Monitoring API
The main monitoring API documentation is at https://instaclustr.redoc.ly/Current/tag/Monitoring-API
The monitoring API currently provides the following monitoring information:
- Long-term cluster health indicators
- Metrics for:
- Cassandra status
- reads and writes operations per second
- CPU utilization
- disk utilization
- pending compactions
Metrics information is provided with either for an individual node or for all nodes in a cluster and cluster data centre.
The API also provides key statistics for each table in the cluster (similar to what is available through “nodetool tablehistograms”):
- read & write counts (mean, distribution)
- read & write latency (mean, distribution)
- live cells & tombstones per read (mean, max)
- number of sstables read for each read operation (mean, max)
The set of available metrics will expand as we build out this API. Descriptions of each of the metrics can be found in the application specific monitoring sections of this support site:
Authentication
All requests to the API must use Basic Authentication and contain a valid username and an API key.
The API keys are created per user, per account.
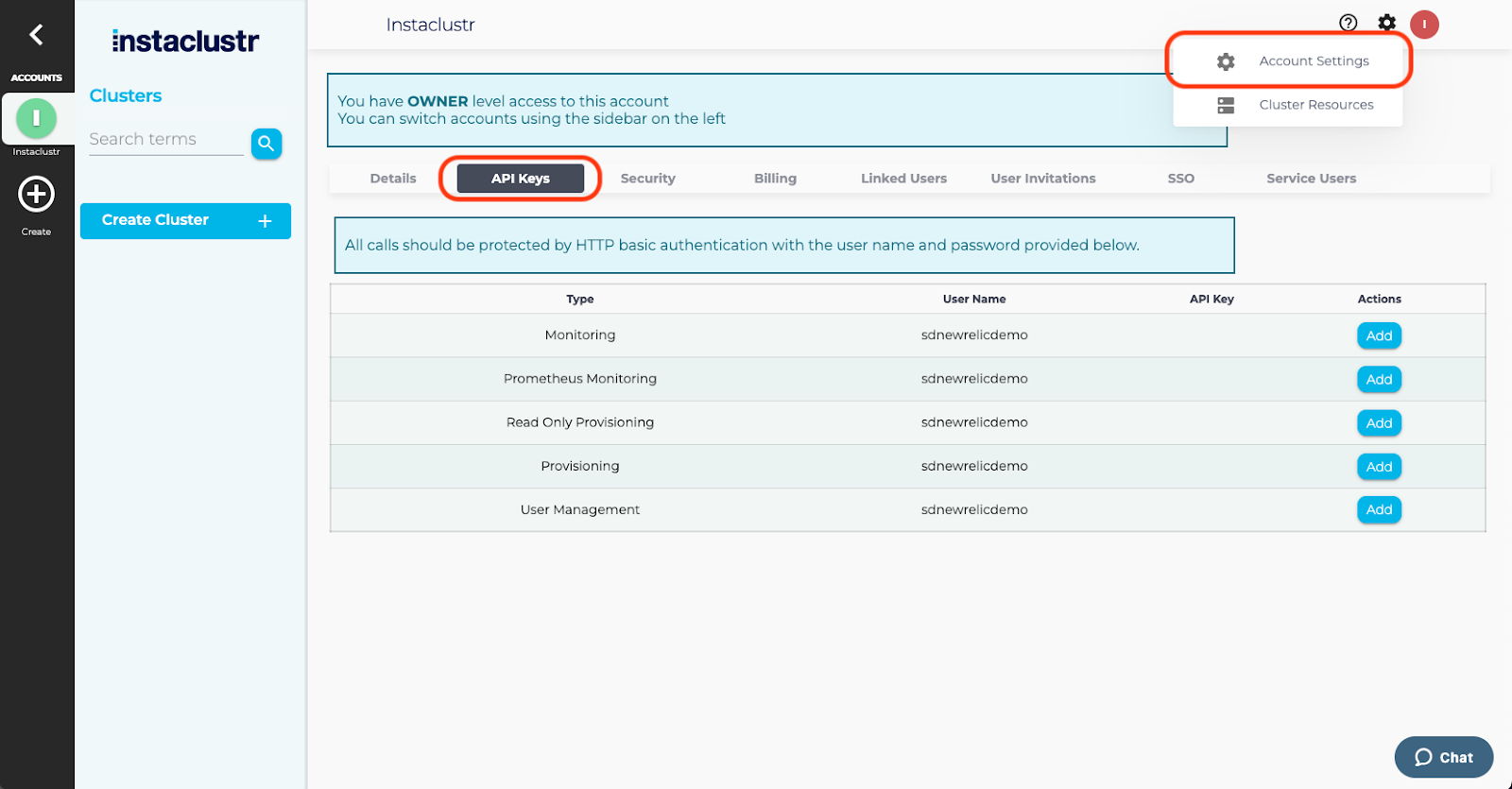
Creating your API keys
API keys can be created from the secure page in the console by going to Account Settings > API Keys. Please note that for your security the key will only be shown once on creation.
