The annual Kafka Summit 2020 went ahead this year (August 24-25) with a lot of topics. In the previous blog, I examined talks 1-3 from the perspective of challenging Kafka Use Cases. In this blog, I’ll focus on some of the more interesting Kafka technology advances from the remaining talks that I watched.
Here is the list of talks I recently watched during the Kafka Summit 2020:
- IMQTT and Apache Kafka: The Solution to Poor Internet Connectivity in Africa—Fadhili Juma (Remitly)
- Flattening the Curve with Kafka—Rishi Tarar (Northrop Grumman Corp.)
- Marching Toward a Trillion Kafka Messages Per Day: Running Kafka at Scale at PayPal [Lightning]—Maulin Vasavada (PayPal)
- KafkaConsumer: Decoupling Consumption and Processing for Better Resource Utilization—Igor Buzatović (Inovativni trendovi d.o.o)
- Apache Pinot Case Study: Building Distributed Analytics Systems Using Apache Kafka—Neha Pawar (Stealth Mode Startup)
- Building a Data Subscription Service with Kafka Connect—Danica Fine and Ajay Vyasapeetam (Bloomberg)
- A Tale of Two Data Centers: Kafka Streams Resiliency—Anna McDonald (Confluent)
- Getting up to Speed with MirrorMaker 2—Mickael Maison (IBM), Ryanne Dolan
- Tradeoffs in Distributed Systems Design: Is Kafka The Best?—Ben Stopford and Michael Noll (Confluent)
- Building a Modern, Scalable Cyber Intelligence Platform with Kafka [Lightning]—Jac Noel (Intel)
- Redis and Kafka: Advanced Microservices Design Patterns Simplified [Sponsored]—Allen Terleto (Redis Labs)
- Kafka ♥ Cloud—Jay Kreps (Confluent)
1. Kafka Consume
Decoupling Consumption and Processing for Better Resource Utilization—Igor Buzatović (Inovativni trendovi d.o.o)

{kind=link}
Igor’s talk was a deep dive into how Kafka consumers work, and how you can correctly overcome the limitations of single-thread Kafka consumers to maximize throughput, reduce latency, and rebalancing time, and process events in order and with exactly-once semantics. Sounds impossible?! Kafka consumers are normally single-threaded, so in the same thread you both poll for messages and then process them. This works fine if the processing time per message is very small. But, if the processing time blows out (for example to run an anomaly detection pipeline, or to write/read data to/from a database etc.) then latency and throughput both degrade, and the typical solution is to increase the number of Kafka consumers to compensate.
This just follows from “Little’s Law” which states that the average concurrency of a system (U) is the average response time (RT) multiplied by the average throughput (TP), i.e.:
U = RT * TP
Or, rearranging for TP:
TP = U/RT
So, as RT goes up the only way to increase TP is to increase the concurrency, or the number of Kafka consumers (if they are single threaded). However, increasing Kafka consumers entails increasing the number of Kafka partitions per topic (as you must have at least 1 partition per consumer), which can seriously reduce the cluster throughput. So, you want to try and optimize the Kafka consumers first (to reduce the RT part of the above equation).
The optimizations I’ve used in the past are to use multiple thread pools/multithreading and/or asynchronous processing for the message processing phase, as this increases the concurrency and reduces the latency, but at the potential cost of incorrect event ordering and commits. For example, in my demo Kafka IoT application (Kongo) I used the Guava Event Bus to decouple message polling from processing to handle high fan-outs, and for Anomalia Machina (an Anomaly Detection pipeline using Kafka, Cassandra, and Kubernetes) having two thread pools and tuning the size of the processing thread pool as critical for throughput optimization. This diagram shows the use of two thread pools in the context of an Anomaly Detection pipeline:
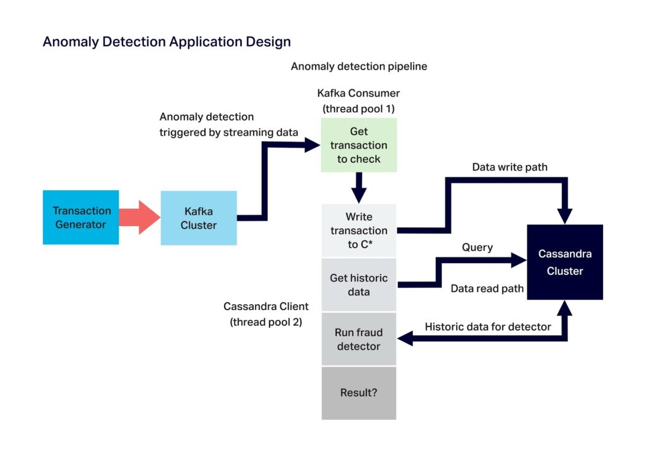
DoorDash also uses a similar multithreading approach, so it’s apparent that this isn’t a new idea. What’s good about Igor’s solution is that it’s correct! Igor goes through the pros and cons of several alternative multithreaded Kafka consumer designs before settling for a “fully-decoupled” design which solves most of the issues. Igor’s solution is to process all the records from the same partition by the same thread (thereby ensuring ordering), and use a manual commit (handled in the main polling thread) to ensure exactly-once semantics and reduce rebalancing issues. Multi-threading can be hard, but Igor’s approach looks like a correct and elegant solution for Kafka consumer multi-threading, and demo code is available here.
