How to perform a snapshot migration from Amazon OpenSearch Service
Overview
This guide shows how to perform snapshot migration from an Elasticsearch cluster in the AWS OpenSearch Service, to a cluster in the Instaclustr managed service for Bring Your Own Cloud customers.
Snapshot migration is the fastest migration method in this scenario based on our observations from practice, providing a rate of at about 80 MB/s of primary store data for small clusters, and scales with size of the cluster with speeds of up to hundreds of MB/s on 30-node clusters. However, to ensure the destination cluster doesn’t miss writes, this method does require that writes are stopped on the source cluster during the migration. Nevertheless, the duration of write stoppages can be decreased by implementing an incremental backup approach and scheduling snapshots for periods that fall within acceptable downtime windows.
In this guide, the AWS account containing the AWS OpenSearch Service domain will be referred to as the ‘source AWS account’, and the AWS account containing the Instaclustr cluster will be referred to as the ‘destination AWS account’.
Assumptions
The steps in this guide can only be used when the destination cluster is in an AWS account that you control, which has been configured to permit Instaclustr to provision clusters. At Instaclustr, this configuration is referred to as Bring Your Own Cloud (BYOC – previously RIYOA).
To carry out the steps, you must also have permission to:
- Create roles, users, and policies in the source AWS account
- Edit a bucket policy in the destination AWS account
Throughout this guide, the AWS OpenSearch Domain will be identified as the ‘source account’ and the AWS account configured for Instaclustr BYOC provisioning will be known as the ‘destination account’.
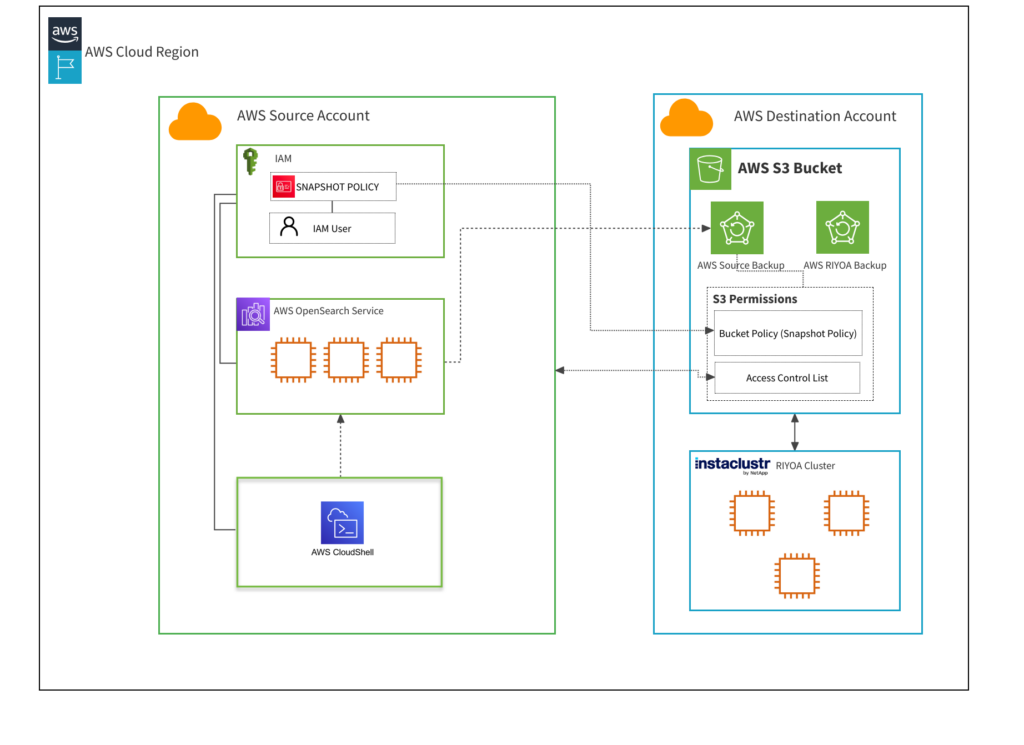
Table of Contents
Step 1: Create an IAM Policy
In the source AWS account, set up a new AWS Identity and Access Management (IAM) policy.
This policy will grant permission to access the S3 bucket in the destination AWS account (also referred as the AWS account configured for Instaclustr BYOC).
Take the following steps:
- In the AWS console, navigate to IAM.
- Go to the ‘Policies’ page. Choose ‘Create policy’.
