



















What is Apache Kafka®?
Apache Kafka® is the leading distributed streaming and queuing technology for large-scale, always-on applications. Kafka has built-in features of horizontal scalability, high-throughput, and low-latency. It is highly reliable, has high-availability, and allows geographically distributed data streams and stream processing applications.
Donated to The Apache Foundation by LinkedIn in 2011, Kafka has garnered a lot of interest and is now being broadly used by many organizations across the globe including Netflix, Twitter, Spotify, and Uber. Kafka has grown into a strong and vibrant open community and it is compatible with a wide range of complementary technology.
Kafka has a similar shared-nothing, replicated architecture to Cassandra that allows it to operate with similar extreme levels of scalability, reliability, and availability. In any Big Data application, Kafka really has three core functions:
Message Transport
Enabling transportation of data between various publisher and subscriber endpoints.
Message Aggregation
Aggregating a number of various data streams for use by distributed processing applications.
Message Store
Storing data streams as a cache in a replicated, fault-tolerant storage environment.
Use of Messaging Queuing Technology
Messaging queuing technology has been in use for some time now—enabling different applications and endpoints to communicate with each other. These applications can be on the same or different physical platforms. With queuing technology, the producer and consumer do not need to interact with the message queue at the same time. Messages placed onto the queue are stored until the consumer retrieves them.
Kafka is part of the general family of technologies that provide queuing, messaging, and/or streaming—sometimes known as a streaming engine. Fundamentally it is a system that takes streams of messages from applications known as producers, stores them reliably on a central cluster (known as the brokers) and allows those streams to be received by applications that process the messages (applications called consumers). Other examples of this broad technology family include technologies such as RabbitMQ, IBM MQ, and Microsoft Message Queue.
A message queuing technology is deployed in an application stack for the following reasons:
- Messaging buffering. To provide a buffering mechanism in front of a processing (i.e. to deal with temporary incoming message rates that are greater than what the processing app can deal with).
- Guarantee of message delivery. Allows producers to publish messages with some assurance that the message will eventually be delivered if the consuming application is unable to receive the message when it is published.
- Providing abstraction. This type of technology provides an architectural separation between the consumers of messages and the applications that are producing the messages.
- Enabling scale. Provides a flexible and highly configurable architecture that enables many producers delivering messages to multiple consumers.
Apache Kafka Advantages
Most Java Message Service (JMS) brokers either don’t persist messages at all (i.e. non-persistent) or only store them until they are consumed and acknowledged (persistent). When comparing the traditional system v/s Kafka, Kafka has a completely different model where it stores all messages before and even after they are successfully received by subscribing applications.
Kafka comes with the following advantages:
- Highly scalable
- Highly reliable due to built-in replication, supporting true always-on operation
- Enables stream processing applications to utilise geographically distributed data streams
- Can handle high-velocity and high-volume data
- Achieves high throughput and high availability using a distributed cluster of servers, therefore supporting message throughput of thousands of messages per second
- Low latency for most of the new age applications, using load balancing and data replication to allow failure or planned maintenance of individual nodes with no downtime
- It’s fault-tolerant
- Distributed technology and JVM codebase similar to Cassandra
- Built-in optimization such as compression and message batching
- Rich ecosystem including many connectors
- Integrates with external stream processing layers such as Spark Streaming
- Strong open source community is supporting it
- Powers some of the biggest organisations across the globe.
Kafka is considered very popular for various use cases. Check out our eBook on Apache Kafka – A Visual Introduction.
Some Key Kafka Concepts
- Producer: Producers are applications that publish a stream of records to one or more Kafka topics.
- Consumer: Consumers are the applications that read data from Kafka topics.