2. Apache Pinot Case Study
Building Distributed Analytics Systems Using Apache Kafka—Neha Pawar (Stealth Mode Startup)

{kind=link}
Before this talk, I hadn’t heard of Apache Pinot (Incubating). It’s actually not a wine recommendation system, but a real-time OLAP processing system for low-latency analytics at scale, with use cases including BI and Anomaly Detection. It was developed at LinkedIn and is used by other companies including Uber and Slack. Pinot ingests data from Kafka in real-time, and needs to be scalable, fault tolerant, reduce consumer/topic rebalancing, and ensure exactly-once semantics.
This talk was similar to the previous talk, in that Neha explored a number of different designs before reaching an optimal solution, which also involved modifications to the default Kafka consumer behaviour (to take control over partition mappings and checkpointing), and the use of a custom consumer coordinator. They use a single coordinator across all replicas, which manages partitions and mappings from partitions to servers, including start and end offset. All actions in the cluster are determined by this coordinator, and consumers write to the coordinator to keep track of offsets. The pattern they use is 1 consumer per partition, and the coordinator maintains this relationship with Pinot Servers and Kafka consumers coming and going.
As Neha’s explanation may have lost something in my summary, the complete talk is available here.
3. Building a Data Subscription Service With Kafka Connect—Danica Fine & Ajay Vyasapeetam (Bloomberg)
Danica and Ajay talked about how Bloomberg had migrated much of the technology stack to a Kafka Streams and Kafka Connect based microservices architecture, the goal being low-latency data pipelines. However, they still needed to consume real-time market data through synchronous in-line request/responses. This introduced unwanted latency and complexity (e.g. around error handling in stream processors). To solve this problem they built their own fault tolerant and scalable data subscription framework to enable subscriptions to multiple data sources. They used a custom Kafka subscription manager to hook data sources up to custom source connectors, which pull data from multiple data sources and make it available on Kafka topics for the stream processors. As we’ve seen from some of the other talks that use custom Kafka connectors, one common challenge is handling consumer rebalancing, and this was also the case for Bloomberg due to Kafka connect stop-the-world reconfiguration and rebalancing.
After the talk I discovered that you can subscribe to Bloomberg market data feeds (e.g. ticker updates) via the Bloomberg labs open API and using a Kafka connector. This sounds like another potential solution for my globally distributed stock broker demo application.
4. A Tale of Two Data Centers: Kafka Streams Resiliency—Anna McDonald (Confluent)

{kind=link}
One of the recurring themes from the Kafka Summit this year is companies running multiple Kafka clusters (e.g. the Paypal use case in the previous blog). Sometimes multiple clusters are used for different applications with different data in each cluster, or for architectural and scalability reasons (e.g. to handle high fan-out data pipelines). But a more common use case is to increase redundancy and resilience (in the case of data center failures) and to reduce latency (due to geographical separation). Anna’s presentation was a great explanation of the problems and tradeoffs (from both theoretical and practical perspectives) of running multiple Kafka clusters, for an active/passive configuration in particular (although active/active is also possible). Anna started out by emphasizing the importance of understanding your Recovery Time Objective (RTO—how long can a system be down for), and Recovery Point Objective (RPO—how much data can be missed).