- Use the ‘JSON’ tab in the policy editor and input the following policy.
(Please ensure the placeholders3-bucket-nameis replaced with the actual name of your bucket, while the wildcard suffix/*is kept intact).
Note: Ensure to use the accurate S3 bucket name designated for the destination AWS account.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:ListBucket" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::s3-bucket-name" ] }, { "Action": [ "s3:GetObject", "s3:PutObject", "s3:DeleteObject" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::s3-bucket-name/*" ] } ] } |
Step 2: Create an IAM Role
In the source AWS account, create an AWS IAM role.
This role will use the IAM policy created in the previous step.
Take the following steps in the AWS console:
- In the AWS console, navigate to IAM
- Go to the ‘Roles’ page. Choose ‘Create role’, then ‘AWS service’.
- For use case, select ‘EC2’.
- In ‘Add permission’, select the policy created earlier in Step 1.
- Create the role with your desired name. For example: ‘SnapshotRole’
- Once created, select the role again and go to ‘Trust relationships’ and ‘Edit trust policy’. Replace the service ec2.amazonaws.com with es.amazonaws.com as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": "es.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } |
Make a note of the ARN of this IAM role – it will be needed later.
Step 3: Create an IAM user
In the source AWS account, create a new IAM user.
This user will be used to register the destination cluster’s snapshot repository in the AWS OpenSearch Service cluster. If you have an existing user that you would like to use, you can skip the user creation step.
First, we will create a new IAM user with no permissions:
- In the AWS console, navigate to IAM
- Go to the ‘Users’ page. Choose ‘Create user’.
- Ignore all the permissions options – choose ‘Next’ and ‘Create user’ for now. This will create a blank user with no permissions.
Navigate to the user you just created and set permissions:
- Choose ‘Add permissions’, then ‘Create inline policy’.
- Set the policy editor to JSON, and use the policy below.
The following placeholders need to be replaced in the template below:
- The ARN of the role you created in the previous step.
- The ARN of your AWS OpenSearch domain. Please ensure that the wildcard suffix is kept after the ARN (the resource should end with a forward slash followed by an asterisk, “/*”).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "iam:PassRole", "Resource": "arn:aws:iam::123456789012:role/SnapshotRole" }, { "Effect": "Allow", "Action": "es:ESHttpPut", "Resource": "arn:aws:es:region:123456789012:domain/AWSOpenSearchServiceDomain/*" } ] } |
Now you have all the required IAM roles and policies.
Make a note of the ARN of this IAM user – it will be needed later.
Step 4: Map Elasticsearch Roles to allow AWS OpenSearch Service to manage snapshots
The source cluster requires Elasticsearch-specific permissions to register the destination cluster’s backup bucket.
There are two ways to accomplish this step:
- Using Kibana
- Using the REST API
Using Kibana is easier if it is enabled, but this option is only convenient if you have network access to your source cluster’s Kibana URL – for example, this may be difficult if the source cluster is in a private VPC. This guide will provide steps for both options.
Managing Role Mappings using Kibana
Earlier, we created an IAM user, and an IAM role.
In this step, we will map the user and role together in the Elasticsearch security plugin, allowing the user to register a snapshot repository.
- In the AWS console, go to ‘Amazon OpenSearch Service’, and go to ‘Domains’. Find the source cluster. In the general information for this cluster, there should be a ‘Kibana URL’.
- Visit the Kibana URL in your browser.
(If you are unable to reach Kibana, skip to the next section: “Mapping roles via CURL”.) - In Kibana, go to ‘Security’ in the sidebar, then ‘Roles’.
- Search for ‘manage_snapshots’.

- Click the ‘manage_snapshots’ role and go to the ‘Mapped users’ tab. Choose ‘Manage mapping’.
- In ‘Users’, provide the ARN of the IAM user you created earlier.
(Don’t use the ‘Create new internal user’ button – this is not necessary.) - In ‘Backend roles’, provide the ARN of the IAM role you created earlier.
- Choose ‘Map’ to create the mapping.

- The ‘Mapped users’ tab should now show the IAM user mapped to the IAM role.
Managing Role Mappings using the REST API
When working with role mappings during your migration process, it is important to note that the REST API request syntax may vary depending on whether your source cluster is running OpenSearch, or Open Distro for Elasticsearch. Below, we provide the relevant curl commands for each to help you create or replace the specified role mappings.
