Having explored one fork in the path (Elasticsearch and Kibana) in the previous pipeline blog series (here is part 5), in this blog we backtrack to the junction to explore the alternative path (PostgreSQL and Apache Superset). But we’ve lost our map (aka the JSON Schema)—so let’s hope we don’t get lost or attacked by mutant radioactive monsters.

(Source: Shutterstock)
Just to recap how we got here, here’s the Kafka source connector -> Kafka -> Kafka sink connector -> Elasticsearch -> Kibana technology pipeline we built in the previous blog series:
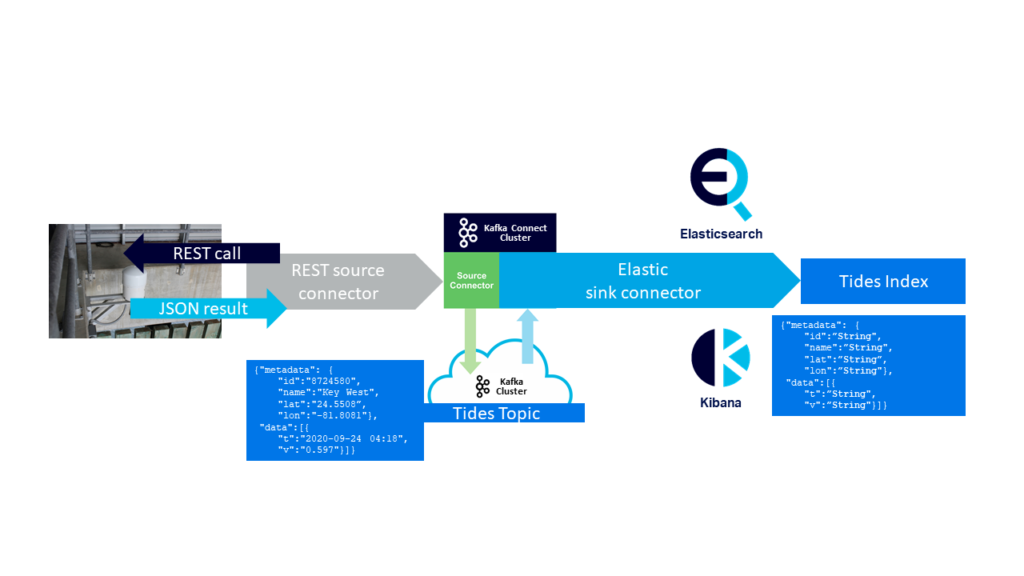
And here’s the blueprint for the new architecture, with PostgreSQL replacing Elasticsearch as the target sink data store, and Apache Superset replacing Kibana for analysis and visualization:
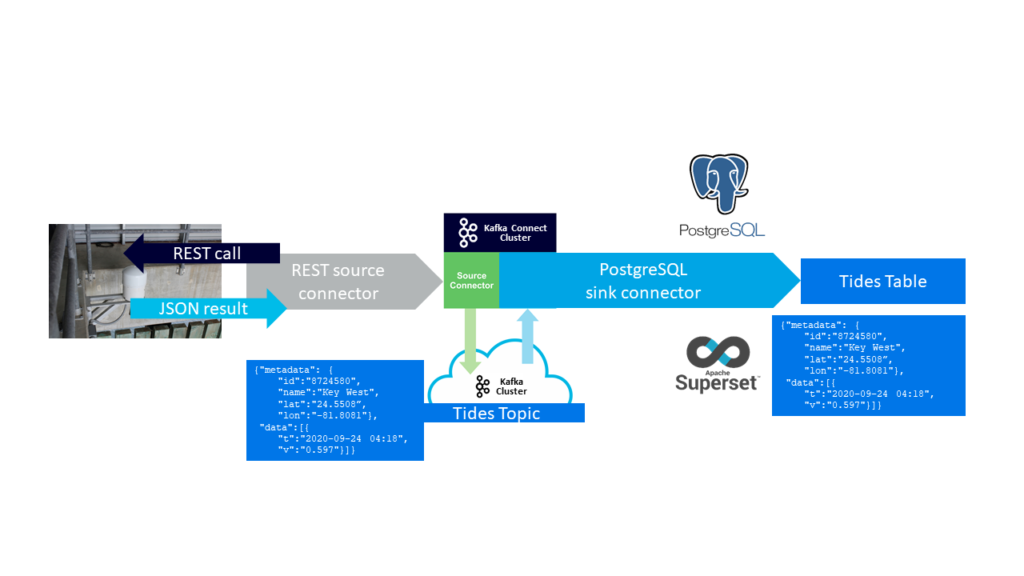
Well that’s the plan, but you never know what surprises may be lurking in the unmapped regions of a disused uranium mine!
