Slots
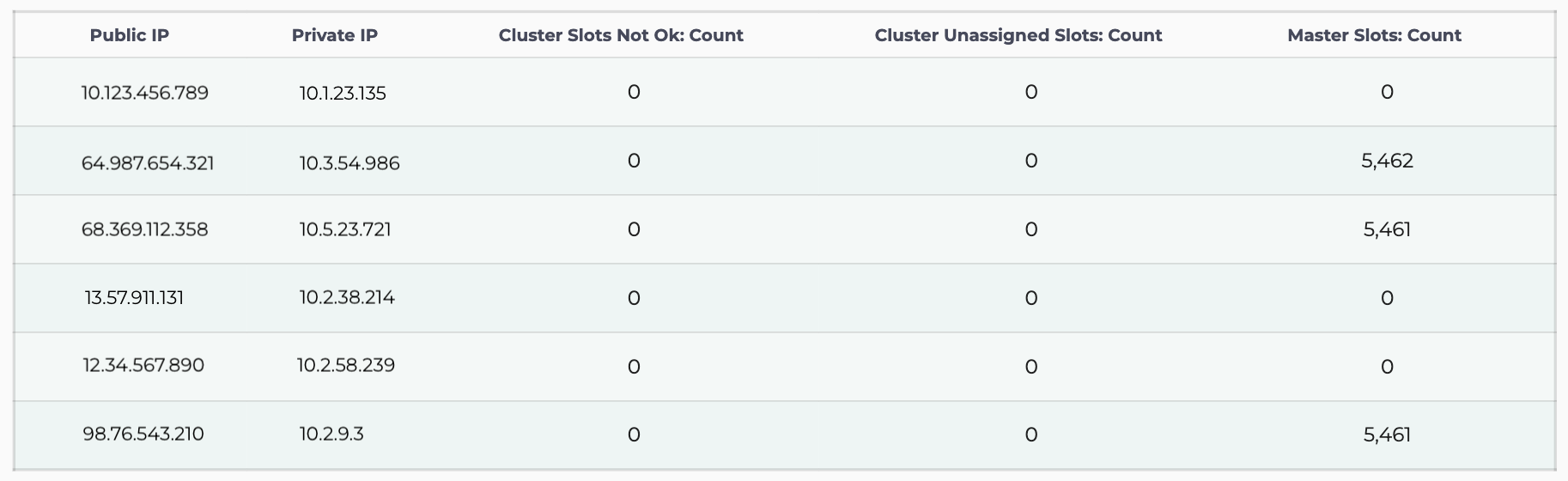
There are 3 metrics visible when viewing the Redis Slots monitoring list or graph.
- Master Slots Count: This is the number of hash slots that each master node has been assigned. The total number adds to 16384 hash slots in a cluster. When master nodes are added, each existing master will hand-off a number of hash slots to the new node/s. When removing a master node, the node’s hash slots will be divided between the remaining master nodes. This happens without any downtime as there is no need to stop operations to change each master’s hash slot count. Replica nodes will have a Master Slot Count of 0.
- Cluster Unassigned Slots Count: This is the number of slots which have not been assigned to a master node in the cluster. Due to each node specifically reporting the status of the cluster, all nodes will report the total number of unassigned slots for the cluster. The default value should be 0 within a working Redis cluster.
- Cluster Slots Not Ok Count: This is the number of hash slots mapping to a node which are currently in a FAIL or PFAIL state. Due to each node specifically reporting the status of the cluster, all nodes will report the total number of “not-ok” slots for the cluster. The default value should be 0 within a working Redis cluster.
PFAIL and FAIL
Redis Cluster failure detection uses 2 flags to identify possible failure (PFAIL) and failed (FAIL) nodes in the cluster.
PFAIL: A Node will be identified as PFAIL by other nodes when it has been unreachable by other nodes for a specified amount of time. This is a non-acknowledged failure type, and therefore is possible only a single node can identify one of its companions as “unable to be reached”. Any node (both master or replica) can flag any other node as PFAIL. This PFAIL flag is only kept locally on the identifying node, other nodes may not flag the “failing node” as PFAIL.
FAIL: A PFAIL node will be upgraded to a FAIL state when a set of conditions are met:
- Some node, that we’ll call A, has another node B flagged as PFAIL.
- Node A collected, via gossip sections, information about the state of B from the point of view of the majority of masters in the cluster.
- The majority of masters signalled the PFAIL or FAIL condition within a specified time
This will then cause Node A to flag Node B as FAIL and broadcast that message to other nodes in the cluster.
More information about Redis Cluster Failure Detection can be found in the Redis Cluster Specifications.