Delayed Operations
The Delayed Operations metric group contains metrics regarding the number of requests that are delayed and waiting in purgatory. The purgatory size can be used to determine the root cause of latency. For example, increased consumer fetch times could be explained by an increased number of fetch requests waiting in purgatory. The metrics available are:
- Fetch Purgatory Size
- Produce Purgatory Size
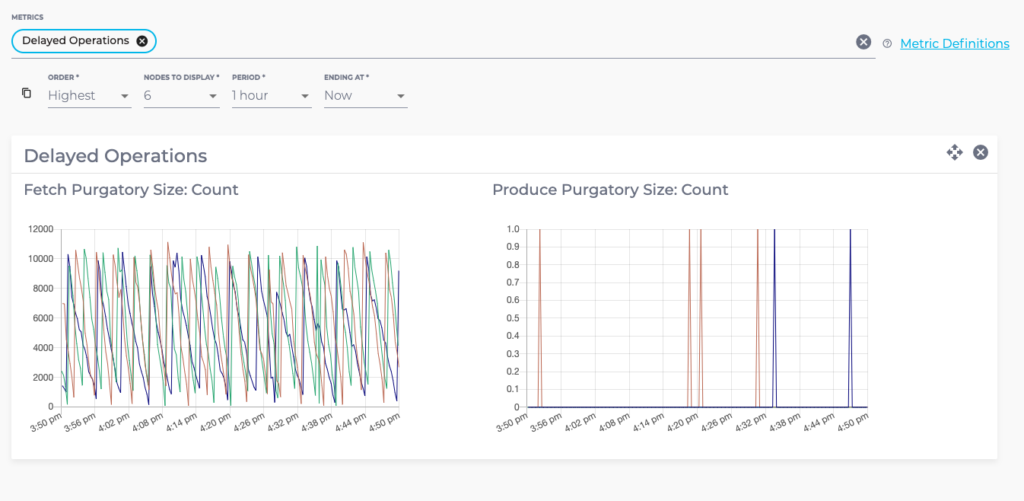
Fetch Purgatory Size
The Fetch Purgatory Size metric shows the number of fetch requests currently waiting in purgatory. Fetch requests are added to purgatory if there is not enough data to fulfil the request (determined by fetch.min.bytes in the consumer configuration) and the requests wait in purgatory until the time specified by fetch.wait.max.ms is reached, or enough data becomes available.
Produce Purgatory Size
The Produce Purgatory Size metric shows the number of produce requests currently waiting in purgatory. Produce requests are added to purgatory if request.required.acks is set to -1 or all, and the requests wait in purgatory until the partition leader receives an acknowledgement from all its followers. If the purgatory size keeps growing, some partition replicas may be overloaded. If this is the case, you can choose to increase the capacity of your cluster, or decrease the amount of produce requests being generated.