






















In the last blog, we demonstrated a complete end to end example using the Instaclustr Provisioning API, which included dynamic Cassandra cluster resizing. This blog picks up where we left off and explores dynamic resizing in more detail.
1. Dynamic Resizing
Let’s recap how Instaclustr’s dynamic Cassandra cluster resizing works. From our documentation:
- Cluster health is checked Instaclustr’s monitoring system including synthetic transactions.
- The cluster’s schema is checked to ensure it is configured for the required redundancy for the operation.
- Cassandra on the node is stopped, and the AWS instance associated with the node is switched to a smaller or larger size, retaining the EBS containing the Cassandra data volume, so no data is lost.
- Cassandra on the node is restarted. No restreaming of data is necessary.
- Monitor the cluster to wait until all nodes have come up cleanly and have been processing transactions for at least one minute (again, using our synthetic transaction monitoring) and then move on to the next nodes.
Steps 1 and 2 are performed once per cluster resize, steps 3 and 4 are performed for each node, and step 5 is performed per resize operation. Nodes can be resized one at a time, or concurrently, in which case multiple steps 3 and 4 are performed concurrently. Concurrent resizing allows up to one rack at a time to be replaced for faster overall resizing.
Last blog we ran the Provisioning API demo for a 6 node cluster (3 racks, 2 nodes per rack), which included dynamic cluster resizing one node at a time (concurrency = 1). Here it is again:
Welcome to the automated Instaclustr Provisioning API Demonstration
We’re going to Create a cluster, check it, add a firewall rule, resize the cluster, then delete it
STEP 1: Create cluster ID = 5501ed73-603d-432e-ad71-96f767fab05d
racks = 3, nodes Per Rack = 2, total nodes = 6
Wait until cluster is running…
progress = 0.0%………………….progress = 16.666666666666664%……progress = 33.33333333333333%…..progress = 50.0%….progress = 66.66666666666666%……..progress = 83.33333333333334%…….progress = 100.0%
Finished cluster creation in time = 708s
STEP 2: Create firewall rule
create Firewall Rule 5501ed73-603d-432e-ad71-96f767fab05d
Finished firewall rule create in time = 1s
STEP 3 (Info): get IP addresses of cluster: 3.217.63.37 3.224.221.152 35.153.249.73 34.226.175.212 35.172.132.18 3.220.244.132
STEP 4 (Info): Check connecting to cluster…
TESTING Cluster via public IP: Got metadata, cluster name = DemoCluster1
TESTING Cluster via public IP: Connected, got release version = 3.11.4
Cluster check via public IPs = true
STEP 5: Resize cluster…
Resize concurrency = 1
progress = 0.0%………………………………………………………progress = 16.666666666666664%………………………..progress = 33.33333333333333%……………………….progress = 50.0%……………………….progress = 66.66666666666666%………………………………………..progress = 83.33333333333334%………………………….progress = 100.0%
Resized data centre Id = 50e9a356-c3fd-4b8f-89d6-98bd8fb8955c to resizeable-small(r5-xl)
Total resizing time = 2771s
STEP 6: Delete cluster…
Deleting cluster 5501ed73-603d-432e-ad71-96f767fab05d
Delete Cluster result = {“message”:”Cluster has been marked for deletion.”}
*** Instaclustr Provisioning API DEMO completed in 3497s, Goodbye!
This time we’ll run it again with concurrency = 2. Because we have 2 nodes per rack, this will resize all the nodes in each rack concurrently before moving onto the next racks.
Welcome to the automated Instaclustr Provisioning API Demonstration
We’re going to Create a cluster, check it, add a firewall rule, resize the cluster, then delete it
STEP 1: Create cluster ID = 2dd611fe-8c66-4599-a354-1bd2e94549c1
racks = 3, nodes Per Rack = 2, total nodes = 6
Wait until cluster is running…
progress = 0.0%………………..progress = 16.666666666666664%…..progress = 33.33333333333333%…..progress = 50.0%…..progress = 66.66666666666666%…….progress = 83.33333333333334%…….progress = 100.0%
Finished cluster creation in time = 677s
STEP 2: Create firewall rule
create Firewall Rule 2dd611fe-8c66-4599-a354-1bd2e94549c1
Finished firewall rule create in time = 1s
STEP 3 (Info): get IP addresses of cluster: 52.44.222.173 54.208.0.230 35.172.244.249 34.192.193.34 3.214.214.142 3.227.210.169
STEP 4 (Info): Check connecting to cluster…
TESTING Cluster via public IP: Got metadata, cluster name = DemoCluster1
TESTING Cluster via public IP: Connected, got release version = 3.11.4
Cluster check via public IPs = true
STEP 5: Resize cluster…
Resize concurrency = 2
progress = 0.0%…………………….progress = 16.666666666666664%….progress = 33.33333333333333%………………………progress = 50.0%….progress = 66.66666666666666%……………………..progress = 83.33333333333334%…..progress = 100.0%
Resized data centre Id = ae984ecb-0455-42fc-ab6d-d7eccadc6f94 to resizeable-small(r5-xl)
Total resizing time = 1177s
STEP 6: Delete cluster…
Deleting cluster 2dd611fe-8c66-4599-a354-1bd2e94549c1
Delete Cluster result = {“message”:”Cluster has been marked for deletion.”}
*** Instaclustr Provisioning API DEMO completed in 1872s, Goodbye!
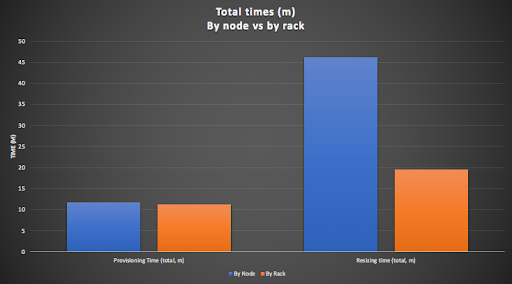
This graph compares these two results, and shows the total time (in minutes) for provisioning and dynamically resizing the cluster. The provisioning times are similar, and the resizing times are longer. Resizing by rack is 2.35 times faster than resizing by node (19 minutes c.f. 47 minutes).