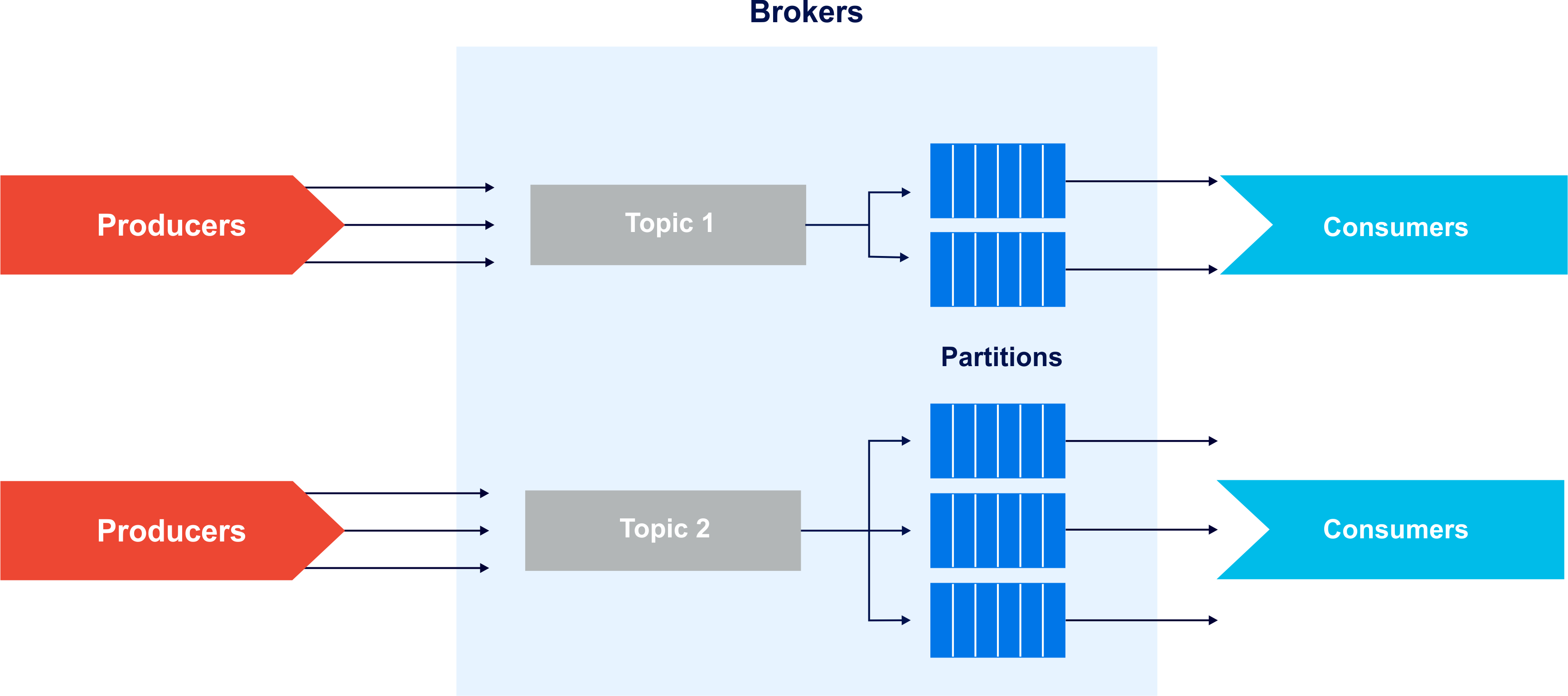
- Kafka Brokers: Brokers are the Kafka “servers”. They store data provided by the producer and make it available to the consumer. Kafka brokers require Apache ZooKeeper deployment to store configuration data, topic offsets, consumer groups, and other information. Kafka replicates its logs over multiple servers for fault-tolerance. Each Kafka Broker has a unique ID (number). Kafka Brokers contain topic log partitions.
- Kafka Topic and Partition: Topic is a stream of data, and is composed of individual records, basically just a sharded write-ahead log. Producer append records to these logs and consumer subscribe to changes. Kafka topics are divided into a number of partitions that allows one to parallelize a topic by splitting the data in a particular topic across multiple brokers. Each partition can be placed on a separate machine to allow for multiple consumers to read from a topic in parallel and also allowing a topic to hold more data that can fit on any one machine.