Creating role mapping in Open Distro for Elasticsearch
The following command will create a role mapping called ‘manage_snapshots’.
Two placeholders need to be replaced:
- The ARN of the IAM user created earlier.
- The ARN of the IAM role created earlier.
|
1 2 3 4 5 6 7 8 9 10 |
curl -X PUT -u <username>:<password> "https://<host_domain_endpoint>:9200/_opendistro/_security/api/rolesmapping/manage_snapshots" -H 'Content-Type: application/json' -d' { "hosts": [], "users": [ "arn:aws:iam::1234567892716:user/user-test-migration" ], "backend_roles": [ "arn:aws:iam::1234567892716:role/user-test-migration-snapshot-role" ] }' |
For detailed information on role mappings within Open Distro for Elasticsearch, refer to the Open Distro for Elasticsearch documentation.
Creating role mapping in OpenSearch
The following command will create a role mapping called ‘manage_snapshots’.
Two placeholders need to be replaced:
- The ARN of the IAM user created earlier.
- The ARN of the IAM role created earlier.
|
1 2 3 4 5 6 7 8 9 10 11 |
curl -X PUT -u <username>:<password> "https://<endpoint>:9200/_plugins/_security/api/rolesmapping/manage_snapshots" -H 'Content-Type: application/json' -d' { "hosts": [], "users": [ "arn:aws:iam::1234567892716:user/user-test-migration" ], "backend_roles": [ "arn:aws:iam::1234567892716:role/user-test-migration-snapshot-role" ], "and_backend_roles": [] }' |
For detailed information on role mappings within OpenSearch, refer to the OpenSearch documentation.
Step 5: Update S3 Bucket permissions (temporary settings)
Next, switch to the destination account – the AWS account set up for Instaclustr BYOC provisioning – to configure permissions that allow the source account to access the bucket. These changes are temporary and will be rolled back once the backup is completed successfully.
Go to the S3 bucket which has been configured as your destination cluster’s backup bucket and select the “Permissions” tab.
- Edit bucket policy and provide the following:
- ARN of the IAM role created in Step 2.
- ARN of this S3 bucket ending with /*
1234567891011121314151617{"Version": "2012-10-17","Statement": [{"Effect": "Allow","Principal": {"AWS": "arn:aws:iam::123456789012:role/SnapshotRole"},"Action": ["s3:GetObject","s3:PutObject","s3:PutObjectAcl"],"Resource": "arn:aws:s3:::s3-bucket-name/*"}]}Once provided click Save changes.
- Once the bucket’s policy changes are saved. Navigate to Edit “Object Ownership”, select “ACLs enabled”, keep the “Bucket owner preferred” setting and click Save Changes.

- Edit “Access control list (ACL)”, click “Add grantee” and provide the canonical ID of the source AWS account.
(The canonical ID can be found by logging into the AWS console as the source account, choosing your user name drop down in the top right, and going to “Security credentials” – on this page, there is a ‘Canonical User ID’ field.) - Select the ‘List’ and ‘Write’ options under ‘Objects’. Click ‘Save changes’.

Step 6: Register the snapshot repository with AWS OpenSearch Service and initiate a backup
To set up a manual repository on the AWS OpenSearch cluster and initiate a backup, we have adapted the Python script from the AWS documentation, which can be executed within AWS CloudShell or from an EC2 instance that has connectivity to the source AWS OpenSearch cluster to register the repository and initiate the backup.
1. Create an Input file (json)
For the python script to execute correctly, the user must supply specific details regarding the source cluster and the destination backup bucket. This information should be entered into a JSON file, which the python script will then utilize to register the repository and start the backup process.
The following is an example of a dataset in JSON array format, which includes two entries representing two separate objects or source clusters. The information pertaining to the second object or source cluster is optional and can be omitted if not needed, but can be useful when migrating multiple clusters at a time. At least one set of source cluster information is needed for the Python script to perform the repository registration and initiate the backup process.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
[ { "host": "https://search-example-source-cluster-53ilhjrtdlrziirybjqpzdggmu.us-east-1.es.amazonaws.com", "region": "us-east-1", "repository_api_endpoint": "source-repository", "snapshot_name": "source-snap-name", "s3_bucket_name": "s3-bucket-name", "s3_base_path": "4066e28c-c724-44b2-9754-a38f039860a1/folder-name", "s3_role_arn": "arn:aws:iam::123456789012:role/SnapshotRole" }, { "host": "second…host…in…the…same…region…if…required…otherwise…remove", "region": "us-east-1", "repository_api_endpoint": "another-repository", "snapshot_name": "another-snap", "s3_bucket_name": "manual-repo-riyoa", "s3_base_path": "<AWS_RIYOA_CLUSTER_ID>/source-repository", "s3_role_arn": "xxx:aws:iam::123456789012:role/TheSnapshotRole" } ] |
Further explanation on input parameters:
- host
This value represents the Domain endpoint (IPv4) and can be obtained from the General Information page of the source cluster’s domain.