This is a graph of the resize time for each unit of resize (nodes, or rack). There are 6 resize operations (by node) and 3 (by rack, 2 nodes at a time). Each rack resize operation is actually slightly shorter than each node resize operation. There is obviously some constant overhead per resize operation, on top of the actual time to resize each node. In particular (Step 5 above) the cluster is monitored for at least a minute after each resizing operation, before moving onto the next operation.
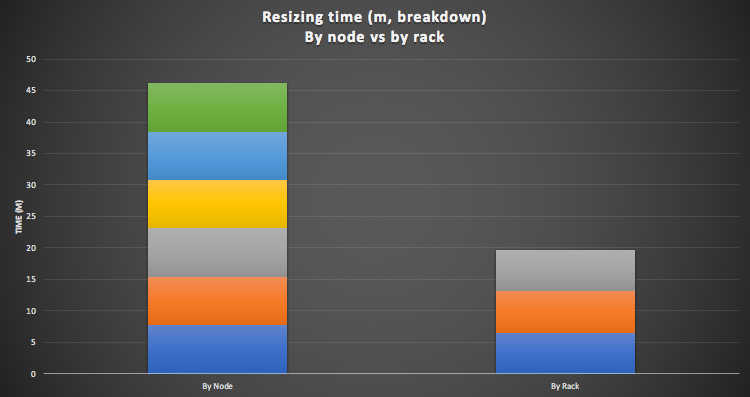
In summary, cluster resizing by rack is significantly faster than by node, as multiple nodes in a rack can be resized concurrently (up to the maximum number of nodes in the rack), and each resize operation has an overhead, so a smaller number of resize operations are more efficient.
2. Dynamics of Resizing
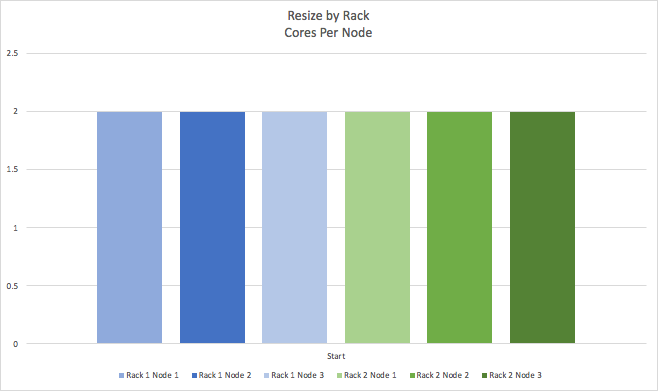
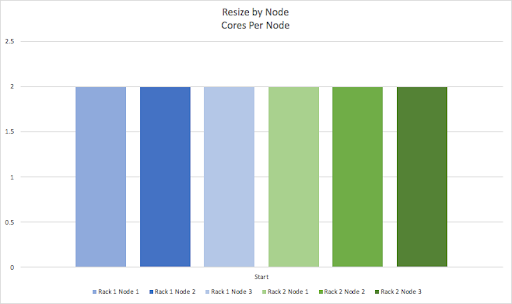
What actually happens to the cluster during the resize? The following graphs visualize the dynamics of the cluster resizing over time, by showing the change to the number of CPU cores for each node in the cluster. For simplicity, this cluster has 2 racks (represented by blue and green bars) with 3 nodes per rack, so 6 nodes in total. We’ll start with the visually simplest case of resizing by rack. This is the start state. Each node in a rack starts with 2 CPU cores.
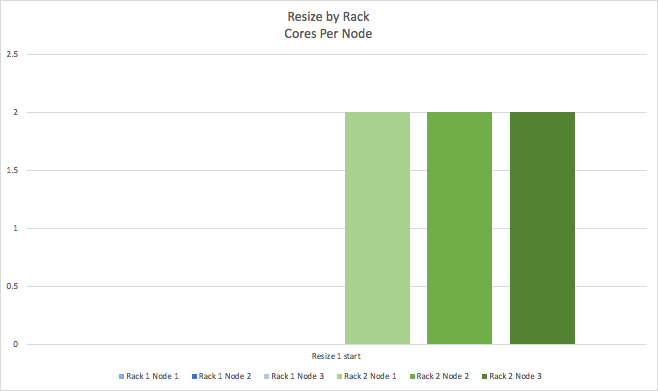
At the start of the first rack resize all the nodes in the first rack (blue) are reduced to 0 cores.
By the end of the first resize, all of the 2 core nodes in the first rack have been resized to 4 core nodes (blue).
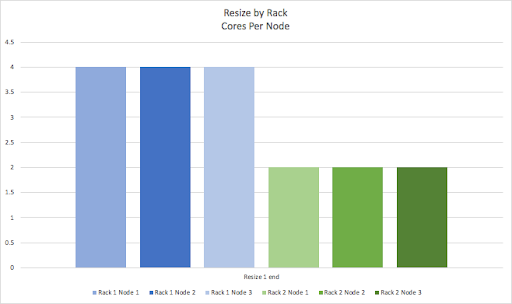
The same process is repeated for the second rack (green).
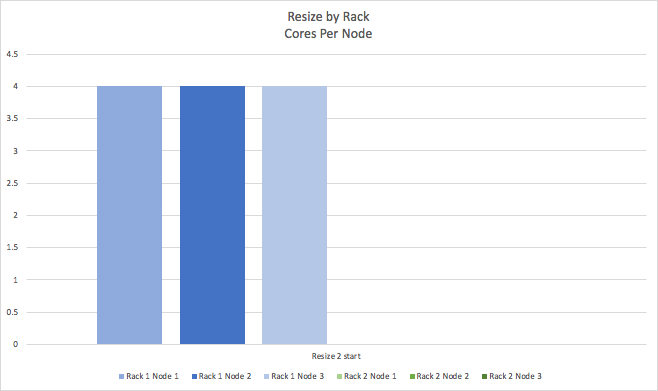
So that we end up with a cluster than has 4 cores per node.