- Kafka Cluster: Apache Kafka is made up of a number of brokers that run on individual servers coordinated Apache Zookeeper. You can start by creating a single broker and add more as you scale your data collection architecture. A Kafka cluster can have, 10, 100, or 1,000 brokers in a cluster, if needed. Apache Kafka uses Apache Zookeeper to maintain and coordinate the Apache Kafka brokers.
- Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka and other systems. It is an API and ecosystem of 3rd party connectors that enables Kafka to be easily integrated with other systems without developers having to write any extra code.
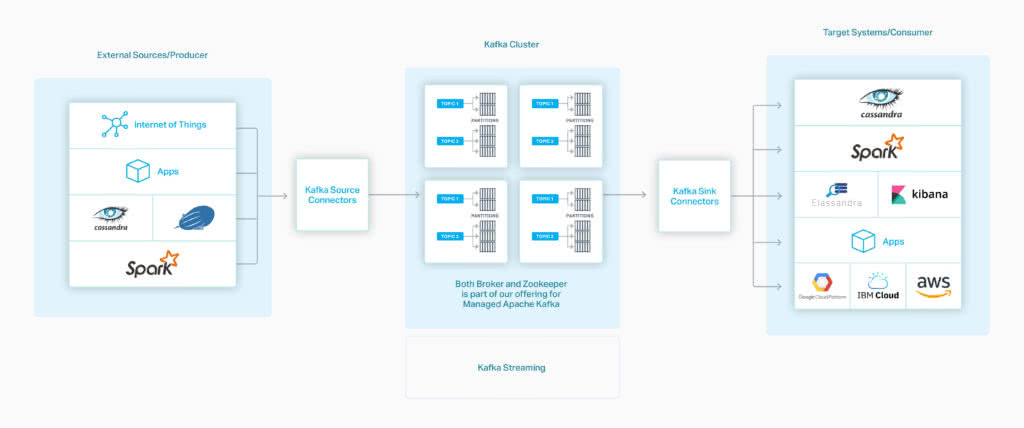
Paul Brebner, Technology Evangelist at Instaclustr wrote a series of blogs around Apache Kafka.
Paul’s blog around Apache Kafka Connect Architecture covers Source and Sink Connectors, Connectors, Plugins, Task and Worker, Clusters, and Convertors. Paul wrote a series of blogs on Instaclustr Kongo IoT Application that looks at implementing Kafka to build an IoT logistic applications.
Two of his blogs in the series are devoted to understanding Kafka Connect API. The first blog focuses on use cases extending the Kongo IoT application to stream events from Kafka to Apache Cassandra using a Kafka Connect Cassandra Sink. Part 2 of the blog, covers useful Kafka Connect resources. An interesting read for an in-depth perspective on Kafka Connect. Our infographic on Kafka Concepts will help you understand Kafka related terminology.
Kafka Architecture
In the most simple of ways, producers send records to the Kafka clusters which stores these records and then passes them in a controlled manner to consuming applications.
Kafka’s main architectural components include Producers, Topics, Consumers, Consumer Groups, Clusters, Brokers, Partitions, Replicas, Leaders, and Followers. A simplified UML diagram describes the ways these components relate to one another and helps you develop an understanding of Kafka Architecture.