- region
The name of region in which the AWS OpenSearch cluster is currently present.
For example: us-east-1 - repository_api_endpoint
The name of the snapshot repository to register.
For example: source-repository
Note: Repository names cannot start with “cs-“. Additionally, you shouldn’t write to the same repository from multiple domains. Only one domain should have “write” access to the repository.
- snapshot_name
Name of the snapshot. Must be unique within the snapshot repository.
- s3_bucket_name
Name of the s3 bucket that resides in the destination account.
- s3_base_path
Specifies the path within s3 bucket where backup data will be stored. We recommend using a base path that should comprise of “<BYOC_CLUSTER_ID>/<S3 Bucket Folder name of your choice>”.
For example: 4066e28c-c724-44b2-9754-a38f039860a1/source-repository
- s3_role_arn
The snapshot role ARN which was created in the source account as stated in step 2
for example: arn:aws:iam::123456789012:role/SnapshotRole
2. Saving the input file inside an AWS Cloud Shell session
AWS CloudShell is a browser-based shell that gives you command-line access to your AWS resources in the selected AWS Region. AWS CloudShell comes pre-installed with popular tools for resource management and creation. You have the same credentials as you use to log in to the console.
After preparing the input.json file for import into the Cloud Shell, initiate an AWS CloudShell session in the source account. To begin, look at the top right corner of the AWS Management Console; the CloudShell icon is typically the first one displayed, as illustrated in the image below:
![]()
run command:
|
1 |
cat > input.json << 'EOF' |
Paste the json file contents and write ‘EOF’ to close and save the file with name input.json
3. Running python script
The Python script below is designed to use the input.json file created earlier. It will use these parameters to register the snapshot repository and take a snapshot.
To create the script file, run the command in AWS Cloud Shell
|
1 |
cat > snapshot.py << 'EOF' |
Press the “return” key to start a new line, then copy the entire Python script provided below and paste it into the AWS Cloud Shell. After pasting, press “return” once more to begin a new line and type ‘EOF’ to signify the end of the file input, which will save the script as ‘snapshot.py’. Finally, press enter to complete the process. (This method employs the ‘here document’ syntax for file creation.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
import boto3 import json import requests from requests_aws4auth import AWS4Auth import sys, traceback # To reduce the exception trace back and return only meaningful value def hook_for_exception(type, value, tb): trace = traceback.format_tb(tb, limit=1) trace = trace[0].split("\n")[0] exc = traceback.format_exception_only(type, value)[0] print("\n" + trace + "\n" + exc) sys.excepthook = hook_for_exception # Common method to print the result for the API requests (registering repository and snapshot) def print_result(success_message, failure_message, status_code, status_text): if str(status_code) == "200": print(success_message) print(status_text) else: print(failure_message) print(str(status_code) + " - " + status_text) file_name = input("Please enter the JSON file name: ") while not file_name.endswith(".json"): file_name = input("Enter file name with .json extension: ") file_contents = open(file_name) data = json.load(file_contents) for i in data: host = i["host"] + "/" region = i["region"] service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) # Register repository api_endpoint = i["repository_api_endpoint"] bucket = i["s3_bucket_name"] base_path = i["s3_base_path"] role_arn = i["s3_role_arn"] path = '_snapshot/{}'.format(api_endpoint) # the OpenSearch API endpoint url = host + path payload = { "type": "s3", "settings": { "bucket": "{}".format(bucket), "region": "{}".format(region), "base_path": "{}".format(base_path), "role_arn": "{}".format(role_arn) } } headers = {"Content-Type": "application/json"} response_rego = requests.put(url, auth=awsauth, json=payload, headers=headers) print_result("\nRegistration of Snapshot repository is completed for {}".format(host), "\nError while Registering Snapshot repository for {}".format(host), response_rego.status_code, response_rego.text) if response_rego.status_code == 200: # Take snapshot snapshot = i["snapshot_name"] backup_path = '_snapshot/{}/{}'.format(api_endpoint, snapshot) backup_url = host + backup_path response_snap = requests.put(backup_url, auth=awsauth) print_result("Snapshot: {} Triggered successfully for {}".format(snapshot, host), "\nSnapshot: {} cannot be taken successfully for {}".format(snapshot, host), response_snap.status_code, response_snap.text) else: print("\nSkipping snapshot creation because Snapshot Repository was not registered successfully for " + host) # Closing file file_contents.close() |
4. Install dependencies for the script
Prior to executing the script, dependencies must be installed.