There are two architectural solutions to replication across multiple Data Centers (DCs) in Kafka: Replication (two clusters, 1 per DC), and a Stretched cluster (a single cluster across two DCs). Replication is the simplest solution (and is typically achieved using MirrorMaker, see next talk), gives lower producer latency, but the consumers need to manually failover and keep track of offset state, and doesn’t support exactly-once semantics. A Stretched cluster, (being only a single cluster), gives automatic failover of consumers and offset management, and does support exactly-once semantics. The main problem with stretching a cluster is if you stretch it too far! Anna recommended that more than 100ms latency is too much.
Anna also recommended some changes to the default settings for Kafka Streams Applications for Stretched clusters as follows:
| Parameter name (component) | Stretched cluster value |
| acks (Producer) | acks=all |
| replication.factor (Streams) | -1 (to inherit broker defaults for stretch) |
| min.insync.replicas (Broker) | 2 |
| retries (Streams) | Integer.MAX_VALUE |
| Delivery.timeout.ms (Producer) | Integer.MAX_VALUE |
This was one summit talk where I thought it was worthwhile to clarify with the presenter if the solution would work correctly for open source Kafka. In this case I was worried that the 100ms latency limit may only be applicable for the non-open source version of Kafka which has “observers” (essentially asynchronous replicas that are not counted towards ISR and acks), which in turn depends on a KIP-392 to allow consumers to fetch from the closest replica (which in supported by the current open source version of Kafka offered by Instaclustr Managed Kafka, 2.5.1). For more information see this discussion. Based on a combination of Anna’s reply to my question and the availability of KIP-392 I expect that with careful benchmarking and monitoring (e.g. Instaclustr’s managed Kafka provides multiple metrics, including replica lag) a stretched cluster should be possible approaching 100ms latency. To double check I asked our TechOps gurus and they said, and I quote, “Yup, under 100ms is totally doable”. Perhaps a lucky coincidence, but 100ms is the maximum latency between AWS Regions in the same “georegion” (e.g. Tokyo and Australia, USA West and USA East, etc.) that I planned to run multiple Kafka clusters across for my globally distributed stock broker demo application (Instaclustr doesn’t currently support stretch clusters across multiple AWS Regions).
5. Getting up to Speed with MirrorMaker 2—Mickael Maison (IBM), Ryanne Dolan
So if you still need multiple Kafka clusters with data replicated between them, and have latencies exceeding 100ms between them, what can you do? Mickael and Ryanne’s talk is the answer, and they explained how to mirror data between Kafka clusters for high availability and disaster recovery using the new (since 2.4.0) MirrorMaker 2 (MM2).
Their talk covered how MM2 works, and how it improves on MM1. MM1 had some major limitations, particularly that it didn’t do offset translation, and only allowed for timestamp-based recovery. MM2 offers offset translation, consumer group checkpoints, and even cross-cluster metrics for, for example replication latency. The main MM2 components are actually Kafka connectors as follows. The MirrorSourceConnector replicates and of records from local to remote clusters, and enables offset synchronization from remote back to local cluster. The MirrorCheckpointConnector manages consumer offset synchronization, emits checkpoints, and enables failover (auto and programmatically)
Finally, the MirrorHeartbeatConnector provides heartbeats, monitoring of replication flows, and client discovery of replication topologies (which can be more complex than for MM1).
The second part of the talk focused on MM2 deployment modes and monitoring/tuning, but you can avoid most of this complexity if you use Instaclustr’s Managed Kafka Service (Instaclustr uses MirrorMaker 2 on top of Kafka Connect) and we have fully managed MirrorMaker 2 coming very soon. Key configuration options enable Active/Active and Active/Passive replication, with configurable mapping of topic names between clusters. Two extra cards MM2 has up its sleeve are stopping infinite event subscription loops (which are a danger with more complex pub-sub topologies—which I’ve been caught out by in the past with older technologies), and exactly-once semantics (KIP-656, in progress). So it looks like MM2 is a pretty good solution to Kafka cluster replication, particularly when you have > 100ms latency between Data Centers, but there may be still some manual work on the consumer side to manage failover, starting to reading from the correct offset (as there are still two clusters so consumers are independent), and recovery.