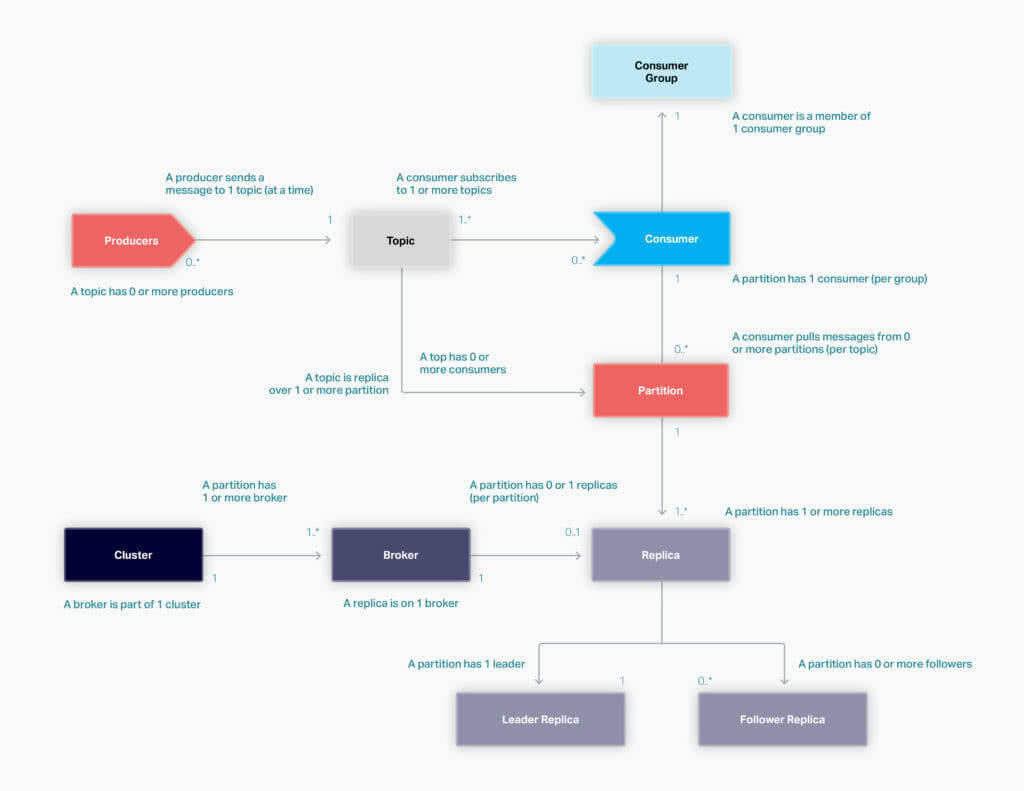
Important things to note:
- Kafka clusters can have one or more brokers.
- Brokers can host multiple replicas.
- Topics can have one or more partitions.
- A broker can host zero or one replica per partition.
- A partition has one leader replica and zero or more follower replicas.
- Each replica for a partition needs to be on a separate broker.
- Every partition replica needs to fit on a broker, and a partition can’t be divided over multiple brokers.
- Every broker can have one or more leaders, covering different partitions and topics.
Paul wrote two articles for Insidebigdata. The first part will help you understand Kafka Architecture components and how Kafka consumers work and the second part provides information on how these contribute to the ability of Kafka to provide extreme scalability for streaming write and read workloads.
Kafka enables developers to meet important requirements for applications such as:
- Safely dealing with spikes in workloads by temporarily storing data until it’s ready for processing;
- Allowing data from one source to be processed by many downstream applications;
- Allowing data from many sources to be gathered in a single sport for processing by downstream applications; and
- Facilitating stream processing where calculations can be performed on the streams of data such as calculating average values over a time window (as well as much more complex things).
The part 2 and part 3 of Instaclustr Kongo IoT applications blog re-engineers the Kongo application to introduce Apache Kafka. The series explores designing and developing an example IoT application with Apache Kafka to illustrate the typical design and implementation considerations and patterns.
Kafka Streams
Kafka Streams is a framework for stream data processing. It is a client library for processing and analyzing data store in Kafka. Kafka Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, transforming the input streams to output streams. It is the easiest way to write mission-critical, real-time applications, and microservices that power your core business.
