In-place Data Centre Resizing
Nodes in a cluster data centre can be resized in-place via the Console or by issuing an API request. Resizing nodes let you scale the CPU core count and memory quota to meet changing demands and is significantly faster than adding additional Cassandra nodes.
Table of Contents
Preparation
Instaclustr recommends that you first test your applications against a data centre in a non-production setting to verify that the resize process doesn’t interrupt your applications.
During a cluster resize operation one or more nodes will temporarily become unavailable as they are resized. Cassandra, as a whole, will handle these transient outages to ensure data consistency but client applications need to be programmed with certain considerations in mind.
Instaclustr will only concurrently resize nodes within the same rack to ensure that replicas stored in other racks remain available during the resize.
Minimum Requirements
- All keyspaces are using the Replication Strategy class:
org.apache.cassandra.locator.NetworkTopologyStrategy - All keyspaces have a Replication Factor ≥ 3 for the data centre.
A RF of 0 or no RF specified is also permitted which implies no replicas exist in the data centre. - The number of nodes in the data centre is ≥ the specified Replication Factor for that data centre.
Additionally, you may only concurrently resize more than one node at a time in a data centre if:
- The number of racks ≥ Replication Factor
Query Consistency Levels
Your clients query consistency level, which you can configure globally or per-query, specifies how many Cassandra replicas are required to acknowledge a read or write operation. During a data centre resize one or more nodes, and therefore replicas, will be temporarily offline. The query consistency level needs to be selected carefully to ensure that these transient outages won’t cause the queries to fail due to lack of sufficient replicas.
If you have a requirement to use a consistency level that will fail during a resize, then you will need to ensure that your application correctly handles the errors or exceptions returned or thrown by the Cassandra driver.
Different consistency levels will either allow queries to execute successfully or exhibit certain failure modes during a resize, as outlined below.
| Consistency Level | Query Behaviour During Resize |
|---|---|
ANY |
Success |
ONE |
Success |
TWO |
Success |
THREE |
Cluster with a single data centre with a keyspace Replication Factor ≤ 3: Failure Cluster with a single data centre with a keyspace Replication Factor > 3: Success Cluster with multiple data centres: Success |
QUORUM |
Success |
ALL |
Failure
Cassandra will be unable to contact all replicas as one or more nodes will be offline during the resize. Instaclustr recommends that your clients do not use the |
LOCAL_ONE |
Success |
LOCAL_QUORUM |
Success |
EACH_QUORUM |
Success |
SERIAL |
Same as QUORUM |
LOCAL_SERIAL |
Same as LOCAL_QUORUM |
Resizing
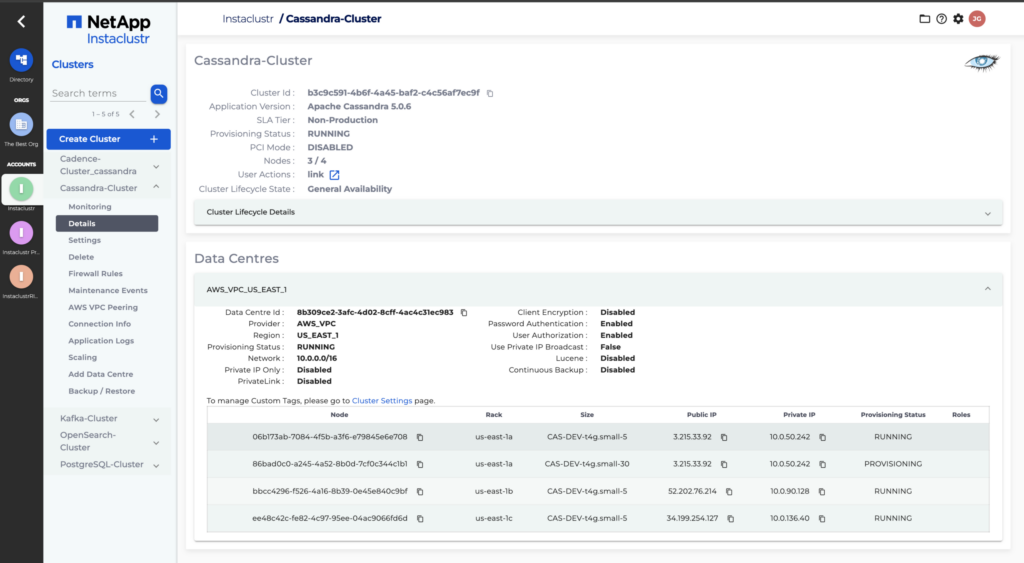
- To in-place resize node(s) on your existing cluster, log into the Instaclustr console.