| All available metrics are updated every 20 seconds (i.e. requesting the same metric twice in 20 seconds will always return the same response). |
|---|
For more information on API Keys, please visit our API Keys documentation page.
Availability
Our APIs are engineered and operated for high levels of availability. However, you should not expect that our APIs have the same level of availability as a managed cluster and you should not build any dependency on the APIs into availability of your service. While we do not provide formal SLAs for the APIs, we aim for 99.95% availability (ie up to ~20 mins downtime per month). Longer maintenance outages may be schedule with appropriate notice. Consequently, any service dependent on the APIs should be able to cope gracefully with periods of unavailability of up to a few minutes. Planned and unplanned outages are communicated via https://status.instaclustr.com/.
Get Metrics
Metrics can be retrieved via API requests for either an individual node, or for all nodes in a cluster and cluster data centre. Send a request to https://api.instaclustr.com/monitoring/v1/clusters/{clusterId} with a metrics parameter to retrieve metrics.
Example: Get CPU Utilization metric and Network Out Delta Metric
Send a GET request to https://api.instaclustr.com/monitoring/v1/clusters/{clusterId}?metrics=n::cpuUtilization,n::networkoutdelta
The API will respond with status 200 OK and a JSON packet containing the following information:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 |
[ { "id": "90e6a8a3-039d-438a-9fd4-38fd22277436", "payload": [ { "metric": "cpuUtilization", "type": "percentage", "unit": "1", "values": [ { "value": "6.614017769002962", "time": "2020-12-07T04:47:37.000Z" } ] }, { "metric": "networkoutdelta", "type": "value", "unit": "1", "values": [ { "value": "1668152.0", "time": "2020-12-07T04:47:37.000Z" } ] } ], "publicIp": "54.156.20.185", "privateIp": "10.224.118.42", "rack": { "name": "us-east-1b", "dataCentre": { "name": "US_EAST_1", "provider": "AWS_VPC", "customDCName": "AWS_VPC_US_EAST_1" }, "providerAccount": { "name": "INSTACLUSTR", "provider": "AWS_VPC" } } }, { "id": "67d64a4b-bf2b-4f16-9b8f-803d54cf4936", "payload": [ { "metric": "cpuUtilization", "type": "percentage", "unit": "1", "values": [ { "value": "3.7731134432783606", "time": "2020-12-07T04:47:36.000Z" } ] }, { "metric": "networkoutdelta", "type": "value", "unit": "1", "values": [ { "value": "1677851.0", "time": "2020-12-07T04:47:36.000Z" } ] } ], "publicIp": "3.225.136.230", "privateIp": "10.224.46.204", "rack": { "name": "us-east-1a", "dataCentre": { "name": "US_EAST_1", "provider": "AWS_VPC", "customDCName": "AWS_VPC_US_EAST_1" }, "providerAccount": { "name": "INSTACLUSTR", "provider": "AWS_VPC" } } }, { "id": "bf4a2e00-d872-4a06-a0f9-6a88eb1f1d20", "payload": [ { "metric": "cpuUtilization", "type": "percentage", "unit": "1", "values": [ { "value": "4.663855122798314", "time": "2020-12-07T04:47:45.000Z" } ] }, { "metric": "networkoutdelta", "type": "value", "unit": "1", "values": [ { "value": "1733185.0", "time": "2020-12-07T04:47:45.000Z" } ] } ], "publicIp": "54.83.239.187", "privateIp": "10.224.138.126", "rack": { "name": "us-east-1c", "dataCentre": { "name": "US_EAST_1", "provider": "AWS_VPC", "customDCName": "AWS_VPC_US_EAST_1" }, "providerAccount": { "name": "INSTACLUSTR", "provider": "AWS_VPC" } } } ] |