Kafka Streams are highly scalable, distributed, fault-tolerant, elastic applications. With Kafka Streams, we can process the stream data within Kafka. No separate cluster is required just for processing. Our three-series blog starts with exploring Apache Kafka Streams, the topology of Streams Processing and more. Blog Kongo 5.2 and Blog Kongo 5.3 covers Apache Kafka Streams examples that gives an insight into Kafka Streams example using the murder mystery game Cluedo (Clue in the US) as a simple problem domain. Download our white paper Understanding Apache Kafka. Additionally, Paul Brebner, Tech Evangelist at Instaclustr wrote a blog for those who want to learn more about Apache Kafka, Producer API and Consumer API. In his blog, Paul delivers 100 million light trees to Santa by Christmas Eve using Kafka.
Kafka Use Cases
Kafka can be used for the variety of use cases such as generating matrix, log aggregation, messaging, audit trail, stream processing, website activity tracking, monitoring, and more.
For example in Event sourcing, you consider the sequence of changes made (as opposed to the result of those changes) to be the source of truth for the state of your application. Kafka is really useful for this use case, as it is designed for reliably storing a series of events and can provide an ideal data store for this purpose. Kafka’s support for compaction can also assist in this case. View our infographics illustrating four of the many Apache Kafka Use Cases.
Using Kafka, Spark, and Cassandra
Apache Kafka is the leading stream processing engine for scale and reliability; Apache Cassandra is a well-known database for powering the most scalable, reliable architectures available; and Apache Spark is the state-of-the-art advanced and scalable analytics engine.
Deployed together, these three technologies give developers the building blocks needed to build reliable, scalable, and intelligent applications that adapt based on the data they collect.
Download white paper on “Apache Spark, Apache Kafka, and Apache Cassandra Powering Intelligent Applications” focused on bringing forth the use cases in the area of Internet of Things, financial solutions, marketing and advertising, and more such industries. Additionally, this one-page document will help you understand how these 3 technologies work in combination.
Our Pick’n’Mix blog is an interesting read if you are interested in gaining an understanding of Instaclustr managed solutions that can be used together.
How Real-Time Streaming Data Helps
Kafka supports write and read scalability at the same time, which essentially means developers can stream enormous amounts of data to Kafka and carry out a real-time processing of the messages, including sending messages to other systems, for multiple different purposes concurrently. The use is only limited by your imagination. Our infographics on how real-time streaming data help would give you interesting possibilities to imagine.
Rules for Managing Kafka
Kafka has evolved from a messaging queue to a versatile streaming platform. If you are using Kafka, you would need to be aware of a few rules that would help you manage Kafka pipelines. Download our white paper on 10 Golden Rules for Managing Kafka to understand various components and gain in-depth knowledge on rules for log, hardware requirements, ZooKeeper, replication and redundancy, and more.
Deploying Kafka on AWS and Other Providers
Instaclustr offers Managed Apache Kafka on AWS, Microsoft Azure, Google Cloud Platform, and IBM Cloud. You can choose between different developer node sizes and professional node sizes. In our blog Kongo 6.1, Kongo 6.2 and Kongo 6.3, we deploy the Kongo IoT application to a production Kafka cluster, using Instaclustr Managed Apache Kafka service on AWS.
Kafka-As-A-Service
When deciding on deploying Apache Kafka as a crucial part of your technology stack you have to consider capability management requirements. You need to decide if the right decision is to build the necessary in-house expertise, or should you outsource the responsibility to a managed service provider (MSP) who can deliver Kafka-as-a-service. Download our white paper “The Unmatchable ROI of Managed Apache Kafka Service” and explore 3 broad considerations—cost, time, and business risk to help you arrive at the right decision.
Kafka Support
Earlier this year, we added Kafka to our Integrated Data Platform. The presentation on “Key Challenges and Lessons Learned in Extending Instaclustr Provisioning and Management System for Kafka” will give insights into the building Instaclustr Managed Apache Kafka.
Our documentation around Kafka Support gives access to a series of resources to help you create a Kafka cluster.
Kafka Consulting
Our consulting package for Apache Kafka is designed to provide an independent review of your operational Apache Kafka deployment. The package is designed to help customers who already have deployed and have operational application and are looking for assurance that the solution is scalable and is free from any potential issues.