Run the following commands in AWS CloudShell:
|
1 2 3 4 5 6 7 8 9 10 |
# Create a virtual environment python3 -m venv venv # Enter the virtual environment # (This step will be needed every time the script is used) source venv/bin/activate # Install dependencies pip3 install boto requests-aws4auth |
5. Generate access and secret key
The script needs to act as the IAM user created in step 3. To do so, we can generate an access key and secret key.
Take the following steps (further details in AWS User guide if needed):
- In the AWS console, locate the IAM user that you created earlier.
- In this user, go to the ‘Security Credentials’ tab.
- Go to ‘Access keys’ and ‘Create access key’. (For use-case, choose ‘Command line interface’).
- Record the access key and secret key that are generated in a secure location.
6. Use access key
Now we need to make use of the access key and secret key generated in the previous step.
In CloudShell, run the following command:
aws configure
Follow prompts to enter the access key and secret key in this environment
7. Run the Python script
- Confirm that everything is ready:
– If you runaws sts get-caller-identity, this should have the ARN of the IAM user you created earlier, indicating thataws configurewas used successfully.
– Your shell prompt should start with(venv), indicating that you are still in the virtual environment that was created earlier. (If not, runsource venv/bin/activateagain.) - Run the script with the following command:
python snapshot.py - On the prompt to enter the file name, provide the name of the JSON file that you created in an earlier step – ‘input.json’.
- The script will attempt to register the repository; if this is successful, it will also attempt to trigger a backup. The output should be similar to this example:

NOTE: By default, the create snapshot API only initiates the snapshot process, which runs in the background. Depending on its size, a snapshot can take some time to complete and does not represent perfect point-in-time view of the cluster.
Since snapshots are incremental, meaning that they only store data that has changed since the last successful snapshot, we recommend taking snapshots until the snapshot time falls into acceptable downtime range.
If you need to delete a snapshot, be sure to use the OpenSearch API rather than navigating to the storage location and purging files. Incremental snapshots from a cluster often share a lot of the same data; when you use the API, OpenSearch only removes data that no other snapshot is using.
After the backup has finished successfully, check to ensure that the objects are present within the directory or base path of the backup bucket specified in the JSON file. If you have the bucket page open, you might need to click on “Refresh Objects” to view the new objects.
Step 7: Unthrottle restore settings on destination cluster
Since the destination cluster will not be used until after the restore is complete, the performance impact of the restore process on the destination cluster does not matter. We can unthrottle restore-related settings to speed up the snapshot restore.
On the destination cluster, perform the following API call to speed up the restore process:
|
1 2 3 4 5 6 7 8 9 |
curl -X PUT -u <username>:<password> "https://<endpoint>:9200/_cluster/settings -H 'Content-Type: application/json' -d ' { { "persistent" : { "indices.recovery.max_bytes_per_sec" : "100gb", "indices.recovery.max_concurrent_file_chunks" : "5", "indices.recovery.max_concurrent_operations" : "4" } }' |
Step 8: Recreate users and other artefacts on destination cluster
The steps in this document will migrate indices from the source cluster to the destination cluster. However, the steps will not bring the following objects:
- Users, roles, and role mappings, if role-based access control is in use on the source cluster.
- Index templates
- Ingest pipelines
- Cluster settings
If the source cluster has any of these objects in use, they will need to be recreated using the OpenSearch REST API at this point.
Step 9: Prepare for the Final Incremental Snapshot
-
Client Shutdown:
Prior to initiating the final incremental snapshot, ensure all client applications that interact with your OpenSearch cluster are properly and safely shut down. This is a critical step to prevent any data changes during the snapshot process and ensure data consistency.