1. Step 1: PostgreSQL database
In the news recently was Instaclustr’s acquisition of Credativ, experts in the open source PostgreSQL database (and other technologies). As a result, Instaclustr has managed PostgreSQL on its roadmap, and I was lucky to get access to the internal preview (for staff only) a few weeks ago. This has all the features you would expect from our managed services, including easy configuration and provisioning (via the console and REST API), server connection information and examples, and built-in monitoring with key metrics available (via the console and REST API).
Having a fully functional PostgreSQL database available in only a few minutes is great, but what can you do with it?
The first thing is to decide how to connect to it for testing. There are a few options for client applications including psql (a terminal-based front-end), and a GUI such as pgAdmin4 (which is what I used). Once you have pdAdmin4 running on your desktop you can easily create a new connection to the Instaclustr managed PostgreSQL server as described here, using the server IP address, username, and password, all obtained from the Instaclustr console.
You also need to ensure that the IP address of the machine you are using is added to the firewall rules (and saved) in the console (and update this if your IP address changes, which mine does regularly when working from home). Once connected you can create tables with the GUI, and run arbitrary SQL queries to write and read data to test things out.
I asked my new Credativ colleagues what else you can do with PostgreSQL, and they came up with some unexpectedly cool things to try—apparently PostgreSQL is Turing Equivalent, not “just” a database:
- Classic Towers of Hanoi in PostgreSQL
- A space-based strategy game implemented entirely within a PostgreSQL database
- GTS2— A whole game in PostgreSQL and pl/python where you can drive around in python-rendered OSM-Data with a car, with collision detection and all the fun stuff!
- A Turing Machine implemented in PostgreSQL. This is an example I found, just to prove the Turing machine point. It was probably easier to build than the one below, which is an actual working Turing machine, possibly related to this one. Although the simplest implementation is just a roll of toilet paper and some rocks.

So that’s enough PostgreSQL fun for the time being, let’s move onto the real reason we’re using it, which is to explore the new pipeline architecture.
2. Step 2: Kafka and Kafka Connect Clusters
The next step was to recreate the Kafka and Kafka Connect setup that I had for the original pipeline blogs, as these are the common components that are also needed for the new experiment.
So, first I created a Kafka cluster. There’s nothing special about this cluster configuration (although you should ensure that all the clusters are created in the same AWS region to reduce latency and costs—all Instaclustr clusters are provisioned so they are spread over all AWS availability zones for high availability).
Then I created a Kafka Connect Cluster targeting the Kafka cluster. There are a couple of extra configuration steps required (one before provisioning, and one after).
If you are planning on bringing your own (BYO) connectors, then you have to tick the “Use Custom Connectors” checkbox and add the details for the S3 bucket where your connectors have been uploaded to. You can find the bucket and details in your AWS console, and you need the AWS access key id, AWS secret access key, and the S3 bucket name. Here are the instructions for using AWS S3 for custom Kafka connectors.
Because we are going to use sink connectors that connect to PostgreSQL, you’ll also have to configure the Kafka Connect cluster to allow access to the PostgreSQL server we created in Step 1, using the “Connected Clusters” view as described here.
Finally, ensure that the IP address of your local computer is added to the firewall rules for the Kafka and Kafka Connect clusters, and remember to keep a record of the usernames/passwords for each cluster (as the Instaclustr console only holds them for a few days for security reasons).
3. Step 3: Kafka Connectors

(Source: Shutterstock)
Before we can experiment with streaming data out of Kafka into PostgreSQL, we need to replicate the mechanism we used in the earlier blogs to get the NOAA tidal data into it, using a Kafka REST source connector as described in section 5 of this blog. Remember that you need to run a separate connector for every station ID that you want to collect data from. I’m just using a small subset for this experiment. I checked (using the kafka-console-consumer, you’ll need to set up the kafka properties file with the Kafka cluster credentials from the Instaclustr console for this to work), and the sensor data was arriving in the Kafka topic that I’d set up for this purpose.
But now we need to select a Kafka Connect sink connector. This part of the journey was fraught with some dead ends, so if you want to skip over the long and sometimes dangerous journey to the end of the tunnel, hop in a disused railway wagon for a short cut to the final section (3.5) which reveals “the answer”!