- Select your running Cassandra cluster from the sidebar menu and Click Scaling.
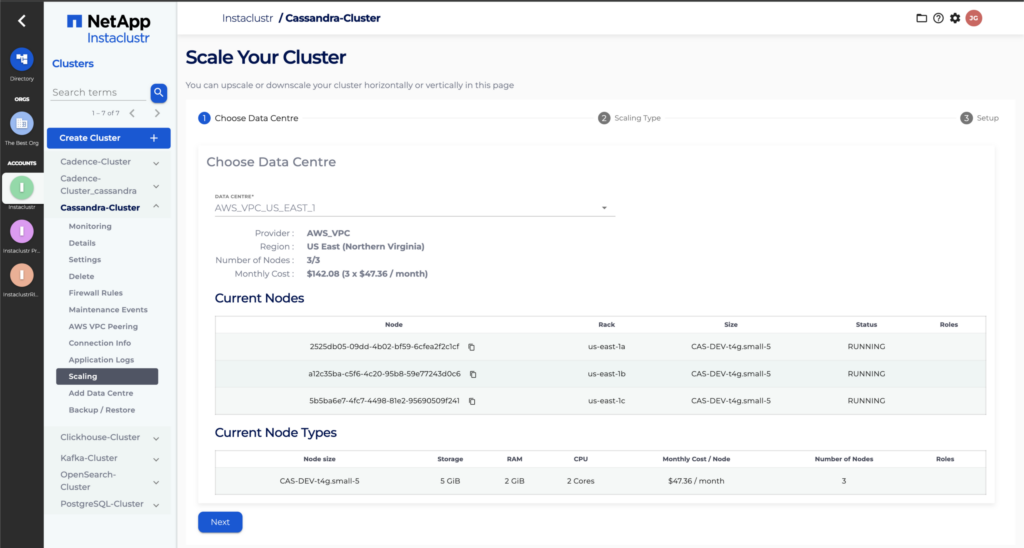
- Select the data centre you want to resize and Click Next.
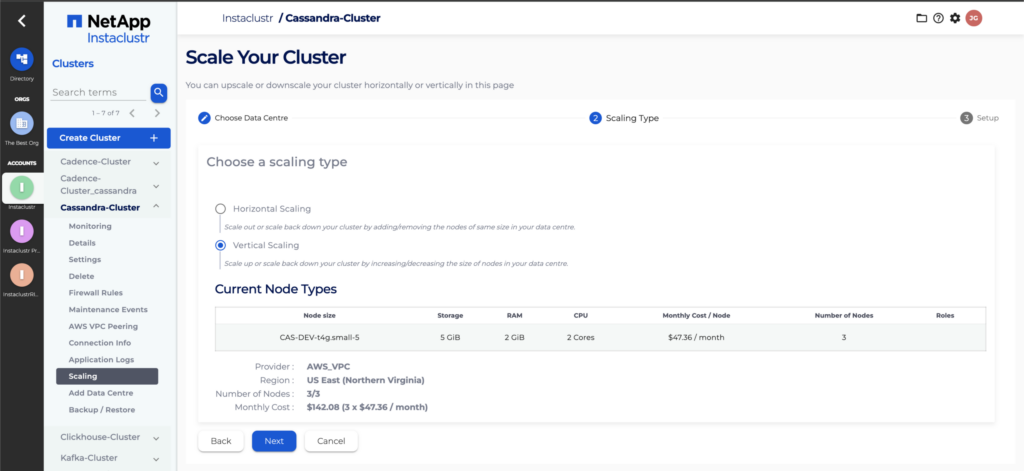
- Choose Vertical Scaling and Confirm the nodes information before clicking next.
- Fill in the required information on the Vertical Scaling page and Click the Resize button.