-
Update Client Configuration:
While your client applications are offline, update their configurations to point to the new destination OpenSearch cluster. This will typically involve:
- changing the endpoint URLs your application uses to connect to the cluster
- changing the username and password the application uses to authenticate (unless you recreated users and roles from the source cluster in the previous step)
Step 10: Rollback S3 bucket permissions
This step will ensure that the destination cluster is able to access the snapshot generated by the source cluster.
Proceed with this step only after confirming that the backup has been completed.
1. Rollback S3 bucket permissions (Destination Account)
As the source cluster’s account holds the ownership of the objects in the bucket currently, it is essential to transfer ownership of the snapshot objects to the destination AWS account for restore requests to succeed. To accomplish this, reverse the modifications implemented in Step 5 by disabling the ACL and removing the bucket policy.
Following, we have outlined two methods to revert the S3 Bucket permissions to their previous state. The first method involves utilizing a Python script crafted to specifically reverse those permissions. The second method entails performing the rollback manually via the AWS Management Console.
OPTION 1: Using Python Script
The Python script requires the name of the S3 Bucket as an input parameter to execute the rollback operations. For instance, here ‘fshami-manual-repo-riyoa‘ as demonstrated in the screenshot provided below

Additionally, to make use of this method, the IAM user should have the appropriate permissions, such as s3:DeleteBucketPolicy, WRITE_ACP, and s3:PutBucketOwnershipControls. You can run this script in the destination account’s AWS Cloud Shell, which avoids the need for installing additional dependencies. If you opt not to use AWS Cloud Shell, you’ll need to prepare your local environment according to the instructions in the Boto3 Quick Start guide.
Using AWS Cloud Shell, run command:
Paste the file contents, hit ‘enter’ and write ‘EOF’ to close and save the file with
|
1 |
cat > rollback.py << 'EOF' |
After saving the file, the user can execute it by typing python rollback.py into the command prompt, then entering the S3 bucket name when prompted, and the script will carry out the rollback operations.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
import boto3 bucket_name = input("Please enter the bucket name to rollback the given S3 permissions: \n") s3_client = boto3.client('s3') def rollback_bucket_policy(bucket, client): bucket_policy_response = client.delete_bucket_policy( Bucket=bucket, ) get_response(bucket_policy_response, "Bucket Policy Deleted", "Bucket policy cannot be deleted, please check user permissions") def rollback_bucket_acl(bucket, client): try: bucket_acl_response = client.put_bucket_acl( ACL='private', Bucket=bucket ) except: print("Access for other AWS accounts cannot be removed from Bucket, " "either it is already done manually or the user has not sufficient permissions, " "please login to AWS Console and verify S3 Bucket permissions tab") else: get_response(bucket_acl_response, "Access for other AWS accounts has been removed from Bucket", bucket_acl_response) finally: rollback_bucket_ownership(bucket_name, s3_client) def rollback_bucket_ownership(bucket, client): bucket_ownership_response = client.put_bucket_ownership_controls( Bucket=bucket, OwnershipControls={ 'Rules': [ { 'ObjectOwnership': 'BucketOwnerEnforced' }, ] } ) get_response(bucket_ownership_response, "Bucket Object Ownership has been reset to BucketOwnerEnforced", "Bucket Object Ownership cannot be reset, please check user permissions") def get_response(response_msg, pass_message, fail_message): response_status_code = response_msg["ResponseMetadata"]["HTTPStatusCode"] if str(response_status_code) == "200" or str(response_status_code) == "204": print(pass_message) else: print(fail_message) try: # check for bucket existence response = s3_client.head_bucket( Bucket=bucket_name, ) get_response(response, "Bucket found, continuing rollback operation...", response) rollback_bucket_policy(bucket_name, s3_client) rollback_bucket_acl(bucket_name, s3_client) print("Destination or BYOC account Bucket Settings has been roll backed successfully.") except: print("Bucket not found, please check bucket name and try again!") |
OPTION 2: Manual approach using AWS Console.
Go to the s3 bucket in the destination account and select “Permissions”
- Delete the bucket policy that was to grant permissions for the snapshot role.
- Edit access control list (ACL) and remove the access granted for the source account, Save changes.
- Edit “Object Ownership” and select “ACLs disabled (recommended)”. Then Save changes.

2. Delete the IAM Role and IAM User in the source account (Optional)
- The Snapshot role and IAM user that were set up in the source account for the backup process, as outlined in steps 1 and 2, can now be removed.
- After deleting the Snapshot role and user, proceed to eliminate any redundant mappings from the AWS OpenSearch Service’s Kibana.