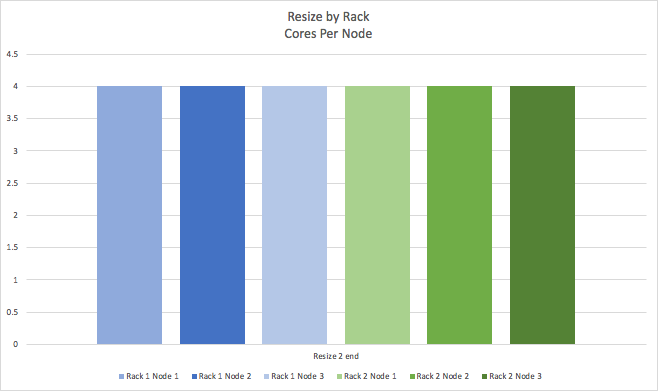
Next we’ll show what happens doing resize by node. It’s basically the same process, but as only one node at a time is resized there are more operations (we only show the 1st and the 6th). The initial state is the same, with all nodes having 2 cores per node.
At the start of the first resize, one node is reduced to 0 cores.
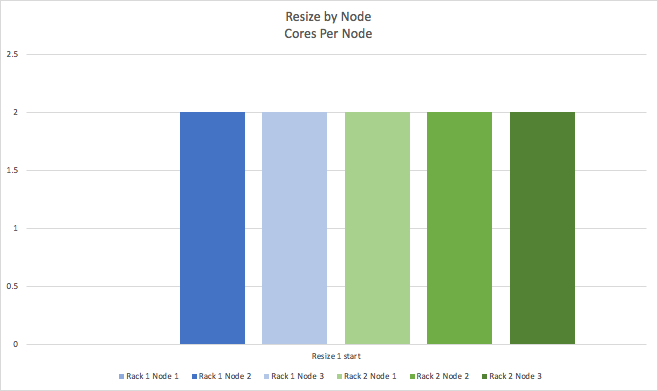
And at the end of the operation, this node has been resized to 4 cores.
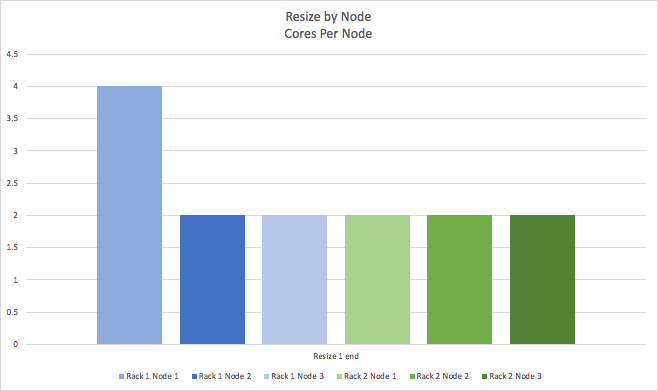
This process is repeated (not shown) for the remaining cores, until we start the 6th and last resize operation:
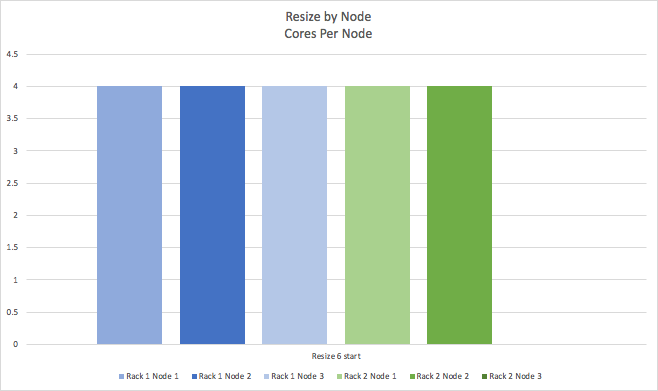
Again resulting in the cluster being resized to 4 cores per node.
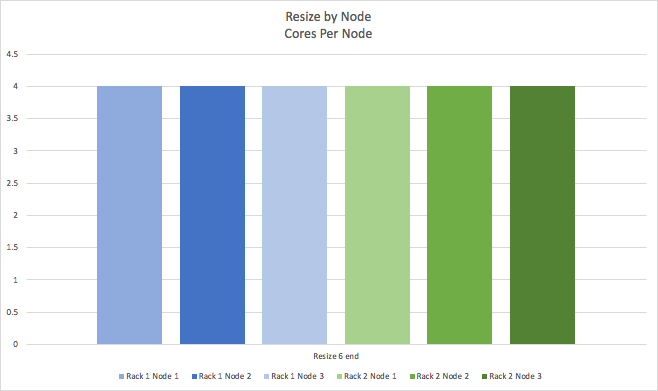
These graphs show that during the initial resize operation there is a temporary reduction in total cluster capacity. The reduction is more substantial when resizing by rack, as a complete rack is unavailable until it’s resized (3/6 nodes = 50% initial capacity for this example), than if resizing by node, as only 1 node at a time is unavailable (⅚ nodes = 83% initial capacity for this example).
3. Resizing Modeling
In order to give more insight into the dynamics of resizing we built a simple time vs. throughput model for dynamic resizing for Cassandra clusters. It shows the changing capacity of the cluster as nodes are resized up from 2 to 4 core nodes. It can be used to better understand the differences between dynamic resizing by node or by rack. We assume a cluster with 3 racks, 2 nodes per rack, and 6 nodes in total.