3.1 Open Source Kafka Connect PostgreSQL Sink Connectors
Previously I used an open source Kafka Connect Elasticsearch sink connector to move the sensor data from the Kafka topic to an Elasticsearch cluster. But this time around, I want to replace this with an open source Kafka Connect sink connector that will write the data into a PostgreSQL server. However, such connectors appear to be as rare as toilet paper on shop shelves in some parts of the world in 2020 (possibly because some monster Turing Machine needed more memory). However, I did finally track (only) one example down:
- Kafka sink connector for streaming JSON messages into a PostgreSQL table
- Last updated two years ago, and is unsupported
- MIT License
3.2 Open Source Kafka Connect JDBC Sink Connectors
Why is there a shortage of PostgreSQL sink connectors? The reason is essentially that PostgreSQL is just an example of the class of SQL databases, and SQL databases typically have support for Java Database Connectivity (JDBC) drivers. Searching for open source JDBC sink connectors resulted in more options.
So, searching in the gloom down the mine tunnel I found the following open source JDBC sink connector candidates, with some initial high-level observations:
- IBM Kafka Connect sink connector for JDBC
- Last updated months ago
- It has good instructions for building it
- Not much documentation about configuration
- It has PostgreSQL support
- Apache 2.0 License
- Aiven Connect JDBC Connector
- A fork of the Confluent kafka-connect-jdbc connector
- It has a source and a sink connector
- It has PostgreSQL support
- Good configuration and data type mapping documentation
- Apache 2.0 License
- Apache Camel JDBC Kafka Sink Connector
- Sink only available.
- Apache 2.0 License
How should you go about selecting a connector to trial? I had two criteria in mind. The first factor was “easy to build and generate an uber jar file” so I could upload it to the AWS S3 bucket to get it into the Instaclustr Managed Kafka Connect cluster I was using. The second factor relates to how the connectors map the data from the Kafka topic to the PostgreSQL database, tables, and columns, i.e. the data mappings. Luckily I had a close look at the PostgreSQL JSON side of this puzzle in my previous blog, where I discovered that you can store a schemaless JSON object into PostgreSQL in a single column, of type jsonb, with a gin index.
3.3 Finding a Map (Schema)
Taking another look at my Tidal sensor data again, I was reminded that it is structured JSON, but without an explicit JSON schema. Here’s an example of one record:
{"metadata": {
"id":"8724580",
"name":"Key West",
"lat":"24.5508”,
"lon":"-81.8081"},
"data":[{
"t":"2020-09-24 04:18",
"v":"0.597",
"s":"0.005", "f":"1,0,0,0", "q":"p"}]}
It has two fields, metadata and data. The data field is an array with one element (although it can have more elements if you request a time range rather than just the latest datum). However, it doesn’t have an explicit schema.
What are the theoretically possible options for where to put JSON schemas for Kafka sink connectors to use?
- No schema
- Explicit schema in each Kafka record (this wastes space and requires the producer to write a record with the correct schema as well as the actual data)
- Explicit schema in the connector configuration. This is a logical possibility, but would potentially limit the connector to working with only one topic at a time. You’d need multiple configurations and therefore connectors to work with topics with different schemas.
- Explicit schema stored somewhere else, for example, in a schema registry
But why/when is a schema needed? Looking at the code of some of the connectors, it appears that the schema is primarily used to auto-create a table with the correct columns and types, but this is assuming that you want to transform/extract the JSON fields to multiple columns.
And is the data mapping separate from the schema? Does it use the schema? Let’s look closer at a typical example, the IBM and Aiven connectors which are based on the Confluent approach which (1) requires an explicit schema in each Kafka record, and (2) requires Kafka record values to be structs with primitive fields.
Assuming we could “flatten” and remove some of the unwanted fields, then the JSON tidal data would look like this:
|
1 2 3 4 5 6 7 |
{ "name":"Key West", "lat":"24.5508”, "lon":"-81.8081", "t":"2020-09-24 04:18", "v":"0.597" } |
Then the complete Kafka record, with schema and payload would look like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
{ "schema": { "type": "struct", "fields": [ { "field": "name", "type": "string", "optional": false }, { "field": "lat", "type": "float32", "optional": false }, { "field": "lon", "type": "float32", "optional": false }, { "field": "t", "type": "timestamp", "optional": false }, { "field": "v", "type": "float32", "optional": false } ] }, "payload": { "name":"Key West", "lat":"24.5508”, "lon":"-81.8081", "t":"2020-09-24 04:18", "v":"0.597" } |
So we’ve essentially drawn our own schema/map; let’s see if it helps us to find a way out of the mine!