3. Remove credentials from AWS Cloud Shell session (Source Account)
Run the following commands in the AWS CloudShell session to remove the access and secret keys:
|
1 2 |
aws configure set aws_access_key_id "" aws configure set aws_secret_access_key "" |
Alternatively, you can delete the credential file along with other files
|
1 2 3 |
rm ~/.aws/credentials rm ~/path/to/input.json rm ~/path/to/script.py |
Step 11: Register snapshot repository in destination cluster
To restore data to the destination cluster, it is necessary to establish a custom repository for the destination cluster that shares the same base path used during the backup.
Use the API call provided below, ensuring to substitute the placeholders enclosed in angle brackets with the correct data.
|
1 2 3 4 5 6 7 8 9 |
curl -X PUT -u <username>:<password> "https://<endpoint>:9200/_snapshot/<repository-name>" -H 'Content-Type: application/json' -d' { "type": "s3", "settings": { "bucket": "<S3-bucket-name>", "base_path": "<cluster_id>/<custom-snapshot-repository-base-path>", "readonly": true } }' |
NOTE: Please provide the correct base_path, it should be the same base path used to create backup, created in step 6 and mentioned in the input json file as “s3_base_path”. For e.g: “4066e28c-c724-44b2-9754-a38f039860a1/folder-name“.
It is important to use the “readonly“: true setting, as shown above. If you forget to do so, the repository metadata may become corrupt, leading to errors when attempting to use the repository.
Step 12: Initiate snapshot restore
Once the snapshot repository registration is successful, you can confirm the snapshot and perform restore.
You can run GET /_snapshot/<repository-name>/_all to list snapshots in the repository – this can be used to get the name of the snapshot taken before, which is required for the next step.
|
1 2 3 4 |
curl -X POST -u <username>:<password> "https://<endpoint>:9200/_snapshot/<repository-name>/<snapshot-name>/_restore?wait_for_completion=true -d ' { "indices": "-.opendistro_security" }' |
The ‘indices’ argument uses multi-target syntax. We should avoid attempting to restore the ‘.opendistro_security’ index, because it is not possible to restore over an existing index. The example above will restore all indices except ‘.opendistro_security’. It is also possible to supply a list of indices to restore – eg, if there were two indices called ‘customers’ and ‘accounts’, we could run the call with ”indices”: “customers,accounts”, and only those two indices would be restored
The snapshot restore is a blocking call (due to our use of the wait_for_completion parameter) – this call will hang until the snapshot is completed. Depending on the client you are using to make the snapshot call, you may need to increase a timeout setting to wait until this returns output. If the client times out, the restore will continue, but we would not know when it finishes, or receive confirmation that all shards were successfully restored.
Step 13: Monitor restore progress
Snapshot restore speed varies – depending on the number of nodes and the presence or absence of resource bottlenecks, it can take from tens of MB/s to hundreds of MB/s.
If you need to know when the restore is expected to finish, the following steps can provide some information about progress:
- Check the total number of shards. When all shards involved in the restore are present and in GREEN status on the destination cluster, the restore will be finished. The results of a GET /_cat/health?v call will show the number of shards in the cluster, as well as overall cluster health. If your shards are roughly similar in size, comparing the number of shards present on the source and destination clusters can provide a rough progress indicator (although the final count may not be identical, due to differences in the configuration of system indices.)
- Check recovery tasks. Snapshot restore works via the shard recovery mechanism. To view ongoing shard recovery tasks, you can run GET /_cat/recovery?v&active_only=true on the destination cluster. This doesn’t show overall progress (many recovery tasks will start and finish throughout the process), but it provides detailed information about what is currently being done – this can help to clarify what’s going on if large shards are taking a long time.
When the restore is complete, the restore API call should return output, showing which indices were restored, the snapshot name, and mostly importantly, the success or failure of the restore. Example output:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{ "snapshot": { "snapshot": "source-snap-name-2", "indices": [ "baseline" ], "shards": { "total": 6, "failed": 0, "successful": 6 } } } |
Check the output and verify that there are zero failures.
Step 14: Restart Client Applications
After successfully completing the final restore and verifying that the target cluster is prepared to handle traffic, you can bring your client applications back online. Make certain that they are now connecting to the destination cluster by monitoring the connections and conducting tests on the functionality to ensure that the migration is seamless and does not disrupt the experience of the end-users.
Step 15: Return restore speed to default
Earlier, we increased various settings to speed up snapshot restore.