6. Tradeoffs in Distributed Systems Design: Is Kafka The Best?—Ben Stopford and Michael Noll (Confluent)
Ben and Michael are well known in distributed systems circles (e.g. Ben for “Designing Event Driven Systems”, Michael for Kafka Streams), so this was a “must watch” talk for me. The short answer is “Best” is subjective, and you need to know the use case! A more nuanced answer is that Kafka (being a distributed log based pub-sub messaging system) is just about the most scalable possible solution for streaming data, being designed for sequential data access, replication of data, and event reprocessing (facilitated by the log abstraction, messages are never discarded), supporting highly concurrent consumers (for load sharing) and consumer groups (for broadcasting)—facilitated by partitions. As well as explaining the differences in architecture between Apache Kafka and other messaging technologies (e.g. RabbitMQ) and Apache Pulsar, they shared a summary of some more detailed benchmark results. Kafka throughput was the best (600MB/s), followed by Pulsar (300MB/s), and then RabbitMQ (100MB/s, or 40MB/s Mirrored), running on identical hardware.
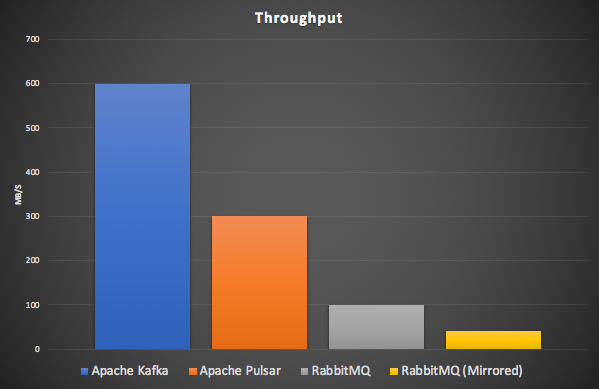
Kafka also delivers the best latencies at higher loads. At lower loads, RabbitMQ had the lowest latency, followed by Kafka, with Pulsar the highest. They used the OpenMessaging Benchmark Framework (which required a few fixes to work fairly across all the three technologies).
The use of partitions in Kafka means that partition data is continuous on a single node, so it’s very fast for r/w and quick to navigate to the correct node, but a partition size is limited to a single node and number of partitions are limited by file handles. By comparison, Pulsar uses Apache BookKeeper which spreads a partition across multiple nodes, with the side-effect that there is lots of meta-data to manage and extra latency.
They identified the simple “single-tier” architecture (homogeneous/interchangeable node types) of Kafka as being key to its success (c.f. Pulsar which has different node types) and relative simplicity to operate and lower cost to run. Of course, currently Kafka also needs ZooKeeper to run, but the plan is to remove ZooKeeper (KIP-500—this will apparently also allow for more partitions. And of course there are other Kafka components that make sense to run as independently scalable (e.g. Kafka Streams and Connect). However, oddly they are also advocating “tiered storage” (KIP-405, designed to address increasing cluster sizes and operability, and which will allow for longer term data storage without having to increase cluster sizes), so I’m not sure they are entirely consistent in terms of what makes a good architecture as this adds “tiering”!
As part of my blogs I’ve run informal benchmarks (based on demonstration applications) on Instaclustr’s Managed Kafka (and complementary technologies including Apache Cassandra), the most recent results were 19 Billion Anomaly checks/day, with a peak of 2.3 Million events/s into the Kafka cluster (using Kafka as a buffer). I’ve also explored the impact of increasing partitions on throughput in this blog. Instaclustr regularly conducts benchmarking for new instances sizes, for example here are the results for Kafka on AWS r4 instances.
7. Conclusions
- Apache Kafka is a core and mission critical component in Enterprises for acquisition, integration, processing, and delivery of event pipelines. Apache Kafka is an excellent choice of technology to solve heterogeneous integration and processing problems at massive scale and with low-latency.
- There is a large ecosystem of robust open source software to assist with integration (e.g. Kafka Connectors), and many of the complementary technologies that organizations use with Apache Kafka are also Apache licensed.
- Many of the talks in the summit this year focused on problems related to using multiple Kafka clusters or more complex consumer use cases, requiring custom components and consumers. There are currently not many open source solutions in this space, and it’s complex to build these sorts of custom components, but our global team of Kafka experts in the Instaclustr Services team can help with these sorts of bespoke engineering problems.
- Organizations are increasingly realizing the benefits of using multiple Kafka clusters. However, it can be more challenging to provision, monitor, manage, and use multiple clusters. Instaclustr provides managed Apache Kafka clusters and associated services (including Kafka Connect and MirrorMaker) which means customers can focus on their applications.