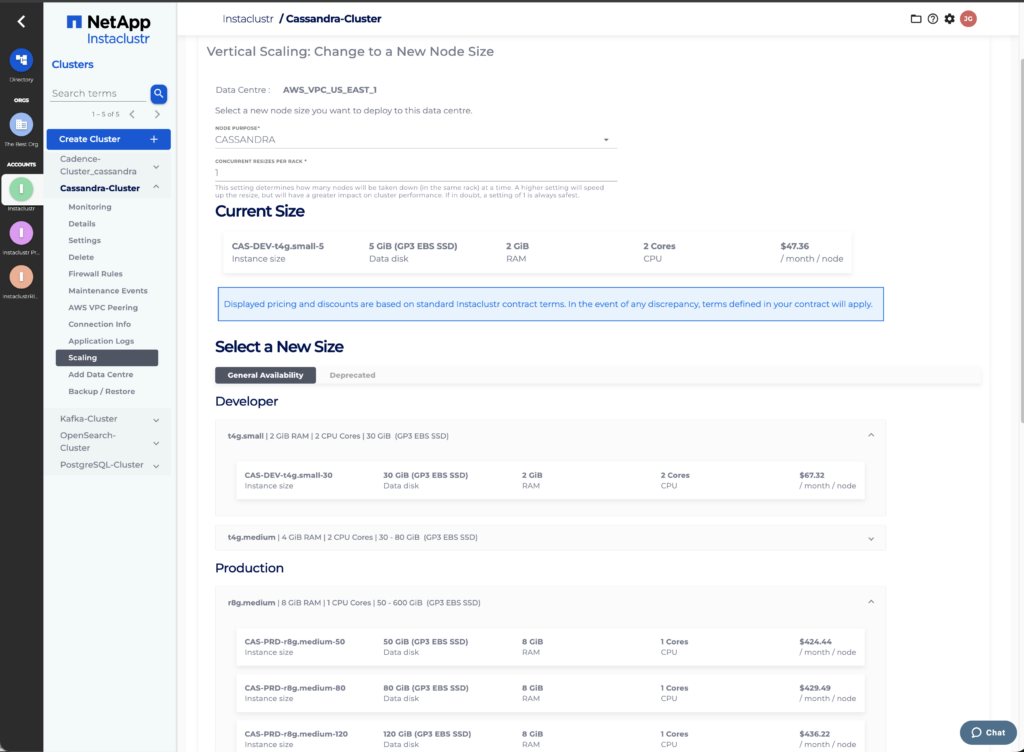
The vertical scaling page lets you select the desired target node purpose, size and specify the resize concurrency factor and notification options. The difference in CPU core count, memory quota and total monthly price are listed on the page.
The Concurrency Factor is a number, from 1 to the count of nodes in the largest rack, that specifies how many nodes may be resized at the same time. Instaclustr will only resize multiple nodes concurrently if they are located in the same rack.After you have selected a new size, you will be shown a summary of the resize, which will include the new price for managing your cluster and any changes in the new size resources. Click on Resize to begin.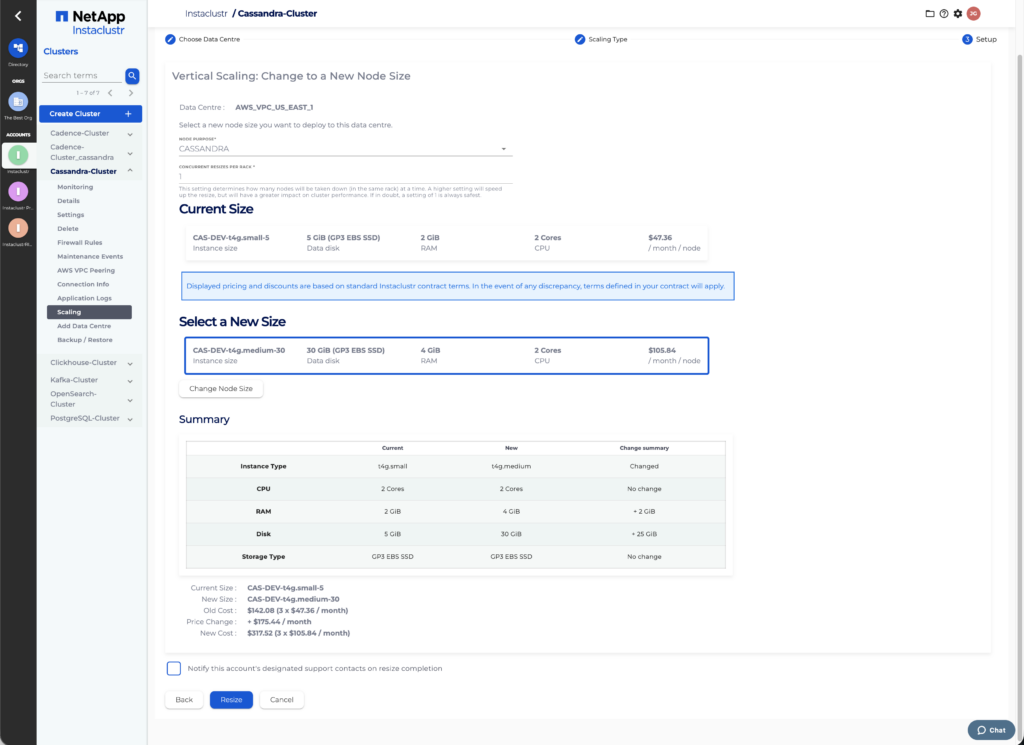 If your new node size has any downsized resources, you will be warned and asked to acknowledge the risk with downsizing by checking the appropriate checkbox.