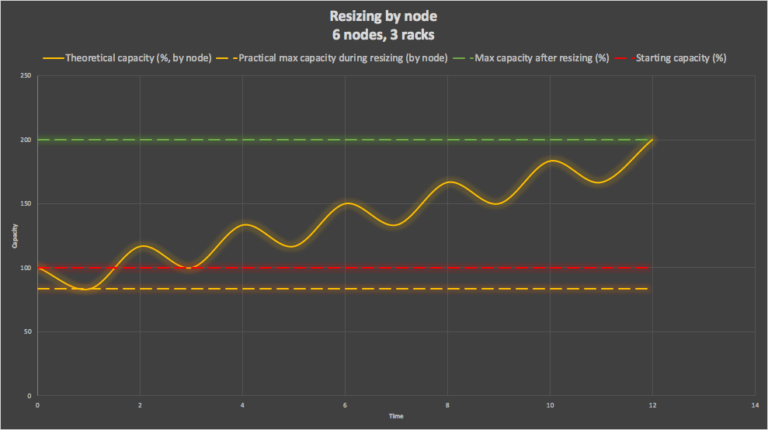
First, let’s look at resizing one node at a time. This graph shows time versus cluster capacity. We assume 2 units of time per node resize (to capture the start, reduced capacity, and end, increased capacity—states of each operation as in the above graphs). The initial cluster capacity is 100% (dotted red line), and the final capacity will be 200% (dotted green line). As resizing is by node, initially 1 node is turned off, and eventually replaced by a new node with double the number of cores. However, during the 1st resize, only 5 nodes are available, so the capacity of the cluster is temporarily reduced to ⅚th of the original throughput (83%, the dotted orange line). After the node has been replaced the theoretical total capacity of the cluster has increased to 116% of the original capacity. This process continues until all the nodes have been resized (note that for simplicity we’ve approximated the cluster capacity as a sine wave, in reality it’s an asymmetrical square wave).
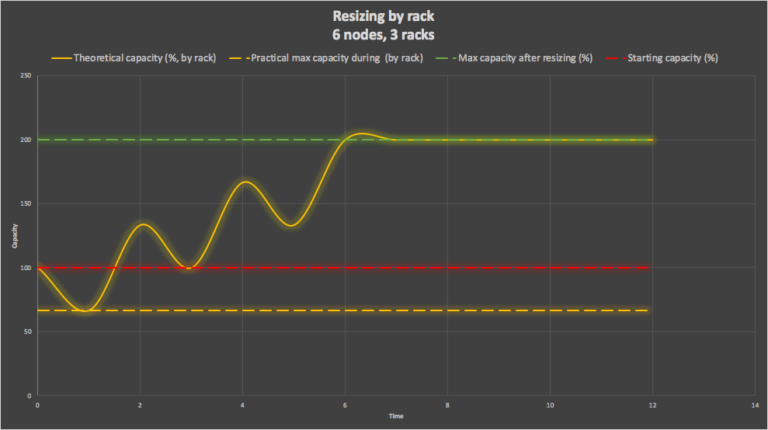
The next graph shows resizing by rack. For each resize, 2 nodes are replaced concurrently. During the 1st rack resize the capacity of the cluster is reduced more than for the single node resize, to 4/6th of the original throughput (67%). After two nodes have been replaced the theoretical capacity of the cluster has increased to 133% of the original capacity. So, for rack resizing the final theoretical maximum capacity is still double the original, but it happens faster, and we lose more (⅓) of the starting capacity during the 1st rack resize.
The model has 2 practical implications (irrespective of what type of resizing is used). First, the maximum practical capacity of the cluster during the initial resize operation will be less than 100% of the initial cluster capacity. Exceeding this load during the initial resize operation will overload the cluster and increase latencies. Second, even though the theoretical capacity of the cluster increases as more resize operations are completed, the practical maximum capacity of the cluster will be somewhat less. This is because Cassandra load balancing assumes equal sized nodes, and is therefore unable to perfectly load balance requests across the heterogeneous node sizes. As more nodes are resized there is an increased chance of a request hitting one of the resized nodes, but the useable capacity is still impacted by the last remaining original small node (resulting in increased latencies for requests directed to it). Eventually when all the nodes have been resized the load can safely be increased as load balancing will be back to normal due to homogeneous node sizes.
The difference between resizing by node and by rack is clearer in the following combined graph (resizing by node, blue, by rack, orange):
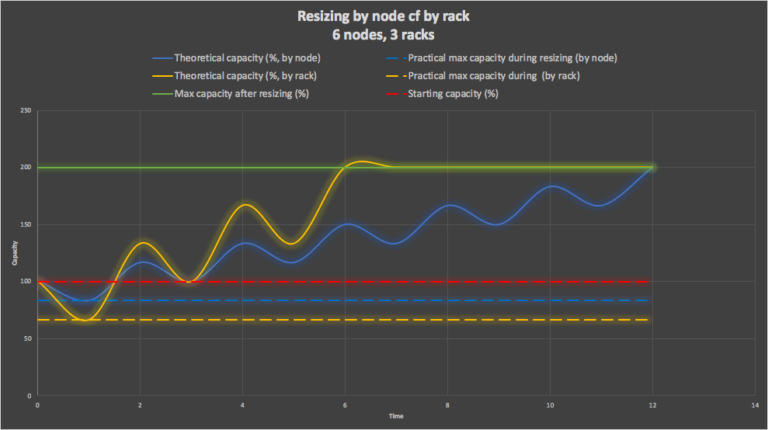
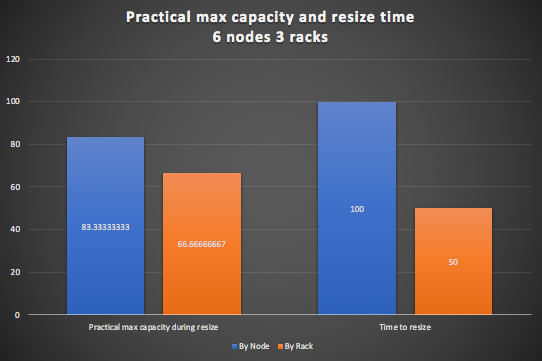
In summary, it shows that resizing by rack (orange) is faster but has a lower maximum capacity during the first resize operation. This graph summaries these two significant differences (practical maximum capacity during first resize operation, and relative time to resize the cluster).