I constructed some example records with this format and put them into a test Kafka topic with the kafka-console-producer.
The connector configuration requires a PostgreSQL connection URL, user and password, the topic to read from and the table name to write to. The schema is used to auto-create a table with the required columns and types if one doesn’t exist, and then the payload values are just inserted into the named columns.
Here’s an example PostgreSQL configuration from the IBM connector documentation:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "name": "jdbc-sink-connector", "config": { "connector.class": "com.ibm.eventstreams.connect.jdbcsink.JDBCSinkConnector", "tasks.max": "1", "topics": "tidal_data_test", "connection.url": "jdbc:postgresql://PGIP:5432/postgres", "connection.user": "PGuser", "connection.password": "PGpassword", "connection.ds.pool.size": 5, "insert.mode.databaselevel": true, "table.name.format": "tides_table" } } |
Note that with PostgreSQL you need the IP address, port number, and the database name, postgres (in this example) for the URL.
Building the IBM connector was easy, and I was able to upload the resulting uber jar to my AWS S3 bucket and sync the Instaclustr managed Kafka Connect cluster to see that it was available in the cluster (just remember to refresh the browser to get the updated list of connectors).
Here’s the CURL command used to configure and run this connector on the Instaclustr Managed Kafka Connect (KC) cluster (note that you need the credentials for both the Kafka Connect cluster REST API and the PostgreSQL database):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
curl https://kcip:8083/connectors -X POST -H 'Content-Type: application/json' \ -k -u kcuser:kcpassword \ -d '{ "name": "jdbc-sink-connector", "config": { "connector.class": "com.ibm.eventstreams.connect.jdbcsink.JDBCSinkConnector", "tasks.max": "1", "topics": "tidal_data_test", "connection.url": "jdbc:postgresql://PGIP:5432/postgres", "connection.user": "user", "connection.password": "password", "connection.ds.pool.size": 5, "insert.mode.databaselevel": true, "table.name.format": "tides_table" } } |
You can easily check that the connector is running in the Instaclustr console (Under “Active Connectors”), and you should ensure that the Kafka Connect logs are shipped to an error topic in case something goes wrong (it probably will, as it often takes several attempts to configure Kafka connector correctly).
The IBM connector was easy to build, configure, and start running, however, it had a few issues. As a result of the first error I had a look at the code, and discovered that a schema is also required for the table name. So the correct value for “table.name.format” above is “public.tides_table” (for my example). Unfortunately, the next error was impossible to resolve (“org.apache.kafka.connect.errors.DataException: Cannot list fields on non-struct type”) and we concluded it was a problem with the Kafka record deserialization.
I also tried the Aiven sink connector (which has a very similar configuration to the IBM one), but given the lack of details on how to build it, a dependency on Oracle Java 11, the use of Gradle, which I’m not familiar with, and finally this error (“java.sql.SQLException: No suitable driver found for jdbc:postgresql:///…”, possibly indicating that the PostgreSQL driver needs to be included in the build and/or an uber jar generated to include the driver), I didn’t have any success with it either.
3.4 The Schemaless Approach

(Source: Shutterstock)
So that’s two out of four connectors down, two to go.
Given the requirement to have an explicit schema in the Kafka records, the IBM and Aiven connectors really weren’t suitable for my use case anyway, so no great loss so far. And even though I’d had success with the Apache Camel connectors in the previous blogs, this time around the documentation for the Camel JDBC sink connector didn’t have any configuration examples, so it wasn’t obvious how it would work and if it needed a schema or not. This left the first(PostgreSQL-specific) connector as the only option remaining, so, let’s throw away our hand-drawn map and try the schemaless idea out.
The idea behind this connector is that elements from a JSON Kafka record message are parsed out into column values, specified by a list of columns, and a list of parse paths in the connector configuration.