If your new node size has any downsized resources, you will be warned and asked to acknowledge the risk with downsizing by checking the appropriate checkbox.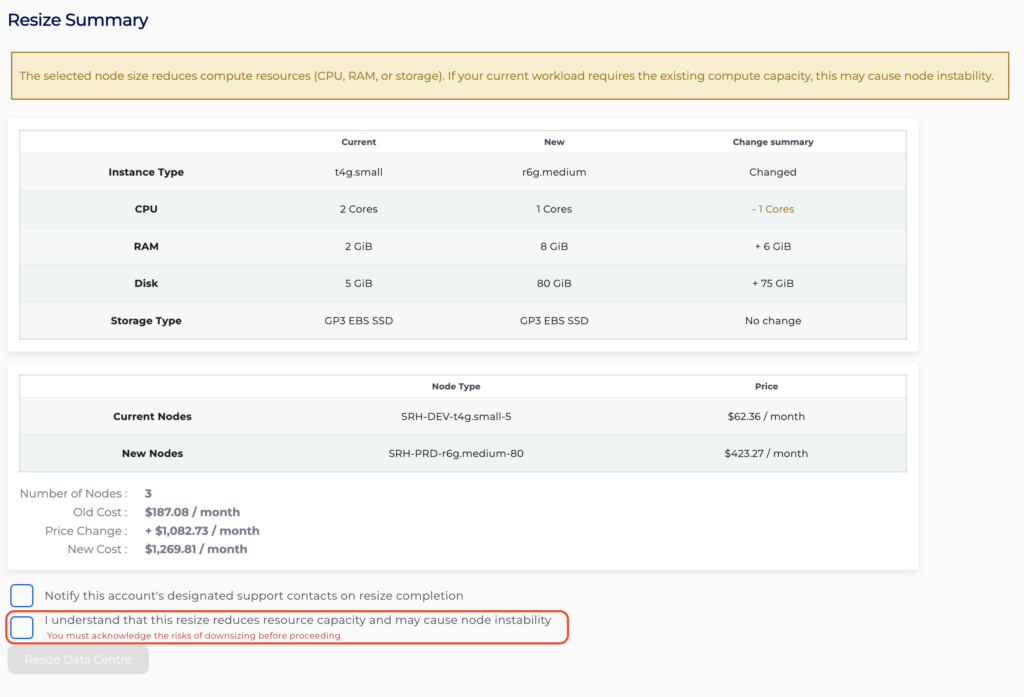
- Once a resize is in progress it cannot be cancelled. Your accounts’ designated support contact will receive a notification if the Notify this accounts’ designated support contacts on resize completion checkbox is selected.
- While a resize is in progress, the Scaling page will display the progress of the resize. You will see individual nodes switch statuses as they progress through the scaling process.
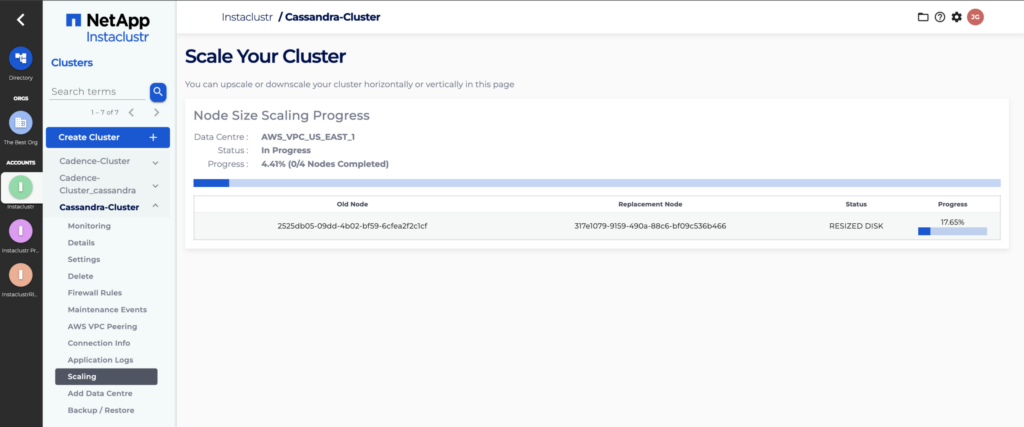 The Cluster Details page will also display the progress of the resize operation. You will see individual nodes switch from Running to Pending → Provisioning/Provisioned and then back to Running once their size has been changed.
The Cluster Details page will also display the progress of the resize operation. You will see individual nodes switch from Running to Pending → Provisioning/Provisioned and then back to Running once their size has been changed.