What happens if you have different sized clusters (number of nodes)? This graph shows that the maximum useable capacity during resizing by node, ranges from 0.5 to 0.93 of the original capacity with increasing numbers of nodes (from 2 to 15). Obviously the more nodes the cluster has the less impact there is if only one node is resized at a time.
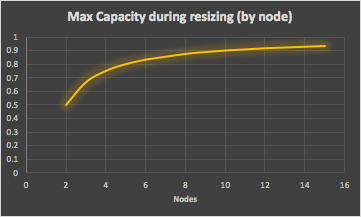
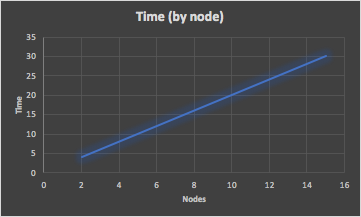
The problem with resizing by node is that the total cluster resizing time is linearly increasing, so prohibitively high for larger clusters.
4. Auto Scaling Cassandra Elasticity
Another use case for the Instaclustr Provisioning API is to use it for automating Cassandra Elasticity, by initiating dynamic resizing on demand. A common use case for dynamic scaling is to increase capacity well in advance for predictable loads such as weekend batch jobs or peak shopping seasons. Another less common use case is when the workload unexpectedly increases and the resizing has to be more dynamic. However, to do this you need to know when to trigger a resize, and what type of resize to trigger (by node or rack). Another variable is how much to resize by, but for simplicity we’ll assume we only resize from one instance size up to the next size (the analysis can easily be generalized).
We assume that the Instaclustr monitoring API is used to monitor Cassandra cluster load and utilization metrics. A very basic auto-scaling mechanism could trigger a resize based on exceeding a simple threshold cluster utilization. The threshold would need to be set low enough so that the load doesn’t exceed the reduced load due to the initial resize operation. This obviously has to be lower for resize by rack than by node, which could result in the cluster having lower utilization than economical, and “over-eager” resizing. A simple threshold trigger also doesn’t help you decide which type of resize to perform (although a simple rule of thumb may be sufficient to decide, e.g. if you have more than x nodes in the cluster then always resize by rack, else by node).
Is there a more sophisticated way of deciding when and what type of resize to trigger? Linear regression is a simple way of using past data to predict future trends, and has good support in the Apache Maths library. Linear regression could therefore be run over the cluster utilization metrics to predict how fast the load is changing.
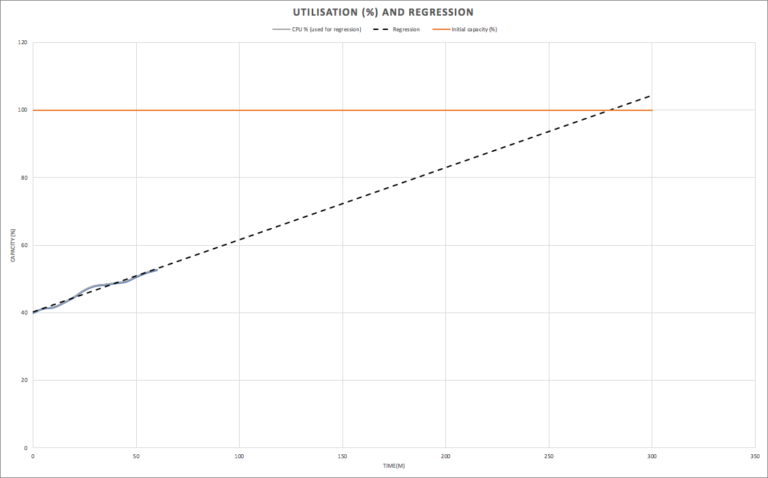
This graph shows the maximum capacity of the cluster initially (100%). The utilization of the cluster is measured for 60 minutes, and the load appears to be increasing. A linear regression line is computed to predict the expected load in the future (dotted line). The graph shows that we predict the cluster will reach 100% capacity around the 280 minute mark (220 minutes in the future).
What can we do to preempt the cluster being overloaded? We can initiate a dynamic resize sufficiently ahead of the predicted time of overload to preemptively increase the cluster capacity. The following graphs show autoscaling (up) using the Instaclustr Provisioning API to Dynamically Resize Cassandra clusters from one r5 instance size to the next size up in the same family. The capacity of the cluster is 100% initially, and is assumed to be double this (200%) once the resize is completed. The resize times are based on the examples above (but note that there may be some variation in practice), for a 6 node cluster with 3 racks.