We should return these settings to default – otherwise, we may see performance issues during non-urgent operations, such as the replacement of a failed node.
On the destination cluster, perform the following API call:
|
1 2 3 4 5 6 7 8 9 |
curl -X PUT -u <username>:<password> "https://<endpoint>:9200/_cluster/settings -H 'Content-Type: application/json' -d ' { { "persistent" : { "indices.recovery.max_bytes_per_sec" : null, "indices.recovery.max_concurrent_file_chunks" : null, "indices.recovery.max_concurrent_operations" : null } }' |
Known Errors and Solutions
Error: Bucket Does Not Allow ACLs
When attempting to register your S3 bucket for use with AWS OpenSearch or during other operations, you may encounter the following error message:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ "error": { "root_cause": [ { "type": "repository_verification_exception", "reason": "[fshami-manual-repo-4] path [eb2488cc-df5e-440e-99be-ad1bc3aaab10] is not accessible on master node" } ], "type": "repository_verification_exception", "reason": "[fshami-manual-repo-4] path [eb2488cc-df5e-440e-99be-ad1bc3aaab10] is not accessible on master node", "caused_by": { "type": "i_o_exception", "reason": "Unable to upload object [eb2488cc-df5e-440e-99be-ad1bc3aaab10/tests-UI0aUY5USOG_XTIVfv8sEQ/master.dat] using a single upload", "caused_by": { "type": "amazon_s3_exception", "reason": "amazon_s3_exception: The bucket does not allow ACLs (Service: Amazon S3; Status Code: 400; Error Code: AccessControlListNotSupported; Request ID: ATEEWMP7AGNKXDWJ; S3 Extended Request ID: McXeAqDJhvth6oapi5HEnHYEmBAL71pVXEh6eqAyhA97/5YMkuMcOzwpd9q0+l7TNl8MZgWDcrk=)" } } }, "status": 500 } |
Solution:
To resolve this issue, you will need to modify the bucket’s permissions to enable ACLs. Here’s how you can do this:
- Navigate to the Amazon S3 console.
- Find the bucket in question and click on its name to view its settings.
- Go to the ‘Permissions’ tab for the bucket.
- Edit “Object Ownership”, select “ACLs enabled”, keep the “Bucket owner preferred” setting.
- Save the changes and retry the operation that previously caused the error.
Error: Using same repository with same objects
That error is typically when you register a repository as read / write on more than one cluster. Also, if you are using same base_path and not a different folder for restoring the objects it will show this error.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{ "error": { "root_cause": [ { "type": "repository_exception", "reason": "[s3-repo] Could not read repository data because the contents of the repository do not match its expected state. This is likely the result of either concurrently modifying the contents of the repository by a process other than this cluster or an issue with the repository's underlying storage. The repository has been disabled to prevent corrupting its contents. To re-enable it and continue using it please remove the repository from the cluster and add it again to make the cluster recover the known state of the repository from its physical contents." } ], "type": "repository_exception", "reason": "[s3-repo] Could not read repository data because the contents of the repository do not match its expected state. This is likely the result of either concurrently modifying the contents of the repository by a process other than this cluster or an issue with the repository's underlying storage. The repository has been disabled to prevent corrupting its contents. To re-enable it and continue using it please remove the repository from the cluster and add it again to make the cluster recover the known state of the repository from its physical contents." }, "status": 500 } |
Solution:
Delete the repository by DELETE _snapshot/<REPOSITORY_1>/ and recreate the repository with the correct base path. You can also use readonly option just add a comma after the base path and add a new attribute with value “readonly”: “true”
How do I resolve the manual snapshot error in my OpenSearch Service cluster?
Please refer to https://repost.aws/knowledge-center/opensearch-manual-snapshot-error.
Credential retrieval error
When running the python script to create the repository, if you experience the following error:
botocore.exceptions.CredentialRetrievalError: Error when retrieving credentials from container-role: Error retrieving metadata: Received non 200 response 500 from container metadata
This indicates that your access key and secret key have not been configured properly (via aws configure) – see the AWS documentation on configuring the CLI.
We hope this guide has provided you with a clear and comprehensive path for your snapshot migration from AWS OpenSearch Service to Instaclustr BYOC. Should you have any questions or require further clarification on any of the steps outlined in this guide, please do not hesitate to reach out the Instaclustr Support team at [email protected]. We’re here to ensure your migration process is as smooth and successful as possible.