Here’s an example configuration for my JSON tidal data to extract the name, t and v values from the JSON record, and insert them into name, time, and value columns:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
"config": { "connector.class": "com.justone.kafka.sink.pg.json.PostgreSQLSinkConnector", "tasks.max": "1", "topics": "tidal_data", "db.host": "jdbc:postgresql://PGIP:5432", "db.database": "postgres", "db.username": "pguser", "db.password": "pgpassword", "db.schema": "public", "db.table": "tides-test2", "db.columns": "name,time,value", "db.json.parse": "/@metadata/@name,/@data/#0/@t,/@data/#0/@v", "db.delivery" : "fastest" } |
This connector was also hard to build (it was missing some jars, which I found in an earlier release). The documentation doesn’t say anything about how the table is created, so given the lack of schema and type information, I assumed the table had to be manually created before use. Unfortunately, I wasn’t even able to start this connector running in the Instaclustr Kafka Connect cluster, as it resulted in this error when trying to configure and run it:
3.5 Success With a Customized IBM Connector
So with our last candle burning low and the sounds of ravenous monsters in the darkness of the mine growing louder by the second, it was time to get creative.
The IBM connector had been the easiest to build, so it was time to rethink my requirements. Based on my previous experience with JSON and PostgreSQL, all I really needed the connector to do was to insert the entire JSON Kafka record value into a single jsonb column type in a specified table. The table would also need a single automatically incremented id field, and a gin index on the jsonb table. It turned out to be straightforward to modify the behavior of the IBM connector to do this.
The table and gin index (with a unique name including the table name) is created automatically if it doesn’t already exist, and the column names are currently hardcoded to be “id” (integer) and “json_object” (type jsonb). I did have to modify the SQL code for creating the table for it to work with PostgreSQL correctly, and customize the insert SQL.
Based on my previous experiences with sink connectors failing due to badly formed JSON or JSON with a different schema to expected, I was pleasantly surprised to find that this connector was very robust. This is due to the fact that PostgreSQL refuses to insert badly formed JSON into a jsonb column type and throws an exception, and the IBM connector doesn’t fail under these circumstances; it just logs an error to the Kafka error topic and moves onto the next available record.
However, my previous experiments failed to find a way to prevent the JSON error messages from being indexed into Elasticsearch, so I wondered if there was a solution for PostgreSQL that would not cause the connector to fail.
The solution was actually pretty simple, as PostgreSQL allows constraints on json columns. This constraint (currently executed manually after the table is created, but it could be done automatically in the connector code by analyzing the fields in the first record found) uses one of the PostgreSQL JSON existence operators (‘?&’) to add a constraint to ensure that ‘metadata’ and ‘data’ exist as top-level keys in the json record:
|
1 |
ALTER TABLE tides_table ADD CONSTRAINT field_check CHECK (json_object ?& array['metadata', 'data']) |
This excludes error records like this: {“error”:”error message”}, but doesn’t exclude records which have ‘metadata’ and ‘data’ and superfluous records. However, extra fields can just be ignored when processing the jsonb column later on, so it looks like we have found light at the end of the mine tunnel and are ready to try out the next part of the experiment, which includes building. deploying, and running Apache Superset, configuring it to access PostgreSQL, and then graphing the tidal data.

Further Resources
Here’s the customized Kafka Connect sink connector that I developed, with a prebuilt compressed uber jar file (which has everything including the PostgreSQL driver) included.
Follow the Pipeline Series
- Part 1: Building a Real-Time Tide Data Processing Pipeline: Using Apache Kafka, Kafka Connect, Elasticsearch, and Kibana
- Part 2: Building a Real-Time Tide Data Processing Pipeline: Using Apache Kafka, Kafka Connect, Elasticsearch, and Kibana
- Part 3: Getting to Know Apache Camel Kafka Connectors
- Part 4: Monitoring Kafka Connect Pipeline Metrics with Prometheus
- Part 5: Scaling Kafka Connect Streaming Data Processing
- Part 6: Streaming JSON Data Into PostgreSQL Using Open Source Kafka Sink Connectors
- Part 7: Using Apache Superset to Visualize PostgreSQL JSON Data
- Part 8: Kafka Connect Elasticsearch vs. PostgreSQL Pipelines: Initial Performance Results
- Part 9: Kafka Connect and Elasticsearch vs. PostgreSQL Pipelines: Final Performance Results
- Part 10: Comparison of Apache Kafka Connect, Plus Elasticsearch/Kibana vs. PostgreSQL/Apache Superset Pipelines
Transparent, fair, and flexible pricing for your data infrastructure: See Instaclustr Pricing Here

Master Apache Kafka with expert insights
Struggling to strike the perfect balance between performance, scalability, and reliability in your Kafka ecosystem? Whether you're optimizing for zero downtime or maximizing resource efficiency, this guide has you covered.