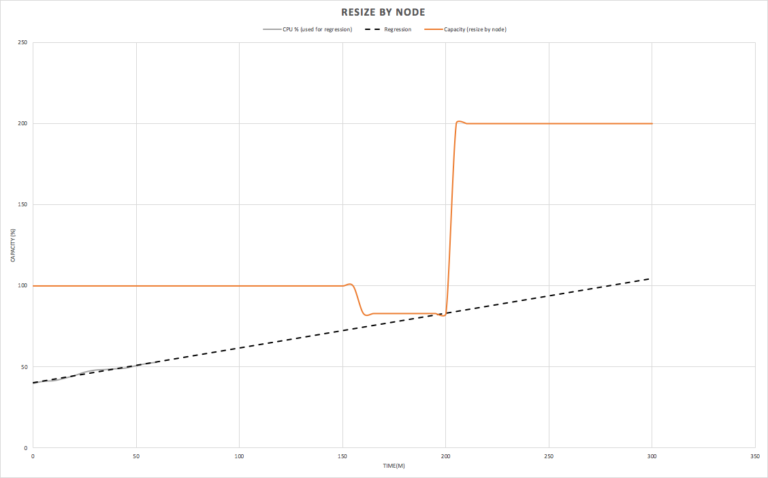
The first graph shows resize by node (orange). As we discovered above, the effective maximum capacity during a resize by node is limited to 83% of the initial capacity, and the total time to resize was measured at 47 minutes. We therefore need to initiate a cluster resize by node (concurrency=1) at least 47 minutes prior (at the 155 minute mark) to the time that the regression predicts we’ll hit a utilization of 83% (200m mark), as shown in this graph:
The second graph shows resizing by rack. As we discovered above, the maximum capacity during a resize by rack is limited to 67% of the initial capacity, and the total time to resize was measured at 20 minutes. We therefore need to initiate a cluster resize by rack at least 20 minutes prior (at the 105 minute mark) to the time that the regression predicts we’ll hit a utilization of 67% (125m mark), as shown in this graph:
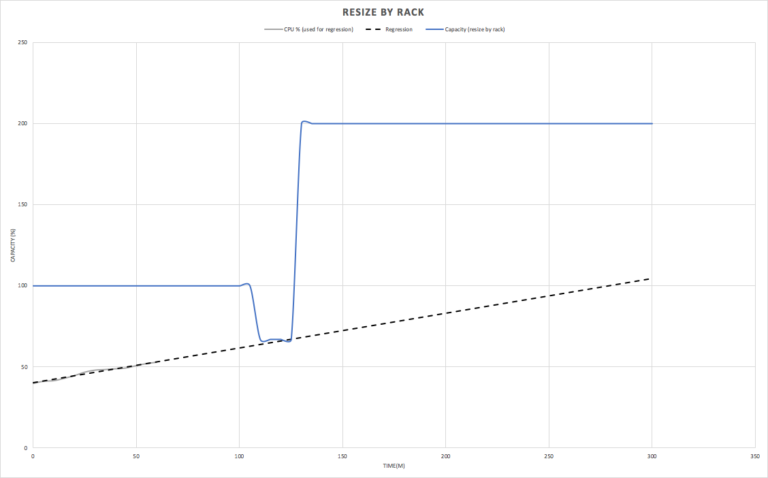
This graph shows the comparison, and reveals that resize by rack (blue) must be initiated sooner (but completes faster) than resize by node (orange).
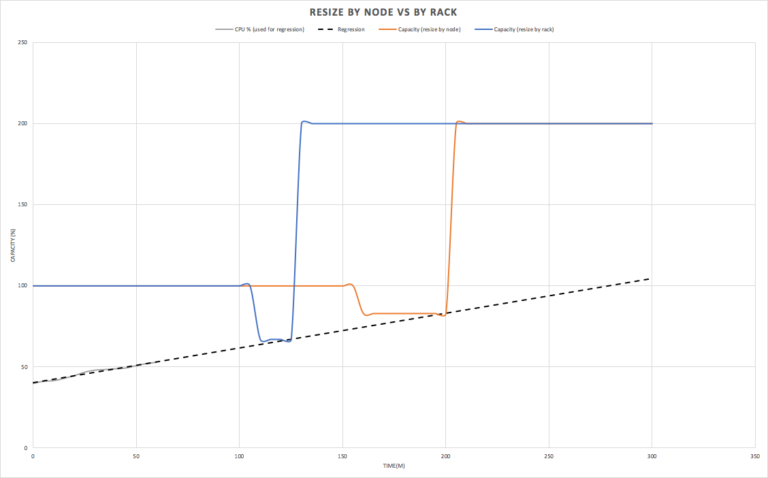
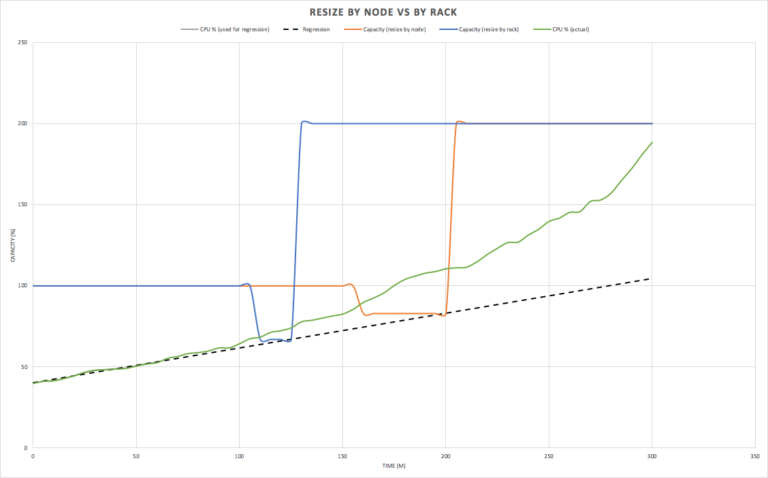
How well does this work in practice? Well, it depends on how accurate the linear regression is. In some cases the load may increase faster than predicted, in other cases slower than predicted, or may even drop off. For our randomly generated workload it turns out that the utilization actually increases faster than predicted (green), and both resizing approaches were initiated too late, as the actual load had increased to higher than safe load for either resize types.
