driver. Otherwise, all of our other applications continued to work without any additional changes. These included applications using the Java, Python, and Clojure drivers.
Once we had completed our integration testing in our test environment, we switched over all traffic in the test environment from our 3.X cluster to the new 4.0 cluster. In this situation we did not copy over any changes which were applied to the 3.X cluster in between restoring the backup, and switching over our applications. This was strictly due to this being a test environment, and these not being of high importance.
We continued to leave this as the cluster being used in our test environment, in order to see if any issues would slowly be uncovered after an extended time. We began working on our plan for upgrading our production cluster to the 4.0 release.
Although we had initially intended to release the Cassandra 4.0.0 version to our Cassandra cluster as soon as it was available, unfortunately due to a nasty bug in the 4.0.0 release, we decided to delay this until a patch could be raised against it.
The silver lining here was that due to additional work on our metrics pipeline being deployed, we had additional options for testing a production load on a Cassandra 4.0 cluster. As we covered in an earlier blog, we had deployed a Kafka architecture in our monitoring pipeline, including a microservice who writes all metrics to our Cassandra cluster.
What this architecture allows us to do is effectively have many application groups consume the same stream of metrics from Kafka, with a minimal performance impact. We have already seen how we had one consumer writing these metrics to Cassandra, and another which writes it to a Redis cache.
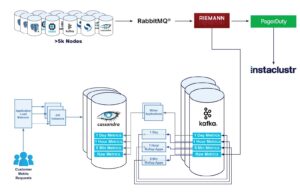
So, what’s the big benefit here? Well, we can duplicate the writes to a test Cassandra cluster, while we perform the upgrade! Effectively giving us the ability to perform a test upgrade on our actual live production data, with no risk to console downtime or customer issues! All we have to do is create an additional Cassandra cluster, and an additional group of writer applications.
So, we deployed an additional 3.11.6 Cassandra cluster which was configured identically to our existing Instametrics Cassandra cluster, and applied the same schema. We then configured a new group of writer applications, which would perform the exact same operations, on the same data, as our “live” production Cassandra cluster. In order to put a read load on the cluster, we also set up a Cassandra Stress instance to put a small read load on the cluster. We then left this running for a number of days in order to place an appropriate amount of data into the cluster for the upgrade.
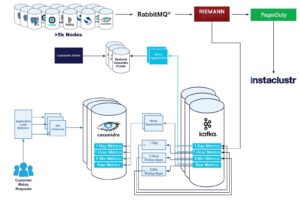
The Test Upgrade
Now came the fun part! Upgrading our test Cassandra cluster from 3.X to 4.0, while under load. We applied our upgrade procedure, paying careful attention to any application side errors from either of our writers, or Cassandra stress. Cassandra by design should be able to perform any upgrade, major or minor, without any application side errors if your data model is designed correctly.
We did not experience any issues or errors during our test upgrade procedure, and the upgrade process was a successful operation! We did see slightly elevated CPU usage and OS load during the upgrade process, but that is to be expected due to upgrading sstables, running repairs, and a reduction in available nodes during the upgrade.
In order to gain further confidence in the system, we also left this configuration running for a number of days. This was to ascertain if there was any performance or other issues with longer running operations such as compactions or repairs. Again, we did not see any noticeable impacts or performance drops across the two clusters when running side by side.
The Real Upgrade
Filled with confidence in our approach, we set out to apply the exact same process to our live production cluster, with much the same effect. There was no application downtime, and no issues with any operation during the upgrade process. Keeping a watchful eye on the cluster longer term, we did not see any application-side latency increases, or any other issues other than the elevated CPU usage and OS load we saw on the test cluster.
Once completed, we removed our additional writer infrastructure that had been created.
Wrapping Up
It has now been a number of months since we upgraded our Cassandra cluster to 4.0.1, and we have not experienced any performance or stability issues. Cassandra 4.0.1 continues to be our recommended version that customers should be using for their Cassandra workloads.
Need help with your Apache Cassandra database?