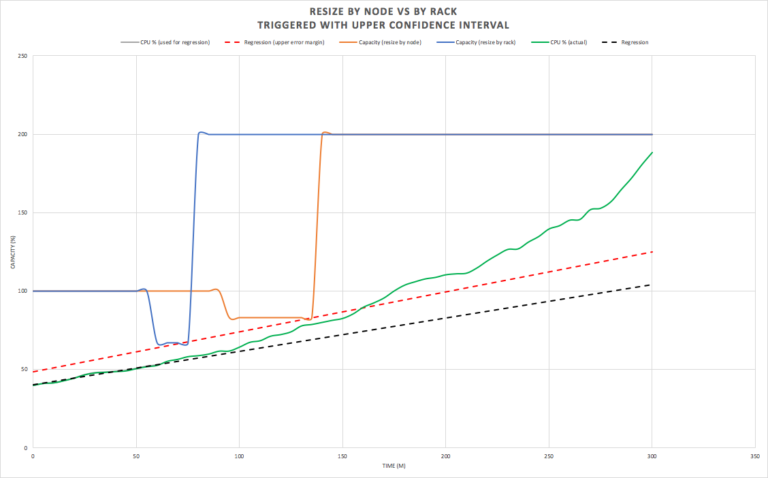
What could we do better? Resizing earlier is obviously advantageous. A better way of using linear regression is to compute confidence intervals (and is included in Apache Maths). The following graph shows a 90% upper confidence interval (red dotted line). Using this line for the predictions to trigger resizes results in earlier cluster resizing (at the 60 and 90 minute marks. The resize by rack (blue) is now triggered immediately after the 60 minutes of measured data is evaluated), resulting in the resizing operations being completed by the time the load becomes critical as shown in this graph:
The potential downside of using a 90% confidence interval to trigger the resize is that it’s possible that the actual utilization never reaches the predicted value. For example, here’s a different run of randomly generated load showing a significantly lower actual utilization (green). In this case it’s apparent that we’ve resized the cluster far too early, and the cluster may even need to be resized down again depending on the eventual trend.
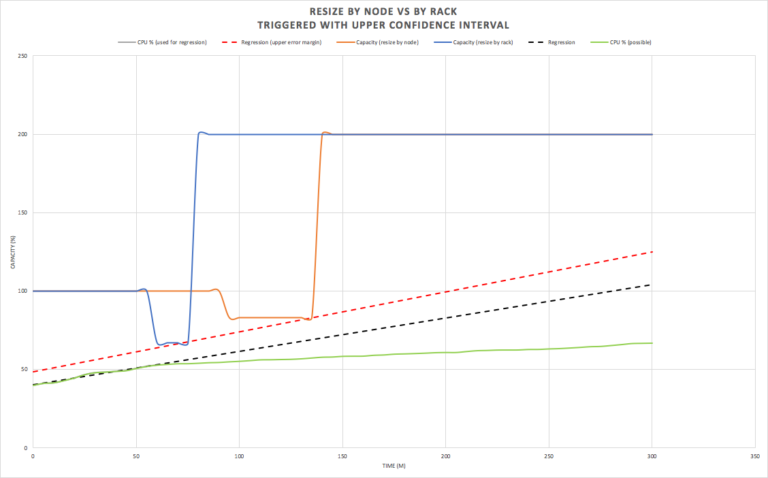
The risk of resizing unnecessarily can be reduced by ensuring that the regressions are regularly recomputed (e.g. every 5 minutes), and resizing requests are only issued just in time. For example, in this case the resize by node would not have been requested if the regression was recomputed at the 90 minute mark, using only the previous 60 minutes of data, and extrapolated 60 minutes ahead, as the upper confidence interval is only 75%, which is less than the 83% trigger threshold for resizing by node.
5. Resizing Rules—by node or rack
As a thought experiment (not tested yet) I’ve developed some pseudo code rules for deciding when and what type of upsize to initiate, assuming the variables are updated every 5 minutes, and correct values have been set for a 6 node (3 rack, 2 nodes per rack) cluster.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | now = current time load = current utilisation (last 5m) rack_threshold = 67% (for 3 racks), in general = 100 - ((1/racks)<em>100) node_threshold = 83% (for 6 nodes), in general = 100 - ((1/nodes)</em>100) rack_resize_time = 25m (rounded up) node_resize_time = 50m (rounded up) predict_time_rack_threshold (time when rack_threshold utilisation is predicted to be reached) predict_time_node_threshold (time when node_threshold utilisation is predicted to be reached) predicted_load_increasing = true if regression positive else negative sufficient_time_for_rack_resize = (predict_time_rack_threshold - rack_resize_time) > now sufficient_time_for_node_resize = (predict_time_node_threshold - node_resize_time) > now trigger_rack_resize_now = (predict_time_rack_threshold - rack_resize_time) <= now trigger_node_resize_now = (predict_time_node_threshold - node_resize_time) <= now 1 Every 5 minutes recompute linear regression function (upper 90% confidence interval) from past 60 minutes of cluster utilisation metrics and update the above variables. 2 IF predict_load_increasing THEN IF load < rack_threshold AND NOT sufficient_time_for_node_resize AND trigger_rack_resize_now THEN TRIGGER RACK RESIZE to next size up (if available) WAIT for resize to complete ELSE IF load < node_threshold AND trigger_node_resize_now THEN TRIGGER NODE RESIZE to next size up (if available) WAIT for resize to complete |
How does the rule work? The general idea is that if the load is increasing we may need to upsize the cluster, but the type of resize (by rack or by node) depends on the current load and the time remaining to safely do the different types of resizes. We also want to leave a resize as late as possible in case the regression prediction changes signalling that we don’t really need to resize yet.
If the current load is under the resize by rack threshold (67%), then both options are still possible, but we only trigger the rack resize if there is no longer sufficient time to do a node resize, and it’s the latest possible time to trigger it.
However, if the load has already exceeded the safe rack resize threshold and it’s the latest possible time to trigger a node resize, then trigger a node resize.
If the load has already exceeded the safe node threshold then it’s too late to resize and an alert should be issued. An alert should also be issued if the cluster is already using the largest resizeable instances available as dynamic resizing is not possible.
Also note that the rack and node thresholds above are the theoretical best case values, and should be reduced for a production cluster with strict SLA requirements to allow for more headroom during resizing, say by 10% (or more). Allowing an extra 10% headroom reduces the thresholds to 60% (by rack) and 75% (by node) for the 6 node, 3 rack cluster example.
If you resize a cluster up you should also implement a process for “downsizing” (resizing down).
This works in a similar way to the above, but because downsizing (eventually) halves the capacity, you can be more conservative about when to downsize. You should trigger it when the load is trending down, and when the capacity is well under 50% so that an “upsize” isn’t immediately triggered after the downsize (e.g. triggering at 40% will mean that the downsized clusters are running at 80% at the end of the downsize, assuming the load doesn’t drop significantly during the downsize operation). Note that you also need to wait until the metrics for the resized cluster have stabilized otherwise the upsizing rules will be triggered (as it will incorrectly look like the load has increased).
After an upsizing has completed you should also wait for close to the billing period for the instances (e.g. an hour) before downsizing, as you have to pay for them for an hour anyway so there’s no point in downsizing until you’ve got value for money out of them, and this gives a good safety period for the metrics to stabilize with the new instance sizes.
Simple downsizing rules (not using any regression or taking into account resize methods) would look like this:
1 2 3 4 5 | 3 IF more than an hour size last resize up complete AND NOT predict_load_increasing THEN IF load < 40% THEN TRIGGER RACK RESIZE to next size down (if available) WAIT for resize to complete + some safety margin |
We’ve also assumed a simple resize step from one size to the next size up. The algorithm can be easily adapted to resize from/to any size instances in the same family, which would be useful if the load is increasing more rapidly and is predicted to exceed the capacity of a single jump in instances sizes in the available time (but in practice you should do some benchmarking to ensure that you know the actual capacity improvement for different instance sizes).
6. Resizing Rules—any concurrency
We above analysis assumes you can only size by node or rack. In practice, concurrency can be any integer value between 1 and the number of nodes per rack, so you can resize by part rack concurrently. In practice, resizing by part rack may be the best choice as it can mitigate against losing quorum and is reasonable fast (if a “live” node fails during resizing you can lose quorum, the more nodes resized at once, the greater the risk). These rules can therefore be generalized as follows, with resize by node and rack now just edge cases. We keep track of the Concurrency which starts from an initial value equal to the number of nodes per rack (resize by “rack”) and eventually decreases to 1 (resize by “node”). We also now have a couple of functions that compute values for different values of concurrency, basically the current concurrency and the next concurrency (concurrency – 1). Depending on the number of nodes per rack, some values of concurrency will have different threshold values but the same resize time (if the number of nodes isn’t evenly divisible by concurrency).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | now = current time load = current utilisation (last 5m) racks = number of racks (e.g. 3) nodes_per_rack = number of nodes per rack (e.g. 10) total_nodes = racks * nodes_per_rack concurrency = nodes_per_rack threshold(C) = 100 - ((C/total_nodes) * 100) resize_operations(C) = roundup(nodes_per_rack/C) * racks resize _time(C) = resize_operations(C) * average time per resize operation (measured) predict_time_threshold(C) = time when threshold(C) utilisation is predicted to be reached predicted_load_increasing = true if regression positive else negative sufficient_time_for_resize(C) = (predict_time_threshold(C) - resize_time(C)) > now trigger_resize_now(C) = (predict_time_threshold(C) - resize_time(C)) <= now 1 Every 5 minutes recompute linear regression function (upper 90% confidence interval) from past 60 minutes of cluster utilisation metrics and update the above variables. 2 IF predict_load_increasing THEN IF load < threshold(concurrency) AND (concurrency == 1 OR resize_time(concurrency) == resize_time(concurrency - 1) OR NOT sufficient_time_for_resize(concurrency - 1)) AND Trigger_resize_now(concurrency) THEN TRIGGER RESIZE(concurrency) to next size up (if available) WAIT for resize to complete ELSE IF concurrency == 1 exception(“load has exceeded node size threshold and insufficient time to resize”) ELSE IF load < Threshold(Concurrency - 1) Concurrency = Concurrency - 1 |
This graph shows the threshold (U%) and cluster resize time for an example 30 node cluster, with 3 racks and 10 nodes per rack and a time for each resize operation of 3 minutes (faster than reality, but easier to graph). Starting with concurrency = 10 (resize by “rack’), the rules will trigger a resize if the current load is increasing, under the threshold (67%, in the blue region), there is just sufficient predicted time for the resize to take place, and the next concurrency (9) resize time is the same or there is insufficient time for the next concurrency (9) resize. However, if the load has already exceeded the threshold then the next concurrency level (9) is selected and the rules are rerun 5 minutes later. The graph illustrates the fundamental tradeoff with the dynamic cluster resizing, which is that smaller concurrencies enable resizing with higher starting loads (blue), with the downside that resizes take longer (orange).
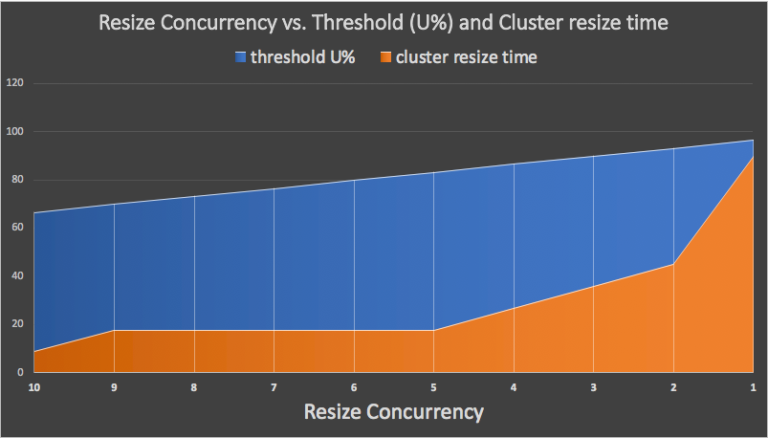
These (or similar) rules may or may not be a good fit for specific use case. For example, they are designed to be conservative to prevent over-eager resizing by waiting as late as possible to initiate a resize at the current concurrency level. This may mean that due to load increases you miss the opportunity to do a resize at higher concurrency level, so have to wait longer for a resize at a lower concurrency level. Instead you could choose to trigger a resize at the highest possible concurrency as soon as possible, by simply removing the check for there being insufficient time to resize at the next concurrency level.
Finally, these or similar rules could be implemented with monitoring data from the Instaclustr Cassandra Prometheus API, using Prometheus PromQL linear regression and rules to trigger Instaclustr provisioning API dynamic resizing.